一个垃圾分类项目带你玩转飞桨(2)
一个垃圾分类项目带你玩转飞桨(2)
接上文《一个垃圾分类项目带你玩转飞桨(1)》:基于PaddleClas实现垃圾分类,导出inference模型利用PaddleHub Serving 进行服务化部署,并利用PYQT5实现可视化。
本文同以垃圾分类为项目基点,采用PaddleX『飞桨』深度学习全流程开发工具,基于Yolov3-DarkNet53模型,实现多目标垃圾分类检测。并基于EdgeBoard边缘部署设备对模型进行落地部署,从而加快垃圾分类效率,助力社会环保。
基于PaddleX实现垃圾检测
随着垃圾分类政策的深入落地,现如今,垃圾分类相关产品如雨后春笋拔地而起。然如今垃圾分类产品,多采用计算机视觉中的图像分类技术对垃圾进行识别分类,此方案虽能较为准确的识别垃圾种类,但其受限于技术本身,其识别图像为保证识别准确率只能存在于一种垃圾,即:用户在使用此产品时,只能在本次识别过程中在识别区放置一种垃圾。故而此方案极大地阻碍了垃圾分类效率的提升。而采用目标检测技术能够有效解决此问题,加速垃圾分类效率,真正助力垃圾分类政策的深入落地,向社会普及垃圾分类知识。
PaddleX相关介绍
PaddleX 集成飞桨智能视觉领域图像分类、目标检测、语义分割、实例分割任务能力,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,并提供统一任务API接口及图形化开发界面Demo。开发者无需分别安装不同套件,以低代码的形式即可快速完成飞桨全流程开发。
PaddleX 经过质检、安防、巡检、遥感、零售、医疗等十多个行业实际应用场景验证,沉淀产业实际经验,并提供丰富的案例实践教程,全程助力开发者产业实践落地。
目前PaddleX已发布2.0.4rc版本正式发布,实现动态图的全面升级。本项目为保证模型能顺利部署于EdgeBoard开发板上,仍采用1.3.11版本。
解压数据集
本项目挂载数据集提供了既符合VOC格式又符合COCO格式的数据集,可以满足PaddleX或PaddleDetection模型训练的数据集格式要求。
【相关数据集转换方法可参考此Github仓库欢迎贡献代码、star……】
!unzip -oq /home/aistudio/data/data100472/dataset.zip -d dataset
模型训练
- 首先安装paddlex==1.3.11版本;
- 依据EdgeBoard开发板模型支持列表及具体部署场景选择训练模型;
- 模型导出;
1、考虑到本项目需部署于EdgeBoard开发板中,故安装paddlex==1.3.11版本。
!pip install paddlex==1.3.11
2、模型训练
在模型选取方面,EdgeBoard提供了基于PaddleX部署的支持模型,在此模型列表中(此处只展示检测支持模型,详细模型请查询此链接)
在本项目中,结合此检测模型支持列表,依据实际部署场景,以精度为第一选择优先级,选取Yolov3-DarkNet53模型进行训练。以下是详细的训练代码:
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from paddlex.det import transforms
import paddlex as pdx
# 定义训练和验证时的transforms
# API说明 https://paddlex.readthedocs.io/zh_CN/develop/apis/transforms/det_transforms.html
train_transforms = transforms.Compose([
transforms.MixupImage(mixup_epoch=250), transforms.RandomDistort(),
transforms.RandomExpand(), transforms.RandomCrop(), transforms.Resize(
target_size=608, interp='RANDOM'), transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.Resize(
target_size=608, interp='CUBIC'), transforms.Normalize()
])
# 定义训练和验证所用的数据集
# API说明:https://paddlex.readthedocs.io/zh_CN/develop/apis/datasets.html#paddlex-datasets-vocdetection
train_dataset = pdx.datasets.VOCDetection(
data_dir='/home/aistudio/dataset/VOC2007',
file_list='/home/aistudio/dataset/VOC2007/train_list.txt',
label_list='/home/aistudio/dataset/VOC2007/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='/home/aistudio/dataset/VOC2007',
file_list='/home/aistudio/dataset/VOC2007/val_list.txt',
label_list='/home/aistudio/dataset/VOC2007/labels.txt',
transforms=eval_transforms)
# 初始化模型,并进行训练
# 可使用VisualDL查看训练指标,参考https://paddlex.readthedocs.io/zh_CN/develop/train/visualdl.html
num_classes = len(train_dataset.labels)
# API说明: https://paddlex.readthedocs.io/zh_CN/develop/apis/models/detection.html#paddlex-det-yolov3
model = pdx.det.YOLOv3(num_classes=num_classes, backbone='DarkNet53')
# API说明: https://paddlex.readthedocs.io/zh_CN/develop/apis/models/detection.html#id1
# 各参数介绍与调整说明:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.html
model.train(
num_epochs=270,
train_dataset=train_dataset,
train_batch_size=16,
eval_dataset=eval_dataset,
learning_rate=0.000125,
save_interval_epochs=2,
lr_decay_epochs=[104, 126, 240],
save_dir='output/yolov3_darknet53',
use_vdl=True)
3、模型导出
!paddlex --export_inference --model_dir=image_model --save_dir=./inference_model
基于EdgeBoard实现模型部署
EdgeBoard简介
EdgeBoard是百度面向嵌入式与边缘计算场景打造的AI解决方案。丰富的硬件选型,可满足多变的边缘部署需求。无缝兼容百度大脑工具平台与算法模型,开发者既可以选用已有模型,也可以自定义算法。同时,模型训练与部署全程可视化,极大降低了开发与集成门槛。EdgeBoard灵活的芯片架构,可适配行业内最前沿、效果最好的算法模型,基于EdgeBoard打造的软硬一体产品,可广泛适用于安防、工业、医疗、零售、教育、农业、交通等场景。


硬件准备
- EdgeBoard及其电源 ;显示屏; miniDP转HDMI转换器; 网线 ;.usb摄像头;电脑
EdgeBoard具体操作
- 启动
使用配套的12V电源适配器插到EdgeBoard的电源接口,EdgeBoard电源接口为3.81mm间距的2pin绿色端子台,如下图所示,注意电源正负,其他接口无供电功能。

- 关机
EdgeBoard关机时,建议先通过poweroff命令将软件操作系统断电,再切断外部电源,可以保护SD卡文件系统不被意外损坏。
- 重启
EdgeBoard重启有两种方式,一种是在操作系统的窗口输入reboot命令,完成系统重启;另一种是短按设备上的reset按键,同样实现EdgeBoard系统重启
Windows环境
配置电脑IP
电脑配置IP地址步骤如下:电脑和Edgeboard直连后,进入控制面板–>网络和Internet–>查看网络状态和任务
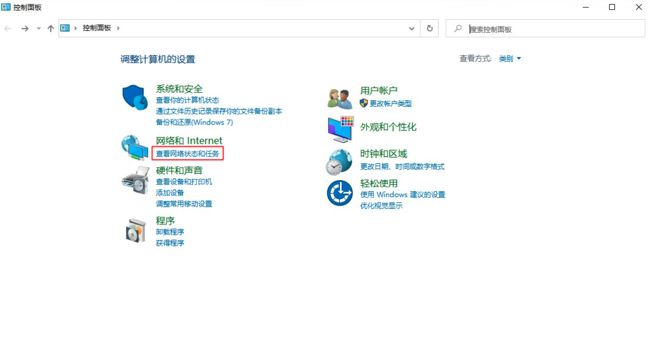
点击以太网

点击属性
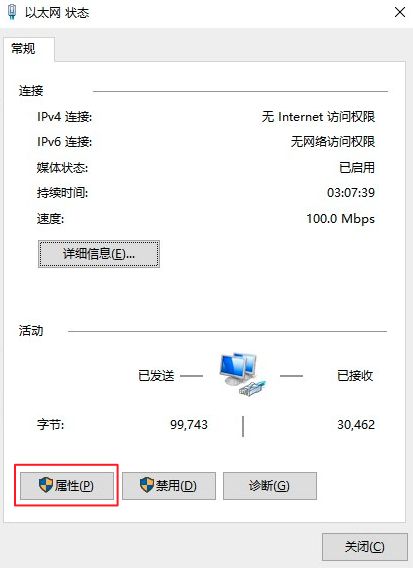
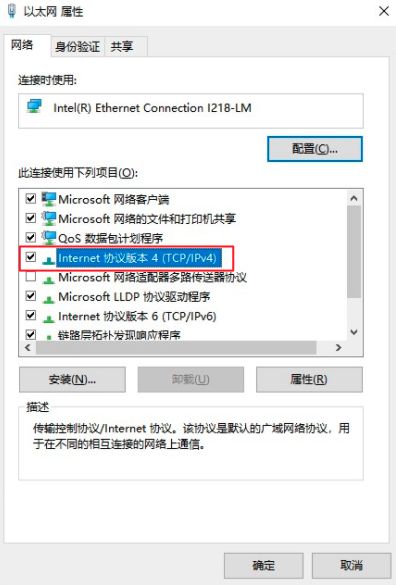
点击Internet协议版本4
设置电脑IP地址为静态IP地址
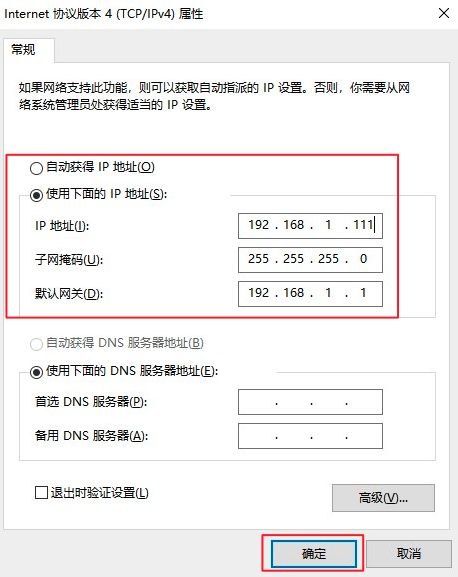
点击确定。
登录Edgeboard系统
Edgeboard系统是精简后的linux系统,可以通过网络SSH协议与其通讯。给设备上电后,通过电脑登录到Edgeboard系统中进行操作,Edgeboard系统的用户名和密码均为root。本教程使用window自带的终端Windows PowerShell ,具体操作如下
打开Windows PowerShell,输入ssh [email protected],点击回车,如果第一次连接该ip地址,会询问是否接入,输入yes,再回车,password为不可见字符,输入root后,直接回车,即可进去Edgeboard系统

EdgeBoard串口连接设备通讯
如果出现ssh连接不上,或者(设备ip动态获取后)需要查看ip,需要使用串口进入设备的控制台。
可使用配套的USB调试线连接EdgeBoard的USB UART调试接口,使用电脑连接EdgeBoard系统。
Windows连接串口方法
安装依赖
1.安装驱动:初次使用usb转串口设备需安装驱动 CP210x_Windows_Drivers,下载链接:https://cn.silabs.com/developers/usb-to-uart-bridge-vcp-drivers
2.安装调试工具:下文以MobaXterm工具为例来介绍,工具下载:https://mobaxterm.mobatek.net/download.html
连接设备
1.保证电脑已连接EdgeBoard的USB UART接口(接口位置请参考对应型号的硬件介绍),进入【控制面包->硬件和声音->设备管理器】查看设备管理器中映射的端口号,如图所示,端口号为COM4

2.打开MobaXterm,点击Session,进入Session settings,选择Serial,Serial port选择映射出的端口,Speed为115200,Flow Control为None,点击OK,如下图所示
3.配置完成后进入Session页面,给Edgeboard上电,会看到系统启动信息,待启动完成后输入用户名和密码root/root,即可进入设备系统。如下图所示
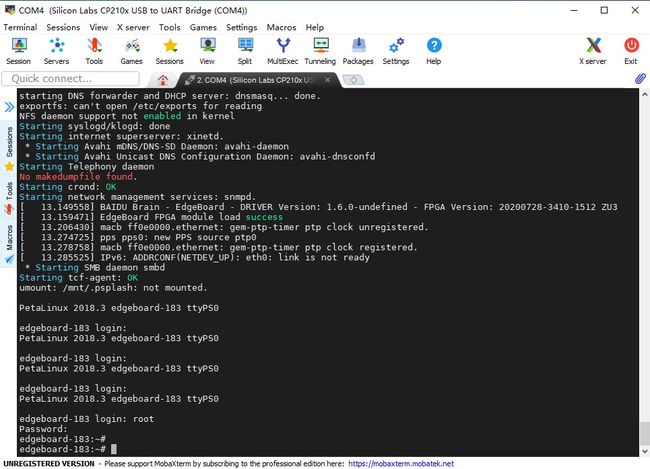
文件传输方式
推荐工具:winscp,下载链接:https://winscp.net/eng/download.php 「尊重知识产权,遵守工具使用规范,推荐您使用正版软件」
参照如下配置后,文件协议:scp;主机名:Edgeboard的IP;用户名&密码:root&root。点击登录
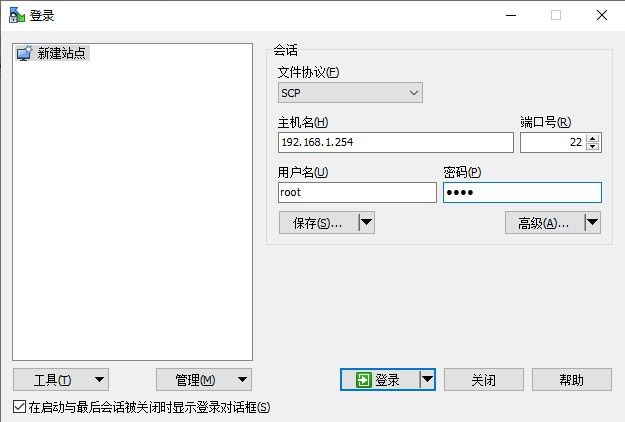
登录后,可以直接通复制粘贴命令进行电脑和设备间文件的拷贝
基于Edgeboard 1.8.0模型部署
上传模型
模型训练完成后,将模型文件上传到Edgeboard内,存放于/home/root/workspace/PaddleLiteDemo/res/models选择与模型相对应的文件夹,比如yolov3模型存放在detection目录,模型文件中需要包含于示例对应的文件,包括
model, params:模型文件(paddlepaddle版本不同,训练出的模型名称或有差别,只要在config.json中对应上即可)
label_list.txt:模型标签文件
img:放置预测图片的文件夹
config.json:配置文件,需要基于示例给出的结构,更改为自训练模型的参数
修改模型配置文件参数
config.json文件内容如下:
{
"network_type":"YOLOV3",
"model_file_name":"model",
"params_file_name":"params",
"labels_file_name":"label_list.txt",
"format":"RGB",
"input_width":608,
"input_height":608,
"mean":[123.675, 116.28, 103.53],
"scale":[0.0171248, 0.017507, 0.0174292],
"threshold":0.3
}
注意:config.json文件内的mean、scale计算方式与训练模型时的计算方式可能不同,一般有如下两种方式:
例如R为一张图片中一个像素点的R通道的值
①(R / 255 – mean‘) / std’
②(R – mean) * scale(EdgeBoard处理方式)
如果训练模型的mean和std为第一种计算方式,就需要通过如下运算,计算为Edgeboard的处理方式。
edgeboard中的mean值 = mean‘ * 255
Edgeboard中的scale值 = 1 / ( 255 * std’ )
修改系统参数配置文件
系统配置文件存放于/home/root/workspace/PaddleLiteDemo/configs内,根据模型属性修改对应的配置文件,比如yolov3模型,修改image.json文件中模型文件路径以及预测图片路径。
{
"model_config": "../../res/models/detection/yolov3",
"input": {
"type": "image",
"path": "../../res/models/detection/yolov3/img/screw.jpg"
},
"debug": {
"display_enable": true,
"predict_log_enable": true,
"predict_time_log_enable": false
}
}
执行程序
模型配置文件和系统配置文件修改完成后,运行程序
cd /home/root/workspace/PaddleLiteDemo/C++/build
./detection ../../configs/detection/yolov3/image.json