Python数据结构与算法学习笔记03
6 算法进阶
6.1 贪心算法
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
贪心算法并不保证会得到最优解,但是在某些问题上贪心算法的解就是最优解。要会判断一个问题能否用贪心算法来计算。
6.1.1 找零问题
假设商店老板需要找零n元钱,钱币的面额有:100元、50元、20元、5元、1元,如何找零使得所需钱币的数量最少?
t = [100,50,20,5,1]
def change(t,n):
m = [0 for _ in range(len(t))]
for i ,money in enumerate(t):
m[i] = n // money
n = n % money
return m,n
print(change(t,376))
6.1.2 背包问题
一个小偷在某个商店发现有n个商品,第i个商品价值vi元,重wi千克。他希望拿走的价值尽量高,但他的背包最多只能容纳W千克的东西。他应该拿走哪些商品?
- 0-1背包:对于一个商品,小偷要么把它完整拿走,要么留下。不能只拿走一部分,或把一个商品拿走多次。(商品为金条)
- 分数背包:对于一个商品,小偷可以拿走其中任意一部分。(商品为金砂)
举例: - 商品1:v1=60,w1=10
- 商品2:v2=100,w2=20
- 商品3:v3=120,w3=30
- 背包容量:W=50
对于0-1背包和分数背包,贪心算法是否都能得到最优解?为什么?
#分数背包
goods = [(60, 10),(100, 20),(120, 30)]
goods.sort(key=lambda x: x[0]/x[1],reverse=True) # 每个商品元组表示(价格,重量
def fractional_backpack(goods,w):
m = [0 for _ in range(len(goods))]
total_v = 0
for i,(price,weight) in enumerate(goods):
if w >= weight:
m[i] = 1
total_v += price
w -= weight
else:
m[i] = w / weight
total_v += m[i] * price
w = 0
break
return total_v,m
print(fractional_backpack(goods,50))
6.1.3数字拼接问题
有n个非负整数,将其按照字符串拼接的方式拼接为一个整数。如何拼接可以使得得到的整数最大?
例:32,94,128,1286,6,71可以拼接出的最大整数为94716321286128.
from functools import cmp_to_key
li = [32, 94, 128, 1286, 6, 71]
def xy_cmp(x, y):
if x+y < y+x:
return 1
elif x+y > y+x:
return -1
else:
return 0
def number_join(li):
li = list(map(str, li))
li.sort(key=cmp_to_key(xy_cmp))
return "".join(li)
print(number_join(li))
6.1.4活动选择问题
假设有n个活动,这些活动要占用同一片场地,而场地在某时刻只能供一个活动使用。
每个活动都有一个开始时间si和结束时间fi(题目中时间以整数表示),表示活动在[si,fi)区间占用场地。
问:安排哪些活动能够使该场地举办的活动的个数最多?
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| si | 1 | 3 | 0 | 5 | 3 | 5 | 6 | 8 | 8 | 2 | 12 |
| fi | 4 | 5 | 6 | 7 | 9 | 9 | 10 | 11 | 12 | 14 | 16 |
贪心结论:最先结束的活动一定是最优解的一部分。
证明:假设a是所有活动中最先结束的活动,b是最优解中最先结束的活动。
- 如果a=b,结论成立。
- 如果a≠b,则b的结束时间一定晚于a的结束时间,则此时用a替换掉最优解中的b,a一定不与最优解中的其他活动时间重叠,因此替换后的解也是最优解。
activities = [(1,4), (3,5), (0,6), (5,7), (3,9), (5,9), (6,10), (8,11), (8,12), (2,14), (12,16)]
#保证活动是按照结束时间排好序的
activities.sort(key=lambda x:x[1])
def activity_selection(a):
res = [a[0]]
for i in range(1,len(a)):
if a[i][0] >= res[-1][1]: #当前活动的开始时间大于等于最后一个入选活动的结束时间
#不冲突
res.append(a[i])
return res
print(activity_selection(activities))
6.2 动态规划算法
从斐波那契数列看动态规划
斐波那契数列:Fn=Fn-1+Fn-2
练习:使用递归和非递归的方法来求解斐波那契数列的第n项。
#递归——子问题的重复计算
def fibnacci(n):
if n == 1 or n == 2:
return 1
else:
return fibnacci(n-1) + fibnacci(n-2)
#非递归——动态规划(DP)的思想:递推式+重复子问题
def fibnacci_no_recurision(n):
f = [0,1,1]
if n > 2:
for i in range(n-2):
num = f[-1] + f[-2]
f.append(num)
return f[n]
print(fibnacci(10))
print(fibnacci_no_recurision(100))
6.2.1 钢条切割问题
某公司出售钢条,出售价格与钢条长度之间的关系如下表:
| 长度i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 价格pi | 1 | 5 | 8 | 9 | 10 | 17 | 17 | 20 | 24 | 30 |
问题:现有一段长度为n的钢条和上面的价格表,求切割钢条方案,使得总收益最大。
长度为4的钢条的所有切割方案如下:(c方案最优)
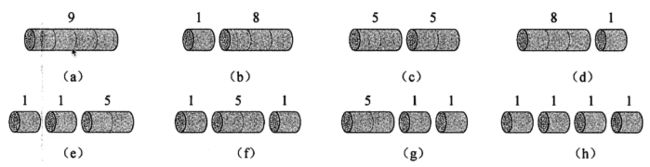
思考:长度为n的钢条的不同切割方案有几种?2n-1

递推式
设长度为n的钢条切割后最优收益值为rn,可以得出递推式:
rn=max(pn,r1+rn-1,r2+rn-2,···,rn-1+r1)
第一个参数pn表示不切割。
其他n-1个参数分别表示另外n-1种不同切割方案,对方案i=1,2,···,n-1
- 将钢条切割为长度为i和n-i两段
- 方案i的收益为切割两段的最优收益之和
考察所有的i,选择其中收益最大的方案。
最优子结构
可以将求解规模为n的原问题,划分为规模更小的子问题:完成一次切割后,可以将产生的两段钢条看成两个独立的钢条切割问题。
组合两个子问题的最优解,并在所有可能的两段切割方案中选取组合收益最大的,构成原问题的最优解。
钢条切割满足最优子结构:问题的最优解由相关子问题的最优解组合而成,这些子问题可以独立求解。
钢条切割问题还存在更简单的递归求解方法: - 从钢条的左边切割下长度为i的一段,只对右边剩下的一段继续进行切割,左边的不再切割。
- 递推式简化为rn=max1≤i≤n(pi+rn-i)
- 不做切割的方案就可以描述为:左边一段长度为n,收益为pn,剩余一段长度为0,收益为r0=0.
p = [0, 1, 5, 8, 9, 10, 17, 17, 20, 24, 30]
def cut_rod_recurision_1(p,n):
if n == 0:
return 0
else:
res = p[n]
for i in range(1, n):
res = max(res, cut_rod_recurision_1(p,i) + cut_rod_recurision_1(p,n-i))
return res
def cut_rod_recurision_2(p, n):
if n == 0:
return 0
else:
res = 0
for i in range(1, n+1):
res = max(res, p[i] + cut_rod_recurision_2(p,n-i))
return res
print(cut_rod_recurision_1(p,9))
print(cut_rod_recurision_2(p,9))
递归算法由于重复求解相同子问题,效率极低。
动态规划的思想:
- 每个子问题只求解一次,保存求解结果
- 之后需要此问题时,只需查找保存的结果
def cut_rod_dp(p,n):
r = [0]
for i in range(1, n+1):
res = 0
for j in range(1, i+1):
res = max(res, p[j] + r[i - j])
r.append(res)
return r[n]
print(cut_rod_dp(p,10))
如何修改动态规划算法,使其不仅输出最优解,还输出最优切割方案?

def cut_rod_extend(p, n):
r = [0]
s = [0]
for i in range(1,n+1):
res_r = 0 #价格的最大值
res_s = 0 #价格最大值对应方案的左边不切割部分的长度
for j in range(1, i+1):
if p[j] + r[i - j] > res_r:
res_r = p[j] + r[i - j]
res_s = j
r.append(res_r)
s.append(res_s)
return r[n],s
def cut_rod_solution(p,n):
r, s = cut_rod_extend(p, n)
ans = []
while n > 0:
ans.append(s[n])
n -= s[n]
return ans
r,s = cut_rod_extend(p,10)
#print(s)
print(cut_rod_solution(p,9))
6.2.2 最长公共子序列
一个序列的子序列是在该序列中删去若干元素后得到的序列。
例:“ABCD”和“BDF”都是“ABCDEFG”的子序列。
最长公共子序列(LCS)问题:给定两个序列X和Y,求X和Y长度最大的公共子序列。
例:X = “ABBCBDE” Y = “DBBCDB” LCS(X,Y) = “BBCD”
应用场景:字符串相似度比对

例如:要求a = “ABCBDAB” 与 b = “BDCABA” 的LCS:
由于最后一位“B”≠“A”:
因此LCS(a,b)应该来源于LCS(a[:-1],b)与LCS(a,b[:-1])中更大的那一个。

def lcs_length(x, y):
m = len(x)
n = len(y)
c = [[0 for _ in range(n+1)] for _ in range(m+1)]
for i in range(1,m+1):
for j in range(1,n+1):
if x[i-1] == y[j-1]: # i j 位置上的字符匹配的时候,来自于左上方+1
c[i][j] = c[i-1][j-1] + 1
else:
c[i][j] = max(c[i-1][j],c[i][j-1])
# for _ in c:
# print(_)
return c[m][n]
def lcs(x,y):
m = len(x)
n = len(y)
c = [[0 for _ in range(n+1)] for _ in range(m+1)]
b = [[0 for _ in range(n+1)] for _ in range(m+1)] #1 左上方 2 上方 3 左方
for i in range(1,m+1):
for j in range(1,n+1):
if x[i-1] == y[j-1]: #i j 位置上的字符匹配的时候,来自于左上方—+1
c[i][j] = c[i-1][j-1] + 1
b[i][j] = 1
elif c[i-1][j] > c[i][j-1]:#来自于上方
c[i][j] = c[i-1][j]
b[i][j] = 2
else:
c[i][j] = c[i][j-1]
b[i][j] = 3
return c[m][n],b
def lcs_trackback(x, y):
c,b = lcs(x,y)
i = len(x)
j = len(y)
res = []
while i > 0 and j > 0:
if b[i][j] == 1: #来自左上方=>匹配
res.append(x[i-1])
i -= 1
j -= 1
elif b[i][j] == 2: #来自于上方=>不匹配
i -= 1
else: # == 3 来自于左方=>不匹配
j -= 1
return "".join(reversed(res))
print(lcs_length("ABCBDAB","BDCABA"))
c, b = lcs("ABCBDAB","BDCABA")
for _ in b:
print(_)
print(lcs_trackback("ABCBDAB","BDCABA"))
6.3 欧几里得算法
6.3.1 最大公约数
约数:如果整数a能被整数b整除,那么a叫做b的倍数,b叫做a的约数。
给定两个整数a,b,两个数的所有公共约数中的最大值即为最大公约数(Greatest Common Divisor,GCD)
例:12与16的最大公约数是4.
欧几里得算法:gcd(a,b) = gcd(b,a mod b)
例:gcd(60,21) = gcd(21,18) = gcd(18,3) = gcd(3,0) = 3
def gcd(a,b):
if b == 0:
return a
else:
return gcd(b, a % b)
def gcd2(a,b):
while b > 0:
r = a % b
a = b
b = r
return a
print(gcd(12,16))
print(gcd2(12,16))
6.3.2 实现分数计算
利用欧几里得算法实现一个分数类,支持分数的四则运算。
class Fraction:
def __init__(self,a,b):
self.a = a
self.b = b
x = self.gcd(a,b)
self.a /= x
self.b /= x
def gcd(self, a, b):
while b > 0:
r = a % b
a = b
b = r
return a
def zgs(self, a, b):
x = self.gcd(a,b)
return a * b / x
def __add__(self, other):
a = self.a
b = self.b
c = other.a
d = other.b
fenmu = self.zgs(b,d)
fenzi = a * fenmu / b + c * fenmu / d
return Fraction(fenzi,fenmu)
def __str__(self):
return "%d/%d" % (self.a,self.b)
#
# f = Fraction(30,15)
# print(f)
a = Fraction(1,3)
b = Fraction(1,2)
print(a+b)