一行代码搞定数据分析——pandas_profiling
数据分析神器——pandas_profiling
本文首发于微信公众号《Python希望社》,点击这里就可查看完整全文。欢迎关注,定时持续更新python学习干货
对于从事数据科学相关行业的人员来说,如何简单高效地实现对数据集的初步分析是后续一切工作的重要基础。今天我们就为大家介绍一种基于python的数据分析神器——pandas_profiling
本文构成大纲如下图所示,全文约2000字,完成阅读约2分钟。文本有惊喜哦~
一、一些传统的数据分析方法
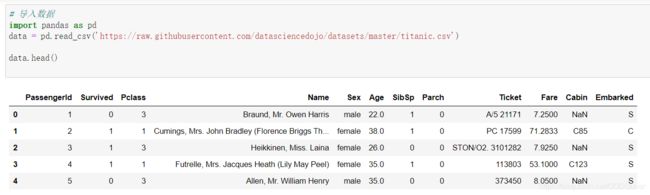
先看下数据大致是什么样的呢?
# 导入数据
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')
data.head()
再来对数据进行统计描述
data.describe()

最后来看看变量的信息和缺失情况吧~
data.info()

尽管上面这些对数据进行了初步的分析并给出了一些基本的数据概况。但在处理大型数据集的时候能起到的帮助非常有限,如何才能在比赛或者工程应用中全面、高效、深入地了解数据集呢?
二、数据分析神器–pandas profiling
与之相对的,使用pandas profiling 提供的 df.profile_report()函数,你只需要一行代码就能快速生成一个包含了大量详细信息的交互式HTML报告。 他是基于scipy、matplotlib、seaborn等工具的展示
- 要点:类型,唯一值,缺失值
- **分位数统计信息,**例如最小值,Q1,中位数,Q3,最大值,范围,四分位数范围
- **描述性统计数据,**例如平均值,众数,标准偏差,总和,中位数绝对偏差,变异系数,峰度,偏度
- 最常使用的值
- 直方图
- 高相关变量Spearman,Pearson和Kendall矩阵的相关性突出显示
- 缺失值矩阵,计数,热图和缺失值树状图

包库的安装
# 利用终端命令安装
pip install pandas -profiling
# 直接从git-hub上安装最新版本:
pip install https://github.com/pandas-profiling/pandas-profiling/archive/master.zip
# 利用conda软件包管理器进行安装:
conda install -c anaconda pandas-profiling
注意:在安装这个包的过程后,如果运行在以下案例中出现报错。这很有可能是包的版本导致的可执行以下命令解决:
(小编当初也是百思不得其解,哪里出了问题,百度了很久也没发现相关信息。几近崩溃准备卸载软件重头再来之时,在一个国外分享交流网站上终于查到问题源头所在)
pip uninstall pandas-profiling
pip install pandas-profiling[notebook,html]
如果觉得pip下载速度较缓慢,可更改为使用国内镜像。关于这方面资料网上很多,在此权且略过。
如安装过程遇到了其他任何问题,欢迎交流或者加入我们的微信交流群~
包你学废!
案例展示
话不多说,砸门直接上实例。让我们祭出古老而又经典的泰坦尼克号数据,来展示一下这个预览分析器的强大能力吧。
# 导入包库和数据
import pandas as pd
from pandas_profiling import ProfileReport
data = pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')
只需一行代码即可生成对应的数据分析报告,这份数据报告十分详细,包括了所有必要的图表。
# 生成并展示你的报告
profile = ProfileReport(data,title="这是一份来自python希望社的教程,你可以编辑这里更改标题")
profile
得到展示结果如下所示
你还可以通过下面的代码将结果导出为一个交互式的 HTML 文件:
profile = df.profile_report(title='Pandas Profiling Report')
profile.to_file(outputfile="Titanic data profiling.html")
进一步的深入探索。
下面的示例代码加载了explorative configuration file(探索性配置文件),它包含了许多用于文本(长度分布、unicode信息),文件(文件大小,创建时间)和图像(尺寸、exif信息)的功能。
profile = ProfileReport(data,title="Title!", explorative=True)
除了上述的简单命令外,你还可以添加一些其他除了标题以外的参数进行你个性化的配置。
title(str):报告的标题(默认为“熊猫分析报告”)。pool_size(int):线程池中的工人数。设置为零时,它设置为可用的CPU数量(默认为0)。progress_bar(bool):如果为True,pandas-profiling将显示进度条。
其他编辑器的配置
估计这会儿有聪明的同学会问了:那如何在pycharm上实现这种操作呢?
别担心,pandas_profiling 还提供了pycahrm的配置方法。你只需要按着下面的步骤一步一步来就好了
配置方法:
-
安装包库,方法同上
-
找到你的
padnas_profiling的.exe可执行文件# mac OS/Linux/BSD 默认情况下 (example) /usr/local/bin/pandas_profiling # Windows 默认情况下 (example) C:\ProgramData\Anaconda3\Scripts\pandas_profiling.exe # 以小编为例 G:\Anaconda\Scripts\pandas_profiling.exeTips: 获取文件绝对路径
右键该文件—属性—安全—对象名称
-
Pycharm:
file—seting—Tools—External Tools—+ -
进行如下配置:
Name:pandas_profilingProgram:粘贴进***步骤二中的位置***Arguments:“ $ FilePath $”“ $ FileDir $ / $ FileNameWithoutAllExtensions $ _report.html”Working directory:$ ProjectFileDir $
使用方法:
在完成配置后,同样滴。我们先来运行以下代码:
# 导入包库和数据
import pandas as pd
from pandas_profiling import ProfileReport
data = pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')
# 生成你的报告 (pycharm并不能直接展示)
profile = ProfileReport(data,title="这是一份来自python希望社的教程,你可以编辑这里更改标题")
运行结束后,我们只需要在代码栏左侧项目栏里右键external_tool中的pandas_profiling即可生成对应的EDA,并以html格式默认保存在同一路径之下。
对于其他编辑器你也可以通过发送请求提供相应的支持,具体细节可参考官方文档。
至此,我们就已经全部完成了关于pandas_profiling的安装、介绍及使用。各位观众还在犹豫什么呢?赶快抄起你的电脑来试试吧~
码字不易,希望各位观众朋友们点个关注再走吧。点击关注不迷路,满满干货为你出