智能推荐系统
什么是智能推荐
智能推荐系统的本质就是一种信息发布工具,这套信息分发系统具备个性化分发的特性,它能够自动将用户与商品联系起来,挖掘用户的个性化需求,帮助用户找到那些他们感兴趣的商品。它有助于提升运营效率和用户转化率,尤其在内容分发、电商、社交等领域实践相当出彩。
个性化推荐如果信息量级小个性化意义不大,个性化推荐的数据量级至少是千级或万级。理论上来说,优质内容越多、类别分布越广泛,个性化推荐效果越好。
信息获取的三种方式
智能推荐是继分类目录、搜索引擎之后的又一信息获取方式,在互联网时代,人们大致经历了三种信息获取方式,即分类目录、搜索引擎、智能推荐,分类目录有雅虎、新浪;搜索引擎有谷歌、百度;智能推荐有字节跳动。
分类目录覆盖信息量有限,用户分门别类查找信息并不轻松。搜索引擎覆盖量大,操作简单,但用户必须提供精确的关键词,而智能推荐则是通过对用户行为数据的计算,将用户最有可能需要的信息主动推送给用户。
推荐业务流程
推荐系统经历了数据收集、特征抽取、特征计算、结果排序、前端调用五个环节。
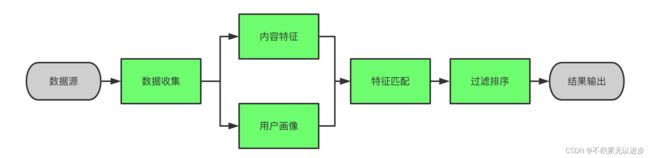
其中特征抽取(用户画像和商品画像)、召回计算、结果排序,是推荐系统的核心部分。
A:生成用户特征向量、商品特征矩阵。
B:根据用户特征向量和特征物品相关矩阵,转化出初始推荐物品列表。
C:对初始推荐列表进行过滤、排名,生成最终的推荐结果。
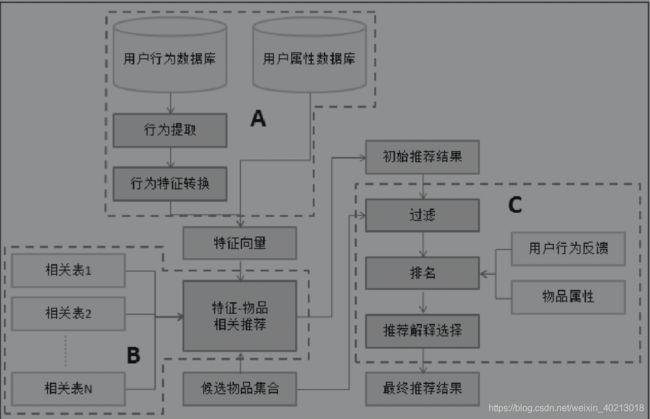
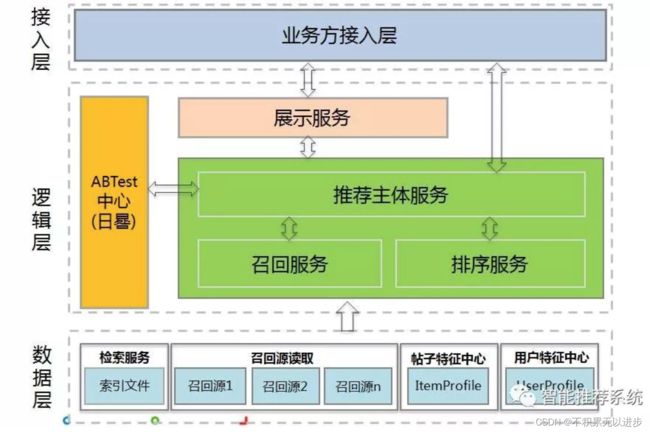
推荐系统架构
推荐系统主要由四个部分组成,分别是大数据层、特征抽取层、模型计算层、结果发布层。
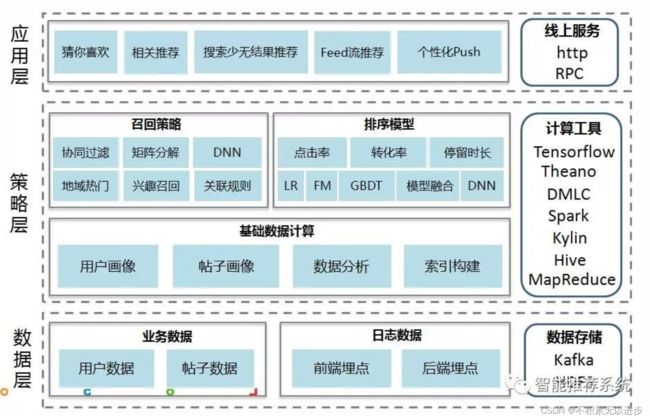
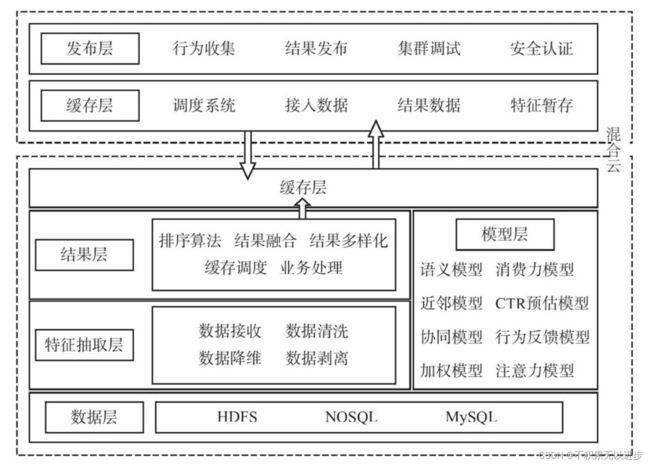
大数据层负责从各个数据源抓取和整合数据,也包括数据清洗、转码、统一数据格式等工作,数据层的数据有两类:一类是物料数据,另一类是用户的静态数据和行为数据。
特征抽取层主要用来接收、清洗来自数据层上报的数据并进行数据特征抽取。一般来说需要经历文本数据的分词、降维、去噪、向量化,生成能够被模型层用来建立模型的特征向量。
特征抽取层处理过的数据会上报至模型层进行建模,一套成熟、通用的推荐系统模型层一般会包括语义模型、LSTM模型、近邻模型、协同模型、FM模型、GBDT+LR模型、DNN模型、加权模型、用户行为反馈模型等,适配电商业务的模型一般还会有用户消费力模型、召回周期模型等。
结果发布层主要的作用是对模型层产出的结果进行过滤与排序。一般来说,模型层的多个模型会分别输出特定的结果及权重,而结果层则通过排序将结果按照权重或者优先级排列。当有特定业务需求时,结果将根据业务规则生成最终的推荐结果,并上报到缓存层,供前端发布层调用。
特征提取
特征分为四类:基本特征,复杂特征,统计特征和自然特征。首先是基本特征,而后统计和复杂特征层层递进,至于图像语音等抽提特征有专用的知识方法。
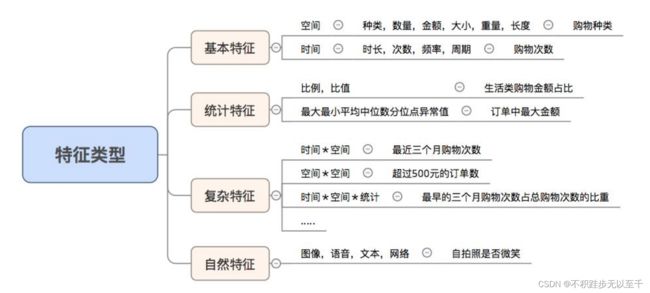
特征提取要争取用20%的精力投入达到80%的效果,使工作效率最大化。将123步完成之后,通过数据去回归特征的效果,查看重要的特征效果是否符合预期,不符合的话为什么?怎么修改?
- 做经验上最重要的
- 做容易做的
- 做可以批量产生的
- 观察bad_case/good_feature,总结经验回到1
可以借助机器学习的力量,使用简单的机器学习模型,例如决策树或支持向量机(SVM)。如果我们提供合适的数据和功能,这些机器学习模型可以充分发挥作用,甚至可以用作基准解决方案。
快速入门机器学习——特征抽取_leekpie的博客-CSDN博客_机器学习特征提取方法
可充分利用机器学习的14种开源工具
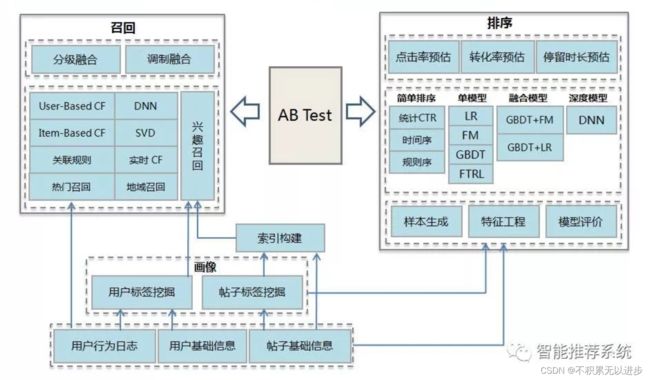
模型层的特征计算
模型层的模型分为近线计算与离线计算,对于近线计算来说,主要目的是实时收集用户行为反馈,并选择训练实例,实时抽取拼接特征,并近乎实时地更新在线推荐模型。这样做的好处是用户的最新兴趣能够近乎实时地体现到推荐结果里。对于离线计算而言,通过对线上用户点击日志的存储和清理,整理离线训练数据,并周期性地更新推荐模型。对于超大规模数据和机器学习模型来说,往往需要高效的分布式机器学习平台来对离线训练进行支持。
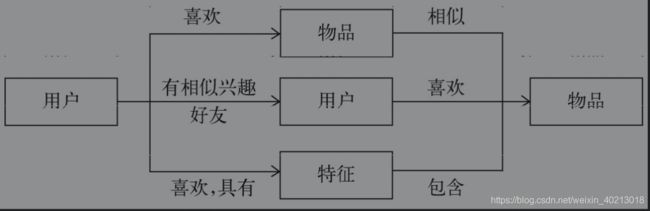
推荐算法
| 算法 | 说明 | 步骤 |
| 相似推荐 | 将用户喜欢的商品的类似商品推荐给用户 |
|
| 协同过滤 | 将有相同兴趣爱好的好友喜欢的商品推荐给用户 |
|
| 内容推荐 | 根据用户喜欢的商品的共性推荐更多的相似商品给用户 |
|
| 关联规则 | 通过数据挖掘发现了商品之间的关联规则,根据关联规则进行推荐 |
推荐效果验证(A/B Test)
ABtest系统虽不是个性化推荐系统的必需模块,但没有ABtest的推荐系统一定是个假的推荐系统,灰度发布可以帮助推荐系统不断迭代和优化。
推荐系统的验证方式与其他数据类产品比较类似,有三种比较通用的验证方式:离线验证、在线验证、用户调查。
冷启动策略总结
可以先给用户推荐热门排行榜,等到用户数据收集到一定程度再切换为个性化推荐。
利用用户注册时提供的年龄、性别等数据做粗粒度的个性化。
利用用户的社交网络账号登录,导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的物品。
要求用户在登录时对一些物品进行反馈,收集用户对这些物品的兴趣信息,然后给用户推荐那些和这些物品相似的物品。
在系统冷启动时,可以引入专家的知识,通过一定的高效方式迅速建立起物品的相关度表。