你应该知道的机器学习模型部署细节和实施步骤
机器学习操作 (MLOps,Machine Learning Operations ) 是“机器学习”和“工程”的组合,涵盖了与生产 ML 生命周期管理有关的所有内容。

ML模型生命周期可大致分为三个阶段
文章目录
-
- 技术交流
- 设计
- 模型开发
- 操作
- 步骤1:确定部署环境
-
- 命令行终端
- Conda虚拟环境
- 编辑器与IDE
- 深度学习框架
- 步骤2:代码管理
-
- Git
- 代码组织
- 良好的编程习惯
-
- 代码文档
- 编程风格
- 类型声明 Typing
- 数据版本管理
- 步骤3:Docker与可复现性
- 步骤4:调试与分析代码
-
- 调试
- 性能优化
- 实验日志
- Trainer模板
- 步骤5:持续集成
- 步骤6:部署模型
-
- HTTP协议
- 本地部署
技术交流
技术要学会分享、交流,不建议闭门造车。 本文技术由粉丝群小伙伴分享汇总。源码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:dkl88191,备注:来自CSDN +技术交流
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
设计
初始阶段从调查问题开始,然后筛选可选的模型框架。由于机器学习需要训练数据,因此我们还会在这一步中调查我们拥有哪些数据以及是否需要以其他方式获取数据。
模型开发
开始设计一些机器学习算法来解决我们的问题,然后需要进行部分数据分析,选择特定的模型架构。最后还需要进行验证和测试,以确保我们的模型能够很好地泛化。
操作
操作是创建一个自动管道的地方,它确保每当我们对代码库进行更改时,它们都会自动合并到我们的模型中,这样我们就不会减慢生产速度。同样重要的还有对已部署模型的持续监控,以确保它们的行为与我们指定的完全一致。
需要注意的是,这三个步骤实际上是一个循环,这意味着我们已经成功部署了一个机器学习模型,这并不是它的结束。比如需求可能会发生变化,模型从新进行设计阶段。
步骤1:确定部署环境
命令行终端
终端是在您的计算机没有可以与之交互的图形界面的时候创建的,是为计算机的文本界面。
终端可以任意位置的机器进行操作,可以发送准确的命令。这里我们建议大家学习使用Linux的终端:
-
跳转目录,运行某个程序
-
将程序允许结果重定向到文件
-
查看文件内容,并修改文件
Conda虚拟环境
Conda 是一个环境管理器,可以帮助不同项目的依赖项不会相互交叉污染。但是安装 conda 是一回事,实际使用它是另一回事。
首先要区分pip 和 conda:
-
pip用来安装 python 包(以 python wheels 和发行版的形式),而 conda 也可以安装用其他语言编写的包,因为它是从二进制文件安装的
-
pip 以序列化递归方式安装依赖项,这意味着它可能会导致依赖项问题,而conda 在安装任何东西之前首先检查所有依赖项以检查兼容性。
-
pip绑定了特定的python版本,而conda可以同时管理多个python版本
在开发多个项目,或者需要切换Python时,强烈建议使用 conda 环境。这里建议大家学习使用conda来管理环境:
-
使用 conda 创建和切换环境
-
使用 pip 在该环境中安装包
当然pip 和 conda 并不是 Python 仅有的两个环境管理器。Pipenv 是另一种经常使用的替代方案。
编辑器与IDE
Notebook非常适合开发简单代码以及解释和可视化代码库。但器学习项目需要处理多个 .py 文件,因此要真正“完成工作”,需要一个好的编辑器或IDE。
如果你还没有安装编辑器,强烈推荐 Visual studio code。当然在终端环境下,我们推荐掌握 vim。
Notebooks 允许开发人员轻松测试我们的新想法。但是当实际需要部署模型时,它们通常会导致痛点。在开完完成后,将Notebook转换为 .py 脚本很简单:
jupyter nbconvert --to=script my_notebook.ipynb
深度学习框架
关于深度学习框架,主要由四个主导:
-
PaddlePaddle
-
Pytorch
-
JAX
-
Tensorflow

我们不会就哪种框架最好进行更长时间的讨论,因为它毫无意义。Pytorch 和 Tensorflow 存在时间最长,因此此时拥有更大的社区和功能集。但这些框架它们都非常相似,因为它们都具有针对研究和生产的特征。
步骤2:代码管理
在大型团队中工作时,将不同的人组织和编写代码的方式的差异最小化是至关重要的。
Git
与其他人的适当协作将在同一代码库上工作,这就是版本控制存在的原因。需要注意的是Github不是git!,Github是一家提供免费存储库托管的公司。
在使用git时,我们推荐掌握:
-
fork项目,修改代码
-
提交代码,合并代码
代码组织
代码组织可以简单理解为代码目录,比如安装代码存储在什么位置,Notebook存储在什么位置。常见的项目文件组织如下:
project
│ README.md
| notebook
| data
└───src
│ │ utils.py
| | ...
| ...
代码组织的标准化确实遵循一些特定的规则,从而使一个人能够更快地理解另一个人的代码。代码组织不仅是为了使代码更易于您维护,而且还便于其他人阅读和理解。
良好的编程习惯
要了解什么是良好的编码习惯,重要的是要了解它不是什么:
-
确保您的代码快速运行
-
确保您使用特定的编码范例
-
确保只使用很少的依赖项
代码文档
大多数程序员对文档都有一种爱恨交加的关系:我们绝对讨厌自己编写文档,但喜欢别人花时间将它添加到他们的代码中。
文档比代码更容易维护,但也需要更多的时间。好的文档比编写文档节省的时间更多。
在文档下可以记录从代码中清晰可见的信息,而不是实际上难以理解的复杂部分。而写太多的文档对大多数人来说会产生与你想要的相反的效果:有太多的东西要读,所以人们会跳过它。
编程风格
当从事个人项目时,这种编码风格的差异并不那么重要,但当多个人一起从事同一项目时,考虑这一点很重要。
Pep8 是 python 的官方风格指南,包含了编写 Python 时被认为是“好的做法”和“坏的做法”。
类型声明 Typing
除了编写文档和遵循特定样式之外,在 Python 中也推荐使用Typing。Typing可以追溯到早期的编程语言,如 c、c++ 等。
Typing可以提高代码的可读性,可以直接从代码中读取输入参数和返回值的预期类型。
数据版本管理
DVC(数据版本控制)是 git 的扩展,它不仅可以获取版本控制数据,还可以获取一般的模型和实验。
DVC将只跟踪元文件,然后该元文件将指向存储原始数据的某个远程位置。图元文件本质上用作数据文件的占位符。
步骤3:Docker与可复现性
项目可重复性的非常重要,可重复性与科学方法密切相关:
观察 -> 问题 -> 假设 -> 实验 -> 结论 -> 结果 -> 观察 -> …
如果实验是不可重现的,那么我们就不指望别人能得出和我们一样的结论。由于机器学习实验与在实验室中进行化学实验基本相同,因此我们应该同样小心确保我们的环境是可重现的。

创建 MLOps 管道的一个重要部分是您能够重现它。为了获得可重复性,我们需要确定系统环境,例如:
-
操作系统
-
软件环境
Docker 通过创建独立的程序提供可重复性。Docker是系统级可重现的,无论在单台机器上还是在 1000 台机器上都没有关系。
Docker主要有三个概念:docker file,Docker image和docker container:
-
Docker file:是一个基本的文本文档,包含用户可以在命令行上调用以运行应用程序的所有命令。包括安装依赖项、从在线存储中提取数据、设置代码以及要运行的命令。
-
Docker image:更准确地说构建一个Docker文件将创建一个Docker镜像。镜像是一个轻量级的、独立的/容器化的、可执行的软件包,其中包括使应用程序运行所需的一切。
-
Docker container:运行创建一个 Docker 容器。这意味着可以多次启动同一个镜像,从而创建多个容器。
步骤4:调试与分析代码
调试
调试非常难教,因为其是经验带来的技能之一。我们可能都熟悉在我们的代码中到处插入 print(…) 语句,这可以帮助我们缩小问题发生的范围。但处理非常大的代码库时,print就不是一种很好的调试方式。
要在 python 调试器中调用构建,可以通过调用设置跟踪:
import pdb
pdb.set_trace()
性能优化
分析代码是为了提高代码的性能。在优化代码之前首先需要明确两个问题:
-
我的代码中每个方法被调用了多少次?
-
每种方法需要多长时间?
第一个问题对优先级优化很重要。如果两个方法 A 和 B 的运行时间大致相同,但 A 的调用次数比 B 多 1000 次,如果我们想加速代码,我们可能应该花时间优化 A 而不是 B。
通过探查器可以帮助您找到代码中的瓶颈。cProfile 是 pythons 内置的分析器,可以帮助您了解程序中涉及的所有函数和方法的运行时概况。
实验日志
实验记录或模型监控是了解模型正在发生的事情,它可以帮助调试模型。最基本的日志记录是将模型生成的指标写入终端或文件以供以后检查。
在进行较小的实验或单独处理一个项目时,这种工作流程可能就足够了,但是在与他人合作进行大规模实验时,合适的实验跟踪器和可视化工具更加重要。
有许多工具可用于记录实验:
-
Tensorboard
-
Comet
-
MLFlow
-
Neptune
-
Weights and Bias
Trainer模板
模板描述了任何标准化的文本、副本、文档、方法或程序,可以在不对原始文件进行重大更改的情况下再次使用。
但这与机器学习项目有什么关系?如果你已经在机器学习领域尝试过几个项目,可能会看到一个模式:每个项目通常都包含以下三个方面的代码:
-
模型实现
-
模型训练代码
-
保存模型和日志代码
虽然后两者看起来当然很重要,但在大多数情况下,实际的开发或研究往往围绕着定义模型展开。
从这个意义上说,训练代码和实用程序都变成了样板,应该从一个项目转移到另一个项目。但问题通常是我们没有概括我们的训练代码来处理未来项目中可能需要的小调整,因此我们每次开始一个新项目时都会一遍又一遍地实施它。
Pytorch 生态系统中最受欢迎的高级(训练)框架是:
-
fast.ai
-
Ignite
-
skorch
-
Catalyst
-
Composer
-
Pytorch Lightning
它们都提供许多相同的功能,因此对于大多数项目来说,选择一个而不是另一个并不重要。
步骤5:持续集成
持续集成是训练数据或数据处理,更新模型架构,基本所有任何代码更改都会对最终结果产生影响。
在讨论持续集成时,许多开发人员经常想到的是代码测试。CI 应该确保无论何时更新代码库,它都会自动进行测试,这样如果代码库中引入了错误,就会及早发现。
我们将要查看的测试类型称为单元测试。单元测试是指编写测试代码库的各个部分以测试其正确性的测试实践。Python 提供了几个不同的库来编写测试,比较常用的是pytest。
步骤6:部署模型
当我们谈论请求时,本质上是在谈论客户端-服务器类型的架构中使用的通信方法。在此架构中客户端(用户)将向服务器(我们的机器学习应用程序)发送请求,服务器将给出响应。
HTTP协议
发送请求的常用方式称为 HTTP。它本质上是对客户端和服务器之间的中间传输方式的一种规范。一个 HTTP 请求基本上由两部分组成:
-
请求 URL:服务器的位置
-
请求方法:执行什么操作

常见的请求方式有(区分大小写):
-
GET:从服务器获取数据
-
POST/PUT:向服务器发送数据
-
DELETE:删除服务器上的数据
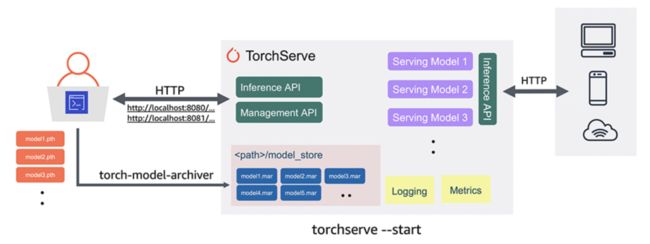
本地部署
模型提供服务的第一个起点应该始终是在本地部署它。部署到云比本地部署花费的时间要长得多。因此本地应该始终是任何新应用程序的第一步。
编译是将用一种语言编写的计算机程序翻译成另一种语言的任务。在大多数情况下,这意味着采用您使用首选编程语言编写的任何内容,并将其翻译成计算机可以执行的机器代码。Pytorch 自带编译器,可以帮你优化模型。它可以在子模块 torch.jit 中找到。