【语音算法】wav2vec系列原理和使用
文章目录
- 前言
- 1. wav2vec
- 2. vq-wav2vec
- 3. wav2vec2.0
-
- 3.1 encoder
- 3.2 context
- 3.3 wav2vec2.0的使用(transformers库)
- 参考文献
前言
wav2vec系列工作由facebook AI Research团队提出,包括wav2vec、vq-wav2vec、wav2vec2.0,效仿nlp上的word2vec,是语音的一种通用特征提取器。本文重点讲解wav2vec2.0模型及其使用方法。
1. wav2vec
论文:wav2vec: Unsupervised Pre-training for Speech Recognition
本文提出一种无监督的语音预训练模型 wav2vec,可迁移到语音下游任务。模型结构如下图,分为将原始音频x编码为潜在空间z的 encoder network(5层卷积),和将z转换为contextualized representation的 context network(9层卷积),最终特征维度为512x帧数。目标是在特征层面使用当前帧预测未来帧。

2. vq-wav2vec
论文:vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations
本文基于wav2vec,将连续特征z通过提出的量化模块,变成离散特征z‘,实现特征空间从无限的连续到有限的离散的转换过程。文中提出了两种量化方法,Gumbel softmax和K-Means,如下图。 其中,左右两个部分中的 e1 … ev,就是码本(记录特征集,可以理解为 BERT 中的词表),Gumbel通过逻辑值最大化(回传时使用Gumbel softmax来保证可导)找对应码本条,K-Means通过计算与码本距离来找最小距离的码本条。

3. wav2vec2.0
论文:wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
本文基于wav2vec,结合了vq-wav2vec的量化模块和Transformer,提出了wav2vec2.0,如下图。其中,encoder network基于CNN,而context network基于Transformer,任务是在特征层面恢复被mask的量化的帧。

模型的整体结构如下图,以下具体讲解结构。

3.1 encoder
feature extractor 使用了7层的一维CNN,步长为(5,2,2,2,2,2,2),卷积核宽度为(10,3,3,3,3,2,2)。
对于x=16000的输入语音,各卷积层输出的时间维度为:
cnn0 (16000-10)/5+1 = 3199
cnn1 (3199-3)/2+1 = 1599
cnn2 (1599-3)/2+1 = 799
cnn3 (799-3)/2+1 = 399
cnn4 (399-3)/2+1 = 199
cnn5 (199-2)/2+1 = 99 (除法有小数,向下取整)
cnn6 (99-2)/2+1 = 49 (除法有小数,向下取整)
因此,对于16k采样率的1s的语音对应矩阵(1,16000),channels大小为512,对应的输出为 (512,49),时间维度上约相当于每20ms产生一个512维的特征向量,但实际上每一帧都经过多层卷积,可见到的时间不止20ms。
另外,在cnn0使用了GroupNorm,在cnn1-6的输出使用了GELU。
(feature_extractor): Wav2Vec2FeatureEncoder(
(conv_layers): ModuleList(
(0): Wav2Vec2GroupNormConvLayer(
(conv): Conv1d(1, 512, kernel_size=(10,), stride=(5,), bias=False)
(activation): GELUActivation()
(layer_norm): GroupNorm(512, 512, eps=1e-05, affine=True)
)
(1): Wav2Vec2NoLayerNormConvLayer(
(conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
(activation): GELUActivation()
)
(2): Wav2Vec2NoLayerNormConvLayer(
(conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
(activation): GELUActivation()
)
(3): Wav2Vec2NoLayerNormConvLayer(
(conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
(activation): GELUActivation()
)
(4): Wav2Vec2NoLayerNormConvLayer(
(conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
(activation): GELUActivation()
)
(5): Wav2Vec2NoLayerNormConvLayer(
(conv): Conv1d(512, 512, kernel_size=(2,), stride=(2,), bias=False)
(activation): GELUActivation()
)
(6): Wav2Vec2NoLayerNormConvLayer(
(conv): Conv1d(512, 512, kernel_size=(2,), stride=(2,), bias=False)
(activation): GELUActivation()
)
)
)
3.2 context
整体结构图中的context包括左右两部分,左边负责将z转换成c(对应wav2vec2特征),右边负责将z离散化以计算损失。
左边部分中,对于输入512x50的z,有:
post_extract_proj: 768x50
apply_mask->pos_conv->LN: 768x50
Transformer*12: 768x50
choose_masking: 768xM,M为mask的帧数
final_proj: 256xM
右边部分中,对于输入512x50的z,有:
choose_masking: 512xM
quantizer: 256xM
project_q: 256xM
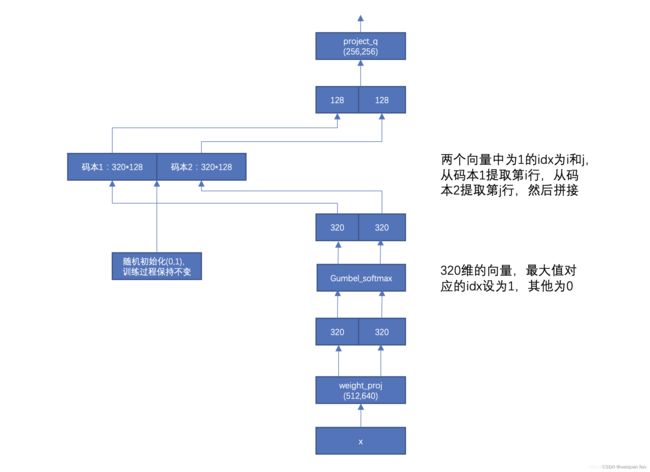
其中,量化的参数有:码本个数G=2,每个码本的条目个数V=320,条目的维度d/G=256/2=128。参数含义:G=latent_groups,V=latent_vars,d=vq_dim。
具体的quantizer流程如下图所示,前向的时候直接找出来最大值对应的码本中的条目,相当于是一个离散的操作,但是这个步骤不可导,无法进行反向传播,为了解决这个问题,采用了gumbel softmax操作。
3.3 wav2vec2.0的使用(transformers库)
import soundfile as sf
import torch
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h") # 用于ASR等,32维
audio_input, sample_rate = sf.read(path_audio) # (31129,)
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values # torch.Size([1, 31129])
logits = model(input_values).logits # torch.Size([1, 97, 32])
predicted_ids = torch.argmax(logits, dim=-1) # torch.Size([1, 97])
transcription = processor.decode(predicted_ids[0]) # ASR的解码结果
from transformers import Wav2Vec2Model
model = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-base-960h") # 用于提取通用特征,768维
wav2vec2 = model(input_values)['last_hidden_state'] # torch.Size([1, 97, 768]),模型出来是一个BaseModelOutput的结构体。
参考文献
https://blog.csdn.net/xmdxcsj/article/details/115787729