【RASA】NLU模块组件分析
Rasa是一个开源机器学习框架,用于构建上下文AI助手和聊天机器人。
Rasa有两个主要模块:
- Rasa NLU:用于理解用户消息,包括意图识别和实体识别,它会把用户的输入转换为结构化的数据。
- Rasa Core:是一个对话管理平台(同时处理多个对话,互不干扰|上下文信息会存储到如redis中,进行管理),用于举行对话和决定下一步做什么。
首先介绍一下rasa中nlu模块自带的组件,然后给出一些常用的pipeline配置方式,最后介绍如何添加自定义组件以及如何配置它们。
- word vector source
- MitieNLP
- SpacyNLP
- Tokenizers
- WhitespaceTokenizer
- JiebaTokenizer
- MitieTokenizer
- Featurizers
- MitieFeaturizer
- SpacyFeaturizer
-
ConveRTFeaturizer
-
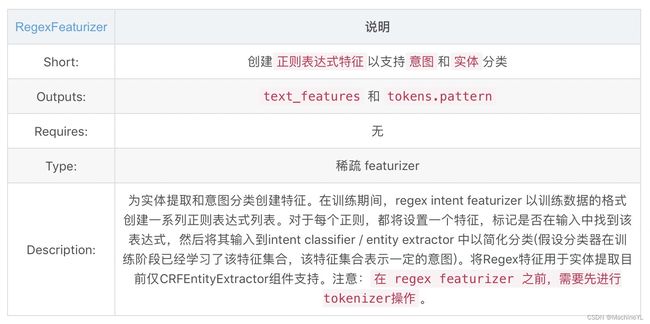
RegexFeaturizer
- CountVectorsFeaturizer
- Intent Classifiers
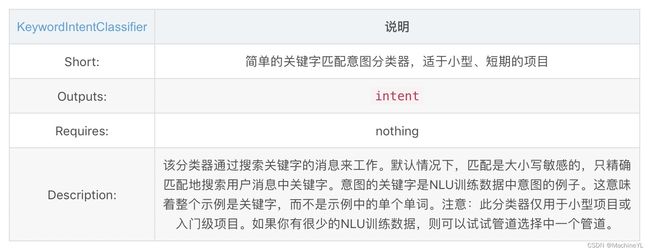
- KeywordIntentClassifier
- MitieIntentClassifier
- SklearnIntentClassifier
- EmbeddingIntentClassifier
- Selectors
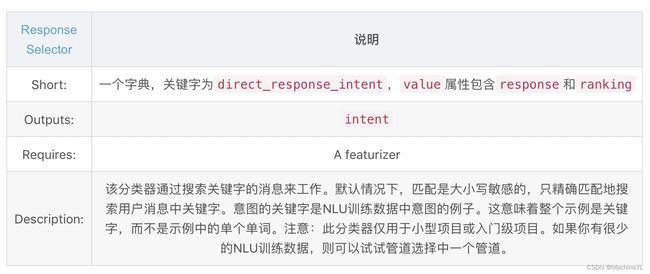
- Response Selector
- Entity Extractors
- MitieEntityExtractor
- SpacyEntityExtractor
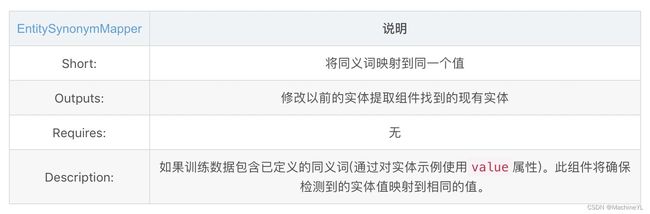
- EntitySynonymMapper
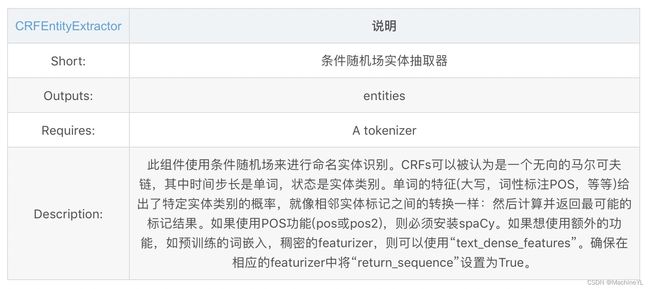
- CRFEntityExtractor
- DucklingHTTPExtractor
1、词向量构建:
(1)mitieNLP

config.yml中配置如下:
pipeline:
- name: "MitieNLP"
# 语言模型
model: "data/total_word_feature_extractor_zh.dat"
(2)spacyNLP
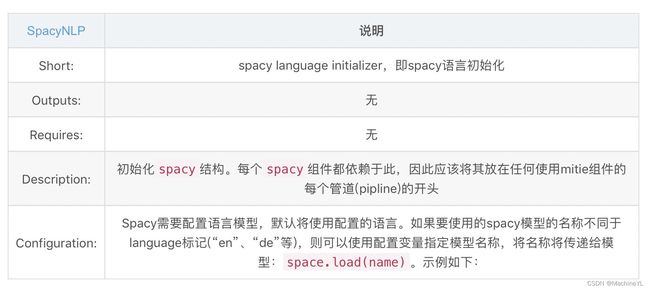
config.yml文件配置如下:
pipeline:
- name: "SpacyNLP"
# 指定语言模型
model: "en_core_web_md"
# 设定在检索单词向量时,这将决定单词的大小写是否相关
# 当为false时,表示不区分大小写。比如`hello` and `Hello`
# 检索到的向量是相同的。
case_sensitive: false
2、tokenizer:
(1)whitespacetokenizer
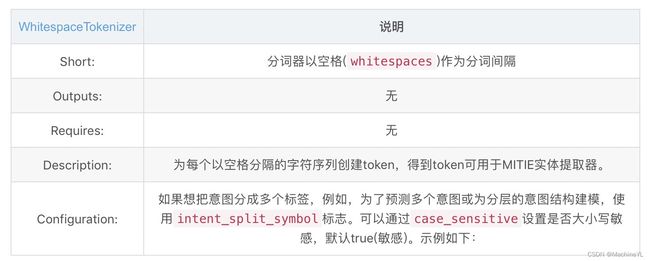
config.yml文件配置如下:
pipeline:
- name: "WhitespaceTokenizer"
# 指定是否大小写敏感,默认true为敏感
case_sensitive: false
(2)jiebatokenizer

config.yml文件配置如下:
pipeline:
- name: "JiebaTokenizer"
# 指定自定义词典
dictionary_path: "path/to/custom/dictionary/dir"
(3)mitietokenizer

config.yml文件配置如下:
pipeline:
- name: "MitieTokenizer"
(4)spacytokenizer

config.yml文件配置如下:
pipeline:
- name: "SpacyTokenizer"
(5)converttokenizer
config.yml文件配置如下:
pipeline:
- name: "ConveRTTokenizer"
3、featurizer
(1)MitieFeaturizer

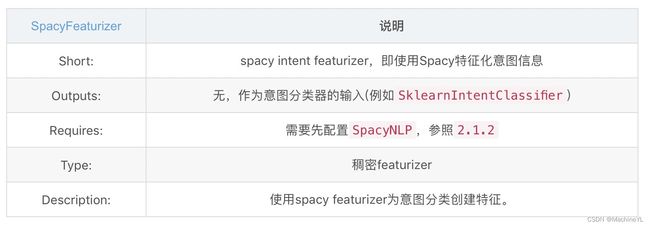
(2)SpacyFeaturizer
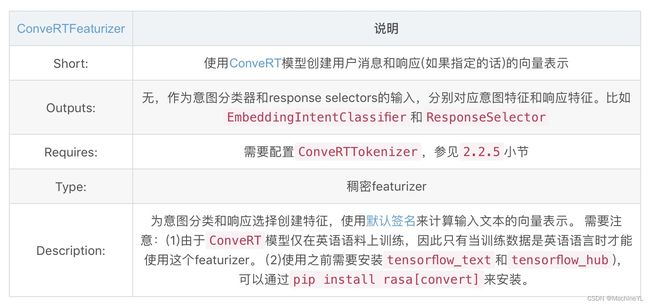
(3)ConveRTFeaturizer
(4)regexFeaturizer
(5)countvectorsFeaturizer

4、intent classifier
(1)mitie intent classifiers

(2)sklearn intent classifiers

(3)embedding intent classifiers

(4)keyword intent classifiers
5、selectors
6、entity extractors
(1)mitie entity extractors

(2)spacy entity extractors

(3)duckling http extractors

(4)crf entity extractors
(5)entity synonym mapper
nlu模块主要用于识别用户输入的message中的intent和entity,nlu模块提供了pipeline方式调用这种组件。pipeline调用时组件是顺序执行的,每个组件处理输入并给出输出,输出可以被该组件之后的任何组件使用。
在nlu模块中,提供了集中template pipeline,如pretrained_embedding_spacy、supervised_embeddings。
1、pretrained_embedding_spacy
config.yml中配置如下
language: "en"
pipeline: "pretrained_embeddings_spacy"
等价于:
language: "en"
pipeline:
- name: "SpacyNLP" # 预训练词向量
- name: "SpacyTokenizer" # 文本分词器
- name: "SpacyFeaturizer" # 文本特征化
- name: "RegexFeaturizer" # 支持正则表达式
- name: "CRFEntityExtractor" # 实体提取器
- name: "EntitySynonymMapper" # 实体同义词映射
- name: "SklearnIntentClassifier" # 意图分类器
pretrained_embeddings_spacy管道使用GloVe或 fastText的预训练词向量,因此,它的优势在于当你有一个训练样本如I want to buy apples,Rasa会预测意图为get pears。因为模型已经知道“苹果”和“梨”是非常相似的。如果没有足够大的训练数据,这一点尤其有用。
2、supervised_embeddings
config.yml中配置如下
language: "en"
pipeline: "supervised_embeddings"
等价于:
language: "en"
pipeline:
- name: "WhitespaceTokenizer" # 分词器
- name: "RegexFeaturizer" # 正则
- name: "CRFEntityExtractor" # 实体提取器
- name: "EntitySynonymMapper" # 同义词映射
- name: "CountVectorsFeaturizer" # featurizes文本基于词
- name: "CountVectorsFeaturizer" # featurizes文本基于n-grams character,保留词边界
analyzer: "char_wb"
min_ngram: 1
max_ngram: 4
- name: "EmbeddingIntentClassifier" # 意图分类器
supervised_embeddings 管道不使用任何的预训练词向量或句向量,而是针对自己的数据集特别做的训练。它的优势是面向自己特定数据集的词向量(your word vectors will be customised for your domain),比如,在通用英语中,单词“balance” (平衡)与单词 “symmetry”(对称)意思非常相近,而与单词"cash"意思截然不同。但是,在银行领域(domain),“balance”与"cash"意思相近,而supervised_embeddings训练得到的模型就能够捕捉到这一点。该pipline不需要任何指定的语言模型,因此适用于任何语言,当然,需要指定对应的分词器。比如默认使用WhitespaceTokenizer,对于中文可以使用Jieba分词器等等,也就是该Pipline的组件是可以自定义的。
还有一些例如pretrained_embeddings_convert、mitie等template pipeline。当然,pipeline的配置非常的灵活,我们可以自定义pipeline中的组件,实现不同特性的pipeline。
reference:
Components