基于各国贷款数据的可视化分析(含python代码)
文章目录
数据集介绍(附获取链接)
一、数据情况预览
二、附带地图的数据可视化
1. 作专题地图,展示不同国家的贷款状况(平均贷款金额)
2. 地图显示不同地区的贫苦指数
3. 用basemap画图 展示"印度资助金额最高的7个地区(由高到低)
三、数据可视化(柱状、折线、树形、饼图、热力图)
1.贷款用途
2. 还款方式
3. 贷款需求(按国家统计贷款人数和金额)
4. 作折线图 展示贷款金额和审批金额, 以及二者比例的变化趋势
5. 查看所有贷款金额分布情况
6. 查看所有贷款人中男性与女性的比例
7. 查看男性与女性的平均贷款额度
总结
数据集介绍(附获取链接)
数据集链接:https://pan.baidu.com/s/1g9HvEpBuanQMNlz6u6Hl8g
提取码:2tv9
data_kiva_loans.csv — 主要贷款信息(贷款金额、贷款人性别、还款方式、所属国家和地区等);
data_kiva_mpi_region_locations.csv — 区域位置数据(贷款所在地的经纬度等信息)
data_loan_themes_by_region.csv — 按地区数据划分的贷款数据(贫苦指数MPI、世界区域名称等信息)
一、数据情况预览
导入包:
#导入接下来会用到的包
import pandas as pd
import numpy as np
import squarify
import seaborn #基于matplotlib的图形可视化
import matplotlib.pyplot as plt
import plotly.offline
import plotly.graph_objs
from mpl_toolkits.basemap import Basemap
from numpy import array
#忽略报警信息
import warnings
warnings.filterwarnings("ignore")
%matplotlib inline
#使用matplotlib inline命令可以将matplotlib的图表直接嵌入到Notebokk之中,
#因此就不需要plt.show()这一语句来显示图片导入数据:
kiva_loans_data = pd.read_csv("data_kiva_loans.csv") #主要贷款数据
kiva_mpi_locations_data = pd.read_csv("data_kiva_mpi_region_locations.csv") #区域位置数据
loan_themes_by_region_data = pd.read_csv("data_loan_themes_by_region.csv") #按地区数据划分的贷款数据
#打印每种数据的大小(行列)
print("kiva_loans_data数据集大小",kiva_loans_data.shape)
print("kiva_mpi_locations_data数据集大小",kiva_mpi_locations_data.shape)
print("loan_themes_by_region_data数据集大小",loan_themes_by_region_data.shape)
用info函数显示dataframe数据集的基本信息
kiva_loans_data.info() #info(),观看数据的基本信息,包括索引范围、列名、非空值的数量、列的数据类型和内存使用情况
用describe函数查看dataframe数据集的可描述性统计变量
kiva_loans_data.describe() #describe()默认参数,显示int和float类型(包括非空数量、均值、标准差、最小值、分位数、最大值) 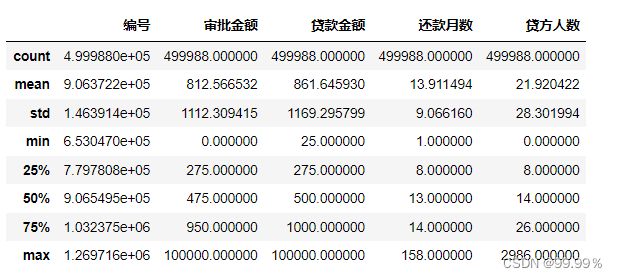
describe(include=["O"]),展示object类型(包括:非空数量、类别的数目、最高数量的类别及出现次数)
kiva_loans_data.describe(include=["O"])
#注意:双引号内是大写的字母0,不是阿拉伯数字0
二、附带地图的数据可视化
1. 作专题地图,展示不同国家的贷款状况(平均贷款金额)
#计算各个国家平均贷款金额,并排序
countries_funded_amount=kiva_loans_data.groupby('国家').mean()['审批金额'].sort_values(ascending=False)
plt.figure(figsize=(15,8),dpi=600)
#把所需指标传进去
data=[dict(
type='choropleth',
locations=countries_funded_amount.index,
locationmode='country names',
z=countries_funded_amount.values,
colorscale='Red',
colorbar=dict(title='平均贷款金额(美元)'))]
#layout:用来定义布局
layout=dict(title='Kiva中不同国家的贷款情况')
#将data补分和layout部分组合成figure对象
fig=dict(data=data,laout=layout)
#设置 validate=False可以禁用请求验证,若输入值错误程序也能成功运行
plotly.offline.iplot(fig,validate=False)效果:
地图可视化
2. 地图显示不同地区的贫苦指数
data=[dict(
type="scattergeo",#画地理坐标中的散点图
lat = kiva_mpi_locations_data["纬度"],#传入经纬度信息
lon = kiva_mpi_locations_data["经度"],
text = kiva_mpi_locations_data["位置名称"],#显示位置名称
marker =dict(
color = kiva_mpi_locations_data['贫苦指数MPI'],
colorbar=dict(title="多位贫苦指数")
))]
layout=dict(title = '不同地区的贫苦指数')
fig = dict(data=data, layout=layout)
plotly.offline.iplot(fig)
效果:
贫困指数mpi——地图散点
3. 用basemap画图 展示"印度资助金额最高的7个地区(由高到低)
#打印印度资助金额最高的7个地区的信息
temp = pd.DataFrame(loan_themes_by_region_data[loan_themes_by_region_data["国家"]=='India'])
print("印度资助金额最高的7个地区(由高到低)")
top_cities = temp.sort_values(by="金额",ascending=False)
top7_cities=top_cities.head(7)
top7_cities 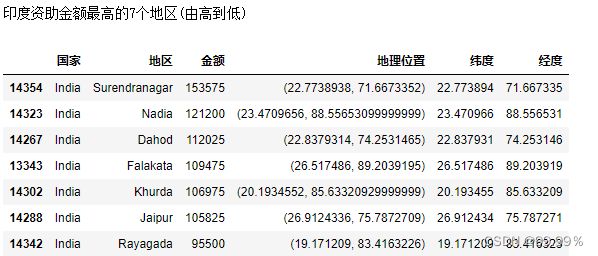
#在印度地图上绘制前7个受资助地区
plt.figure(figsize=(20,15),dpi=600)
seaborn.set_theme(style="whitegrid",font='SimHei',font_scale=1) #设置字体和大小
#用basemap画图
#projection参数规定了投影方法,projection='lcc’:可以通过经纬度设置来得到某一区域的局部地图
#resolution参数设置分辨率级别,1’(低)
#llcrnrlon、lcrnrlat、urcrnrlon、urcrnrlat分别左下角的x轴坐标、左下角的y轴坐标、右上角的x轴坐标、右上角的y轴坐标#lat_,
#lon_0改变地图的投影方式非常简单
map=Basemap(width=4500000,height=900000,projection="lcc",
llcrnrlon=67,llcrnrlat=5,urcrnrlon=99,urcrnrlat=37,lat_0=28,lon_0=77)
map.drawmapboundary()#fillcontinents()和drawmapboundary ()可以实现填充颜色
map.drawcountries()
map.drawcoastlines()#使用drawcoastlines方法绘制地图
lg=array(top7_cities["经度"])#经度
lt=array(top7_cities["纬度"])#纬度
pt=array(top7_cities["金额"])#金额
nc=array(top7_cities["地区"])#地区
x,y= map(lg,lt)
#进行min-max标准化,amount sizes=(原数据最小值)/(最大值-最小值)
a=int(top7_cities["金额"].max())
b=int(top7_cities["金额"].min())
amount_sizes=top7_cities["金额"].apply(lambda x:int(x-b)/(a-b)*100)
#设置位置、大小、标记、颜色
plt.scatter(x,y,s=amount_sizes,marker="o",c=amount_sizes)
#给图形添加标签
for ncs,xpt,ypt in zip(nc,x,y):
plt.text(xpt+60000,ypt+30000,ncs)
plt.title("印度资助金额最高的7个地区") 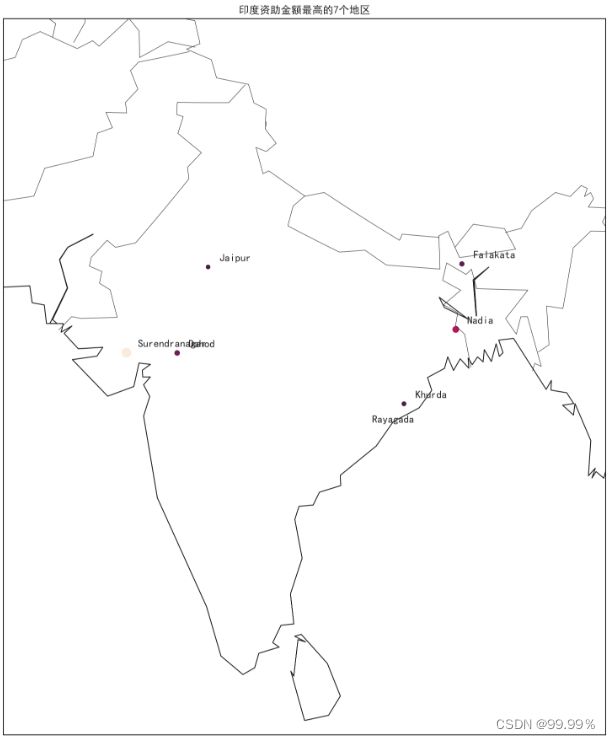
三、数据可视化(柱状、折线、树形、饼图、热力图)
1.贷款用途
贷款用途在表格中称为 贷款领域一级分类
用barplot画出彩虹色的图,并且设置了字体和尺寸,详见代码
sector_num = kiva_loans_data['贷款领域一级分类'].value_counts()#统计每个指标出现个数
plt.figure(figsize=(15,8),dpi=600)#设置图形和清晰度大小。figsize的单位为英寸,dpi单位为每英寸点数
plt.rcParams['font.sans-serif']=['SimHei']#设置正常显示中文标签
seaborn.barplot(sector_num.values, sector_num.index)#用barplot直接画图
#在图上添加values值,enumerate()函数用于将sector_num,values组合为一个索引序列
for i, v in enumerate(sector_num.values): #在选定位置传进v值
plt.text(v,i,v)#参数分别表示该字符串起点的横坐标,纵坐标和数值
plt.xticks(rotation='vertical') #使x轴上的刻度垂直展示
plt.xlabel('数量')
plt.ylabel('贷款领域(一级分类)')
plt.title('贷款领域(一级分类)分布情况')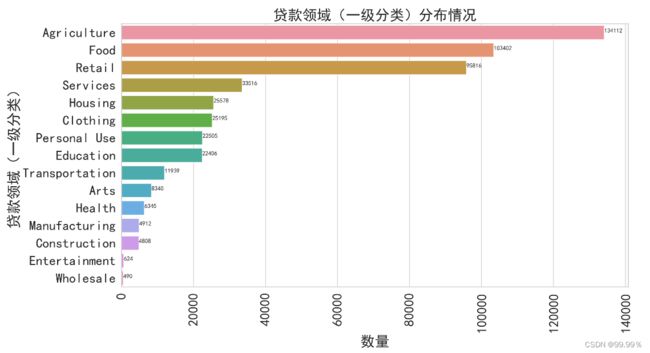
可以作用于看到农业、食品、零售领域的贷款是最多的,这也与数据集中包含了大量欠发达国家、发展中国家有关。
作树地图 查看贷款领域一级分类分布情况
使用squarify绘制树的地图:
sizes:指定离散变量各水平对应的数值,即反映树地图子块的面积大小;
label:为每个子块添加指定标签;
value:为每个子块添加数值大小的标签;
plt.figure(figsize=(15,8),dpi=600)
squarify.plot(sizes=sector_num.values,label=sector_num.index, value=sector_num.values)
plt.title('贷款领域一级分类统计')
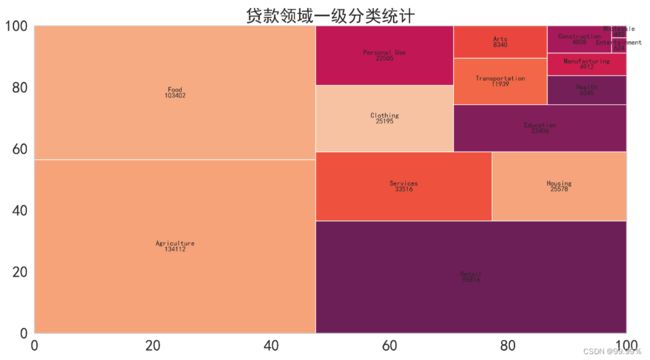
上述结果解释:在一级分类中,农业、食品、零售等生活类用途成为热门贷款领域
2. 还款方式
count = kiva_loans_data['还款方式'].value_counts()
plt.figure(figsize=(50,20),dpi=600)
seaborn.barplot(count.values, count.index)
seaborn.set_theme(style="whitegrid",font='SimHei',font_scale=5) #设置字体和大小
for i, v in enumerate(count.values):
plt.text(v,i,v,fontsize=19)
plt.xlabel('数量')
plt.ylabel('还款方式')
plt.title("还款方式分布情况")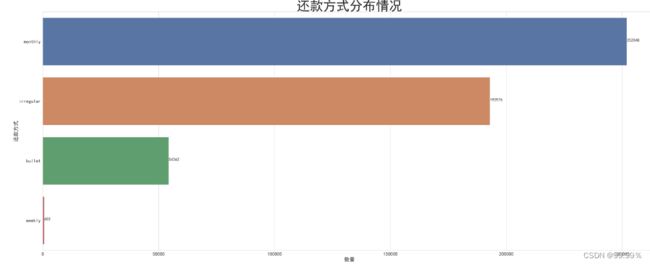
上述结果解释:按月还款和不定期还款的人数占大多数,其中按月还款人数最多,按周还款的人数最少;
作点图,展示不同还款方式随着时间变动,其贷款额的变化趋势:
#转化object型日期为pandas支持的标准时间类型
kiva_loans_data['日期']=pd.to_datetime(kiva_loans_data['日期'])
#按月指定时间形式
kiva_loans_data['日期(年月)']=kiva_loans_data['日期'].dt.to_period("M")
plt.figure(figsize=(15,8),dpi=600)
seaborn.set_theme(style="whitegrid",font='SimHei',font_scale=2) #设置字体和大小
#指定hue,把不同指标按照颜色区分出来
#pointplot:点图代表散点图位置的数值变量的中心趋势估计,并用误差线提供关于该估计的不确定性的一些指示。
g1=seaborn.pointplot(x='日期(年月)',y='贷款金额',
data=kiva_loans_data,hue='还款方式')
g1.set_xticklabels(g1.get_xticklabels(),rotation=90)#x轴数据旋转90度
g1.set_title("按年月计算的贷款金额")
g1.set_xlabel("时间(年月)")
g1.set_ylabel("贷款金额(美元)")
##还款方式:monthly按月还,irregular不定期还款,bullet一次性还款,weekly按周还款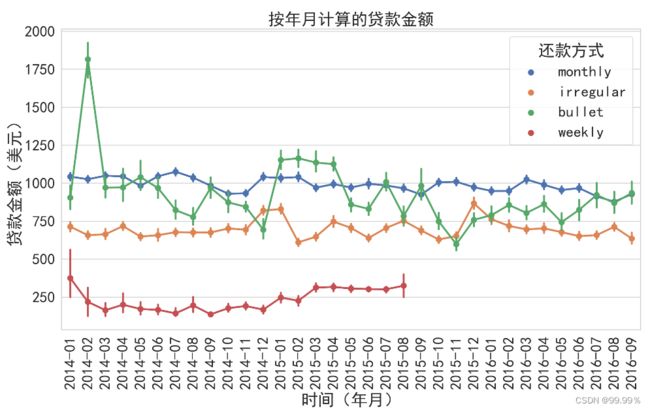
3. 贷款需求(按国家统计贷款人数和金额)
#统计10个最频繁出现的国家
count = kiva_loans_data['国家'].value_counts().head(10)
plt.figure(figsize=(15,8),dpi=600)
seaborn.barplot(count.values, count.index)
seaborn.set_theme(style="whitegrid",font='SimHei',font_scale=2) #设置字体和大小
for i, v in enumerate(count.values):
plt.text(v,i,v,fontsize=19)
plt.xlabel('数量')
plt.ylabel('国家人数')
plt.title("货币需求(按国家统计)") 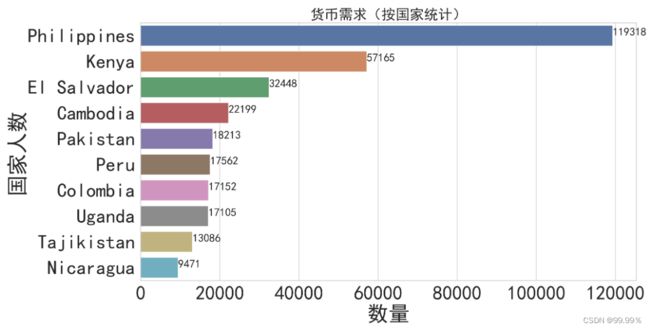
可以看到菲律宾的贷款需求量最大,并且贷款需求量大的都是发展中国家和欠发达的国家;
作词云图:
#缺失值处理,取国家这一列数据中的缺失值
names = kiva_loans_data['国家'][~pd.isnull( kiva_loans_data['国家'])]
myText0=' '.join(names)
from wordcloud import WordCloud #词云
#指定词云中显示的最大字体大小,输出的画布宽度高度
#generate(text):根据文本生成
wordcloud = WordCloud(max_font_size=50, width=600, height=300).generate(myText0)
plt.figure(figsize=(15,8),dpi=600)
plt.imshow(wordcloud)#显示生成的词云
plt.title("词云图")
plt.axis('off')#关闭坐标轴
作热力图 展示不同国家贷款金额随时间的变化:
#使用dt.year提取年份数据
kiva_loans_data['年份']=kiva_loans_data.日期.dt.year
#以国家和年份分组,计算贷款总额
loan=kiva_loans_data.groupby(['国家','年份'])['贷款金额'].sum().unstack()#不要堆叠
plt.figure(figsize=(15,8),dpi=600)
loan=loan.sort_values([2014],ascending=False)#把2014年的数据降序排列
loan=loan.fillna(0)#fillna(0)填充空值
temp=seaborn.heatmap(loan,cmap='Reds')#作热力图
plt.show()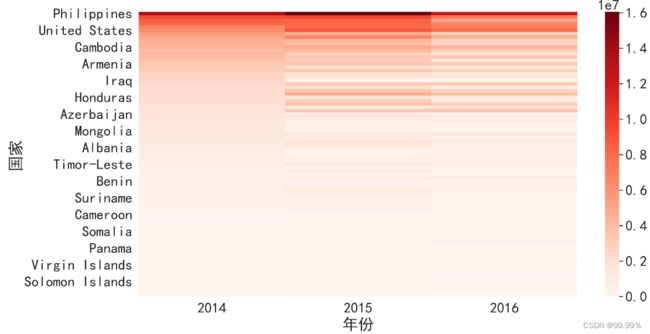
4. 作折线图 展示贷款金额和审批金额, 以及二者比例的变化趋势
#将申请时间转换为pandas支持的时间类型
kiva_loans_data.申请时间=pd.to_datetime(kiva_loans_data["申请时间"])
#设置索引为申请时间
kiva_loans_data.index=pd.to_datetime(kiva_loans_data["申请时间"])
plt.figure(figsize=(15,8),dpi=600)
#把贷款金额以星期聚合
ax=kiva_loans_data["贷款金额"].resample("w").sum().plot()
#把审批金额以星期聚合
ax=kiva_loans_data["审批金额"].resample("w").sum().plot()
ax.set_xlabel("金额($)")
ax.set_ylabel("时间")
#设定x坐标轴的范围
ax.set_xlim((pd.to_datetime(kiva_loans_data["申请时间"].min()),
pd.to_datetime(kiva_loans_data["申请时间"].max())))
#用于设置图例的线条
ax.legend(["申请金额","审批金额"])
plt.title("申请金额与审批金额趋势")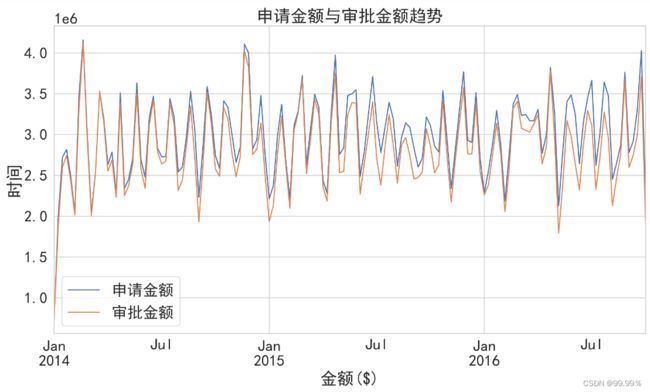
申请金额与审批金额比例随时间变化情况:
plt.figure(figsize=(15,8),dpi=600)
#计算申请金额与审批金额比例
ax=(kiva_loans_data["审批金额"].resample("w").sum()/kiva_loans_data["贷款金额"].resample("w").sum()).plot()
ax.set_ylabel("申请金额与审批金额比例")
ax.set_xlabel("时间")
#设定x坐标轴的范围
ax.set_xlim((pd.to_datetime(kiva_loans_data["申请时间"].min()),
pd.to_datetime(kiva_loans_data["申请时间"].max())))
#ax.set_ylim(0,1)
plt.title("审批比例")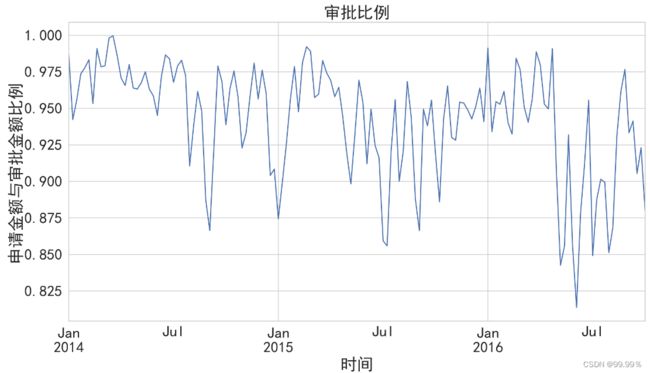
5. 查看所有贷款金额分布情况
plt.figure(figsize=(15,8),dpi=600)
#在数据集取审批金额这一列的数据,并从小到大排序
plt.scatter(range(len(kiva_loans_data['审批金额'])),np.sort(kiva_loans_data.审批金额.values))
plt.xlabel('编号')
plt.ylabel('贷款金额')
plt.title("贷款金额分布情况")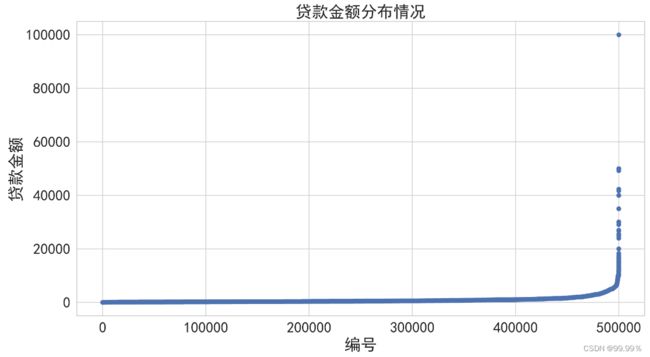
上述结果解释:多为小额贷款(0-20000),贷款超过20000的人数就很少了;
6. 查看所有贷款人中男性与女性的比例
gender_list = []#建立空数组,存入处理后的单个性别信息
for gender in kiva_loans_data["贷款人性别"].values:
if str(gender) != "nan":#过滤缺失值
#extend()用于在列表末尾追加另一个序列的多个值,strip()用于移除字符串头尾空格
gender_list.extend([lst.strip() for lst in gender.split(",")])
temp_data = pd.Series(gender_list).value_counts()
temp_data
labels=np.array(temp_data.index)#np.array数组创建方法
sizes=np.array((temp_data.values/temp_data.values.sum())*100)
plt.figure(figsize=(15,8),dpi=600)
#构造trace,配置相关参数
trace=plotly.graph_objs.Pie(labels=labels,values=sizes)
layout=plotly.graph_objs.Layout(title='贷款人性别')
#将trace保存于列表之中
data=[trace]
#将data补分和layout补分组成figure对象
fig=plotly.graph_objs.Figure(data=data,layout=layout)
#使用plotly.offline.iplot方法,将生成的图形嵌入到ipynb文件中
plotly.offline.iplot(fig)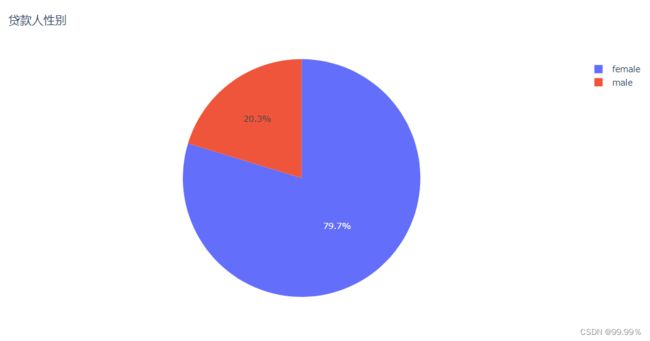
上述结果解释:蓝色为女性贷款人,红色为男性贷款人,可以看出女性贷款人数远远多于男性人数
7. 查看男性与女性的平均贷款额度
loan_sex1=kiva_loans_data[['贷款人性别','审批金额']]
#性别信息处理:若存在n个贷款人同时贷款,则拆分成n条贷款数据。
#split用于将字符串以逗号为分隔符拆分,expand=True把series类型转化为dataframe类
loan_sex2=loan_sex1["贷款人性别"].str.split(',',expand=True).stack()
#reset index 用来重新色织索引,drop=True:删除原来的索引列,level=1表示将第一列设置为索引列
loan_sex3=loan_sex2.reset_index(level=1,drop=True).rename('贷款人性别1')
#drop用于删除原先的贷款人性别列,axis=1;对列进行操作
#join用于将两个dataframe中不同的列索引合并成为一个dataframe(默认左外链接)
loan_sex4=loan_sex1.drop('贷款人性别',axis=1).join(loan_sex3)
#用str方loan_sex2法先转成字符串,再用strip()去除字符串左右两边空格
loan_sex4['贷款人性别1']=loan_sex4['贷款人性别1'].str.strip()
loan_sex5=loan_sex4.index.value_counts().sort_index()#计算人数并按照索引重新排序
loan_sex6=pd.concat([loan_sex4['贷款人性别1'],loan_sex4['审批金额'],loan_sex5],axis=1,keys=['贷款人性别1','总金额','人数'])
loan_sex6['实际金额']=loan_sex6['总金额']/loan_sex6['人数']
loan_sex6.head(10)
loan_sex6.loc[loan_sex6.贷款人性别1 =='nan','贷款人性别1']=np.nan#处理空值
#计算男女贷款金额平均值
sex_mean=pd.DataFrame(loan_sex6.groupby(['贷款人性别1'])['实际金额'].mean()).reset_index()
print(sex_mean)
plt.figure(figsize=(15,8),dpi=600)
seaborn.barplot(sex_mean.贷款人性别1,sex_mean.实际金额)
plt.title("按性别划分的平均资助金额")
plt.xlabel("性别")
plt.ylabel("平均贷款金额")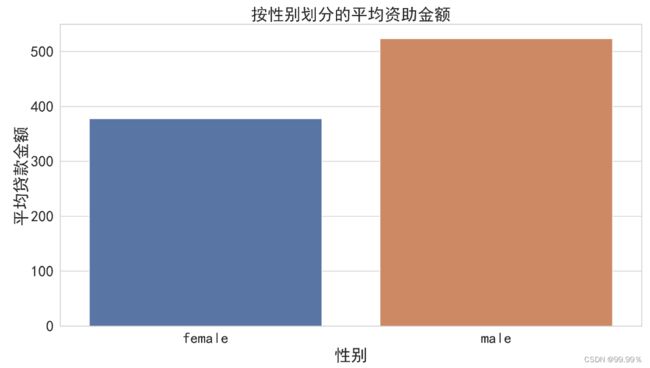
上述结果解释:男性平均贷款额要高于女性平均贷款额;
总结
本文使用了不少可视化形式,其中地图可视化是比较新颖的,只要有经纬度数据,就可以应用地图形式做可视化。