学习笔记:C++进阶【继承、多态、二叉树进阶、map和set、哈希、C++11、异常、智能指针、特殊类设计、C++的类型转换】
文章目录
- 前言
- 一、继承
-
- 1. 继承的概念及定义
-
- 1.1 继承的概念
- 1.2 继承的定义
-
- 1.2.1 定义格式
- 1.2.2 继承关系和访问限定符
- 1.2.3 继承基类成员访问方式的变化
- 2. 基类和派生类对象赋值转换
- 3. 继承中的作用域
- 4. 派生类的默认成员函数
- 5. 继承与友元
- 6. 继承与静态成员
- 7. 复杂的菱形继承及菱形虚拟继承
- 8. 继承的总结和反思
- 9. 笔试面试题
- 二、多态
-
- 前言
- 1. 多态的概念
-
- 1.1 概念
- 2. 多态的定义及实现
-
- 2.1多态的构成条件
- 2.2 虚函数
- 2.3虚函数的重写
- 2.4 C++11 override 和 final
- 2.5 重载、覆盖(重写)、隐藏(重定义)的对比
- 3. 抽象类
-
- 3.1 概念
- 3.2 接口继承和实现继承
- 4. 多态的原理
-
- 4.1虚函数表
- 4.2多态的原理
- 4.3 动态绑定与静态绑定
- 5. 单继承和多继承关系中的虚函数表
-
- 5.1 单继承中的虚函数表
- 5.2 多继承中的虚函数表
- 5.3. 菱形继承、菱形虚拟继承
- 6. 继承和多态常见的面试问题
-
- 6.2 问答题
- 三、二叉树进阶
-
- 1. 内容安排说明
- 2. 二叉搜索树
-
- 2.1 二叉搜索树概念
- 2.2 二叉搜索树操作
- 2.3 二叉搜索树的实现
- 2.4 二叉搜索树的应用
- 2.5 二叉搜索树的性能分析
- 3. 二叉树进阶面试题(OJ题)
- 四、map和set
- 五、哈希
- 六、C++11
- 七、异常
- 八、智能指针
- 九、特殊类设计
- 十、C++的类型转换
前言
这篇是学习笔记:记录C++和数据结构进阶学习过程中的要点疑点和难点。 笔记简介:这篇笔记写于2022/11/16,完结于2022/?/?。完结后多次增删内容和修正。
一、继承
1. 继承的概念及定义
1.1 继承的概念
继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允许程序员在保持原有类特性的基础上进行扩展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象程序设计的层次结构,体现了由简单到复杂的认知过程。以前我们接触的复用都是函数复用,继承是类设计层次的复用。
class Person
{
public:
void Print()
{
cout << "name:" << _name << endl;
cout << "age:" << _age << endl;
}
protected:
string _name = "peter"; // 姓名
int _age = 18; // 年龄
};
// 继承后父类的Person的成员(成员函数+成员变量)都会变成子类的一部分。这里体现出了Student和Teacher复用了Person的成员。我们使用监视窗口查看Student和Teacher对象,可以看到变量的复用。调用Print可以看到成员函数的复用。
class Student : public Person
{
protected:
int _stuid; // 学号
};
class Teacher : public Person
{
protected:
int _jobid; // 工号
};
int main()
{
Student s;
Teacher t;
s.Print();
t.Print();
return 0;
}
1.2 继承的定义
1.2.1 定义格式
下面我们看到Person是父类,也称作基类。Student是子类,也称作派生类。

1.2.2 继承关系和访问限定符

1.2.3 继承基类成员访问方式的变化

总结:
(1)基类private成员在派生类中无论以什么方式继承都是不可见的。这里的不可见是指基类的私有成员还是被继承到了派生类对象中,但是语法上限制派生类对象不管在类里面还是类外面都不能去访问它。
(2)基类private成员在派生类中是不能被访问,如果基类成员不想在类外直接被访问,但需要在派生类中能访问,就定义为protected。可以看出保护成员限定符是因继承才出现的。
(3)实际上面的表格我们进行一下总结会发现,基类的私有成员在子类都是不可见。基类的其他成员在子类的访问方式 == Min(成员在基类的访问限定符,继承方式),public > protected > private。
(4)使用关键字class时默认的继承方式是private,使用struct时默认的继承方式是public,不过最好显示的写出继承方式。
(5)在实际运用中一般使用都是public继承,几乎很少使用protetced/private继承,也不提倡使用protetced/private继承,因为protetced/private继承下来的成员都只能在派生类的类里面使用,实际中扩展维护性不强。
// 实例演示三种继承关系下基类成员的各类型成员访问关系的变化
class Person
{
public:
void Print()
{
cout << _name << endl;
}
protected:
string _name; // 姓名
private:
int _age; // 年龄
};
// class Student : protected Person
// class Student : private Person
class Student : public Person
{
protected:
int _stunum; // 学号
};
2. 基类和派生类对象赋值转换
(1)派生类对象 可以赋值给 基类的对象 / 基类的指针 / 基类的引用。这里有个形象的说法叫切片或者切割。寓意把派生类中父类那部分切来赋值过去。
(2)基类对象不能赋值给派生类对象
(3)基类的指针可以通过强制类型转换赋值给派生类的指针。但是必须是基类的指针是指向派生类对象时才是安全的。这里基类如果是多态类型,可以使用RTTI(Run-Time Type Information)的dynamic_cast 来进行识别后进行安全转换。

class Person
{
protected:
string _name; // 姓名
string _sex; // 性别
int _age; // 年龄
};
class Student : public Person
{
public:
int _No; // 学号
};
void Test()
{
Student sobj;
// 1.子类对象可以赋值给父类对象/指针/引用
Person pobj = sobj;
Person* pp = &sobj;
Person& rp = sobj;
//2.基类对象不能赋值给派生类对象
sobj = pobj;
// 3.基类的指针可以通过强制类型转换赋值给派生类的指针
pp = &sobj;
Student * ps1 = (Student*)pp; // 这种情况转换时可以的。
ps1->_No = 10;
pp = &pobj;
Student* ps2 = (Student*)pp; // 这种情况转换时虽然可以,但是会存在越界访问的问题
ps2->_No = 10;
}
3. 继承中的作用域
(1)在继承体系中基类和派生类都有独立的作用域。
(2)子类和父类中有同名成员,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫隐藏,也叫重定义。(在子类成员函数中,可以使用 基类::基类成员 显示访问)
(3)需要注意的是如果是成员函数的隐藏,只需要函数名相同就构成隐藏。
(4)注意在实际中在继承体系里面最好不要定义同名的成员。
class Person
{
protected:
string _name = "小李子"; // 姓名
int _num = 111; // 身份证号
};
class Student : public Person
{
public:
void Print()
{
cout << " 姓名:" << _name << endl;
cout << " 身份证号:" << Person::_num << endl;
cout << " 学号:" << _num << endl;
}
protected:
int _num = 999; // 学号
};
void Test()
{
Student s1;
s1.Print();
};
// Student的_num和Person的_num构成隐藏关系,可以看出这样代码虽然能跑,但是非常容易混淆
// B中的fun和A中的fun不是构成重载,因为不是在同一作用域
// B中的fun和A中的fun构成隐藏,成员函数满足函数名相同就构成隐藏。
class A
{
public:
void fun()
{
cout << "func()" << endl;
}
};
class B : public A
{
public:
void fun(int i)
{
A::fun();
cout << "func(int i)->" << i << endl;
}
};
void Test()
{
B b;
b.fun(10);
};
4. 派生类的默认成员函数
6个默认成员函数,“默认”的意思就是指我们不写,编译器会变我们自动生成一个,那么在派生类中,这几个成员函数是如何生成的呢?
(1)派生类的构造函数必须调用基类的构造函数初始化基类的那一部分成员。如果基类没有默认的构造函数,则必须在派生类构造函数的初始化列表阶段显示调用。
(2)派生类的拷贝构造函数必须调用基类的拷贝构造完成基类的拷贝初始化。
(3)派生类的operator=必须要调用基类的operator=完成基类的复制。
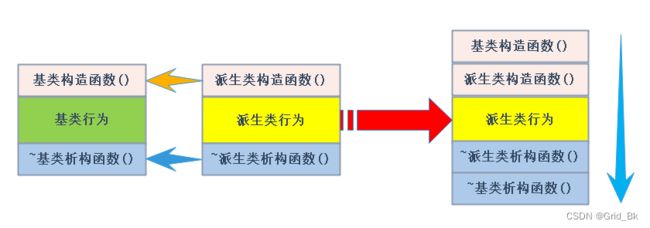
(4)派生类的析构函数会在被调用完成后自动调用基类的析构函数清理基类成员。因为这样才能保证派生类对象先清理派生类成员再清理基类成员的顺序。
(5)派生类对象初始化先调用基类构造再调派生类构造。
(6)派生类对象析构清理先调用派生类析构再调基类的析构。

class Person
{
public:
Person(const char* name = "peter")
: _name(name)
{
cout << "Person()" << endl;
}
Person(const Person& p)
: _name(p._name)
{
cout << "Person(const Person& p)" << endl;
}
Person& operator=(const Person& p)
{
cout << "Person operator=(const Person& p)" << endl;
if (this != &p)
_name = p._name;
return *this;
}
~Person()
{
cout << "~Person()" << endl;
}
protected:
string _name; // 姓名
};
class Student : public Person
{
public:
Student(const char* name, int num)
: Person(name)
, _num(num)
{
cout << "Student()" << endl;
}
Student(const Student& s)
: Person(s)
, _num(s._num)
{
cout << "Student(const Student& s)" << endl;
}
Student& operator = (const Student& s)
{
cout << "Student& operator= (const Student& s)" << endl;
if (this != &s)
{
Person::operator =(s);
_num = s._num;
}
return *this;
}
~Student()
{
cout << "~Student()" << endl;
}
protected:
int _num; //学号
};
void Test()
{
Student s1("jack", 18);
Student s2(s1);
Student s3("rose", 17);
s1 = s3;
}
5. 继承与友元
友元关系不能继承,也就是说基类友元不能访问子类私有和保护成员
class Student;
class Person
{
public:
friend void Display(const Person& p, const Student& s);
protected:
string _name; // 姓名
};
class Student : public Person
{
protected:
int _stuNum; // 学号
};
void Display(const Person& p, const Student& s)
{
cout << p._name << endl;
cout << s._stuNum << endl;
}
void main()
{
Person p;
Student s;
Display(p, s);
}
6. 继承与静态成员
基类定义了static静态成员,则整个继承体系里面只有一个这样的成员。无论派生出多少个子类,都只有一个static成员实例 。
class Person
{
public:
Person() { ++_count; }
protected:
string _name; // 姓名
public:
static int _count; // 统计人的个数。
};
int Person::_count = 0;
class Student : public Person
{
protected:
int _stuNum; // 学号
};
class Graduate : public Student
{
protected:
string _seminarCourse; // 研究科目
};
void TestPerson()
{
Student s1;
Student s2;
Student s3;
Graduate s4;
cout << " 人数 :" << Person::_count << endl;
Student::_count = 0;
cout << " 人数 :" << Person::_count << endl;
}
7. 复杂的菱形继承及菱形虚拟继承
单继承:一个子类只有一个直接父类时称这个继承关系为单继承

多继承:一个子类有两个或以上直接父类时称这个继承关系为多继承

菱形继承:菱形继承是多继承的一种特殊情况

菱形继承的问题:从下面的对象成员模型构造,可以看出菱形继承有数据冗余和二义性的问题。在Assistant的对象中Person成员会有两份。
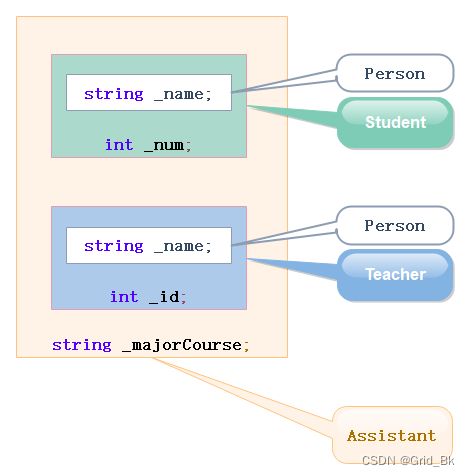
class Person
{
public:
string _name; // 姓名
};
class Student : public Person
{
protected:
int _num; //学号
};
class Teacher : public Person
{
protected:
int _id; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected:
string _majorCourse; // 主修课程
};
void Test()
{
// 这样会有二义性无法明确知道访问的是哪一个
Assistant a;
a._name = "peter";
// 需要显示指定访问哪个父类的成员可以解决二义性问题,但是数据冗余问题无法解决
a.Student::_name = "xxx";
a.Teacher::_name = "yyy";
}
虚拟继承可以解决菱形继承的二义性和数据冗余的问题。如上面的继承关系,在Student和Teacher的继承Person时使用虚拟继承,即可解决问题。需要注意的是,虚拟继承不要在其他地方去使用。
class Person
{
public:
string _name; // 姓名
};
class Student : virtual public Person
{
protected:
int _num; //学号
};
class Teacher : virtual public Person
{
protected:
int _id; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected:
string _majorCourse; // 主修课程
};
void Test()
{
Assistant a;
a._name = "peter";
}
虚拟继承解决数据冗余和二义性的原理:
为了研究虚拟继承原理,我们给出了一个简化的菱形继承继承体系,再借助内存窗口观察对象成员的模型。
class A
{
public:
int _a;
};
// class B : public A
class B : virtual public A
{
public:
int _b;
};
// class C : public A
class C : virtual public A
{
public:
int _c;
};
class D : public B, public C
{
public:
int _d;
};
int main()
{
D d;
d.B::_a = 1;
d.C::_a = 2;
d._b = 3;
d._c = 4;
d._d = 5;
return 0;
}
下图是菱形继承的内存对象成员模型:这里可以看到数据冗余

下图是菱形虚拟继承的内存对象成员模型:
这里可以分析出D对象中将A放到的了对象组成的最下面,这个A同时属于B和C,那么B和C如何去找到公共的A呢?这里是通过了B和C的两个指针,指向的一张表。这两个指针叫虚基表指针,这两个表叫虚基表。虚基表中存的偏移量。通过偏移量可以找到下面的A。

// 有童鞋会有疑问为什么D中B和C部分要去找属于自己的A?那么大家看看当下面的赋值发生时,d是不是要去找出B / C成员中的A才能赋值过去?
D d;
B b = d;
C c = d;
下面是上面的Person关系菱形虚拟继承的原理解释:

8. 继承的总结和反思
(1)很多人说C++语法复杂,其实多继承就是一个体现。有了多继承,就存在菱形继承,有了菱形继承就有菱形虚拟继承,底层实现就很复杂。所以一般不建议设计出多继承,一定不要设计出菱形继承。否则在复杂度及性能上都有问题。
(2)多继承可以认为是C++的缺陷之一,很多后来的OO语言都没有多继承,如Java。
(3)继承和组合
①public继承是一种is-a的关系。也就是说每个派生类对象都是一个基类对象。
②组合是一种has-a的关系。假设B组合了A,每个B对象中都有一个A对象。
③优先使用对象组合,而不是类继承 。
《极限编程》(Extreme programming)的指导原则之一是“只要能用,就做最简单的”。一个似乎需要继承的设计常常能够戏剧性地使用组合来代替而大简化,从而使其更加灵活。因此,在考虑一个设计时,问问自己:“使用组合是不是更简单?这里真的需要继承吗?它能带来什么好处?”
继承和组合的比较:
面向对象系统中功能复用的两种最常用技术是类继承和对象组合(object composition)。正如我们已解释过的,类继承允许你根据其他类的实现来定义一个类的实现。这种通过生成子类的复用通常被称为白箱复用(white-box reuse)。术语“白箱”是相对可视性而言:在继承方式中,父类的内部细节对子类可见。
对象组合是类继承之外的另一种复用选择。新的更复杂的功能可以通过组装或组合对象来获得。对象组合要求被组合的对象具有良好定义的接口。这种复用风格被称为黑箱复用(black-box reuse),因为对象的内部细节是不可见的。对象只以“黑箱”的形式出现。
继承和组合各有优缺点。类继承是在编译时刻静态定义的,且可直接使用,因为程序设计语言直接支持类继承。类继承可以较方便地改变被复用的实现。当一个子类重定义一些而不是全部操作时,它也能影响它所继承的操作,只要在这些操作中调用了被重定义的操作。
但是类继承也有一些不足之处。首先,因为继承在编译时刻就定义了,所以无法在运行时刻改变从父类继承的实现。更糟的是,父类通常至少定义了部分子类的具体表示。因为继承对子类揭示了其父类的实现细节,所以继承常被认为“破坏了封装性” 。子类中的实现与它的父类有如此紧密的依赖关系,以至于父类实现中的任何变化必然会导致子类发生变化。当你需要复用子类时,实现上的依赖性就会产生一些问题。如果继承下来的实现不适合解决新的问题,则父类必须重写或被其他更适合的类替换。这种依赖关系限制了灵活性并最终限制了复用性。一个可用的解决方法就是只继承抽象类,因为抽象类通常提供较少的实现。
对象组合是通过获得对其他对象的引用而在运行时刻动态定义的。组合要求对象遵守彼此的接口约定,进而要求更仔细地定义接口,而这些接口并不妨碍你将一个对象和其他对象一起使用。这还会产生良好的结果:因为对象只能通过接口访问,所以我们并不破坏封装性;只要类型一致,运行时刻还可以用一个对象来替代另一个对象;更进一步,因为对象的实现是基于接口写的,所以实现上存在较少的依赖关系。
对象组合对系统设计还有另一个作用,即优先使用对象组合有助于你保持每个类被封装,并被集中在单个任务上。这样类和类继承层次会保持较小规模,并且不太可能增长为不可控制的庞然大物。另一方面,基于对象组合的设计会有更多的对象 (而有较少的类),且系统的行为将依赖于对象间的关系而不是被定义在某个类中。
这导出了我们的面向对象设计的第二个原则:优先使用对象组合,而不是类继承。
④继承允许你根据基类的实现来定义派生类的实现。这种通过生成派生类的复用通常被称为白箱复用(white-box reuse)。术语“白箱”是相对可视性而言:在继承方式中,基类的内部细节对子类可见 。继承一定程度破坏了基类的封装,基类的改变,对派生类有很大的影响。派生类和基类间的依赖关系很强,耦合度高。
⑤对象组合是类继承之外的另一种复用选择。新的更复杂的功能可以通过组装或组合对象来获得。对象组合要求被组合的对象具有良好定义的接口。这种复用风格被称为黑箱复用(black-box reuse),因为对象的内部细节是不可见的。对象只以“黑箱”的形式出现。 组合类之间没有很强的依赖关系,耦合度低。优先使用对象组合有助于你保持每个类被封装。
⑥实际尽量多去用组合。组合的耦合度低,代码维护性好。不过继承也有用武之地的,有些关系就适合继承那就用继承,另外要实现多态,也必须要继承。类之间的关系可以用继承,可以用组合,就用组合。
9. 笔试面试题
(1)什么是菱形继承?菱形继承的问题是什么?
(2)什么是菱形虚拟继承?如何解决数据冗余和二义性的
(3)继承和组合的区别?什么时候用继承?什么时候用组合?
二、多态
前言
需要声明的,本节课件中的代码及解释都是在vs2013下的x86程序中,涉及的指针都是4bytes。如果要其他平台下,部分代码需要改动。比如:如果是x64程序,则需要考虑指针是8bytes问题等等
1. 多态的概念
1.1 概念
多态的概念:通俗来说,就是多种形态,具体点就是去完成某个行为,当不同的对象去完成时会产生出不同的状态。
举个栗子:
比如买票这个行为,当普通人买票时,是全价买票;学生买票时,是半价买票;军人买票时是优先买票。
再举个栗子:
最近为了争夺在线支付市场,支付宝年底经常会做诱人的扫红包-支付-给奖励金的活动。那么大家想想为什么有人扫的红包又大又新鲜8块、10块…,而有人扫的红包都是1毛,5毛…。其实这背后也是一个多态行为。支付宝首先会分析你的账户数据,比如你是新用户、比如你没有经常支付宝支付等等,那么你需要被鼓励使用支付宝,那么就你扫码金额 = random()%99;比如你经常使用支付宝支付或者支付宝账户中常年没钱,那么就不需要太鼓励你去使用支付宝,那么就你扫码金额 = random()%1;总结一下:同样是扫码动作,不同的用户扫得到的不一样的红包,这也是一种多态行为。
ps:支付宝红包问题纯属瞎编,大家仅供娱乐。
2. 多态的定义及实现
2.1多态的构成条件
多态是在不同继承关系的类对象,去调用同一函数,产生了不同的行为。比如Student继承了Person。Person对象买票全价,Student对象买票半价。
那么在继承中要构成多态还有两个条件:
(1)必须通过基类的指针或者引用调用虚函数
(2)被调用的函数必须是虚函数,且派生类必须对基类的虚函数进行重写

2.2 虚函数
虚函数:即被virtual修饰的类成员函数称为虚函数。
class Person {
public:
virtual void BuyTicket() { cout << "买票-全价" << endl; }
};
2.3虚函数的重写
虚函数的重写(覆盖):
派生类中有一个跟基类完全相同的虚函数(即派生类虚函数与基类虚函数的返回值类型、函数名字、参数列表完全相同),称子类的虚函数重写了基类的虚函数。
class Person {
public:
virtual void BuyTicket() { cout << "买票-全价" << endl; }
};
class Student : public Person {
public:
virtual void BuyTicket() { cout << "买票-半价" << endl; }
/*注意:在重写基类虚函数时,派生类的虚函数在不加virtual关键字时,虽然也可以构成重写(因为继承后基类的虚函数被继承下来了在派生类依旧保持虚函数属性),但是该种写法不是很规范,不建议这样使用
*/
/*void BuyTicket() { cout << "买票-半价" << endl; }*/
};
void Func(Person& p)
{
p.BuyTicket();
}
int main()
{
Person ps;
Student st;
Func(ps);
Func(st);
return 0;
}
虚函数重写的两个例外:
(1)协变(基类与派生类虚函数返回值类型不同)
派生类重写基类虚函数时,与基类虚函数返回值类型不同。即基类虚函数返回基类对象的指针或者引用,派生类虚函数返回派生类对象的指针或者引用时,称为协变。(了解)
class A {};
class B : public A {};
class Person {
public:
virtual A* f() { return new A; }
};
class Student : public Person {
public:
virtual B* f() { return new B; }
};
(2)析构函数的重写(基类与派生类析构函数的名字不同)
如果基类的析构函数为虚函数,此时派生类析构函数只要定义,无论是否加virtual关键字,都与基类的析构函数构成重写,虽然基类与派生类析构函数名字不同。虽然函数名不相同,看起来违背了重写的规则,其实不然,这里可以理解为编译器对析构函数的名称做了特殊处理,编译后析构函数的名称统一处理成destructor。
class Person {
public:
virtual ~Person() { cout << "~Person()" << endl; }
};
class Student : public Person {
public:
virtual ~Student() { cout << "~Student()" << endl; }
};
// 只有派生类Student的析构函数重写了Person的析构函数,下面的delete对象调用析构函数,才能构成多态,才能保证p1和p2指向的对象正确的调用析构函数。
int main()
{
Person* p1 = new Person;
Person* p2 = new Student;
delete p1;
delete p2;
return 0;
}
2.4 C++11 override 和 final
从上面可以看出,C++对函数重写的要求比较严格,但是有些情况下由于疏忽,可能会导致函数名字母次序写反而无法构成重载,而这种错误在编译期间是不会报出的,只有在程序运行时没有得到预期结果才来debug会得不偿失,因此:C++11提供了override和final两个关键字,可以帮助用户检测是否重写。
(1) final:修饰虚函数,表示该虚函数不能再被继承
class Car
{
public:
virtual void Drive() final {}
};
class Benz :public Car
{
public:
virtual void Drive() { cout << "Benz-舒适" << endl; }
};
(2)override: 检查派生类虚函数是否重写了基类某个虚函数,如果没有重写编译报错。
class Car {
public:
virtual void Drive() {}
};
class Benz :public Car {
public:
virtual void Drive() override { cout << "Benz-舒适" << endl; }
};
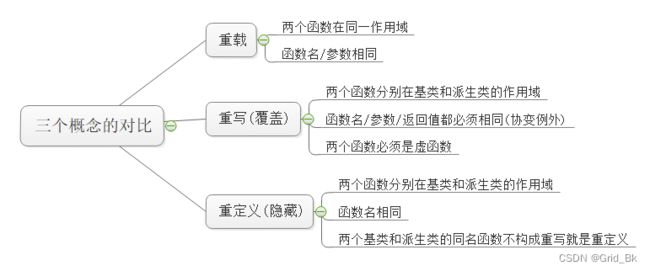
2.5 重载、覆盖(重写)、隐藏(重定义)的对比
3. 抽象类
3.1 概念
在虚函数的后面写上 =0 ,则这个函数为纯虚函数。包含纯虚函数的类叫做抽象类(也叫接口类),抽象类不能实例化出对象。派生类继承后也不能实例化出对象,只有重写纯虚函数,派生类才能实例化出对象。纯虚函数规范了派生类必须重写,另外纯虚函数更体现出了接口继承。
class Car
{
public:
virtual void Drive() = 0;
};
class Benz :public Car
{
public:
virtual void Drive()
{
cout << "Benz-舒适" << endl;
}
};
class BMW :public Car
{
public:
virtual void Drive()
{
cout << "BMW-操控" << endl;
}
};
void Test()
{
Car* pBenz = new Benz;
pBenz->Drive();
Car* pBMW = new BMW;
pBMW->Drive();
}
3.2 接口继承和实现继承
普通函数的继承是一种实现继承,派生类继承了基类函数,可以使用函数,继承的是函数的实现。虚函数的继承是一种接口继承,派生类继承的是基类虚函数的接口,目的是为了重写,达成多态,继承的是接口。所以如果不实现多态,不要把函数定义成虚函数。
4. 多态的原理
4.1虚函数表
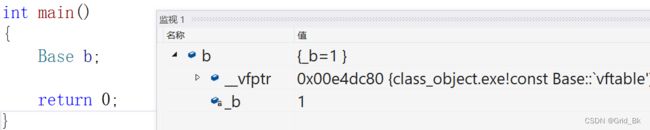
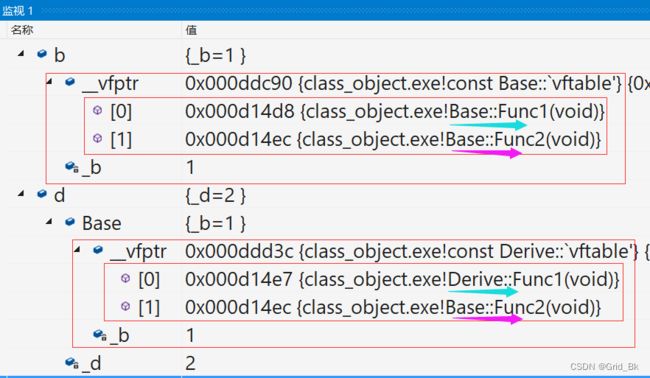
通过观察测试我们发现b对象是8bytes,除了_b成员,还多一个__vfptr放在对象的前面(注意有些平台可能会
放到对象的最后面,这个跟平台有关),对象中的这个指针我们叫做虚函数表指针(v代表virtual,f代表
function)。一个含有虚函数的类中都至少都有一个虚函数表指针,因为虚函数的地址要被放到虚函数表中,
虚函数表也简称虚表,。那么派生类中这个表放了些什么呢?我们接着往下分析
通过观察和测试,我们发现了以下几点问题:
- 派生类对象d中也有一个虚表指针,d对象由两部分构成,一部分是父类继承下来的成员,虚表指针也就
是存在部分的另一部分是自己的成员。 - 基类b对象和派生类d对象虚表是不一样的,这里我们发现Func1完成了重写,所以d的虚表中存的是重
写的Derive::Func1,所以虚函数的重写也叫作覆盖,覆盖就是指虚表中虚函数的覆盖。重写是语法的
叫法,覆盖是原理层的叫法。 - 另外Func2继承下来后是虚函数,所以放进了虚表,Func3也继承下来了,但是不是虚函数,所以不会
放进虚表。 - 虚函数表本质是一个存虚函数指针的指针数组,这个数组最后面放了一个nullptr。
- 总结一下派生类的虚表生成:a.先将基类中的虚表内容拷贝一份到派生类虚表中 b.如果派生类重写了基
类中某个虚函数,用派生类自己的虚函数覆盖虚表中基类的虚函数 c.派生类自己新增加的虚函数按其在
派生类中的声明次序增加到派生类虚表的最后。 - 这里还有一个童鞋们很容易混淆的问题:虚函数存在哪的?虚表存在哪的? 答:虚函数存在虚表,虚表
存在对象中。注意上面的回答的错的。但是很多童鞋都是这样深以为然的。注意虚表存的是虚函数指
针,不是虚函数,虚函数和普通函数一样的,都是存在代码段的,只是他的指针又存到了虚表中。另外
对象中存的不是虚表,存的是虚表指针。那么虚表存在哪的呢?实际我们去验证一下会发现vs下是存在
代码段的,Linux g++下大家自己去验证?
4.2多态的原理
上面分析了这个半天了那么多态的原理到底是什么?还记得这里Func函数传Person调用的
Person::BuyTicket,传Student调用的是Student::BuyTicket

- 观察下图的红色箭头我们看到,p是指向mike对象时,p->BuyTicket在mike的虚表中找到虚函数是
Person::BuyTicket。 - 观察下图的蓝色箭头我们看到,p是指向johnson对象时,p->BuyTicket在johson的虚表中找到虚函数
是Student::BuyTicket。 - 这样就实现出了不同对象去完成同一行为时,展现出不同的形态。
- 反过来思考我们要达到多态,有两个条件,一个是虚函数覆盖,一个是对象的指针或引用调用虚函数。
反思一下为什么? - 再通过下面的汇编代码分析,看出满足多态以后的函数调用,不是在编译时确定的,是运行起来以后到
对象的中取找的。不满足多态的函数调用时编译时确认好的。

4.3 动态绑定与静态绑定
- 静态绑定又称为前期绑定(早绑定),在程序编译期间确定了程序的行为,也称为静态多态,比如:函数
重载 - 动态绑定又称后期绑定(晚绑定),是在程序运行期间,根据具体拿到的类型确定程序的具体行为,调用
具体的函数,也称为动态多态。 - 本小节之前(5.2小节)买票的汇编代码很好的解释了什么是静态(编译器)绑定和动态(运行时)绑定。
5. 单继承和多继承关系中的虚函数表
需要注意的是在单继承和多继承关系中,下面我们去关注的是派生类对象的虚表模型,因为基类的虚表模型
前面我们已经看过了,没什么需要特别研究的
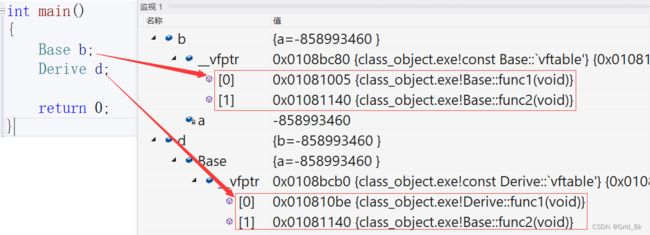
5.1 单继承中的虚函数表
观察下图中的监视窗口中我们发现看不见func3和func4。这里是编译器的监视窗口故意隐藏了这两个函数,
也可以认为是他的一个小bug。那么我们如何查看d的虚表呢?下面我们使用代码打印出虚表中的函数。
5.2 多继承中的虚函数表
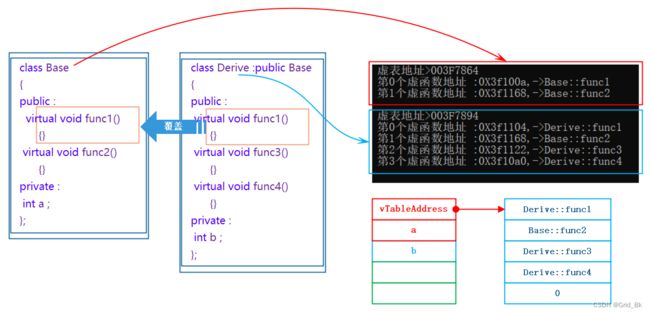
观察下图可以看出:多继承派生类的未重写的虚函数放在第一个继承基类部分的虚函数表中

5.3. 菱形继承、菱形虚拟继承
实际中我们不建议设计出菱形继承及菱形虚拟继承,一方面太复杂容易出问题,另一方面这样的模型,访问
基类成员有一定得性能损耗。所以菱形继承、菱形虚拟继承我们的虚表我们就不看了,一般我们也不需要研
究清楚,因为实际中很少用。如果好奇心比较强的宝宝,可以去看下面的两篇链接文章。
- C++ 虚函数表解析
- C++ 对象的内存布局
6. 继承和多态常见的面试问题
6.1 概念查考
- 下面哪种面向对象的方法可以让你变得富有( )
A: 继承 B: 封装 C: 多态 D: 抽象 - ( )是面向对象程序设计语言中的一种机制。这种机制实现了方法的定义与具体的对象无关,而对方法的
调用则可以关联于具体的对象。
A: 继承 B: 模板 C: 对象的自身引用 D: 动态绑定 - 面向对象设计中的继承和组合,下面说法错误的是?()
A:继承允许我们覆盖重写父类的实现细节,父类的实现对于子类是可见的,是一种静态复用,也称为
白盒复用
B:组合的对象不需要关心各自的实现细节,之间的关系是在运行时候才确定的,是一种动态复用,也
称为黑盒复用
C:优先使用继承,而不是组合,是面向对象设计的第二原则
D:继承可以使子类能自动继承父类的接口,但在设计模式中认为这是一种破坏了父类的封装性的表现 - 以下关于纯虚函数的说法,正确的是( )
A:声明纯虚函数的类不能实例化 B:声明纯虚函数的类成虚基类
C:子类必须实现基类的 D:纯虚函数必须是空函数 - 关于虚函数的描述正确的是( )
A:派生类的虚函数与基类的虚函数具有不同的参数个数和类型 B:内联函数不能是虚函数
C:派生类必须重新定义基类的虚函数 D:虚函数可以是一个static型的函数 - 关于虚表说法正确的是( )
A:一个类只能有一张虚表
B:基类中有虚函数,如果子类中没有重写基类的虚函数,此时子类与基类共用同一张虚表
C:虚表是在运行期间动态生成的
D:一个类的不同对象共享该类的虚表 - 假设A类中有虚函数,B继承自A,B重写A中的虚函数,也没有定义任何虚函数,则( )
A:A类对象的前4个字节存储虚表地址,B类对象前4个字节不是虚表地址
B:A类对象和B类对象前4个字节存储的都是虚基表的地址
C:A类对象和B类对象前4个字节存储的虚表地址相同
D:A类和B类中的内容完全一样,但是A类和B类使用的不是同一张虚表 - 下面程序输出结果是什么? ()
A:class A class B class C class D B:class D class B class C class A
C:class D class C class B class A D:class A class C class B class D
9. 多继承中指针偏移问题?下面说法正确的是( )
A:p1 == p2 == p3 B:p1 < p2 < p3 C:p1 == p3 != p2 D:p1 != p2 != p3
10. 以下程序输出结果是什么()
A: A->0 B: B->1 C: A->1 D: B->0 E: 编译出错 F: 以上都不正确
6.2 问答题
- 什么是多态?答:参考本节课件内容
- 什么是重载、重写(覆盖)、重定义(隐藏)?答:参考本节课件内容
- 多态的实现原理?答:参考本节课件内容
- inline函数可以是虚函数吗?答:不能,因为inline函数没有地址,无法把地址放到虚函数表中。
- 静态成员可以是虚函数吗?答:不能,因为静态成员函数没有this指针,使用类型::成员函数的调用方式
无法访问虚函数表,所以静态成员函数无法放进虚函数表。 - 构造函数可以是虚函数吗?答:不能,因为对象中的虚函数表指针是在构造函数初始化列表阶段才初始
化的。 - 析构函数可以是虚函数吗?什么场景下析构函数是虚函数?答:可以,并且最好把基类的析构函数定义
成虚函数。参考本节课件内容 - 对象访问普通函数快还是虚函数更快?答:首先如果是普通对象,是一样快的。如果是指针对象或者是
引用对象,则调用的普通函数快,因为构成多态,运行时调用虚函数需要到虚函数表中去查找。 - 虚函数表是在什么阶段生成的,存在哪的?答:虚函数表是在编译阶段就生成的,一般情况下存在代码
段(常量区)的。 - C++菱形继承的问题?虚继承的原理?答:参考继承课件。注意这里不要把虚函数表和虚基表搞混了。
- 什么是抽象类?抽象类的作用?答:参考(3.抽象类)。抽象类强制重写了虚函数,另外抽象类体现出
了接口继承关系。
三、二叉树进阶
1. 内容安排说明
二叉树在前面C数据结构阶段已经讲过,本节取名二叉树进阶是因为:
- map和set特性需要先铺垫二叉搜索树,而二叉搜索树也是一种树形结构
- 二叉搜索树的特性了解,有助于更好的理解map和set的特性
- 二叉树中部分面试题稍微有点难度,在前面讲解大家不容易接受,且时间长容易忘
- 有些OJ题使用C语言方式实现比较麻烦
因此本节借二叉树搜索树,对二叉树部分进行收尾总结。
2. 二叉搜索树
2.1 二叉搜索树概念
二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
它的左右子树也分别为二叉搜索树

int a [] = {5,3,4,1,7,8,2,6,0,9};
2.2 二叉搜索树操作
- 二叉搜索树的查找

- 二叉搜索树的插入
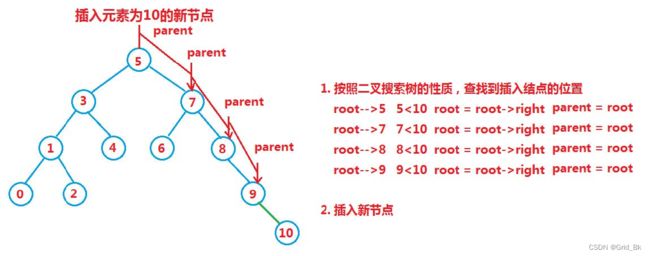
插入的具体过程如下:
a. 树为空,则直接插入

b. 树不空,按二叉搜索树性质查找插入位置,插入新节点
3. 二叉搜索树的删除
首先查找元素是否在二叉搜索树中,如果不存在,则返回, 否则要删除的结点可能分下面四种情况:
a. 要删除的结点无孩子结点
b. 要删除的结点只有左孩子结点
c. 要删除的结点只有右孩子结点
d. 要删除的结点有左、右孩子结点
看起来有待删除节点有4中情况,实际情况a可以与情况b或者c合并起来,因此真正的删除过程如下:
情况b:删除该结点且使被删除节点的双亲结点指向被删除节点的左孩子结点
情况c:删除该结点且使被删除节点的双亲结点指向被删除结点的右孩子结点
情况d:在它的右子树中寻找中序下的第一个结点(关键码最小),用它的值填补到被删除节点中,
再来处理该结点的删除问题
2.3 二叉搜索树的实现
2.4 二叉搜索树的应用
- K模型:K模型即只有key作为关键码,结构中只需要存储Key即可,关键码即为需要搜索到的值。
比如:给一个单词word,判断该单词是否拼写正确,具体方式如下:
以单词集合中的每个单词作为key,构建一棵二叉搜索树
在二叉搜索树中检索该单词是否存在,存在则拼写正确,不存在则拼写错误。 - KV模型:每一个关键码key,都有与之对应的值Value,即
活中非常常见:比如英汉词典就是英文与中文的对应关系,通过英文可以快速找到与其对应的中文,英
文单词与其对应的中文
单词就可快速找到其出现的次数,单词与其出现次数就是
比如:实现一个简单的英汉词典dict,可以通过英文找到与其对应的中文,具体实现方式如下:
<单词,中文含义>为键值对构造二叉搜索树,注意:二叉搜索树需要比较,键值对比较时只比较
Key
查询英文单词时,只需给出英文单词,就可快速找到与其对应的key
2.5 二叉搜索树的性能分析
插入和删除操作都必须先查找,查找效率代表了二叉搜索树中各个操作的性能。
对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的
深度的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:

最优情况下,二叉搜索树为完全二叉树,其平均比较次数为:log2N
最差情况下,二叉搜索树退化为单支树,其平均比较次数为:N/2
问题:如果退化成单支树,二叉搜索树的性能就失去了。那能否进行改进,不论按照什么次序插入关键码,
都可以是二叉搜索树的性能最佳?
3. 二叉树进阶面试题(OJ题)
- 二叉树创建字符串。OJ链接
- 二叉树的分层遍历1。OJ链接
- 二叉树的分层遍历2。OJ链接
- 给定一个二叉树, 找到该树中两个指定节点的最近公共祖先 。OJ链接
- 二叉树搜索树转换成排序双向链表。OJ链接
- 根据一棵树的前序遍历与中序遍历构造二叉树。 OJ链接
- 根据一棵树的中序遍历与后序遍历构造二叉树。OJ链接
- 二叉树的前序遍历,非递归迭代实现 。OJ链接
- 二叉树中序遍历 ,非递归迭代实现。OJ链接
- 二叉树的后序遍历 ,非递归迭代实现。OJ链接