tensorflow [saved_model,.pb]模型生成及处理以及多模型合并到上线服务请求从0到1
多模型合并:在模型上线时,我们训练的多个模型往往功能相似或相近或有某种联系,在请求模型的返回结果时,如果一个接一个的去请求,会严重影响程序的效率。并发请求虽然能够缓解这种现象,理论上甚至可以达到与单个模型相同的请求时间,但是实际操作与理论还是有很大差距的。很明显,这种将模型串联起来的方式不够科学。如果把这些模型并联起来,分别接受相同或不同的输入,效果会大大不同,其运行效率与单个模型相差无几。
接下来我将用几篇的篇幅,讲述模型从建立到上线的一系列流程,以及整个流程涉及到的并发请求、模型合并、串联改并联等一系列方式方法的实现及对比。
准备工作:为了方便讲解,整个过程均采用很简单的模型作为讲解对象,以后称为模型一。
公式:
op = x*y+b
op1 = x*y + op
实现:
![tensorflow [saved_model,.pb]模型生成及处理以及多模型合并到上线服务请求从0到1_第1张图片](http://img.e-com-net.com/image/info8/41c16b2f126c45f78b5bdd839b5ff1b4.jpg)
传入参数x=5,y=5的测试结果是[26,51],
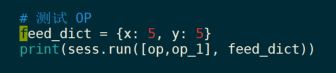
结果截图
![]()
第一步,模型固化:
将模型一固化为.pb模型,此处的.pb模型与上线用的saved_model里的pb模型不一样,这里的pb模型包含了模型的缩影信息(结构和参数值)。
需要引入 graph_util:
from tensorflow.python.framework import graph_util

上图中,‘op_to_store’和'op_1_to_store'是模型的输出,这里定义的输出是模型一中的op,op_1.可以看到这里用的是op,op_1的name属性。’model.pb‘是pb模型的文件名,这里是保存在当前目录下的'model.pb'文件里。
pb模型的读取一般采用ParseFromString()函数,具体如下图:
![tensorflow [saved_model,.pb]模型生成及处理以及多模型合并到上线服务请求从0到1_第2张图片](http://img.e-com-net.com/image/info8/11ab368cb10449218d8afd51f5d1d05c.jpg)
上图中第一个框是读pb模型的过程,第二个框是打印模型中的参数,第三个框是运行模型。要注意的是如何获取模型参数,格式为“模型名/参数名:0",读取pb模型参数时,后面的”:0“一定不能去掉。
第二步:多个pb模型合并
合并模型前,首先要将要合并的模型读取出来,然后重定向输入输出,最后固化保存。
首先,将读取pb模型的部分写成函数。

然后调用函数,分别读取pb模型,为了方便,本文将读取5个相同的模型。不同结构、不同输入输出的模型也一样可以执行接下来的并行操作,改变下输入输出即可。
![tensorflow [saved_model,.pb]模型生成及处理以及多模型合并到上线服务请求从0到1_第3张图片](http://img.e-com-net.com/image/info8/f2350cad416e4fafad2a78ff7fb62cd1.jpg)
上面是读取模型的代码,分别将读出来的模型赋值给5个变量。由于5个模型输入输出一样,因此定义输入的时候,只需要定义一组。如果几个模型结构不同,那就需要根据每个模型的要求分别定义输入。

接下来重定向输入输出,
![tensorflow [saved_model,.pb]模型生成及处理以及多模型合并到上线服务请求从0到1_第4张图片](http://img.e-com-net.com/image/info8/46b2907488154399896ec9ae34a7ef4a.jpg)
import_graph_def的第一个参数,就是我们上面读取到的模型,在这里是“graph_def_x”.
第二个参数”input_map“,输入的是字典类型的数据,字典的键是“旧的输入”,即子模型中的原来的输入,这里用名字来标记,字典的值是“新的输入”,即上面定义的变量名。如上图“input_x”和“input_y”是新的输入,“x:0”和"y:0"是对应的子模型中的输入,其含义就是“x:0”接受”input_x“的值,“y:0”接受"input_y"的值。
第三个参数,return_elements 定义的是模型的返回的值,比如当模型获得一个输入,可能会返回类别信息,或是一个评分,或是一个句子等等。在这里我们返回的是“op_to_store:0”和“op_1_to_store:0”,与子模型里的变量op和op_1的”name“属性相对应。
tf.identity(graph_4, "mod_4") 表示的是在新的大模型里,将子模型graph_4,识别为“mod_4”;也可以理解为,大模型重新为小模型取了个名字。这个名字在模型结合,以及后续模型转化、上线的过程中都会用到。
接下来是模型结合。

convert_variables_to_constants函数的第三个参数“output_node_names”是列表形式,传入的是之前重定向后的模型名字。这个函数也可以用来固化单个模型为pb模型,很方便。
write_graph函数将固化好的模型保存,g_combined_def是固化后的大模型;out_pb_path是模型保存的目录;‘merge_model.pb’是模型保存后的名字;as_text的值一定要设置为False,否则,读取模型的时候会出错。
至此,原来串联的小模型已经是一个大的并行模型了。我们要验证一下他的输入输出是否符合要求,读取大模型的方式与之前类似,只是输入和输出变了。输入时之前定义的新输入,输出是子模型的名字。
![tensorflow [saved_model,.pb]模型生成及处理以及多模型合并到上线服务请求从0到1_第5张图片](http://img.e-com-net.com/image/info8/4848f276fdfa4596bd9849d605a9c5cb.jpg)
第一个框是读取模型的过程,与之前类似,但注意一定要传入“name”属性,读取模型内部参数时需要用到,这里定义的“name”是“XXX”。
第二个框是读取模型变量并打印出来的过程。
第三个框是,传入一组数据得到输出的过程。下图为执行结果。
![]()
可以看到,我们打印出来了获取到的tensor,也打印出来了5个模型的输出,每个子模型输出和单个模型的输出一样,没有被改变。
至此,合并子模型为大模型的操作结束,同时也完成了子模型串联改并联。
第三步:模型上线准备:
纯pb模型转换为saved_model模式,即saved_model.pb+variables的tfserving需要的模式。
接着上面的步骤,一步一步来,可以之前运行测试的代码去掉,没有影响,须保留读取模型tensor的代码:
![tensorflow [saved_model,.pb]模型生成及处理以及多模型合并到上线服务请求从0到1_第6张图片](http://img.e-com-net.com/image/info8/973d0ac6347241eda7703c6e45350491.jpg)
builder是用来保存saved_model全程都需要的工具,用builder.SavedModelBuilder函数声明,传入的参数"./success/1/"是saved_model将要保存的地址。
inputs:定义模型要接受的输入;
outputs:定义模型的输出;
prediction_signature将模型的输入输出进行整合,其中method_name参数必须传入,否则会提示错误;
builder.add_meta_graph_and_variables将模型结构及参数传入builder;
builder.save():保存saved_model模型。
运行之后,/success/1下会有saved_model.pb和文件夹variables.

至此,模型已经可以利用tfserving部署上线了,上线流程与普通模型一样,教程很多,在此不在赘述。要注意的一点是--enable-batch这个参数要去掉,否则请求的时候会出错。

上线之后模型的请求,测试代码如下:
![tensorflow [saved_model,.pb]模型生成及处理以及多模型合并到上线服务请求从0到1_第7张图片](http://img.e-com-net.com/image/info8/ca24aa5b4e7543708be93eb4021f2c49.jpg)
下图是模型请求的返回结果
![]()
以上所有代码均在:
https://github.com/pkulics/tensorflow_model_process
欢迎访问个人官网:lichangsong.win
我的个人网站:lichangsong.win
我的又大又全又便宜的某宝资料铺:
![tensorflow [saved_model,.pb]模型生成及处理以及多模型合并到上线服务请求从0到1_第8张图片](http://img.e-com-net.com/image/info8/eaf1a854cf5d433baec0a8b6af9fe1fc.jpg)
緮置这行话¥PCYX1QCAm9R¥转移至淘宀┡ē【码世界资料铺】;或https://m.tb.cn/h.V6uwZ9I?sm=916410 點击链街,再选择瀏..覽..噐dakai