scale_dot_product_attention and multi_head_attention tf2.x
Transformer用到了两个attention模块:一个模块被用于encoder,一个模块位于decoder。encoder中的attention叫做self-attention,此时QKV分别为这个模块的输入(第一层为词嵌入,第二层及以后为上一次层的输出)分别乘上三个矩阵得到的结果分别为QKV,这三个矩阵是在训练的时候学习。decoder中的attention叫做encoder-decoder attention,这个attention的KV来自encoder的最后一层输出,继续乘以不同的矩阵。至于Q就是decoder上一层的输出乘以一个矩阵。
import matplotlib as mpl
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
# 缩放点积注意力
def scaled_dot_product_attention(q ,k ,v ,mask):
'''
Args:
-q : shape==(...,seq_len_q,depth)
-k : shape==(...,seq_len_k,depth)
-v : shape==(...,seq_len_v,depth_v)
- seq_len_k = seq_len_v
- mask: shape == (...,seq_len_q,seq_len_k) 点积
return:
output:weighted sum
attention_weights:weights of attention
'''
# shape == (...,seq_len_q,seq_len_k)
# embedding 向量算法内积
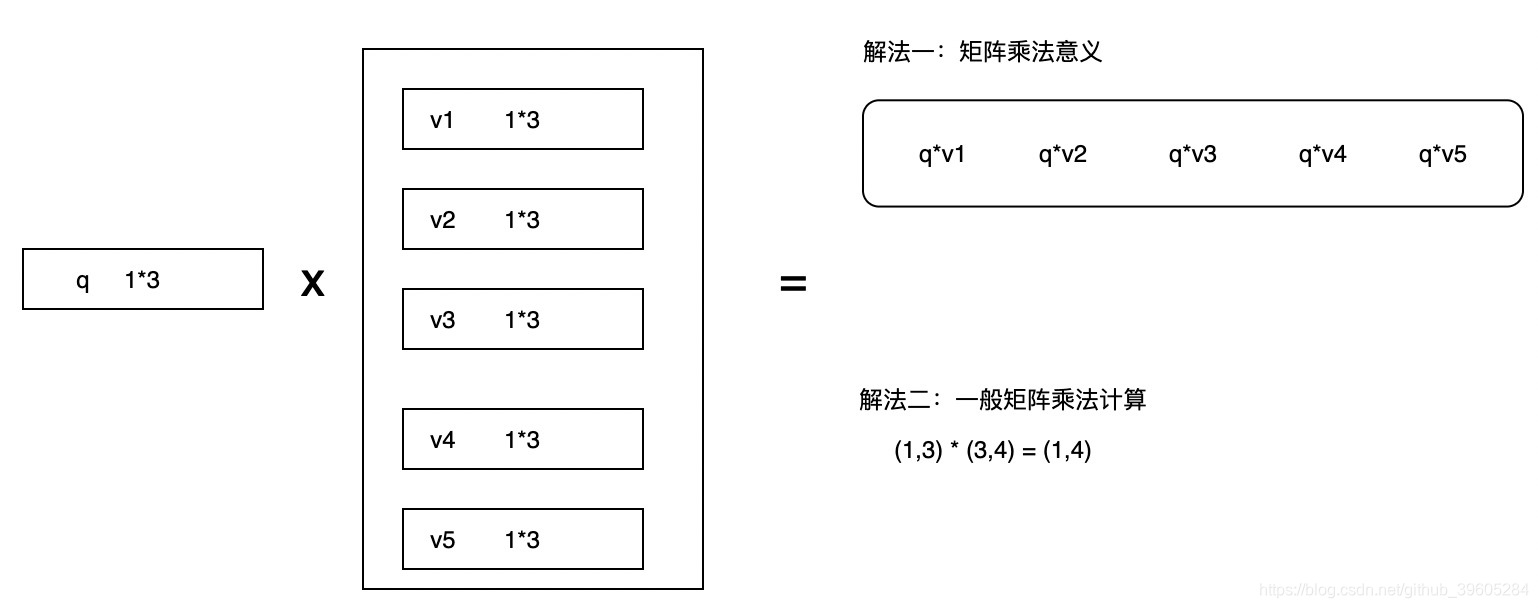
matmul_qk =tf.matmul(q, k, transpose_b=True)
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
if mask is not None:
# 10的负九次方比较大,会使得需要掩盖的数据在softmax的时候趋近0
scaled_attention_logits += (mask * -1e9)
# shape == (...,seq_len_q,seq_len_k)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
# shape==(...,seq_len_q,depth_v)
output = tf.matmul(attention_weights, v)
return output, attention_weights
def print_scaled_dot_attention(q, k, v):
temp_out, temp_att = scaled_dot_product_attention(q, k, v, None)
print("Attention weights are:")
print(temp_att)
print("Outputs are:")
print(temp_out)
# 测试代码
# self attention attention
np.set_printoptions(suppress=True) # 使得小数结果压缩
# 多头注意力机制的实现
# '''
# 理论上
# x->Wq0->q0
# x->Wk0->k0
# x->Wv0->v0
# 实战中
# q->Wq0->q0
# k->Wk0->k0
# v->Wv0->v0
# 技巧
# q->Wq->Q->split->q0,q1,...
# '''
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
# 三个神经网络,对同一输入进行三次不同变换,生成了Q,K,V
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
"""分拆最后一个维度到 (num_heads, depth).
转置结果使得形状为 (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention,
perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
temp_mha = MultiHeadAttention(d_model=512, num_heads=8)
y = tf.random.uniform((1, 60, 512)) # (batch_size, encoder_sequence, d_model)
out, attn = temp_mha(y, k=y, q=y, mask=None)
out.shape, attn.shape
深度学习attention机制中的Q,K,V分别是从哪来的?
各种版本的解释:
q:query代表的是当前单词
k:key代表的是每个单词
v: value代表的也是当前单词