SiamBAN
3. SiamBAN 框架
在本节中,我们将描述建议的SiamBAN框架。如图2所示,SiamBAN由一个Siamese网络主干网和多个box自适应磁头组成。Siamese网络主干负责计算模板块和搜索块的卷积特征映射,它使用了现成的卷积网络。box自适应头包括分类模块和回归模块。具体来说,分类模块对相关层的每个点进行前-背景分类,回归模块对对应位置进行包围盒预测。

图2:提出的box自适应网络的架构。左图为其主要结构,其中C3、C4、C5为骨干网络的特征图,Cls Map、Reg Map为SiamBAN heads输出的特征图。右边的子图显示了每个孪生头,其中DW-Corr表示深度交叉相关操作。
3.1. Siamese主干网络
现代深度神经网络[12,44,13]已被证明在基于Siamese网络的跟踪器中是有效的[20,42,49],现在我们可以在基于Siamese网络的跟踪器中使用ResNet、ResNeXt和MobileNet等深度神经网络。在我们的跟踪器中,我们采用ResNet-50[12]作为主干网络。虽然使用连续卷积步法的ResNet-50可以学习越来越多的抽象特征表示,但它降低了特征分辨率。然而,基于孪生网络的跟踪器需要详细的空间信息才能进行密集预测。为了解决这个问题,我们从最后两个卷积块中移除降采样操作。同时,为了改善接收野,我们使用了空洞卷积[4],这被证明是视觉跟踪的有效方法[21,42]。另外,受多重网格方法[40]的启发,我们在模型中采用了不同的atrous rates。具体来说,我们在conv4和conv5块中将stride设置为1,在conv4块中将atrous rate设置为2,在conv5块中将atrous rate设置为4。
孪生网络主干网由两个相同的分支组成。一个叫做模板分支,接收模板块作为输入(表示z)。另一个被称为搜索分支,接收搜索块作为输入(x)。这两个分支共享参数卷积神经网络以确保相同的转换应用于这两个块。为了减少计算量,我们增加了1×1卷积,将输出特征通道减少到256,并且只使用模板分支中心7×7区域的特征[38,20],仍然可以捕获整个目标区域。为了方便起见,Siamese网络的输出特征表示为 ϕ ( z ) ϕ(z) ϕ(z)和 ϕ ( x ) ϕ(x) ϕ(x)。
3.2. Box自适应Head
如图2(右)所示,box自适应头部由分类模块和回归模块组成。这两个模块都从模板分支和搜索分支接收特征。因此,我们调整并复制 ϕ ( z ) ϕ(z) ϕ(z)和 ϕ ( x ) ϕ(x) ϕ(x)到 [ ϕ ( z ) ] c l s [ϕ(z)]_{cls} [ϕ(z)]cls, [ ϕ ( z ) ] r e g [ϕ(z)]_{reg} [ϕ(z)]reg和 [ ϕ ( x ) ] c l s [ϕ(x)]_{cls} [ϕ(x)]cls, [ ϕ ( x ) ] r e g [ϕ(x)]_{reg} [ϕ(x)]reg到相应模块。根据我们的设计,分类模块相关层的每个点需要输出2个通道用于前-背景分类,回归模块相关层的每个点需要输出4个通道来预测包围盒。每个模块使用深度相关层[20]组合特征图:
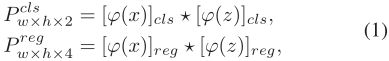
对于分类图 P w × h × 2 c l s P^{cls} _{w×h×2} Pw×h×2cls或回归图 P w × h × 4 r e g P^{reg}_{w×h×4} Pw×h×4reg中的每个位置,我们都可以将其映射到输入搜索块。例如,位置(i, j)对应的位置搜索块 ( ⌊ w i m / 2 ⌋ + ( i − ⌊ w / 2 ⌋ ) × s , ⌊ h i m / 2 ⌋ + ( j − ⌊ h / 2 ⌋ ) × s ] (⌊w_{im}/2⌋+(i−⌊w/ 2⌋)×s,⌊h_{im}/2⌋+ (j−⌊h/2⌋)×s] (⌊wim/2⌋+(i−⌊w/2⌋)×s,⌊him/2⌋+(j−⌊h/2⌋)×s](表示为 ( p i , p j ) (p_i,p_j) (pi,pj)。 w i m w_{im} wim和 h i m h_{im} him代表输入搜索块的宽度和高度,s代表网络的总的步长),这是接受域的中心位置(i, j)。对于回归,基于锚具的跟踪器[21,52,20]将位置(pi, pj)作为锚盒的中心,回归位置(pi, pj)、宽度 a w a_w aw和高度 a h a_h ah。也就是说,对于位置(i, j),回归可以调整其所有的偏移值,但仍然在原始位置进行分类,这可能会导致分类和回归不一致。因此,我们不调整位置(pi, pj),而只计算它在包围框中的偏移值。此外,由于我们的回归目标是正实数,我们在回归模块的最后一层应用 e x p ( x ) exp(x) exp(x)来将任何实数映射到(0,+∞)。
3.3. 多层次预测
利用ResNet-50和空洞卷积后,我们可以使用多层特征进行预测。虽然我们骨干网络的conv3、conv4和conv5块空间分辨率相同,但它们具有不同扩展速率的空洞卷积,因此它们的接收域差异较大,所捕获的信息自然存在差异。正如CF2[26]所指出的,来自较早层的特征可以捕获细粒度信息,这对精确定位非常有用;而后一层的特征可以编码抽象的语义信息,对目标外观变化具有较强的鲁棒性。为了充分利用多层次特征的不同特征,我们采用多箱自适应头进行预测。每个检测头得到的分类图和回归图自适应融合:

其中 α l α_{l} αl和 β l β_{l} βl分别为每个map对应的权值,并与网络一起优化。通过独立地组合分类映射和回归映射,分类模块和回归模块可以专注于它们需要的领域。

图3:分类标签和回归目标的插图。预测值和监督信号如图所示,其中E1表示椭圆E1, E2表示椭圆E2。我们分别使用交叉熵和IoU损失进行分类和box回归。
3.4. 真值和损失
分类标签和回归目标。如图3所示,每个搜索patch上的目标都用一个ground-truth边界框标记。ground-truth包围盒的宽度、高度、左上角、中心点和右下角分别用 g w g_w gw、 g h g_h gh、 ( g x 1 、 g y 1 ) (g_{x_1}、g_{y_1}) (gx1、gy1)、 ( g x c 、 g y c ) (g_{x_c}、g_{y_c}) (gxc、gyc)和 ( g x 2 、 g y 2 ) (g_{x_2}、g_{y_2}) (gx2、gy2)表示。以 ( g x c , g y c ) (g_{x_c}, g_{yc}) (gxc,gyc)为中心,以 g w / 2 g_w/2 gw/2, g h / 2 g_h/2 gh/2为轴长,可得椭圆E1:

以 ( g x c , g y c ) (g_{x_c}, g_{y_c}) (gxc,gyc)为中心,以 g w / 4 , g h / 4 g_w/4,g_h/4 gw/4,gh/4为轴长,得到椭圆E2:

如果位置(pi, pj)落在椭圆E2内,则赋值为正标签,如果落在椭圆E1外,则赋值为负标签,如果落在椭圆E2和E1之间,则忽略它。用带正标号的位置(pi, pj)对包围盒进行回归,回归目标可表示为:

其中dl、dt、dr、db为该位置到包围盒四周的距离,如图3所示。分类损失和回归损失。我们将多任务损失函数定义如下:
![]()
其中 L c l s L_{cls} Lcls为交叉熵损失, L r e g L_{reg} Lreg为IoU(交叉于并集)损失。我们不寻找Eq.6的超参数,简单地设置λ1=λ2= 1。与 G I o U GIoU GIoU[33]类似,IoU损失定义为:
![]()
其中 I o U IoU IoU表示预测包围框与真实包围框相交并集的面积比。有正标签的位置(pi, pj)位于椭圆E2内,且回归值大于0,因此 0 < I o U ≤ 1 0< IoU≤1 0<IoU≤1,则 0 ≤ L I o U < 1 0≤LIoU< 1 0≤LIoU<1。 I o U IoU IoU损失可使 d l 、 d t 、 d r 、 d b d_l、d_t、d_r、d_b dl、dt、dr、db共同回归。
3.5. 训练和推理
训练。我们的整个网络可以在大规模数据集上进行端到端训练。我们用视频或静止图像上的图像对来训练SiamBAN。训练集包括ImageNet VID[34]、YouTube-BoundingBoxes[30]、COCO[25]、ImageNet DET[34]、GOT10k[15]和LaSOT[9]。模板patch的大小为127×127像素,搜索patch的大小为255×255像素。此外,虽然我们的负样本比基于锚的跟踪器少得多[21,20],但负样本仍然比正样本多得多。因此,我们最多从一对图像中收集16个正样本和48个负样本。
推理。在推理过程中,我们从第一帧中裁剪模板patch并将其反馈给特征提取网络。提取的模板特征被缓存,因此我们不必在后续跟踪中计算它们。对于后续帧,我们根据前一帧的目标位置裁剪搜索patch并提取特征,然后对搜索区域进行预测,得到总分类图 P w × h × 2 c l s − a l l P^{cls−all}_{w×h×2} Pw×h×2cls−all和回归图 P w × h × 2 r e g − a l l P^{reg−all}_{w×h×2} Pw×h×2reg−all。然后,我们可以通过下式得到预测盒:

其中, d l r e g d^{reg}_l dlreg, d t r e g d^{reg}_t dtreg, d r r e g d^{reg}_r drreg, d b r e g d^{reg}_b dbreg为回归图的预测值, ( p x 1 , p y 1 ) (p_{x_1}, p_{y_1}) (px1,py1)和 ( p x 2 , p y 2 ) (p_{x_2}, p_{y_2}) (px2,py2)为预测框的顶角和右下角。
在生成预测盒后,我们利用余弦窗和尺度变化惩罚对目标运动进行平滑,改变[21],然后选择得分最好的预测盒,并利用前一帧的状态通过线性插值更新预测盒的大小。
实验
4.1 实现细节
我们用ImageNet[34]上预先训练好的权值初始化骨干网络,并冻结前两层的参数。我们的网络是用小批量28对随机梯度下降(SGD)进行训练的。我们总共训练了20个epoch,前5个epoch的热身学习率为0.001到0.005,后15个epoch的学习率为0.005到0.00005的指数衰减。在前10个时期,我们只训练盒子自适应头,在后10个时期,我们以目前1 / 10的学习率微调骨干网络。设定重量衰减和动量为0.0001和0.9。我们的方法是在Python中使用PyTorch在PC上实现的,使用Intel Xeon® 4108 1.8GHz CPU, 64G RAM, Nvidia GTX 1080Ti。
4.2. 对比先进的跟踪器
我们比较我们的暹罗跟踪器与最先进的跟踪器在六个跟踪基准上。我们的跟踪器达到最先进的结果和运行在40 FPS。