数据分析|Python|拼多多优惠券使用预测分析报告
该案例分析项目是在小灶能力派商业数据分析课程上完成的
使用Python和Jupyter Notebook完成,本文是该案例的数据分析报告,详情代码在https://github.com/CLaraRR/xiaozao-data-analysis/tree/master/PDD
目录
1、项目说明
2、项目要求
3、数据认识
4、数据探索
4.1 整体的优惠券使用情况
4.2 不同年龄的使用优惠券情况
4.3 过去6个月优惠券使用情况
4.4 过去1个月优惠券使用情况
4.5 不同职业用户的优惠券使用情况
4.6 不同婚姻状态的用户的优惠券使用情况
4.7 信用卡是否违约的用户的优惠券使用情况
4.8 是否退货的用户的优惠券使用情况
4.9 是否使用信用卡付款的用户的优惠券使用情况
5、模型建立、预测和优化
5.1 数据预处理
5.1.1 数据分箱
5.1.2 哑变量处理
5.1.3 相关系数分析
5.2 模型建立和评估
5.2 模型优化
5.2.1 添加变量
5.2.2 更改损失函数的类别权重
5.2.3 改善数据不平衡
5.2.4 模型解读
6、业务建议
7、项目总结
1、项目说明
拼多多是国内主流的手机购物APP,成立于2015年9月,用户通过发起和朋友、家人、邻居等的拼团,以更低的价格,拼团购买商品。拼多多作为新电商开创者,致力于将娱乐社交的元素融入电商运营中,通过“社交+电商”的模式,让更多的用户带着乐趣分享实惠,享受全新的共享式购物体验。对于各大电商平台,在“双十一”这种大促时间段,优惠券会起到非常大的促销作用。那么,如何找到更容易使用优惠券的用户,对他们精准地推送与营销,从而在双十一期间使销售额大大提升呢?这就是我们需要支持拼多多共同分析与解决的一个问题。
2、项目要求
根据用户的基本信息以及过去的消费行为数据,完成以下事项:
- 使用Python建立逻辑回归模型
- 预测用户是否会在活动中使用优惠券
- 找到对用户使用优惠券影响较大的因素
3、数据认识
数据来源于小灶商业数据分析课程,该数据集一共有25317条数据,将原数据字典按照用户信息、消费行为和预测结果进行不同维度的分类,用思维导图来表示如下:
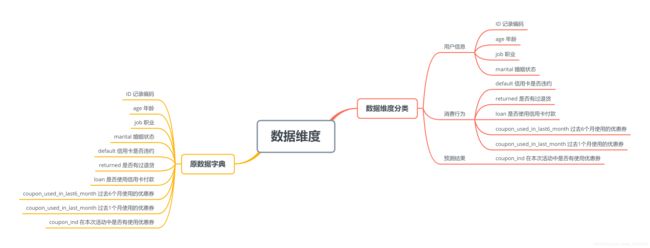
- 用户信息包括:记录编码、年龄、职业、婚姻状态
- 消费行为包括:信用卡是否违约、是否有过退货、是否使用信用卡付款、过去6个月使用的优惠券数量、获取1个月使用的优惠券数量
- 预测结果:也就是本次项目的任务,预测在本次活动中是否有使用优惠券
4、数据探索
本节的数据探索将分为数值变量和类别变量两种分别进行,主要探索其他变量和是否使用优惠券变量的关系。
4.1 整体的优惠券使用情况
统计数据集中所有用户使用优惠券的数量和不使用优惠券的数量。
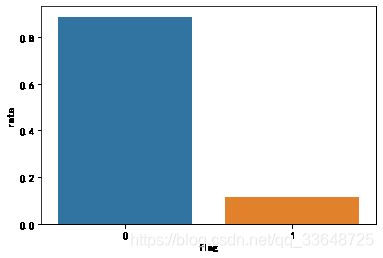
由上图发现数据集极度不平衡,不使用优惠券与适用于优惠券的数据比例将近9:1,因此在后续建模的时候要改善数据不平衡这个问题。
4.2 不同年龄的使用优惠券情况
将所有用户的年龄以5岁的间隔进行分箱,以及区分用户是否使用优惠券绘制直方图,如下图。

从图中发现:
- 使用拼多多APP的用户年龄主要在在20-70之间,小于35岁和大于60岁的用户更倾向于使用优惠券,而在35~60岁间的用户更倾向于不使用优惠券。
分析原因:
- 小于35岁的用户更倾向于使用优惠券的原因是比较好理解的,因为年轻用户对APP的使用更为熟悉,更容易掌握优惠券的用法,而大于60岁的用户由于数量比较少,是否能直接得出他们更倾向于使用优惠券这一结论是不太靠谱的;
- 35岁到60岁之间的用户随着年龄增长用户量也随之减少,不倾向于使用优惠券的原因可能是不清楚APP推出的优惠券活动,或者是因为经济能力比较好而无需费心使用优惠券。
4.3 过去6个月优惠券使用情况
将所有用户过去6个月优惠券使用情况绘制直方图,如下图。

从图中发现:
- 过去6个月各个用户的优惠券使用数情况集中在0-10次之间
- 大部分用户在过去的6个月使用优惠券的次数为3次
- 少数用户使用优惠券的次数在10次以上,最多是55次
4.4 过去1个月优惠券使用情况
将所有用户过去1个月优惠券使用情况绘制直方图,如下图。
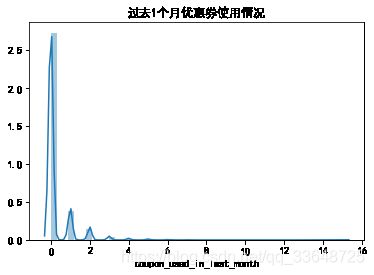
从图中发现:
- 过去1个月优惠券使用数量集中在0-2次之间
- 然而大部分用户在过去一个月没有使用优惠券
4.5 不同职业用户的优惠券使用情况
1、统计各个职业的用户数量,如图1
2、统计各个职业分别使用优惠券和不使用优惠券的用户数量,如图2
3、统计各个职业中使用优惠券的人数比例,如图3
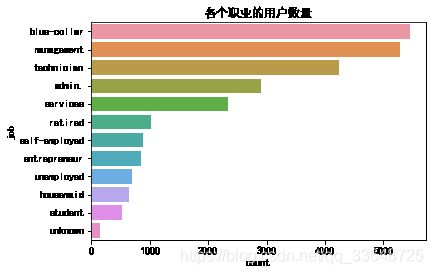

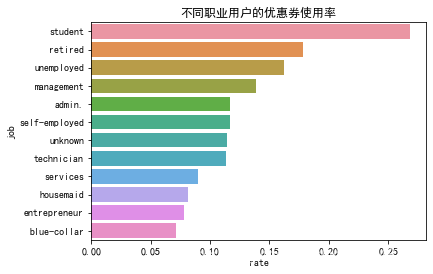
- 使用APP的用户中,蓝领用户最多,其次是管理人员, 技术人员, 行政人员, 服务行业用户
- 使用了优惠券的用户中,管理人员最多,其次是技术人员, 蓝领用户, 行政人员, 服务行业用户,出现这样的结果是因为他们这些群体的用户量本来就很多,所以使用优惠券的人相较其他群体也要多
- 但是在各个职业群体中,优惠券使用率最高的是学生(26.9%)、退休人员(17.9%)、无业(16.2%),可以看出来学生、退休人员、无业游民这类没有收入或工资水平较低的用户更倾向于使用优惠券
4.6 不同婚姻状态的用户的优惠券使用情况
1、统计不同婚姻状态的用户数量,如图1
2、统计不同婚姻状态用户中使用优惠券的人数比例,如图2
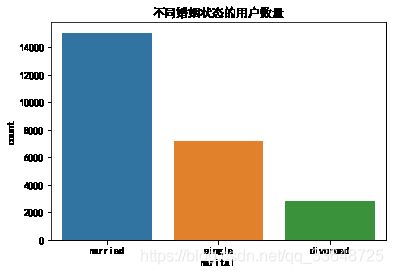

- 在所有用户中,已婚用户数量最多,然后是单身用户、离婚用户
- 单身用户的优惠券使用率最高(14.6%)
4.7 信用卡是否违约的用户的优惠券使用情况
1、统计不同信用卡违约状态的用户数量,如图1
2、分别统计不同信用卡违约状态用户中使用优惠券的人数比例,如图2


- 只有少数用户信用卡违约
- 没有信用卡违约的用户的优惠券使用率为11.4%
4.8 是否退货的用户的优惠券使用情况
1、统计有过退货行为的用户和没有过退货行为的用户的数量,如图1
2、分别统计有过退货行为的用户和没有过退货行为的用户中使用优惠券的人数比例,如图2

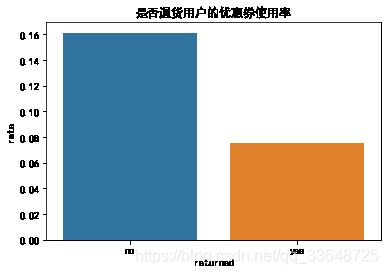
- 退货的用户较多
- 未退货的用户使用优惠券使用率(16.1%)比退货的用户(7.5%)要高
4.9 是否使用信用卡付款的用户的优惠券使用情况
1、统计使用信用卡付款的用户和没有使用信用卡付款的用户的数量,如图1
2、分别统计使用信用卡付款的用户和没有使用信用卡付款的用户中使用优惠券的人数比例,如图2

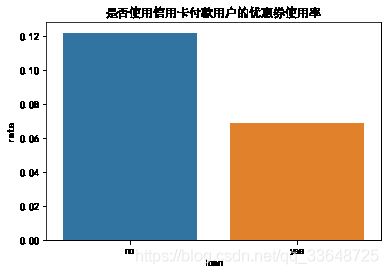
- 大部分用户不使用信用卡付款
- 不使用信用卡付款的用户的优惠券使用率(12.2%)比使用信用卡付款(6.9%)的高
5、模型建立、预测和优化
这一节将采用逻辑回归模型对前面涉及到的变量进行建模,用来预测用户是否使用优惠券。
5.1 数据预处理
在建模前首先要对数据进行预处理,预处理包括数据清洗(缺失值、异常值)、数据分箱、数据归一化、哑变量处理、相关系数分析等操作。数据清洗在数据探索的时候已经完成了,所以这一节主要是进行数据分箱、哑变量处理和相关系数分析。
5.1.1 数据分箱
分箱的主要目的是为了减少建模中的变量数量,使模型的可解释性更强。
- 通过前面的数据探索发现年龄其实可以分为小于25岁, 25-45岁之间, 45-65岁之间, 大于65岁这四个区间
- 由于过去6个月使用优惠券数量和过去1个月使用优惠券数量这两个变量的取值范围比较小,因此也可以进行分箱,使数值型变量转换为类别变量。可以把过去6个月使用优惠券数量划分为0-5次,6-20次,21-41次这三个区间,把过去1个月使用优惠券数量划分为0次, 1次, 2次, 大于2次这四个区间
- 数据集包含的职业类型较多,为了方便后续建模,可以将相似的职业合并成一个类型。根据各个职业的优惠券使用率,初步将student,retired,unemployed合并为低收入群体,management,admin,self-employed,unknown,technician合并为中高收入群体,services,housemaid合并为中等收入群体,entrepreneur,blue-collar合并为高收入群体
分箱完成后数据变为下面的样子:
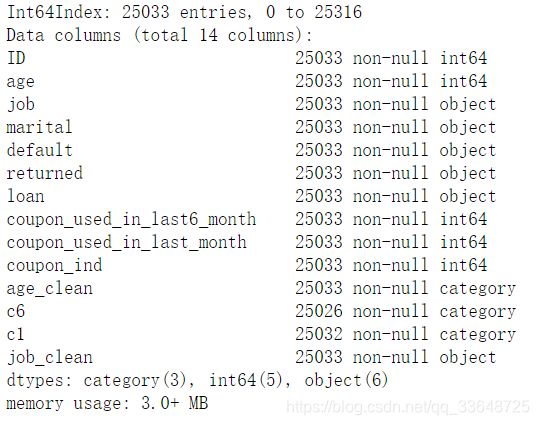
其中job_clean是将job划分后创建的新变量,c6对应的是coupon_used_in_last6_month,c1对应的是coupon_used_in_last_month,age_clean对应的是age,然后可以把原变量删除掉。
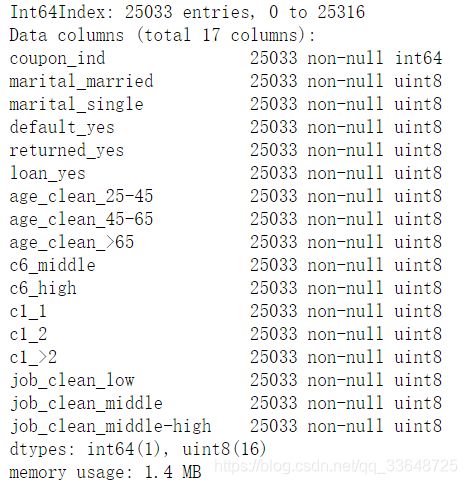
5.1.2 哑变量处理
这一步对类别变量进行哑变量处理,使得使类别变量变成二值变量,从而使得模型能够处理类别变量,数据变为下面的样子:
5.1.3 相关系数分析
这一步将其他变量与是否使用优惠券变量进行相关性分析,取出相关系数绝对值大于0.05的变量进行后续建模。
通过分析,得到以下几个变量:c1_1, job_clean_low, c1_2, age_clean_>65,marital_single, marital_married, loan_yes, returned_yes。
其中变量c1_1, job_clean_low, c1_2, age_clean_>65, marital_single和coupon_ind是强正相关,
变量marital_married, loan_yes, returned_yes和coupon_ind是强负相关。

5.2 模型建立和评估
终于到了最关键的一步也是本项目的最终任务——使用逻辑回归模型对相关变量进行建模来预测用户是否使用优惠券。
这一节先不考虑数据不平衡的问题,之后在模型优化的时候再改善这一问题。
首先将数据集按7:3的比例分为训练集和测试集,使用训练集数据训练逻辑回归模型,再应用到测试集上进行预测。模型的训练准确率、测试准确率、精确率、召回率、F1-Score和AUC如下:
| train_acc | test_acc | precision | recall | f1-score | AUC | |
| Original | 0.8864 | 0.8867 | 0.2667 | 0.0047 | 0.0093 | 0.5015 |
模型的ROC曲线如下:

模型的测试准确率虽然很高,但是由于数据极度不平衡,所以以准确率作为模型优劣的评价准则是有失偏颇的,因此用精确率、召回率、F1-Score作为评价标准更好。
可以看到这个模型的精确率、召回率和f1-score都很低,且AUC值为0.5左右,基本上随机猜测也能达到准确率0.88,这个模型是没有应用的价值的。
5.2 模型优化
我通过三种思路来改进模型:添加变量、更改损失函数的类别权重和改善数据不平衡
5.2.1 添加变量
原始模型只使用了相关系数大于0.05的变量进行建模,如果把所有变量都加进去,再来看看模型效果是否提升。
| train_acc | test_acc | precision | recall | f1-score | AUC | |
| AddVariable | 0.8860 | 0.8871 | 0.4333 | 0.0154 | 0.0297 | 0.5064 |
ROC曲线如下:
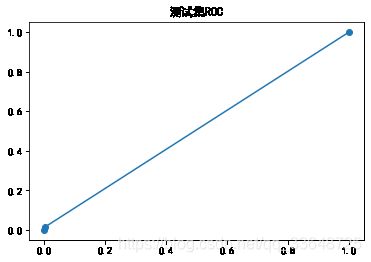
添加所有变量后模型性能并没有明显提升,这种方法不予采用。
5.2.2 更改损失函数的类别权重
更改类别权重就是针对不同类别的数据设置不同的分错代价,即提高少数类分错的代价或降低多数类分错的代价,最终使各类别平衡。常用的机器学习训练方法中,很多都提供了权重设置参数class_weight,可以手动设置该参数,但一般情况下只需要将其设置为balanced即可。
| train_acc | test_acc | precision | recall | f1-score | AUC | |
| Balanced | 0.7055 | 0.7132 | 0.2052 | 0.5403 | 0.2975 | 0.6377 |
ROC曲线:
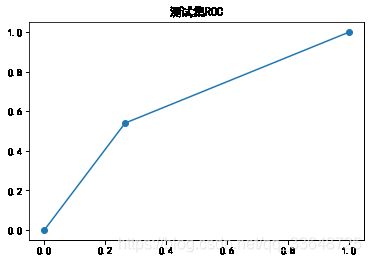
更改类别权重后模型的recall、f1-score和AUC有了较大的提升。
5.2.3 改善数据不平衡
原始模型没有对数据不平衡进行处理,这里我采用了imblearn库的多种重采样方法改善数据不平衡。关于imblearn的使用可以参考链接和官方文档。
需要非常注意的是:必须先划分训练测试集,再在训练集上进行重采样
训练集的作用是为了学得正负样本的分割超平面,但是数据不平衡,会干扰模型的学习,因此,我们才在训练集上使用“重采样”这样的技术手段;而测试集的本质作用是利用历史样本来检验学得的模型的泛化能力,因此测试集必须要代表未来真实的样本分布,不然就丧失了测试集本身应有的作用。所以应该先划分训练测试集,再在训练集上进行重采样,以解决类别不平衡数据怎么"学"的问题。如果先进行重采样再划分训练测试集,那么测试集的分布就不能代表真实的样本分布,而且不同的重采样方法得到的数据不同,在不同的测试集上进行模型对比是不公平的。
- 随机的采样
- RandomUnderSampler 随机下采样
- RandomOverSampler 随机上采样
- 改进的采样
- 上采样
- SMOTE
- ADASYN
- BorderlineSMOTE
- 下采样
- RENN
- NearMiss
- 组合采样
- SMOTEENN
- SMOTETomek
- 上采样
各个方法的效果如下表:
| method | train_acc | test_acc | precision | recall | f1-score | AUC |
| Original | 0.886435 | 0.886684 | 0.266667 | 0.004739 | 0.009313 | 0.501545 |
| AddVariable | 0.886035 | 0.887084 | 0.433333 | 0.015403 | 0.029748 | 0.506426 |
| Balanced | 0.705473 | 0.713182 | 0.205221 | 0.540284 | 0.297456 | 0.637679 |
| RandomUnderSampler | 0.636890 | 0.707457 | 0.201588 | 0.541469 | 0.293796 | 0.634971 |
| RandomOverSampler | 0.636457 | 0.713182 | 0.205221 | 0.540284 | 0.297456 | 0.637679 |
| SMOTE | 0.626513 | 0.683755 | 0.189955 | 0.555687 | 0.283127 | 0.627829 |
| ADASYN | 0.594300 | 0.615712 | 0.164366 | 0.592417 | 0.257334 | 0.605539 |
| BorderlineSMOTE | 0.671022 | 0.615712 | 0.164366 | 0.592417 | 0.257334 | 0.605539 |
| RENN | 0.893524 | 0.827563 | 0.267765 | 0.308057 | 0.286501 | 0.600698 |
| NearMiss | 0.639658 | 0.695872 | 0.198240 | 0.560427 | 0.292879 | 0.636724 |
| SMOTEENN | 0.990801 | 0.881891 | 0.361290 | 0.066351 | 0.112112 | 0.525750 |
| SMOTETomek | 0.626513 | 0.683755 | 0.189955 | 0.555687 | 0.283127 | 0.627829 |
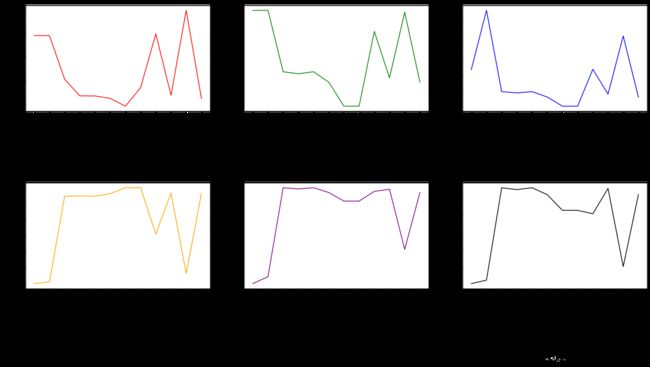
经过上面多种改善数据不平衡方法的尝试,大部分方法都对原模型在精确率、召回率、f1-score有了不同程度的提升,综合下来,选择各方面都较出色的更改损失函数的类别权重的方法。
5.2.4 模型解读
这一节使用优化后的模型进行模型系数解读。各个变量的模型系数和概率比值如下表:
| 变量 | 模型系数 | 概率比值 |
| c1_1 | 1.0895 | 2.9728 |
| job_clean_low | 0.2608 | 1.2979 |
| c1_2 | 1.1283 | 3.0903 |
| age_clean_>65 | 1.0840 | 2.9566 |
| marital_single | 0.2590 | 1.2956 |
| marital_married | -0.1856 | 0.8306 |
| loan_yes | -0.5073 | 0.6021 |
| returned_yes | -0.7893 | 0.4542 |
1、c1_2系数解读:
c1_2系数为1.1283,c1_2对应的coupon_ind变量是0和1,那么我们可以做出如下假设:
- 当c1_1=0时,用户前一个月使用优惠券不是1次,目标用户使用优惠券的概率是1-p
- 当c1_1=1时,用户前一个月使用优惠券为1次,目标用户使用优惠券的概率是p
我们计算的系数,就是对应到事件发生(p)与不发生(1-p)概率比值的log转换,结合公式,即为ln(p/1-p)就等于1.1283,也就是说p/1-p=exp(1.1283)=3.0905。
所以我们可以说,在前一个月使用了2次优惠券的用户在本次活动中使用优惠券的概率是其他用户3倍。
2、job_clean_low系数解读:
job_clean_low系数为0.2608,job_clean_low对应的coupon_ind变量是0和1,那么我们可以做出如下假设:
- 当job_clean_low=0时,用户不是低收入群体,目标用户使用优惠券的概率是1-p
- 当job_clean_low=1时,用户是低收入群体,目标用户使用优惠券的概率是p
我们计算的系数,就是对应到事件发生(p)与不发生(1-p)概率比值的log转换,结合公式,即为ln(p/1-p)就等于0.2608,也就是说p/1-p=exp(0.2608)=1.2979。
所以我们可以说,低收入用户的优惠券使用概率是非低收入用户的1.3倍。
同理,其他变量的系数解读也是类似的:
- 年龄大于65岁的用户使用优惠券的概率是其他用户的3倍
- 单身用户使用优惠券概率是其他用户的1.3倍
- 已婚用户使用优惠券的概率是其他用户的0.83倍
- 使用信用卡付款的用户使用优惠券的概率是不使用信用卡用户的0.6倍
- 有退货行为的用户使用优惠券的概率是没有过退货行为用户的0.5倍
6、业务建议
整理前面数据探索和建模中得到的结论,可以给出以下业务建议以供参考:
- 持续关注年轻人(小于35岁)和老年人(大于60岁)用户的使用优惠券情况,保持这部分群体的优惠券使用率
- 低收入群体,包括学生、老人、无业人员往往更倾向于使用优惠券,可以向这部分人投放更多优惠券
- 老年人、单身用户、不使用信用卡付款、没有过退货行为的用户比他们相反群体的用户的优惠券使用概率要高,可以向这部分人投放更多优惠券
- 中高收入群体是APP的主要使用群体,要想办法提高他们的优惠券使用率
7、项目总结
这个项目让我体验到了从数据清洗-->数据探索-->建模预测-->模型优化-->得出业务结论的完整流程,受益匪浅。其中让我感触最深的是数据探索和模型优化这两个环节,如何从各个变量中发掘他们之间的关系,使用哪种可视化图表展示这种关系,这都是一个需要大量练习才能熟练掌握的过程,而模型优化则涉及到机器学习领域甚至是更高深的数学知识,这也促使我去了解各种机器学习模型的应用场景,以及更新的模型方法。但这次项目也有不足的地方,比如业务建议这一块,由于我对业务这块了解不多,因此给出的建议可能会比较笼统而不具体,今后还要在这方面多多积累。