AdaPrompt: Adaptive Prompt-based Finetuning for Relation Extraction
AdaPrompt: Adaptive Prompt-based Finetuning for Relation Extraction
本文仅供参考、交流、学习
论文地址:https://arxiv.org/abs/2104.07650v1
代码和数据集地址:暂无
1. 摘要
在本文中,将关系抽取任务重新定义为掩码语言建模,并提出一种基于提示(prompt)的自适应微调方法。文中提出了一种自适应的标签词选择机制,该机制将关系标签分散到不同数量的标签字符中,以处理负责的多个标签空间。文中进一步引入一个辅助的实体识别器对象,鼓励模型专注于上下文表示学习。在基准数据集上的大量实验表明,本文方法在小样本和监督设置下都能取得更好的性能。
2. 本文贡献
- 研究了基于提示的关系抽取方法
- 提出了一种新的基于自适应提示的微调方法,该方法具有自适应标签词选择和辅助实体识别对象,和现有的关系抽取方法是正交的
- 在基准数据集上的大量实验结果证明方法的有效性
3. AdaPrompt-tuning
AdaPrompt-tuning只应用了直观的面向任务的模板和基于关系抽取任务的自适应标注此,没有任何额外的模型和梯度搜索。此外,AdaPrompt-tuning害引入了三态掩码语言模型损失来进一步改进。
3.1 背景和符号
设 X i n = { x 1 , x 2 , . . . , X s , . . . , X o , x N } X_{in}=\{x_1,x_2,...,X_s,...,X_o,x_N\} Xin={x1,x2,...,Xs,...,Xo,xN}是一个序列,其中 x n x_n xn是序列中第 n n n个字符, N N N是字符数。对于句子级关系抽取, X i n X_{in} Xin表示给定句子。对于对话级的关系抽取, X i n X_{in} Xin代表整个文档。对于每个样本,都有两个实体,主体实体 X s X_s Xs和客体实体 X o X_o Xo。 X s X_s Xs和 X o X_o Xo都是 X X X的子序列。一个实体可能包含一个或多个字符,例如 X s = { x s , x s + 1 , . . . , x s + m − 1 } X_s=\{x_s,x_{s+1},...,x_{s+m-1}\} Xs={xs,xs+1,...,xs+m−1},其中 s s s表示 x s x_s xs在序列 X X X中的起始位置, m m m表示 X s X_s Xs中字符的个数。给定 X , X s , X o X,X_s,X_o X,Xs,Xo,关系抽取的目标是预测 X s X_s Xs和 X o X_o Xo之间的关系 r ∈ R r\in R r∈R,其中 R R R是数据集中一组预定义的关系类型。
剩下的挑战是构建模板 T T T和标注词 M ( Y ) M(Y) M(Y)——我们把这两件事一起称为模板(prompt) P P P。 V V V指的是语言模型 L L L的词汇量,而 M : Y → V M:Y\rightarrow V M:Y→V是一个单射映射,连接任务标签和词表 V V V中的标签词。我们考虑一个一对多的映射 M M M,其中我们讲标签映射到单词集合。
我们首先将 X i n X_{in} Xin转换为另一个固定的字符序列 X ~ i n \tilde{X}_{in} X~in和 L L L,然后讲 X i n X_{in} Xin映射为一个隐藏向量 h k ∈ R d {h_k\in R^d} hk∈Rd。在标准的微调过程中,我们通常取 x ~ i n = [ C L S ] X i n [ S E P ] \tilde{x}_{in}=[CLS]X_{in}[SEP] x~in=[CLS]Xin[SEP]。在AdaPrompt-tuning中,我们使 X p r o m p t = T ( X ~ i n ) X_{prompt}=T(\tilde X_{in}) Xprompt=T(X~in)是一个掩码语言模型输入,它恰好包含一个 [ M A S K ] [MASK] [MASK]字符。讲提示输入到MLM中,可以将任务转换为语言建模任务,得到预测类 y ∈ Y y\in Y y∈Y为:
p ( y ∣ X p r o m p t ) = ∑ w ∈ V y p ( [ M A S K ] = w ∣ X p r o m p t ) ( 1 ) p(y|X_{prompt})=\sum_{w\in{V_y}}p([MASK]=w|X_{prompt}) \qquad (1) p(y∣Xprompt)=w∈Vy∑p([MASK]=w∣Xprompt)(1)
其中 w w w表示类 y y y中的第 w w w个标签词。它缩短了微调和预训练之间的差距,使得它在完全监督和少资源的场景中使用都更加有效。
3.2 建设面向任务的提示
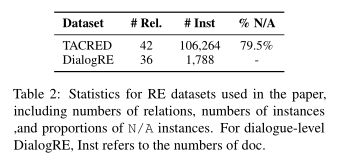
作者提倡利用领域转接知识为关系抽取任务生成通用模板。从图1中可以看出,原始的基于BERT的模型可以用单词预测 [ M A S K ] [MASK] [MASK],这些单词与黄金关系有关,符合语法和词性。
图1
根据MLM内部知识抽取的范式,我们可以用输入句 X i n X_{in} Xin直观地将各种关系抽取任务表述为模板:
X p r o m p t = [ C L S ] X i n [ S E P ] T [ S E P ] ( 2 ) X_{prompt}=[CLS]X_{in}[SEP]T[SEP] \qquad (2) Xprompt=[CLS]Xin[SEP]T[SEP](2)
例如, X i n X_{in} Xin(“People close to the situation said chief financial officer Douglas Flint will replace departing Stephen Green as chairman of the banking giant.” )对于输入格式,使用加粗字体来突出显示下面提到的实体,并设 T T T为“[E1] Douglas Flint [/E1] is [MASK] [E2] chief financial officer [/E2].” or “The relation between [E1] Xs [/E1] and [E2] Xo [/E2] is [MASK].” 上述的 T T T结构简洁,也直观易于理解。
3.3 自适应标签词选择
接下来,我们的目标是构建 M : Y → V M:Y\rightarrow V M:Y→V是一个单设映射,将任务标签连接到词汇表中的标签词集合。对于每个类 c ∈ Y c\in Y c∈Y,利用初始 L L L,基于前 k k k个词汇的条件似然构造一个修剪集 V c ⊂ V V^c\subset V Vc⊂V。然而,单纯搜索可能的任务是(1)一般难以处理的,因为关系抽取任务中类的数量往往超过30个,而搜索空间是指数型的,那么搜索的数量可能是 k C k^C kC;(2)很容易耗费时间和计算成本,因为dev一般都很大,所以很多轮评估都是耗时和计算成本高的。以使用基于字符的梯度搜索方法选择标签词为例,它需要大量的例子,在小样本的情况下可能非常不可靠。
受到类包含真实语义信息的启发,作者考虑将标签类型分别分解为多个词作为标签词。例如,我们可以将标签 y y y( y = y= y=“per:city_of_death”)分解为:
M ( y ) = { p e r s o n , c i t y , d e a t h } ( 3 ) M(y)=\{person,city,death\} \qquad (3) M(y)={person,city,death}(3)
其中, M M M需要分解符号“_”,完成属性词“per”,并删除连接词“of”。类标签自然对应于词表中的字符,这个分布可以很容易地解释为类标签上的分布。然后我们可以进一步将方程改写为:
p ( y ∣ X p r o m p t ) = e x p ( W M ( y ) ⋅ h [ M A S K ] ) ∑ y ′ ∈ Y e x p ( W M ( y ′ ) ⋅ h [ M A S K ] ) ( 4 ) p(y|X_{prompt})=\frac{exp(W_{M(y)}·h_{[MASK]})}{\sum_{y'\in Y}exp(W_{M(y')}·h_{[MASK]})} \qquad (4) p(y∣Xprompt)=∑y′∈Yexp(WM(y′)⋅h[MASK])exp(WM(y)⋅h[MASK])(4)
其中 h [ M A S K ] h_{[MASK]} h[MASK]为在 X p r o m p t X_{prompt} Xprompt上应用 L L L得到的 [ M A S K ] [MASK] [MASK]位置对应的隐向量, w M ( y ) w_{M(y)} wM(y)为预训练中使用的标签词的pre-softmax输出向量的和, v ∈ M ( y ) v\in M(y) v∈M(y)。当有监督示例 { ( X p r o m p t , y ) } \{(X_{prompt},y)\} {(Xprompt,y)}可用时,可以对 L L L进行微调,以最小化交叉熵。
3.4 训练目标
在微调过程中,我们有两个目标:关系判别目标 L R L_R LR和实体判别目标 L E L_E LE。
3.4.1 关系判别目标
关系判别目标是对文本中两个实体之间的关系进行分类,以进一步使plm理解现实场景中复杂的推理链。如图2所示,给定 ( X i n , T ) (X_{in},T) (Xin,T),我们可以生成 X p r o m p t X_{prompt} Xprompt,
L R = C E ( p ( y ∣ X p r o m p t ) ) ( 5 ) L_R=CE(p(y|X_{prompt})) \qquad (5) LR=CE(p(y∣Xprompt))(5)
其中 L R L_R LR为RD损失,CE为交叉熵损失函数。
图2

3.4.2 实体判别目标
由于输入空间和输出空间都由字符组成,我们可以逆向思考,如果plm可以找到另一个实体和一个关系的实体。AdaPrompt-tuning在ERICA的启发下,为了保持从plm继承来的语言理解能力,并避免灾难性的遗忘,AdaPrompt-tuning增加了实体判别目标来训练plm通过考虑文本中实体与其它实体的关系来理解一个实体。从图2中可以看出,我们只随机屏蔽一个实体 X e = { x s , x s + 1 , . . . , x x s + M − 1 } X_e=\{x_s,x_{s+1},...,x_{x_{s+M-1}}\} Xe={xs,xs+1,...,xxs+M−1},其中s表示 X X X序列中 X s X_s Xs的起始位置,M表示 X e X_e Xe中字符的数量设 x ′ x' x′是原始字符x,它被随机屏蔽了实体 X e X_e Xe中的字符, x m x^m xm是原始上下字符 x ′ x' x′中被屏蔽了。取 P ( x m ∣ x ′ , y ) P(x^m|x',y) P(xm∣x′,y)最大值如下:
q ( x m ∣ x ′ , y ) = e x p ( [ L ( x ′ , y ) ] x m ) ∑ v ′ ∈ V e x p ( [ L ( x ′ , y ) ] v ′ ) ( 6 ) L E = ∑ m ∈ M B C E ( q ( x m ∣ x ′ , y ) ) ( 7 ) q(x^m|x',y)=\frac{exp([L(x',y)]x^m)}{\sum_{v'\in V}exp([L(x',y)]v')} \qquad (6) \\ L_E=\sum_{m\in M} BCE(q(x^m|x',y)) \qquad (7) q(xm∣x′,y)=∑v′∈Vexp([L(x′,y)]v′)exp([L(x′,y)]xm)(6)LE=m∈M∑BCE(q(xm∣x′,y))(7)
通过优化 L r Lr Lr,plm可以学习包含三元组之间丰富语义的上下文表示。最终有以下训练损失:
L = L R + L E ( 8 ) L=L_R+L_E \qquad (8) L=LR+LE(8)
4. 实验结果
表1
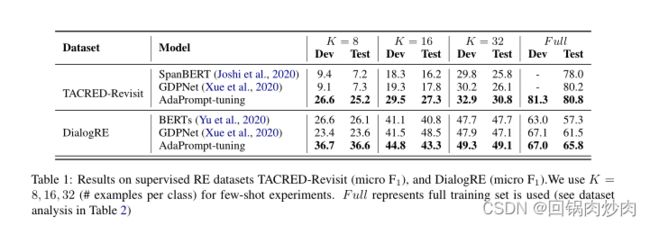
表2