贝叶斯超参数寻优(附Python代码,scikit-optimize)
文章目录
- 引言
- 工程原理
-
- 问题
- 算法实现
- scikit-optimize
-
- BayesSearchCV
-
- 代码 (SVM)为例
-
- 定义搜索空间
- 设置BayesSearchCV
- 拟合,查看效果
- 参数解释
- Bayes Optimization
-
- 代码(XGBoost)为例
-
- 定义搜索空间
- 目标函数
- 选择surrogate函数,进行寻优
- 结果、可视化
- 结语
- References
声明:本文目的是让读者最快速上手超参数贝叶斯优化,所以不多涉及细节和数学内容
引言
超参数调参是机器学习中不可或缺的过程,但实际应用中,往往因为数据集过大,使得超参数调参变得非常困难。现在常用的超参数寻优方法有:1、Random search(随机搜索);2、Grid search(网格搜索);3、Bayesian optimization(贝叶斯优化)。Ramdom search时间开销小,但平均效果可能不佳。Grid search时间开销大,平均效果好。Bayesian optimizaiton 则是综合了两者的优点,综合效果可能会更好。
工程原理
想要快速的学习一个算法,我们可以从其工程原理入手,去了解算法是工作的原理是什么,是一个什么样的过程。
问题
我们可以将超参数搜索理解成如下图的一个过程:我们输入一组超参数,然后得到一个output(一般是performance),但是我们不知道这个超参数和output的函数关系。不难发现,这其实就是一个关于超参数和performance的黑箱子问题。
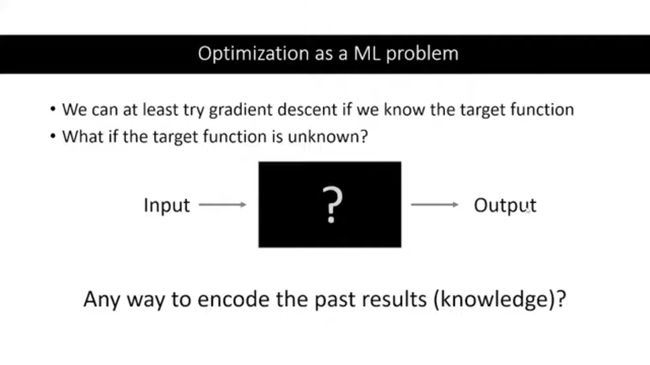
那怎么样能够提高寻找最佳超参数的效率呢?
答:如果我们能知道“超参数”和“output(perfromance)”的函数关系,那我们就有很多种方法求到output的最大值了。但问题在于,该如何找到这个函数呢?
算法实现
首先我们定义两个函数:
1、surrogate(代理/代替)函数:用于拟合超参数和performance关系的函数
2、acquisition函数:用于确定下一次迭代要尝试什么超参数
思路(如下图):
是一个迭代的过程
Step1:首先随机尝试一些点(超参数),得到他们的output
Step2:使用surrogate函数去拟合Step1的结果
Step3:根据acquisition函数确定下一次迭代要尝试的点
Step4:不断尝试,直到满足停止条件
细节
1、如何选择surrogate函数?
答:一般使用gaussian process regression、Random Forest Regression,the choice in Hyperopt, the Tree Parzen Estimator (TPE) 进行拟合,得到的结果是一个带有置信区间的。
2、如何选择acquisition函数
答:一般使用expected improvement函数,还有许多函数(如下图)可以使用的,每个函数代表着不同的策略。但无论是哪个函数,都是基于上一步surrogate的结果

更多数学内容参考:https://static.sigopt.com/b/20a144d208ef255d3b981ce419667ec25d8412e2/static/pdf/SigOpt_Bayesian_Optimization_Primer.pdf
scikit-optimize
我们可以利用scikit-optimize包实现贝叶斯超参数寻优。其中,提供有两个函数:1、BayesSearchCV;2、自己选择的surrogate函数
BayesSearchCV
这是一个基于CV实现的贝叶斯超参数寻优,是一个封装好的函数,调用非常方便。
主要步骤:
1、定义搜索空间
2、设置BayesSearchCV
3、拟合数据,查看结果
代码 (SVM)为例
定义搜索空间
# define search space
#svm
params = dict()
params['C'] = (1e-6, 100.0, 'log-uniform')
params['gamma'] = (1e-6, 100.0, 'log-uniform')
params['degree'] = (1,5)
params['kernel'] = ['linear', 'poly', 'rbf', 'sigmoid']
设置BayesSearchCV
使用默认的scoring时候
from sklearn.model_selection import RepeatedStratifiedKFold
from skopt import BayesSearchCV
from sklearn.svm import SVC
# define evaluation
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=1, random_state=SEED)
# define the search
search = BayesSearchCV(estimator=SVC(), search_spaces=params, n_jobs=-1, cv=cv)
使用自己设置的scoring
要求设置的函数:1、传入参数:estimator、X(训练集)、y(测试集);2、返回的是一个数值,这个数值就是score
def evaluate_model(estimator,X,y):
# configure the model with specific hyperparameters
acc = cross_val_score(estimator, X, y, scoring="accuracy",cv=cv).mean()#评测分数是cv后的结果
return acc
from sklearn.model_selection import RepeatedStratifiedKFold
from skopt import BayesSearchCV
from sklearn.svm import SVC
# define evaluation
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=1, random_state=SEED)
# define the search
search = BayesSearchCV(estimator=SVC(),scoring=evaluate_model,search_spaces=params, n_jobs=-1, cv=cv)
拟合,查看效果
# perform the search
search.fit(x_train, y_train)
# report the best result
print(search.best_score_)
print(search.best_params_)
print(search.cv_results_)
参数解释
链接:https://scikit-optimize.github.io/stable/modules/generated/skopt.BayesSearchCV.html
常用参数:
| 参数 | 范围 | 作用 |
|---|---|---|
| estimator | sklearn中的学习器,且要带有score或者scoring参数 | 你要调参的模型 |
| search_spaces | estimator所支持的超参数 | 控制超参数范围 |
| n_iter | int,default=50 | 选择要尝试的超参数组合数目,越多越精准,耗费越大 |
| optimizer_kwargs | {‘base_estimator’: ‘RF’},default= Gaussian Process(应使用这种字典的方式传参) | 选择surrogate函数 |
| scoring | 一个评分函数,可以自定义,传入的可以是字符串、函数。如果没传入,则默认是estimator中的score方法 | 相当于超参数寻优的目标函数,自定义你想要的寻优结果的标准 |
| n_jobs | int | 利用的内核数 |
| refit | boolean:True or False | 是否需要使用超参数去拟合整个数据集。如果不,则不能用这个BayesSearchCV的结果(没有fit的过程)去预测 |
Bayes Optimization
相比于BayesSearchCV,通过Bayes Optimization的方法能够有更高的灵活性和个性化订制。你可以发现,在BayesSearchCV中,没有参数是用于设置acquisition函数的。但使用Bayes Optimization完全可以解决这个问题
主要步骤:
1、设置搜索空间
2、设置目标函数
3、选择surrogate函数,进行拟合
4、查看结果
代码(XGBoost)为例
定义搜索空间
# define the space of hyperparameters to search
# XGboost
SPACE = [
skopt.space.Real(0.01, 0.5, name='learning_rate', prior='log-uniform'),
skopt.space.Integer(1, 30, name='max_depth'),
skopt.space.Integer(2, 100, name='num_leaves'),
skopt.space.Integer(10, 1000, name='min_data_in_leaf'),
skopt.space.Real(0.1, 1.0, name='feature_fraction', prior='uniform'),
skopt.space.Real(0.1, 1.0, name='subsample', prior='uniform')]
目标函数
注意:为什么返回的是acc的负数?因为在算法的训练过程中,目标是使得目标函数值越低。但我们这里选用的是accuracy,应该是越高越好。所以设置为负数,保证目标是使得acc越高。
(这里和BayesSearchCV中的scoring不一样,scoring在训练中是越高越好)
我们可以通过cv的方式计算目标函数值,这样也能达到cv的效果。
# 为什么是负号?
#因为scikit-optimize的训练过程是,使得目标函数最小。如果设置的是acc,则应该反过来
from sklearn.model_selection import cross_val_score
from sklearn.svm import SVC
@skopt.utils.use_named_args(search_space)
def evaluate_model(**params):
# configure the model with specific hyperparameters
clf = SVC(**params)
acc = cross_val_score(clf, x_train, y_train, scoring="accuracy",cv=5).mean()#评测分数是cv后的结果
return -acc
选择surrogate函数,进行寻优
我们可以根据自己的需要选择surrogate函数,也可以选择不同的acquisition函数。
#可选有:gp_minimize,dummy_minimize,forest_minimize,gbrt_minimize
#参数:https://scikit-optimize.github.io/stable/modules/generated/skopt.gp_minimize.html
from skopt import gp_minimize
result = gp_minimize(
func=evaluate_model,
dimensions=search_space,
acq_func="gp_hedge",#acquisition函数
n_calls=100,
random_state=SEED,
verbose=True,
n_jobs=-1,
)
结果、可视化
# summarizing finding:
print('Best Accuracy: %.3f' % (result.fun))
print('Best Parameters: %s' % (result.x))
#参考:https://scikit-optimize.github.io/stable/modules/plots.html
from skopt.plots import plot_convergence,plot_evaluations,plot_objective,plot_regret
plot_convergence(result)
plot_evaluations(result)
plot_objective(result)
plot_regret(result)
结语
使用基于贝叶斯的调参方式能够加速调参的速度,达到兼顾“速度”和“效果”的目标。但在实际应用中,基于贝叶斯的调参方式是否能够比Grid Search表现的更好,这还需要画上一个问号。Anyway,BayesSearch确实值得去尝试。
Python中可以利用scikit-optimize实现BayesSearch。其中有两个方法:BayesSearchCV和自定义surrogate函数。BayesSearchCV提高更方便快捷的使用,但因为封装程度大,导致自定义程度低,不支持选择acquisition函数。自定义surrogate函数的方法,自定义程度高,但运用比较复杂,需要有一定的代码能力。
(挖个坑:scikit-optimize中的Random Search和Grid Search以及旧版本下的Neputune管理scikit-optimize)
References
Code
1、https://machinelearningmastery.com/scikit-optimize-for-hyperparameter-tuning-in-machine-learning/
2、https://medium.datadriveninvestor.com/alternative-hyperparameter-optimization-techniques-you-need-to-know-part-2-e9b0d4d080a9