39.Isaac教程--使用 Pose CNN 解码器进行 3D 物体姿态估计
使用 Pose CNN 解码器进行 3D 物体姿态估计

ISAAC教程合集地址: https://blog.csdn.net/kunhe0512/category_12163211.html
文章目录
- 使用 Pose CNN 解码器进行 3D 物体姿态估计
-
- 应用概述
-
- 推理模块
- Pose CNN 解码器训练模块
- Pose CNN 解码器架构
- Pose CNN解码器训练
-
- 从场景二进制文件生成样本对象数据:Industrial Dolly 和 Industrial Box
- 从场景源文件为自定义对象生成数据
- 运行 Pose CNN 解码器训练流程
- 存储生成的数据以供离线训练和验证
- 运行训练应用
- 运行推理
-
- 推理示例
- 3D 物体姿态估计评估
-
- 使用模拟收集评估数据
- 姿势估计评估
- 姿势估计推理记录
- 评估指标计算
物体检测和 3D 姿态估计在机器人技术中起着至关重要的作用。 导航、对象操作和检查等各种应用都需要它们。 Isaac SDK 中的 3D 对象姿态估计应用程序提供了一个框架,可以完全在模拟中训练任何模型的姿态估计,并在模拟和现实世界中测试和运行推理。
此应用程序将 Isaac SDK Pose CNN 解码器架构用于其 3D 姿势估计模型。 该架构基于 Sundermeyer 等人的工作。 Xiang 等人的 PoseCNN。 给定 RGB 图像,该算法首先使用 Isaac SDK 中可用的任何对象检测模型从具有可用 3D CAD 模型的一组已知对象中检测对象,然后使用 Pose CNN 解码器模型估计它们的 3D 姿势。 此应用程序和网络架构旨在通过利用 GPU 加速实现低延迟、实时对象检测和 3D 姿态估计,同时实现良好的准确性。
与 Isaac SDK 中基于自动编码器的 3D 姿态估计算法相比,该应用具有以下特点:
更人性化:省去了生成码本和码本查找的额外中间步骤。
可以使用单个经过训练的模型处理多个对象类:另一方面,自动编码器需要为每个对象类使用单独的经过训练的模型和代码本。
更强大的抗遮挡能力:网络学习直接从边界框参数和输入图像预测对象中心。
应用概述

该应用程序由两个模块组成:
-
推理模块
-
一个 Pose CNN 解码器训练模块
推理模块
推理模块由两个子模块组成:对象检测和 3D 姿态估计。 对象检测子模块接受 RGB 图像并使用 Isaac SDK 中可用的任何对象检测模型确定感兴趣对象的边界框。 目前,示例应用程序文件支持 Isaac 的 DetectNet 对象检测推理模型。 3D 姿态估计子模块根据边界框裁剪图像,并估计每个裁剪图像中对象的 3D 姿态。 为了估计物体的 3D 姿态,该模块需要一个经过训练的 Pose CNN 解码器神经网络,该神经网络接受裁剪图像及其相应的边界框参数(即边界框大小和中心)作为输入。
Pose CNN 解码器训练模块
Pose CNN 解码器训练模块为对象或对象列表训练神经网络。 该模块使用编码器-解码器架构的变体以及回归层来估计对象的 3D 姿态。 它训练解码器神经网络将输入的 RGB 图像重建为不受遮挡影响的分割图像,从而迫使网络学习对象形状,而不管遮挡和其他噪声、背景和光照条件如何。
训练模块需要基于用户提供的对象的 3D CAD 模型的模拟颜色和分割图像数据。 此应用程序还提供了一个使用 Unity 引擎和 Isaac Sim Unity3D 的模拟数据生成模块,该模块为给定对象的 3D CAD 模型生成模拟数据。 但是,训练应用程序与用于生成数据的模拟平台无关,可以用任何其他模拟引擎替换,例如基于 NVIDIA Omniverse 套件的 Isaac Sim。
Pose CNN 解码器架构
Pose CNN 解码器网络接受两个输入:裁剪后的 RGB 图像和边界框参数。 该网络使用两个编码器来提取图像的特征,以及边界框,并连接特征空间。 该网络使用连接的特征空间将裁剪图像解码为去噪分割图像,并通过将其作为回归问题来估计对象 3D 姿态的平移和旋转参数。
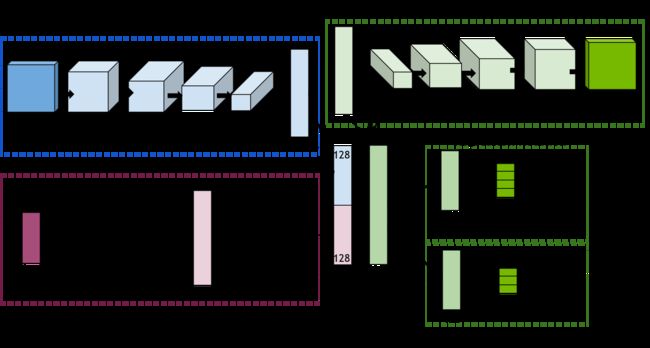
输出分割图像的解码器经过训练以去除遮挡并填充对象的遮挡像素。 输出平移参数是相机图像帧中的对象中心 x 和 y 坐标,以及现实世界中相机的深度。 四个旋转参数是物体在相机坐标系中旋转的四元数。 在姿态细化步骤中再次使用分割掩模来裁剪出相关的深度图像点云,并将 3D 姿态估计用作细化姿态的起点。
Pose CNN解码器训练
获取和标记训练 3D 姿态估计模型所需的真实世界数据极具挑战性、耗时且容易出错。 对于机器人技术来说,这个问题尤其严重:机器人需要在各种各样的专门场景中执行姿势估计,因此为每个这样的场景收集大量准确和标记的真实世界数据是令人望而却步的,这反过来又减慢了速度 采用这些模型。
此应用程序使用模拟数据,完全在模拟中训练网络进行 3D 姿势估计,以通过模拟器中可用的功能(例如域随机化和程序生成技术)弥合模拟与真实之间的差距。
Pose CNN 解码器训练阶段包括两个主要步骤:
-
生成模拟数据
-
运行 Pose CNN 解码器训练管道
生成模拟数据
训练 Pose CNN 解码器模型需要三种不同类型的数据:
-
渲染的 RGB 图像
-
分割图像的去噪版本(即,对遮挡不变的分割图像版本)
-
相机和感兴趣对象的 3D 姿势,以计算对象相对于相机的 3D 姿势
从场景二进制文件生成样本对象数据:Industrial Dolly 和 Industrial Box
构建中的 isaac_sim_unity3d 存储库中提供了示例“未来工厂”场景二进制文件,它为两个对象生成上述数据,一个推车和一个盒子。 在 Isaac Sim Unity3D 发布版本中使用以下命令运行二进制文件,以开始发送用于推车姿态估计训练的样本:
bob@desktop:~/isaac_sim_unity3d$ ./builds/factory_of_the_future.x86_64 --scene Factory01 --scenario 8
此命令运行 Factory01 Unity 场景和场景 8,推车姿势估计训练场景。 此场景中的训练数据是通过连接到机器人的摄像头的视点收集的。
使用以下命令在 Isaac Sim Unity3D 发布版本中运行二进制文件,以开始发送用于框姿势估计训练的样本:
bob@desktop:~/isaac_sim_unity3d$ ./builds/factory_of_the_future.x86_64 --scene Factory01 --scenario 10
Isaac Sim Unity3D 通过 TCP 套接字与 Isaac SDK 通信。 isaac/sdk/packages/navsim/apps/navsim.app.json 应用程序设置连接以使用 TcpPublisher 节点将模拟数据发布到用户定义的端口。 训练应用程序使用 TcpSubscriber 在 packages/object_pose_estimation/apps/pose_cnn_decoder/training/training.app.json 接收数据。
从场景源文件为自定义对象生成数据
isaac_sim_unity3d 存储库中的 packages/Nvidia/Samples/ObjectPoseEstimation 中提供了为自定义对象生成训练数据的示例场景。 在 Unity Editor 中打开 pose_cnn_decoder_training.unity 场景。 此示例场景可以生成具有随机背景、遮挡对象、照明条件和相机姿势的数据。
场景配置为使用 TCP 将每个帧的所有三个必需标签流式传输到 Isaac SDK。 场景中的默认兴趣对象是推车。 按照以下步骤为新对象设置场景:
注意
如果感兴趣的对象已经在 packages/Nvidia/Samples/ObjectPoseEstimation/PoseEstimationObjectsGroup 中的组中,则可以跳过步骤 1-3。
-
加载Unity,上传物体的3D CAD模型和贴图,制作预制件。
-
在预制件中,单击添加组件并添加 LabelSetter 脚本。 输入您选择的标签名称。 此脚本创建分割图像并计算边界框。
-
将预制件添加到
packages/Nvidia/Samples/ObjectPoseEstimation中的PoseEstimationObjectsGroup。 为此,请将元素大小增加 1,或者通过将预制件拖放到列表中来将现有预制件与对象的预制件交换。 -
将
packages/Nvidia/Samples/ObjectPoseEstimation/pose_cnn_decoder_training.unity场景拖到 Hierarchy 面板中,并删除面板中的所有现有场景。 -
在
Class Label Rules > dolly > Expression字段中为预制件设置标签名称。 默认名称为“dolly”,这是“Dolly”预制件的标签名称。 标签名称在 Isaac Sim 中用于渲染场景中对象的分割图像。 ClassLabelManager 中的表达式名称可以是您选择的任何名称,默认设置为“Target”。 -
保存场景并播放。
此时,您应该看到墙壁和地板的相机位置、对象、照明和背景物质在每一帧都在变化。 您可以根据需要在 procedural_camera GameObject 及其子 CameraGroup 以及程序 GameObjects 中调整背景、相机位置等的随机化频率。 建议根据对象的大小调整程序相机中 CameraGroup 子对象中 Position 和 Target 配置的 UniformRange 值。 目标是确保数据样本包含所有可能的视点和相机的距离范围。 为 Target 参数添加非零均匀范围可确保对象不会始终呈现在图像帧的中心,这对于获得多样化的翻译训练样本很重要。
注意
相机型号默认设置为使用 42 度的垂直 FOV 和 1280(宽度)x 720(高度)的图像分辨率。 如果您希望针对某些其他相机模型进行训练,可以在作为 CameraGroup 的子对象的 EncoderColorCamera 和 DecoderSegmentationCamera 中的 Field of View 以及 Width 和 Height 中更改这些值。
Isaac Sim 中还提供了姿势估计训练的基本场景设置,使用 OV 套件开始使用样本立方体。 此处的文档中提供了有关场景设置的详细信息。 该场景被编写为使用与 Unity 场景设置相同的通道名称通过 TCP 发送示例立方体所需的姿势、编码器和解码器图像。 因此,Isaac SDK 中的训练管道也可以重新用于基于 Omniverse 的训练场景。 但是,由用户添加所有必需的域随机化,如背景、光照、纹理、颜色,并设置训练所需的相机姿势随机化,以确保数据样本满足推理设置的要求。 可以在此处找到有关 Isaac Sim 中域随机化的更多详细信息。
运行 Pose CNN 解码器训练流程
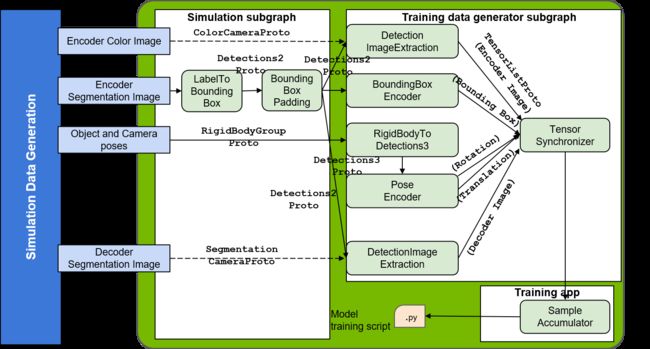
Isaac SDK 提供两种训练姿势估计模型的模式:在线和离线。 在在线训练期间,数据是在模拟中动态生成的,并被引入训练管道。 这种训练模型的主要优点是可以使用无限量的数据来训练网络。 然而,同时运行模拟数据生成和训练网络是一项计算密集型任务,并且在没有多个 GPU 可用的情况下会减慢训练速度。 在这种情况下,离线进行训练很有用,用户首先生成并保存有限数量的标记数据用于训练,然后单独进行训练。 上图说明了在线训练和小码连接的训练应用程序。 在离线训练的情况下,最后的 SampleAccumulator 节点被替换为数据生成节点。
存储生成的数据以供离线训练和验证
在离线训练开始之前,通过运行模拟场景和 Isaac SDK 存储库中提供的数据生成应用程序 (packages/object_pose_estimation/apps/pose_cnn_decoder/training/generate_training_validation_data.app.json) 生成并保存固定数量的数据。 此应用程序还会生成验证数据,以随着训练的进行评估训练网络在未见固定数据集上的性能。 如果你想在训练过程中进行不验证的在线训练,你可以跳过这一步。
在运行应用程序之前,使用应用程序包/object_pose_estimation/apps/pose_cnn_decoder/training/generate_training_validation_data.app.json 中的相应配置参数 num_training_samples 和 num_validation_samples 在 GeneratePoseCnnDecoderData 组件中设置所需训练和验证数据样本的数量。 如果是在线训练,请将num_training_samples设置为0。另外,使用自定义Unity场景时,将场景参数设置为场景名称pose_cnn_decoder_training,将对象的预制件名称设置为data.simulation.scenario_manager组件中的robot_prefab参数。 要将未来场景的工厂用于工业小车和箱子,请将场景名称设置为 Factory01。 要生成数据,请在 Isaac SDK 存储库中使用以下命令运行应用程序
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder/training:generate_training_validation_data
训练和验证数据默认分别保存在/tmp/pose_data/training 和/tmp/pose_data/validation 中。
运行训练应用
对于在线训练,模拟场景必须仍在并行运行。 训练配置可以在 packages/object_pose_estimation/apps/pose_cnn_decoder/training/training_config.json 文件中设置。 训练模式通过将“online_training”配置参数设置为在线训练的“true”和离线训练的“false”来配置。 在在线训练的情况下,将配置参数场景设置为 pose_cnn_decoder_training 并将 robot_prefab 设置为自定义 Unity 场景模拟中要生成的对象的预制名称。 默认场景名称为“Factory01”,对应未来场景的工厂。 要使用提供的未来场景工厂在线训练 Industrial Dolly,请在训练配置文件中将 decoding_full_object 参数设置为 false。 这使解码器能够训练仅解码没有轮子的小车框架,从而使姿势对于此用例的轮子随机化更加稳健。 在离线训练的情况下,保存训练数据的路径在training_data_dir中设置。 默认目录为/tmp/pose_data/training,这是离线数据生成步骤中为存放验证数据而生成的目录。 运行训练的 gpu 可以使用配置参数 gpu_visible_device 设置,默认设置为“0”。 如果您的系统上有多个 GPU,建议在与运行模拟的不同的 gpu 上运行训练,以提高在线训练的训练速度。
默认情况下,日志和检查点存储在 /tmp/autoenc_logs/ckpts 中,但可以使用配置文件中的 train_logdir 配置选项更改此路径。 默认情况下,训练应用程序从训练迭代 0 开始运行,直到迭代次数等于 training_config.json 文件中给定的 training_step 值。
要从中间检查点开始训练,请将检查点配置选项设置为相应的检查点文件名,默认情况下的格式为 model-。 该脚本提取数字,附加“model-”作为检查点编号,并从该迭代编号重新开始。 例如,如果要从迭代编号 10000 重新开始,请将检查点设置为模型 10000。 然后,步数将从 10000 开始,以 training_steps 配置选项的值结束,该选项默认设置为 50000。
训练的默认学习率在配置选项 learning_rate 中设置为 2e-4 并且可以在前 20000 次左右的迭代后降低到 1e-4 以促进训练并进一步减少错误。
如果您需要在固定模拟数据训练期间验证模型,请将验证配置选项设置为“true”,并在 validation_data_dir 中指定保存验证数据的路径。 这里默认设置为/tmp/pose_data/validation,这是离线数据生成步骤生成的用于存放验证数据的目录。 在验证步骤中,计算并存储姿势估计误差指标,如平移和旋转中的中值误差,以及日志目录中的相应迭代次数。 验证数据样本的数量和验证频率分别在配置选项 num_validation_data 和 validation_every 中设置。
从模型输出计算误差指标需要有关实际相机的针孔模型和裁剪前图像尺寸的信息——这些值在配置选项 pinhole_focal、pinhole_center 和 image_dim 中提供。 这些参数的默认选项设置为相机垂直 FOV 为 42 度且图像分辨率为 720 x 1280 的训练场景设置。用户还需要指定旋转和平移误差阈值以计算精度指标(验证数据的分数 在设置的错误阈值内)分别使用配置选项 rotation_err_threshold(默认为 10 度)和 translation_err_threshold。 误差指标是根据其地面真实深度(与相机的距离)在 depth_roi 配置选项指定的感兴趣范围内的样本计算的。 默认设置为 [1.7, 3.5],这意味着姿态的平均误差度量仅在验证数据中的样本中计算,其对象与相机的距离在 1.7 m 到 3.5 m 的范围内。 将其设置为“无”会计算所有验证数据样本的指标。
validation config options后面的参数主要和pose网络架构相关,可以保留默认值,除非你需要试验网络架构值,比如encoder中的filters数量,decoder架构,filter sizes 、潜在向量和改变网络大小的全连接层大小。 还有一些选项可以使用配置参数 translation_loss 和 rotation_loss 来设置平移和旋转损失函数。 翻译损失的可用选项是“L1”、“L2”,它们计算翻译值的 L1 和 L2 损失。 以下是旋转损失的可用选项:
-
“AcosLoss”:默认值,其中误差函数是预测标签和估计标签的四元数点积的反余弦,即以弧度为单位的旋转误差。
-
“PLoss”:这个损失函数计算单位立方体角点在用预测和地面真实旋转旋转后的距离的 L2 误差。
最后,还有两个重要的配置选项对应物体的对称轴:symmetry_axes,设置为旋转对称轴的索引,0、1、2分别代表x、y、z轴; num_rotation_symmetry,设置为围绕“symmetry_axes”的对称轴数。 这些配置参数对于通过考虑对象的对称性来计算旋转损失函数很重要。
现在,使用以下命令运行训练应用程序:
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder/training:pose_estimation_cnn_training
要查看 TensorBoard 上的训练进度,请在终端中运行以下命令:
tensorboard --logdir=/tmp/autoenc_logs/ckpts
可以在 http://localhost:6006 访问可视化界面。 从模拟引擎接收到的图像以及边界框可以在 http://localhost:3000 的 Sight 中可视化。
注意
如果 TensorBoard 中的解码器输出在 10 次迭代内看起来全黑或全白,请将 training_config.json 文件中的 add_noise_to_image 设置更改为“true”。 这会增加图像的噪声,从而防止训练变量饱和。 您现在应该开始看到黑白像素的组合,而不是完全黑/白的图像。 如果需要,您可以在几百次迭代后将选项重置为“false”以训练更清晰的图像。
注意
根据对象的类型,模型可能不需要默认的 50000 个训练步骤。 如果作为模型输出的重建解码器图像在多个训练样本中清晰可见,则可以更快地结束训练。 这是确定模型质量的一个很好的检查。 您可以在 TensorBoard 图像部分查看重建图像。 此外,您可以根据示例模拟数据评估模型,以确保误差指标在用例可接受的范围内。 本章最后几节详细介绍了执行姿势估计评估的说明。
冻结的 TensorFlow 模型仅在训练结束时生成(即当迭代次数等于 training_steps 配置选项的值时)。 因此,如果您想在给定步骤完成之前结束训练,您可以通过运行以下命令从该检查点生成冻结模型:
bob@desktop:~/isaac/sdk$ bazel run packages/ml/tools:freeze_tensorflow_model_tool -- --out /tmp/autoenc_logs/ckpts/model-24000 --output_node_name 'translation_output','rotation_output_1','decoder_output' /tmp/autoenc_logs/ckpts/model-24000
上面的命令将最后一个检查点编号设置为 24000。您可以根据需要更改此值。
转换为 UFF 模型
UFF 包包含一组实用程序,用于将经过训练的模型从各种框架转换为通用 UFF 格式。 在此应用程序中,UFF 解析器将 Tensorflow 模型转换为 UFF,因此它可用于码本生成和推理。 有关详细信息,请参阅 NVIDIA TensorRT 文档。
在训练迭代结束时,Tensorflow 模型被保存为 .pb 文件。 然后,您需要使用 python 脚本和 UFF 解析器将其转换为 UFF 模型。 例如,在24000次迭代结束时,Tensorflow模型保存为model-24000.pb,可以使用以下命令转换为UFF模型:
bob@desktop:~/isaac/sdk$ bazel run packages/ml/tools:tensorflow_to_tensorrt_tool -- --out /tmp/autoenc_logs/ckpts/pose_cnn_model.uff --input_node_name 'encoder_input' --input_node_name 'encoder_bbox_input' --output_node_name 'translation_output' --output_node_name 'rotation_output_1' --output_node_name 'decoder_output' /tmp/autoenc_logs/ckpts/model-24000-frozen.pb
运行推理
注意
建议使用同一个相机进行推理和训练。 只要推理图像的纵横比与训练数据相同,推理应用程序就会处理图像分辨率和焦距的变化。 默认训练相机模型使用 42 度的垂直 FOV。 然而,如果推理相机的相机模型参数与训练相机有很大差异,我们建议使用推理相机参数训练模型并调整训练场景中的相机随机化参数,以便数据样本覆盖整个生成的感兴趣对象。 完整的图像框架。 如果训练数据的 FOV 或图像尺寸发生变化,则必须在使用的推理配置文件中的 detection_pose_estimation.object_pose_estimation.pose_estimation 组件中设置这些参数。
使用 Pose CNN 解码器架构估计物体姿态的端到端推理需要物体检测模型的推理,然后是姿态估计。 在使用这两个模型运行端到端推理之前,模拟中的示例推理应用程序提供了地面实况检测,以便用户可以首先测试使用上述部分中提供的说明训练的姿势估计模型的性能。 可以使用相同的训练场景来运行此推理应用程序。 为此,首先播放用于训练的场景(例如,带有场景 11 的小车的 factory_of_the_future 场景)。 您还可以使用 Unity 中的自定义场景包/Nvidia/Samples/ObjectPoseEstimation/pose_cnn_decoder_training.unity 作为您感兴趣的对象。 在 Isaac SDK 中,使用 sdk/packages/object_pose_estimation/apps/pose_cnn_decoder/pose_estimation_inference_sim_groundtruth_detection.app.json 中的配置参数 allowlist_labels 在 object_pose_estimation.detection_filter 组件中设置类标签名称。 然后使用以下命令从 Isaac SDK 存储库运行姿态估计推理应用程序:
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder:pose_estimation_inference_sim_groundtruth_detection
在 localhost:3000 的 Sight 中可视化推理。
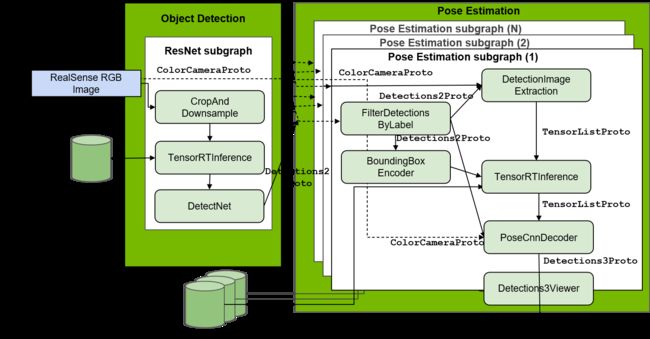
上图说明了一个完整的端到端示例推理应用程序。 对于姿态估计框架的完整端到端推理,有四种可用的基于数据收集的物体姿态估计推理模式:模拟、相机馈送、日志回放和图像馈送。 这些模式可以通过 Python 脚本运行。 与训练一样,该包为两个对象提供样本推理:一个用于导航用例的推车和一个用于操作用例的盒子。 在对自定义对象进行推理的情况下,修改默认推理配置文件 /packages/object_pose_estimation/apps/pose_cnn_decoder/ detection_pose_estimation_cnn_inference.config.json 中的配置参数,并使用它来运行不同的推理模式来代替为 dolly 提供的示例配置文件 和盒子。 从姿势估计训练生成的 uff 文件的路径、对象检测模型的参数(如训练模型的路径、置信度阈值等)都在此配置文件中设置。
注意
当前版本的 Isaac SDK 使用 Jetpack 版本的 TensorRT 7.1.3,不支持 UFF 模型的动态批量大小。 因此,目前,姿势估计推断被设置为在图像中对象的多个实例的情况下推断与图像的用户定义的中心部分重叠最多的单个对象实例的姿势。 可以使用“detection_pose_estimation.object_pose_estimation.detection_filter”中的“focus_factor”配置参数设置图像中间部分的大小范围。 然后,检查重叠程度的焦点区域是像素列范围 [(1 - focus_factor)/2, (1 + focus_factor)/2] * image_columns。
dolly 和 box 的推理 Python 脚本和配置文件位于 /packages/object_pose_estimation/apps/pose_cnn_decoder。 下面提供了为工业小车和箱子运行四种推理模式的命令:
-
对模拟数据的推断是检查模型准确性的良好初步测试。 要在检测和姿态估计的模拟数据上运行推理应用程序,首先播放姿态估计训练场景二进制文件,然后在 Isaac SDK 中运行推理命令。 以下是此模式所需的输入参数:
-
–mode:对于此模式,应将其设置为 sim。
-
–image_channel:从模拟发送彩色图像的图像通道的名称。 默认名称是颜色。
-
–rows 和–cols:输入图像的行数和列数。 默认值分别为 720 和 1280。
-
–scenario_scene 和 --scenario_robot_prefab:如果对象需要从 Isaac SDK 中生成,则分别为要加载的模拟场景的名称和要生成的对象的预制名称。 默认选项设置为无,如果感兴趣的对象已经在场景中设置,如 factory_of_the_future 场景,则该选项有效。
对于推车推理,从 isaac_sim_unity3d 发布文件夹中使用以下命令运行场景 12:
bob@desktop:~/isaac/sdk$ ./builds/factory_of_the_future.x86_64 --scene Factory01 --scenario 12然后使用以下命令对模拟数据运行工业推车推理:
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder:detection_pose_estimation_cnn_inference_app -- --mode sim --image_channel color --intrinsics_channel color_intrinsics --config packages/object_pose_estimation/apps/pose_cnn_decoder/detection_pose_estimation_cnn_inference_dolly.config.json对于盒推理,从 isaac_sim_unity3d 发布文件夹中使用以下命令运行推理场景 11:
bob@desktop:~/isaac/sdk$ ./builds/factory_of_the_future.x86_64 --scene Factory01 --scenario 11然后使用以下命令对模拟数据运行框推理:
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder:detection_pose_estimation_cnn_inference_app -- --mode sim --image_channel encoder_color --intrinsics_channel encoder_color_intrinsics --config packages/object_pose_estimation/apps/pose_cnn_decoder/detection_pose_estimation_cnn_inference_kltSmall.config.json要使用 Unity 中的示例场景对自定义对象进行推理,请在 Unity 编辑器中打开并播放 packages/Nvidia/Samples/ObjectPoseEstimation/pose_cnn_decoder_training.unity 场景。 您可以增加程序和程序相机游戏对象的帧间隔配置选项编号,这样数据就不会在每一帧随机化。 然后使用以下命令对模拟数据运行推理,例如 Dolly.prefab:
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder:detection_pose_estimation_cnn_inference_app -- --mode sim --image_channel encoder_color --intrinsics_channel encoder_color_intrinsics --scenario_scene pose_cnn_decoder_training --scenario_robot_prefab Dolly --config packages/object_pose_estimation/apps/pose_cnn_decoder/detection_pose_estimation_cnn_inference.config.json -
-
在来自 RealSense 摄像头的实时摄像头源上运行推理,需要以下输入参数:
-
–mode:这个模式应该设置为realsense。
-
–rows 和–cols:输入图像的行数和列数。 默认值分别为 720 和 1280。
-
–fps:RGB通道的帧率。 目前,RealSense 摄像头仅支持两种帧速率,15 和 30。 默认值为 15。
在 Isaac SDK 中使用以下命令对摄像头源运行移动推车推理:
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder:detection_pose_estimation_cnn_inference_app -- --mode realsense --config packages/object_pose_estimation/apps/pose_cnn_decoder/detection_pose_estimation_cnn_inference_dolly.config.json在 Isaac SDK 中使用以下命令对摄像头源运行框推理:
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder:detection_pose_estimation_cnn_inference_app -- --mode realsense --config packages/object_pose_estimation/apps/pose_cnn_decoder/detection_pose_estimation_cnn_inference_kltSmall.config.json -
-
要使用记录的日志运行推理应用程序,需要以下输入参数:
-
–mode:对于这种模式,应该设置为 cask。
-
–cask_directory:示例重播日志的路径。 默认路径设置为 dolly 重播日志。
-
–rows 和–cols:输入图像的行数和列数。 默认值分别为 720 和 1280。
在 Isaac SDK 中使用以下命令对示例日志运行 dolly 推理:
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder:detection_pose_estimation_cnn_inference_app -- --mode cask --rows 480 --cols 848 --config packages/object_pose_estimation/apps/pose_cnn_decoder/detection_pose_estimation_cnn_inference_dolly.config。 JSON在 Isaac SDK 中使用以下命令对示例日志运行框推理:
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder:detection_pose_estimation_cnn_inference_app -- --mode cask --config packages/object_pose_estimation/apps/pose_cnn_decoder/detection_pose_estimation_cnn_inference_kltSmall.config.json --cask_directory external/sortbot_pose_estimation_data/klt_logs -
-
要使用示例图像运行推理应用程序,需要以下输入参数
-
–mode:对于此模式,应将其设置为图像。
-
–image_directory:示例图像的路径。 默认设置为 dolly 样本图像的路径。
-
–rows 和–cols:输入图像的行数和列数。 默认值分别为 720 和 1280。
-
–optical_center_rows 和–optical_center_cols:指定为输入图像中的行和列的光学中心。 默认值分别为 360 和 640。
-
–focal_length:用于捕捉图像的相机焦距(以像素为单位)。 默认值为 925.74。
需要最后三个参数来构建相机的针孔模型。
在 Isaac SDK 中使用以下命令对示例图像运行移动推车推理:
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder:detection_pose_estimation_cnn_inference_app -- --mode image --rows 480 --cols 848 --optical_center_rows 240 --optical_center_cols 424 --focal_length 614.573 --config packages/object_pose_estimation/apps/pose_cnn_decoder/detection_pose_estimation_cnn_inference_dolly.config.json在 Isaac SDK 中使用以下命令对示例图像运行框推理:
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder:detection_pose_estimation_cnn_inference_app -- --mode image --config packages/object_pose_estimation/apps/pose_cnn_decoder/detection_pose_estimation_cnn_inference_kltSmall.config.json --image_directory external/industrial_dolly_sortbot_sample_images/klt_sample_images/klt_box.png -
-
要使用 ROS 输入主题运行推理应用程序,默认使用以下输入 ROS 主题名称
注意
在运行测试之前必须安装 ROS。 有关详细信息,请参阅 ROSBridge 部分。
-
/depth
-
/rgb
-
/camera_info
发布上述 ROS 主题后,在 Isaac SDK 中使用以下命令对它们运行 dolly 推理:
bob@desktop:~/isaac/sdk$ bazel run packages/object_pose_estimation/apps/pose_cnn_decoder:detection_pose_estimation_cnn_inference_ros_bridge_app -
推理应用程序从不同的输入源获取 RGB 图像,并输出检测到的对象的估计 3D 姿态以及裁剪图像的分割掩码。 提供了 dolly 和 box 对象的示例数据,允许您使用图像和日志运行最后两个推理应用程序。 您可以在 http://localhost:3000 的 Sight 中可视化估计的姿势。
估计姿势有两种可视化类型:
-
一个 3D 边界框,需要指定零方向的 3D 边界框大小和从对象中心到边界框中心的转换。 在推理应用程序文件的
viewers/Detections3Viewer组件中配置这些参数。 参数 box_dimensions 必须设置为感兴趣对象的尺寸。 参数 object_T_box_center 必须设置为对象中心的位姿。 它是一个大小为 7 的位姿向量,前四个按顺序(w, x, y, z)表示旋转四元数,后三个表示平移向量的x, y, z分量。 因此,默认向量[1, 0, 0, 0, 0, 0, 0]表示零旋转和平移姿势,如果对象的 CAD 模型/OBJ 文件的原点位于其中心,则可以保留此设置 . 如果不是,则必须在位姿向量的平移分量中添加到中心的适当偏移量。 -
场景中 CAD 模型的渲染,需要对象 CAD 模型的路径和文件名。 这些分别对应于推理应用程序文件中 websight 组件中的
assetroot和assets参数。
如果您注意到 Sight 中的网格渲染与图像渲染存在滞后,请稍微增加更改延迟值以同步图像、渲染网格和边界框。 要找到此选项,请右键单击 Sight 中的渲染窗口。
提供了另一个推理应用程序 /packages/object_pose_estimation/apps/pose_cnn_decoder/detection_pose_estimation_cnn_inference_deploy_app.json,但不包括有助于更快部署包的工业推车和盒子的示例日志数据。 因此,在包部署的情况下,建议使用此应用程序而不是 detection_pose_estimation_cnn_inference_app.json。 要使用该应用程序,请将上面列出的命令中的 detection_pose_estimation_cnn_inference_app 替换为 detection_pose_estimation_cnn_inference_deploy_app 以在不同模式下运行推理。 该应用程序包括工业小车和盒子的示例图像,用于测试图像模式下的推理。
推理示例

3D 物体姿态估计评估
模型评估对于提高模型的准确性和鲁棒性以及估计模型执行特定任务的能力和局限性都至关重要。 对于姿态估计模型的评估,Isaac SDK 中使用了三个主要指标来评估模型执行所需任务的准确性:
-
x、y 和 z 分量的中值绝对平移误差
-
中值绝对旋转误差
-
模型精度,表示满足平移和旋转误差中值阈值的评估数据的分数。
评估流程还输出两种图:
-
距离相机不同物体距离的数据的平移和旋转误差的误差分布箱线图。
-
平移和旋转误差的精度图显示不同阈值的模型精度(即满足设定误差阈值的数据部分)。
最后,离群数据样本以及预测姿势的 3D 边界框被保存为动画,有助于分析模型的失败案例。
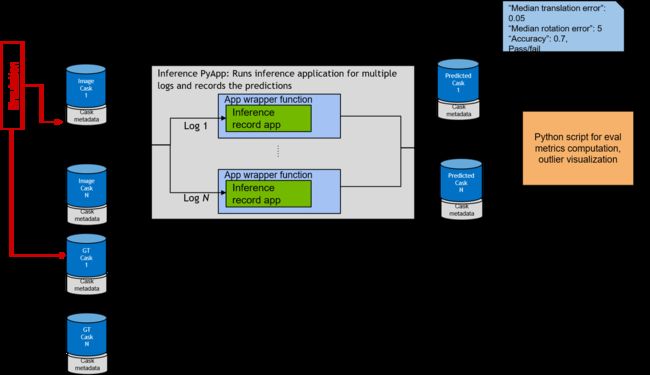
Isaac SDK 中的姿势评估管道被设置为以 Isaac log/cask式摄取数据,以确保管道与评估数据的来源无关,即模拟或真实数据。 上图显示了 Isaac SDK 中评估框架的三个阶段:评估数据生成,生成图像和地面实况 casks,姿势估计推理和记录,生成预测姿势 casks,最后计算评估指标 这生成了木桶数据。
使用模拟收集评估数据
仿真可以轻松访问无限量的标记数据以进行评估。 评估管道设置为使用 Isaac log/cask 格式的数据,因此使用 Isaac SDK 应用程序以 cask 格式记录来自模拟的数据样本以及真实姿势。
要使用 Unity 中的示例场景对自定义对象进行推理,请在 Unity 编辑器中打开并播放 packages/Nvidia/Samples/ObjectPoseEstimation/pose_cnn_decoder_training.unity 场景。 这从同一训练场景收集评估数据。 您可以对场景设置进行任意数量的更改,包括在推理过程中更改相机随机化的种子数、障碍物等,以收集不同的样本进行训练。
注意
此时,我们假设感兴趣对象的预制件已经创建,并且在训练期间也列在 PoseEstimationObjects Group 中。 如果没有,请按照上面从场景源文件生成自定义对象数据部分中的步骤 1 到 6,然后再继续。
在 Isaac SDK 中运行模拟数据记录应用程序。 以下是此模式所需的重要输入参数:
-
–mode:这应该设置为 pose 用于姿势估计数据收集。
-
–image_channel:模拟中发送RGB数据的图像通道名称。
-
–intrinsics_channel:包含相机针孔模型的图像本征通道的名称。 这必须设置为与上面设置的 image_channel 相同的名称,通常带有 _intrinsics 扩展名。 例如,如果 image_channel 参数设置为 encoder_color,则 intrinsics_channel 必须设置为 encoder_color_intrinsics。
-
–load_scene:要使用场景管理器加载的场景的名称。
-
–load_robot_prefab:场景中要加载的物体预制件名称。
-
–detections3viewer_box_dimensions:3D 边界框的尺寸,用于从 sim 查看真实姿势。 例如,对于工业推车,可以设置为“[0.9, 1.32, 0.25]”。
-
–detections3viewer_object_T_box_center:对象到边界框中心转换的 7 元素姿态向量,以在 Sight 中查看 3D 边界框。 默认设置为“[1, 0, 0, 0, 0, 0, 0]”,表示零旋转和平移。
-
–runtime:收集数据样本的模拟运行时间。 默认设置为 20 秒。 增加此值以收集更多评估数据样本。
然后可以在Isaac SDK中使用以下命令收集评估数据,以Dolly.prefab为例:
bob@desktop:~/isaac/sdk$ bazel run packages/ml/apps/record_sim_ground_truth:record_sim_ground_truth -- --mode pose --image_channel encoder_color --intrinsics_channel encoder_color_intrinsics --scenario_scene pose_cnn_decoder_training --scenario_robot_prefab Dolly
该命令连接到模拟引擎,收集 RGB 图像以及小车的真实姿态,并将其记录为 Isaac 日志,稍后可以在模型评估期间重播。 请注意,评估管道目前仅支持单实例数据样本,以便更轻松地将地面实况姿势与感兴趣的对象相关联。 默认情况下,图像数据 cask 保存到 /tmp/data/raw 并包含一个通道(‘color’)。 ground truth data cask 保存到 /tmp/data/ground_truth 并包含一个通道(‘bodies’)。 应用程序的每次运行都会保存一个图像和地面实况数据桶对。 这样就可以采集多组数据,以多条日志的形式进行评估。
姿势估计评估
一旦我们获得了收集的评估数据以及姿势的基本事实,模型的评估将分两个阶段进行。
-
姿势估计推理记录
-
评价指标计算
姿势估计推理记录
在此步骤中,应用程序重放给定输入目录中的所有图像 cask 文件,运行姿势估计推理应用程序,并将估计的姿势记录为每个输入图像 cask 文件的 cask 日志。
以下是此脚本所需的重要输入参数:
-
–inference_app:重放日志、执行推理和记录结果的应用程序文件的路径。
-
–config:为上述推理应用程序的推理参数加载的配置文件。
-
–raci_metadata:将 JSON 元数据与 cask 一起保存到
_md.json -
–no_raci_metadata:没有保存元数据。
-
–input_cask_workspace:包含输入桶文件的工作空间。 输入图像日志必须位于此工作区内的数据/原始目录中。
-
–output_cask_workspace:输出木桶文件写入此工作区内的
data/中。 如果未设置此参数,则假定与 input_cask_workspace 相同。 -
–output_directory_name:将预测 cask 输出写入的基本目录名称。 Cask 文件在
/data/
假设输入图像 casks 存储在 /tmp/data/raw 中,可以通过从 Isaac SDK 目录运行以下命令来生成预测姿势 casks:
bob@desktop:~/isaac/sdk$ bazel run packages/ml/apps/evaluation_inference:evaluation_inference -- --inference_config packages/object_pose_estimation/apps/pose_cnn_decoder/detection_pose_estimation_cnn_inference.config.json --inference_app packages/object_pose_estimation/apps/pose_cnn_decoder/evaluation/pose_cnn_decoder_inference_record.app.json --input_cask_workspace /tmp
使用上述命令,输出预测姿势桶存储在路径 /tmp/data/predictions 中。 输出姿态估计 casks 与输入图像 casks 同名,并带有一个额外的标签,以便在下一步模型评估中可以将图像 casks 和相应的姿态 casks 关联起来。
还提供了来自机器人相机视角的未来场景工厂中工业小车的示例日志,以使用提供的工业小车姿态检测模型试用评估管道。 要运行推理并在示例日志中记录预测,请运行以下命令:
bob@desktop:~/isaac/sdk$ bazel run packages/ml/apps/evaluation_inference:evaluation_inference -- --inference_config packages/object_pose_estimation/apps/pose_cnn_decoder/detection_pose_estimation_cnn_inference.config.json --inference_app packages/object_pose_estimation/apps/pose_cnn_decoder/evaluation/pose_cnn_decoder_inference_record.app.json --input_cask_workspace external/industrial_dolly_pose_evaluation_data --output_cask_workspace /tmp
输出预测桶存储在 /tmp/data/predictions 中。
评估指标计算
一旦收集了图像、地面实况和预测数据,就可以计算评估指标。 此步骤读取 image cask 目录中的完整 casks 列表及其相应的地面实况数据和预测,计算框架指标,并聚合指标。 位于 packages/object_pose_estimation/apps/pose_cnn_decoder/evaluation/evaluation_config.json 的配置文件用于设置平移和旋转误差阈值、针孔相机模型和对象尺寸。 默认值设置为推车模型的值。
以下是此脚本所需的输入参数:
-
config:用于评估的配置文件的路径。 默认设置为 packages/object_pose_estimation/apps/pose_cnn_decoder/evaluation/evaluation_config.json。
-
–use_2d_detections:如果设置为 true,则假设预测的 2D 检测是预测姿势桶的通道之一。 异常值的检测可视化。
-
–image_cask_dir:图像桶目录的路径。 只有图像日志必须放在该目录中。 数据聚集在该目录中的所有日志中。 默认路径设置为 /tmp/data/raw。
-
–gt_cask_dir: image_cask_dir中的image casks对应的ground truth pose cask目录的路径。 默认路径设置为 /tmp/data/ground_truth。
-
–predicted_cask_dir:image_cask_dir中的image casks对应的predicted pose cask目录路径。 如果 use_2d_detections 设置为 true,它也应该包含 2D 检测。 默认路径设置为 /tmp/data/predictions。
-
–results_dir:存放评估结果的路径。 如果目录不存在,则创建该目录。 默认路径设置为 /tmp/pose_evaluation_results。
用于彩色图像、地面真实姿势和预测姿势的图像桶的通道名称分别在配置参数 image_channel、gt_pose_channel 和 pred_pose_channel 的评估配置文件中设置。 默认通道名称分别为 color、gt_poses 和 predicted_poses。
可以使用以下命令运行生成的 cask 文件的姿势评估:
bob@desktop:~/isaac/sdk$ bazel run //packages/object_pose_estimation/apps/pose_cnn_decoder/evaluation:pose_cask_evaluation -- --image_cask_dir='/tmp/data/raw' --gt_cask_dir='/tmp/data/ground_truth' --predicted_cask_dir='/tmp/data/predictions'
要改为根据提供的示例日志计算评估指标,请运行以下命令:
bob@desktop:~/isaac/sdk$ bazel run //packages/object_pose_estimation/apps/pose_cnn_decoder/evaluation:pose_cask_evaluation -- --image_cask_dir='external/industrial_dolly_pose_evaluation_data/data/raw' --gt_cask_dir='external/industrial_dolly_pose_evaluation_data/data/ground_truth' --predicted_cask_dir='/tmp/data/predictions'
中值绝对旋转、平移误差和模型精度等姿势指标都写入 JSON 文件中。 它还具有一个 KPI 通过/失败指标,指示错误和模型准确性是否满足配置文件中设置的阈值。 除了指标 JSON 文件外,误差分布的箱形图和精度图以及离群值样本都保存在 /tmp/pose_evaluation_results 中。
此评估管道作为一种工具提供,以帮助提高模型性能。 如果评估结果不符合标准,则考虑修改训练数据以更好地反映用于评估的数据分布。 异常值结果有助于错误分析:调查模型表现不佳的失败案例和异常值,并使用这些案例来激发模拟中的训练场景。
更多精彩内容:
https://www.nvidia.cn/gtc-global/?ncid=ref-dev-876561
