[论文评析]Adaptive Boosting for Domain Adaptation: Towards Robust Predictions in Scene Segmentation,TIP
Adaptive Boosting for Domain Adaptation: Towards Robust Predictions in Scene Segmentation
- 论文信息
- 背景
- 动机
- 方法
-
- 模型结构
- Adaptive data sampler
- Aggregation
- 优化
- AdaBoost Student
- 总结
- Reference
论文信息
题目:Adaptive Boosting for Domain Adaptation: Towards Robust Predictions in Scene Segmentation
发表: IEEE Transactions on Image Processing (TIP)
作者: Zhedong Zheng and Yi Yang
背景
这篇文章是域适应Domain Adaption领域的一项新工作, 考虑的场景是: 如何更好的把源域学习到的知识迁移到目标域, 其中源域的样本为labeled, 目标域的样本全部为unlabeled.
以往的很多研究往往假设目标域有少量的样本是labeled, 这篇文章考虑的场景更加一般话.
动机
如上所述,由于目标域的样本全部为unlabeled, 这带来的问题是:在进行模型迁移时迁移到什么程度以及合适停止缺乏有效的监督信息, 常用的Early stopping策略存在类似的问题,
基于此,作者提出了一种高效的称之为AdaBoost Student的Boosting方法, 通过在训练过程中调整数据分布来学习"互补"的weak learner并进一步提出了简单的聚合方法来集成这些weak learner, 从而克服了Early stopping的问题, 取得了更好的迁移学习效果.
其与Early stopping策略的比较如下图所示:
![[论文评析]Adaptive Boosting for Domain Adaptation: Towards Robust Predictions in Scene Segmentation,TIP_第1张图片](http://img.e-com-net.com/image/info8/d62c38800209436797c09ad1fec4c113.jpg)
方法
所提出的方法属于Boosting类方法, 非常简单, 基本流程与AdaBoost相同: 通过反复迭代, 以一种交互的方式一边调整数据分布(Adaptive Sampler), 一边训练Weak models, 如下图所示:
![[论文评析]Adaptive Boosting for Domain Adaptation: Towards Robust Predictions in Scene Segmentation,TIP_第2张图片](http://img.e-com-net.com/image/info8/5337f9913a094418832c49884534f911.jpg)
不过经典的AdaBoost是在单域场景下进行的所有的样本都为labeled, 这里考虑的是Domain adaption场景并且target domain的样本全部为unlabeled, 因此首先要解决如下两个问题.
(1) AdaBoost中是根据当前模型的prediction error结果来调整数据的分布(从而在下一次训练时更加关注error较大的样本), 然而这里target domain的样本全部为unlabeled, 该如何来调整数据分布/采样?
(2) AdaBoost中最终是基于各个weak learner的prediction来进行加权从的得到最终的model, 而这里由于target domain的样本全部为unlabeled,该如何加权/聚合这些weak/student learner?
还有一个问题是之前的聚合方法意味着需要保存之前训练过的所有weak learner, 这实际上非常耗费内存,特别是对于deep learning 方法.
在回答上述两个问题前, 先来看下模型结构.
模型结构
模型结构如下图所示, 其中feature learner部分主要是采用Deeplab-v2,其将ResNet-101作为backbone, 后面连接两个classifiers: 一个Primary classifier,一个Auxiliary classifier.
![[论文评析]Adaptive Boosting for Domain Adaptation: Towards Robust Predictions in Scene Segmentation,TIP_第3张图片](http://img.e-com-net.com/image/info8/e8acd59623804cdfa7fa0445f4988165.jpg)
Adaptive data sampler
这里的解决Question-1的思路是: 放弃了传统的基于预测误差调整数据分布的思路, 而是基于预测方法Prediction variance来选择关注哪些samples, 也就是所谓的adaptive data sampler,
如上图所示有两个classifier: Primary classifier, Auxiliary classifier, 记其输出分别为 F p ( X ∣ θ ) F_{p}(X|\theta) Fp(X∣θ), F a ( X ∣ θ ) F_{a}(X|\theta) Fa(X∣θ) , 作者基于KL-divergence来度量二者的差异:
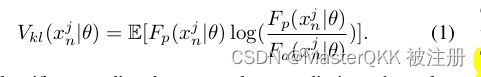 这样一来:如果两个模型的预测分布很接近则KL值很小; 反之,则表示两个模型没有作出一致的预测结果(预测的不确定性很大), 从而要在下一轮重点关注.
这样一来:如果两个模型的预测分布很接近则KL值很小; 反之,则表示两个模型没有作出一致的预测结果(预测的不确定性很大), 从而要在下一轮重点关注.
注: 对所有target samples计算 V k l V_{kl} Vkl之后, 再基于Softmax进行归一化以保证其之和为1.
最终,基于上一次数据分布 D t D_{t} Dt和当前计算的 V k l V_{kl} Vkl就可以决定下一次data sampler:
 很明显, D t + 1 D_{t+1} Dt+1之和为1,每一项非负, 满足分布的性质. 从而那些prediction variance较高的样本更容易在下一次被选中用于训练.
很明显, D t + 1 D_{t+1} Dt+1之和为1,每一项非负, 满足分布的性质. 从而那些prediction variance较高的样本更容易在下一次被选中用于训练.
讨论:
1. Primary classifier和Auxiliary classifier的区别在哪儿?
两个classifier产生discrepancy的output的原因: (1) 输入的features不是同一粒度,(2) classifier模块之前加了 dropout操作.
2. Adaptive data sampler的优势?
(1) 无需目标域的label;(2) 明确关注input data distribution -> samples with high uncertainity -> learn complementary information.
Aggregation
接下来看如何解决Question-2,
在经典的AdaBoost中需要以序列的方式保存所有的weak leaner, 这种方式实际上非常占用memory, 这里作者遵循Mean Teacher 的思路应用移动加权平均来保持之前所有Epoch的一个加权平均模型.
 这样一来,每到一个新的Epoch, 采用如下方式进行鲁棒聚合:
这样一来,每到一个新的Epoch, 采用如下方式进行鲁棒聚合:
 这种方式一方面解决了权重的确定问题, 另一方面 鲁棒加权更能作出稳定的预测, 同时避免了耗费大量内存来保存所有的weak learner.
这种方式一方面解决了权重的确定问题, 另一方面 鲁棒加权更能作出稳定的预测, 同时避免了耗费大量内存来保存所有的weak learner.
优化
总的损失由分割损失和正则化项组成,
 源域的segmentation loss定义如下:
源域的segmentation loss定义如下:
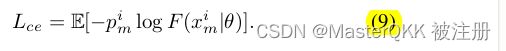
AdaBoost Student
![[论文评析]Adaptive Boosting for Domain Adaptation: Towards Robust Predictions in Scene Segmentation,TIP_第4张图片](http://img.e-com-net.com/image/info8/d6f0b8f480994fa2989f158c338101dc.jpg)
总结
总体思路清晰, 实验证实确实很有效. 简单来说就是想办法把AdaBoost 用到Domain Adaption中, 提出了相应的办法来解决用的过程中出现的两个问题,
没有那么多弯弯扰扰, 很好奇, 之前居然都没有人这样尝试,
Reference
1.Zheng, Zhedong, and Yi Yang. “Adaptive boosting for domain adaptation: Towards robust predictions in scene segmentation.” arXiv preprint arXiv:2103.15685 (2021).