基于注意力机制的多尺度车辆行人检测算法
本文由李经宇,杨静 ,孔斌,王灿,张露联合创作
摘要
无人驾驶汽车在复杂多变的交通场景中能提前且准确检测到车辆行人的动态信息尤为重要。然而,无人驾驶场景下存在相机快速运动、尺度变化大、目标遮挡和光照变化等问题。为了应对这些挑战,本文提出了一种基于注意力机制的多尺度目标检测算法。基于YOLOv3网络,首先,使用空间金字塔池化模块对多尺度局部区域特征进行融合和拼接,使网络能够更全面地学习目标特征;其次,利用空间金字塔缩短通道间的信息融合,构造了YOLOv3- SPP+ -PAN网络;最后,基于注意力机制设计了更高效的目标检测器SE-YOLOv3- SPP+ -PAN。实验结果表明:相比于YOLOv3网络,提出的SE-YOLOv3- SPP+ -PAN网络的平均精度均值提升了2.2,且推理速度仍然保持智能驾驶平台下实时的要求。实验证明了所提出的SE-YOLOv3- SPP+ -PAN网络比YOLOv3更加高效、准确,因此更适合于实际智能驾驶场景下的目标检测任务。
1 引言
随着城市的发展和汽车数量的快速增长,交通场景越来越多样,行车环境也越来越复杂,这带来了一系列交通拥堵以及道路行车安全问题,无人驾驶和深度学习发展为解决这些问题提供了新的思路。通过摄像头检测车辆和行人的位置,无人驾驶系统可以根据这些信息控制行车速度并且提前做出预判,能有效减少事故发生的几率。因此,能够高效准确检测出道路场景信息尤为重要。
由于开放部署环境的多样性,对智能驾驶平台上的场景自动分析提出了更高的要求,给目标检测算法带来了许多新的挑战。这些挑战主要包括:如何处理智能驾驶场景中物体视觉外观的各种变化。如光照、视野、小尺寸和尺度变化。
基于传统机器学习和手工特征的目标检测方法在处理这些变化时容易失败。解决这些挑战的一种有竞争力的方法是基于深度学习技术的对象检测器,近年来得到了广泛的应用。
随着深度学习的发展,多种基于深度学习的目标检测方法被提出。目前广泛使用的基于深度学习的目标检测方法可分为两类。第一类是两阶段目标检测方法,如FastR-CNN、FasterR-CNN等。第二类是一级目标检测算法,如SSD,YOLO,YOLO9000,YOLOv3不需要先生成候选目标,这些方法直接通过网络预测目标的位置和类别。因此,一级目标检测方法具
有更快的检测速度。
具体来说,YOLO深度学习目标检测器在实际应用中被广泛使用。因为其在检测精度和速度两方面具有较好的平衡性。尽管如此,其网络精度仍存在很大的改进空间以提高实际问题中目标检测的准确率。这也成为了我们迫切需要解决的问题。
本文提出了基于注意力机制的多尺度车辆及行人检测算法,具体来说,本文的主要贡献如下:
(1)为了更全面地学习多尺度目标特征,提出了一种改进的空间金字塔池化方法,在同一卷积层中收集并拼接不同尺度的局部区域特征。
(2)进一步加强特征金字塔的结构,缩短了高低层特征融合的路径,构造了YOLOv3- SPP+ -PAN网络。
(3)基于注意力机制构建了更高效的目标检测器SE-YOLOv3- SPP+ -PAN。
2 YOLOv3 快速检测原理

YOLOv3在目标检测精度上对YOLO进行了改进。首先,YOLOv3采用骨干网络Darknet-53作为特征提取器。其次,YOLOv3遵循特征金字塔网络的思想,在三种不同的尺度上预测边界盒。在三个不同尺度的特征图上分别建立三个检测头,负责检测不同尺度的目标。检测头中的每个网格被分配了三个不同的锚,从而预测由4个边界框偏移、1个目标和C个类别预测组成的三个检测。检测头的最终结果张量为N×N×(3×(4+1+C)),其中N×N表示最后卷积特征图的空间大小。
3 算法模块设计
3.1 空间金字塔池化YOLOv3-SPP+网络
本文以YOLOv3为基础网络,针对无人驾驶实际场景中目标检测所面临的问题,对网络进行改进优化。
为了应对无人驾驶场景中尺度变化大问题。在此,本文通过融合不同尺度特征图和不同感受野的信息的方法,提高多尺度检测的准确性。何凯明等人提出了空间金字塔池化(Spatial Pyr⁃amid Pooling,SPP)方法。将任意大小的特征映射集合到固定大小的特征向量中,CNN(卷积神经网络)不仅不需要固定输入图像的大小,而且通过融合多尺度特征,对多尺度目标的检测具有很强的鲁棒性。然而,此方法并没有充分利用同一卷积层不同尺度上的局部区域特征,仍然难以准确地检测出具有丰富局部区域特征的小目标。
YOLOv3的多尺度预测侧重于将多尺度卷积层的全局特征串联起来,但其忽略了同一卷积层上多尺度局部特征的融合。因此,本文的设计中,将SPP模块引入到YOLOv3中,对多尺度局部区域特征进行池化合并,然后将全局和局部多尺度特征结合起来提高目标检测的精度。

图1 SPP+模块结构图
为了进一步丰富深度特征,本文将改进的空间金字塔池模块称为SPP+模块,如图1所示。改进的SPP+模块由4个大小分别为5×5,7×7,9×9和13×13的并行最大池化层组成。针对无人驾驶场景车辆及行人检测实验,我们在YO⁃LOv3第一个检测头前的第5和第6卷积层之间集成了一个改进的SPP+模块,以形成YOLOv3- SPP+ 检测网络。改进的SPP模块能够提取具有不同感受野的多尺度深度特征,并通过在特征映射的通道维度上拼接来融合。在同一层中获得的多尺度特征有望进一步提高YOLOv3的检测精度,且计算量小。
3.2 特征融合YOLOv3- SPP+ -PAN网络
在3.1节已有YOLOv3- SPP+ 网络基础上,为了缩短网络通道间的信息融合,提高智能驾驶场景车辆行人小目标检测,进一步优化网络。
对于卷积神经网络而言,不同深度对应着不同层次的语义特征,浅层网络分辨率高,学习更多细节特征;深层网络分辨率低,学习更多语义特征,丢失了位置信息,导致小目标检测性能下降。特征金字塔网络(Feature Pyramid Net⁃works,FPN)提出不同分辨率特征融合的方式,即每个分辨率的特征图和上采样的低分辨率特征相加,使得不同层次的特征增强。FPN结构如图2所示。

图 2 FPN 模块结构图
FPN的高层级特征与低层级别特征之间路径较长(如图3(a)所示红色虚线所示),增加了访问准确定位信息的难度。为了缩短信息路径和用低层级的准确定位信息增强特征金字塔,PAN(Path Aggregation Network)在FPN基础上创建了自下而上的路径增强(如图3(b)所示)。这种路径增强方式用于缩短信息路径,利用低层特征中存储的精确定位信号,提升特征金字塔架构。具体来说,对于FPN结构,输入图像到得到输出P6特征需要经过较长信息流动(如图3(a)红色虚线所示),其中有Darknet-53很多卷积层。而对于FPN结构,可直接由P4复制得到N4特征,N4特征仅仅需要经过几个降维卷积(如图3(a)绿色虚线所示)得到P6特征。PAN结构如图3所示。
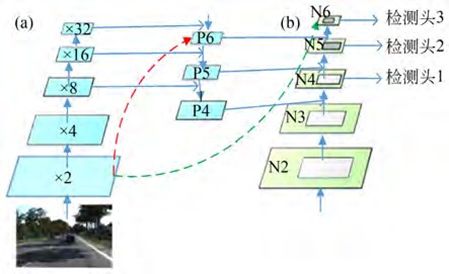
图3 PAN模块结构图
在此,本文在YOLOv3-SPP+网络基础上嵌入了PAN模块来构成YOLOv3-SPP+-PAN网络,如图3(a)所示。×2,×4,×8,×16,×32分别表示主干网络Darknet53的2倍,4倍,8倍,16倍与32倍下采样。网络结构图3中的红色虚线为原FPN特征融合路径,绿色虚线为PAN特征融合路径,绿色虚线跨越更少的卷积层。YO⁃LOv3原本三个检测头为图3中的P4,P5,P6。经过PAN网络的改进,YOLOv3-SPP+-PAN网络输出为绿色虚线N4检测头1,N5检测头2与N6检测头3。分别用于检测输出大目标,中目标和小目标。构建该新支路的优势在于缩短了底层尺寸大的特征到高层尺寸小的特征之间的距离,让特征融合更加有效。
3.3 注意力机制SE-YOLOv3- SPP+ -PAN网络
在实际车辆行人检测场景中,现有的网络往往不能关注车辆行人的重要特征。为此,本文在3.2节已有YOLOv3- SPP+ -PAN网络的基础上,使用注意机制来增加表现力,关注重要特征并抑制不必要的特征。借鉴SENet(Squeeze-and-Excitation Networks)中提出的SE模块加载到现有的网络模型框架。SE模块如图4所示。
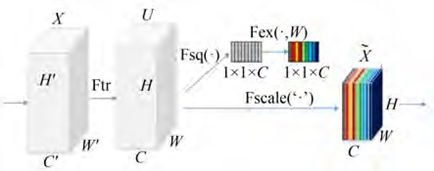
图4 SE模块示意图
SE模块,通过对卷积得到的特征图进行处理,得到一个和通道数一样的一维向量作为每个通道的评价分数,然后将该分数分别施加到对应的通道上,得到其结果。注意力机制的具体实现过程如图4所示。给定一个输入x,其特征通道数为C',通过一系列卷积Ftr变换后得到一个特征通道数为C的特征。接下来通过三个操作来重标定前面得到的特征。
首先是Fsq操作,通过平均池化,将每个通道的二维特征(H×W)压缩为1个实数。它表征着在特征通道上响应的全局分布,在某种程度上具有全局的感受野,通道数保持不变,所以通过Fsq操作后变为1×1×C。
接着是Fex操作,使用一个全连接神经网络,对Fsq操作之后的结果做一个非线性变换。
最后是Fscale特征重标定的操作,使用Fex得到的结果作为权重,乘到输入特征上,完成在通道维度上的对原始特征的重标定。
在YOLOv3- SPP+ -PAN网络基础上,将SE模块添加到骨干网络Darknet53之后即卷积层53层后,进行信息重构。在此,SE模块参数reduc⁃tion设置为16。
至此,我们成功构建了SE-YOLOv3- SPP+ -PAN网络。具体来说,本文在Darknet53之后嵌入SE模块,使网络更加关注车辆行人特征;在第一个检测头前的第5和第6卷积层之间引用改进的SPP+,使得同一卷积层中收集并拼接不同尺度的局部区域特征;利用PAN模块进一步加强特征金字塔的结构,缩短了高低层特征融合的路径。完整的网络结构示意图如图5所示。
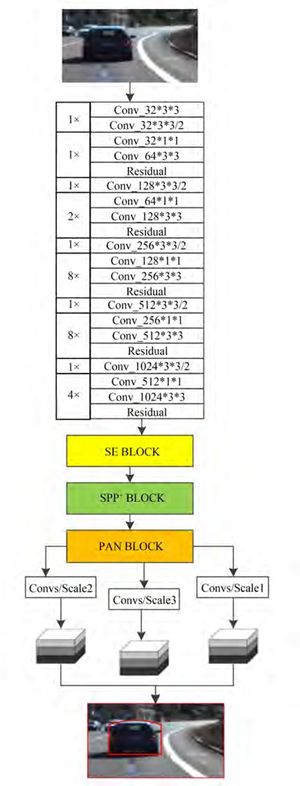
图 5 SE-YOLOv3- SPP+ -PAN 网络结构示意图
3.4 网络损失函数
网络检测算法的损失函数由定位损失lbox、分类损失lcls和置信度损失lobj组成。


4 实验结果及分析
4.1 实验条件
本文的实验环境为:Linux系统、Intel Xeon E5-2643 3.3 GHz CPU、32GB内存及NVIDIA GTX 2080Ti GPU(11.00GB内存)。使用py⁃torch1.1深度学习框架,python3.6版本。
4.2 实验数据集
在KITTI数据集上,我们证明了本文提出的SE-YOLOv3- SPP+ -PAN相较于YOLOv3而言,更适用于实际无人驾驶场景中的车辆及行人检测。KITTI数据集涵盖了自主驾驶环境下的多种数据类型,其提供的所有数据都是在驾驶过程中在车辆平台上获取的。
具体的,6000幅图像用于训练和验证,1481幅图像用于测试。训练模型可以用于检测汽车、行人、坐着的人、骑自行车的人、面包车、卡车、有轨电车、杂项(如拖车、火车)八类目标。
4.3 评估指标
评估指标采用通用目标检测评价指标:精度P,召回率R,AP(Average Precision)以及 mAP (mean Average Precision)。

本文将召回率R划分为11个点(0. 0,0. 1, 0. 2,…,1. 0),按照 PASCAL VOC的计算方式得到每个召回率下的精度P,可以得到 P-R 曲线,P-R曲线与坐标轴围成的面积即为AP值。对于各个类别,分别按照上述方式计算AP,所有类别的AP平均值即是mAP。
4.4 网络训练参数
SE-YOLOv3-SPP+-PAN网络训练参数设置如下:将原始Darknet53的激活函数替换为swish激活函数;损失函数为GIoU损失。动量为0.9,衰减为0.0005,批次大小为64;初始学习率为0.00261,第900和950代的学习率分别降低到原来的0.1倍。为了保证对比实验的公平性,对于基线网络YOLOv3以及YOLOv3-SPP+和YOLOv3-SPP+-PAN网络保持和SE-YOLOv3- SPP+ -PAN网络训练参数一致。
图6展示了SE-YOLOv3-SPP+-PAN网络具体训练过程中目标检测框定位损失GIoU,置信度损失Objectness和分类损失Classification随着训练迭代次数的变化情况。可以看出,随着网络训练迭代的增加,网络模型损失逐渐减少到稳定基本不变直至网络收敛到最优。
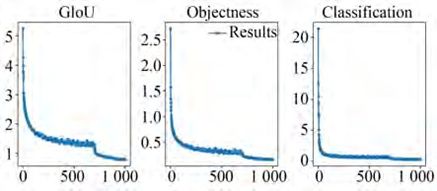
图 6 网络训练损失
4.5 实验结果与分析
表1给出了原始基线YOLOv3网络,改进的YOLOv3- SPP+ ,YOLOv3- SPP+ -PAN和SEYOLOv3- SPP+ -PAN网络在 KITTI测试数据集上的目标检测结果,详细比较了各个网络的性能,包括精度,速度以及模型大小等。对于实验数据的具体分析如下:

(1)如表1所示,YOLOv3-SPP+在KITTI数据集上的目标检测平均精度均值(mAP)为84.6%,比基线网络YOLOv3提升了0.6%。YOLOv3-SPP+在基线网络YOLOv3的第一个检测头前的第5和第6卷积层之间集成了一个改进的SPP+模块。该实验数据证实:SPP+模块对多尺度局部区域特征进行池化合并,将全局和局部多尺度特征结合起来可以提高目标检测的精度。同时,与YOLOv3相比,YOLOv3-SPP+的检测速度仅仅降低了约1.6FPS,YOLOv3-SPP+仍有较快的检测速度。模型大小由492.9M增加至503.4M,模型大小仅仅增加了10.5M。实验结果进一步证实了改进的SPP+模块在同一层中获得的多尺度特征可以进一步提高YOLOv3的检测精度的同时,仅仅增加较小的且计算量。
(2)由表1可以看出,YOLOv3- SPP+ -PAN在YOLOv3-SPP+网络的基础上嵌入PAN模块可以缩短网络通道间的信息融合,YOLOv3- SPP+ -PAN在KITTI数据集上的目标检测精度为85.8%,比YOLOv3-SPP+提高了1.2。同时,与YOLOv3-SPP+相比,YOLOv3- SPP+ -PAN的检测速度仅降低了约0.5FPS,仍能保证检测的实时性。
(3)为了在车辆行人检测过程中,体现对于重要特征的关注及对不必要特征的抑制,本文提出的基于注意力机制的多尺度车辆行人检测算法SE-YOLOv3- SPP+ -PAN在KITTI数据集上的目标检测平均精度均值为 86.2%,其性能比YOLOv3基线模型提升了2.2%,比YOLOv3- SPP+ -PAN提升了 0.4%。
上述实验结果表明:本文网络设计中增加的模块可以学习到通道之间的相关性,筛选出针对通道的注意力,虽稍微增加了一些计算量,但并不影响检测实时性,且获得了相对最高的检测精度。
此外,SE-YOLOv3-SPP+-PAN网络具有同时检测车辆、行人多种类别的能力。包括检测目标的类别属性以及目标的位置信息。我们将网络输出设置为汽车、行人、坐着的人、骑自行车的人、面包车、卡车、有轨电车、杂项(如拖车、火车)8类。特别需要说明的是,车辆和行人大小和尺度往往是不同的。因此在本文的实验设计中,将网络分为三种不同尺度进行预测,分别为13×13,26×26,52×52三种栅格尺寸。借鉴特征金字塔的思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。
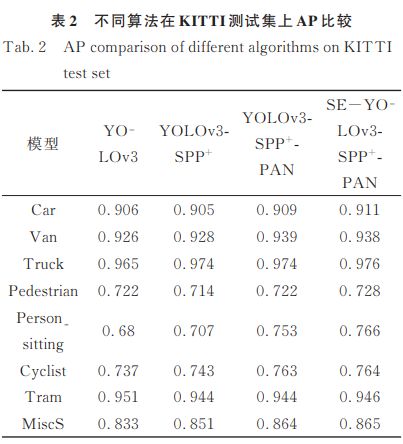
表2给出了基线网络以及改进的网络在KITTI数据集上各类目标检测的AP数值比较。结果表明,本文提出的SE-YOLOv3- SPP+ -PAN网络比基线网络在各个类别上的检测精度均有较大幅度的提升。其中Person_sitting类别的AP由68%提升至76.6%,提高了8.6%,提升结果较为明显。另外,Cyclist类别的AP由73.7%提升至76.4%,提高了2.7%。需要特别说明的是,Person_sitting类别和Cyclist类别在实际场景中具有尺度变化较大、目标相对较小的特点,基线YOLOv3网络对于这类目标的检测结果相对较差,而本文所构造的网络有效提升了这两类目标的检测效果。最终,实验表明所构造的SE-YO⁃LOv3- SPP+ -PAN网络有效提升了网络检测的平均精度,同时仍然保持了实时的检测速度26.5FPS,因此,更适宜无人驾驶场景下的车辆及行人目标检测。
此外,我们还测试了不同复杂场景下SE-YOLOv3- SPP+ -PAN网络对于车辆及行人的目标检测效果。对不同光照、遮挡场景、形变及小目标的检测结果进行了展示和分析,实验结果如图7~图9所示。

图7 不同光照情况下的检测结果

图8 不同程度遮挡的检测结果
图7展示了网络模型在道路场景光照变化剧烈情况下的目标检测结果。图中的检测框代表检测得到的不同物体。可见在阴影、光照不足时如图7(b),和道路强光、路面反射光较强情况如图7(f),本文设计的网络仍有较好的检出结果,证明了该网络模型对光照变化较强的适应能力。
图8展示了不同程度遮挡下的目标检测结果。可见,本文设计的网络模型在轻微程度遮挡(图8(a)和图8(b))、复杂密集车辆场景严重遮挡(图8(c)和图8(d))、复杂密集人群场景严重遮挡(图8(e)和图8(f))等情况下均有较好的检测效果。因而,本文提出的模型更适用于多种复杂实际交通场景中目标检测。
图9展示了具有变形、小尺度特征的目标检测结果。可以看出,本文改进的算法拥有不同形变及尺度下鲁棒的目标检测能力。

图9 变形、小尺度目标检测结果

图 10 错检和漏检
图10展示了本文设计的网络模型在道路场景下出现的目标错检和漏检情况。对于图10(a),错检了图片左下部分绿色检测框。分析造成其错检可能的原因为:局部检测导致的错检,外框和内框的IoU小于0.5(一定的阈值),所以绿色内框没有被完全消除。对于图10(b),漏检了图片左半部分车辆目标。说明网络在具有高度密集遮挡的小目标检测方面的性能还有待提高。因此,在实际复杂场景下,减少漏检和错检,进一步提升检测准确率将是我们未来的研究方向。
结论
本文在YOLOv3网络的基础上,通过添加改进的空间金字塔池化模块,对多尺度局部区域特征进行融合和拼接,使得网络能够更全面地学习目标特征;其次,利用空间金字塔缩短通道间的信息融合,构造了YOLOv3- SPP+ -PAN网络;最终,设计了基于注意力机制的高效目标检测模型SE-YOLOv3-SPP+-PAN。使用本文的新模型在KITTI实验数据集上进行了测试,实验证明SE-YOLOv3-SPP+-PAN所获得的mAP性能比YO⁃LOv3提升了2.2,因而更适合于复杂智能驾驶场景下的目标检测任务。
参考文献
[1] 裴伟,许晏铭,朱永英,等 . 改进的 SSD 航拍目标检测方法[J]. 软件学报,2019,30(3):248-268. PEI W,XU Y M,ZHU Y Y,et al. The target de⁃ tection method of aerial photography images with im⁃ proved SSD[J]. Journal of Software,2019,30(3): 248-268(in Chinese)
[2] 孙皓泽,常天庆,张雷,等 . 基于轻量级网络的装甲目标快速检测[J]. 计算机 辅助设计与图形学学报,2019,31(7):1110-1121. SUN H Z,CHANG T Q,ZHANG L,et al. Fast armored target detection based on lightweight net⁃ work[J]. Journal of Computer-Aided Design & Computer Graphics,2019,31(7):1110-1121. (in Chinese)
[3] 王中宇,倪显扬,尚振东,等 . 利用卷积神经网络的自动驾驶场景语义分割[J]. 光学 精密工程,2019, 27(11):2429-2438. WANG ZH Y,NI X Y,SHANG ZH D,et al. Au⁃ tonomous driving semantic segmentation with convo⁃ lution neural networks[J ]. Opt. Precision Eng. , 2019,27(11):2429-2438.(in Chinese)
[4] GIRSHICK R. Fast R-CNN[J]. Computer Sci⁃ ence,2015.
[5] REN S Q,HE K M,GIRSHICK,R,et al. Faster R-CNN:Towards real-time object detection with re⁃ gion proposal networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,39(6): 1137-1149.
[6] LIU W, ANGUELOY D, ERHAN D, et al. SSD:single shot multibox detector[C]. European Conference on Computer Vision. Springer Interna⁃ tional Publishing,2016 .
[7] REDMON J,DIVVALA S,GIRSHICK R,et al. You only look once:unified,real-time object detec⁃ tion[C]. 2016 IEEE Conference on Computer Vi⁃ sion and Pattern Recognition (CVPR). IEEE, 2016.
[8] REDMON J,FARHAD A. YOLO9000:Better, faster, stronger[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2017:6517-6525.
[9] REDMON J,FARHADI A. Yolov3:An incre⁃ mental improvement[J]. arXiv,2018.
[10] 王建林,付雪松,黄展超,等 . 改进 YOLOv2 卷积神经网络的多类型合作目标检测[J]. 光学 精密工程,2020,28(1). WANG J L,FU X S,HUANG ZH C,et al. Multi- type cooperative targets detection using im⁃ proved YOLOv2 convolutional neural network[J]. Opt. Precision Eng. ,2020,28(1).(in Chinese)
[11] QI Y ,SHI H ,LI N,et al. Vehicle detection un⁃ der unmanned aerial vehicle based on improved YOLOv3[C]. 2019 12th International Congress on Image and Signal Processing,BioMedical En⁃ gineering and Informatics(CISP-BMEI),2019.
[12] 杨晋生,杨雁南,李天骄 . 基于深度可分离卷积 的交通标志识别算法[J]. 液晶与显示,2019,34 (12):1191-1201 YANG J SH,YANG Y N,LI T J,et al. Traffic sign recognition algorithm based on depthwise sepa⁃ rable convolutions[J]. Chinese Journal of Liquid Crystals and Displays. , 2019, 34(12):1191- 1201.(in Chinese)
[13] WANG Q ,WU B ,ZHU P,et al. ECA-net:Ef⁃ ficient channel attention for deep convolutional neu⁃ ral networks[C]. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog⁃ nition,2020:11534-11542.
[14] 余永维,韩鑫,杜柳青 . 基于 Inception-SSD 算法的零件识别[J]. 光学 精密工程 ,2020,28(8): 1799-1809. YU Y W,HAN X,DU L Q. Target part recognition based Inception-SSD algorithm[J]. Opt. Precision Eng. ,2020,28(8):1799-1809.(in Chinese)
[15] WANG H ,YU Y ,CAI Y ,et al. A compara⁃ tive study of state-of-the-art deep learning algo⁃ rithms for vehicle detection[J]. IEEE Intelligent Transportation Systems Magazine,2019:1-1.
[16] 程全,樊宇,刘玉春,等 . 多特征融合的车辆识别 技术[J]. 红外与激光工程,2018,v. 47;No. 285 (7):316-321. CHENG Q,FAN Y,LIU Y C,et al. Multi- type cooperative targets detection using improved YO⁃ LOv2 convolutional neural network[J]. Infrared and Laser Engineering,2018,v. 47;No. 285(07): 316-321.(in Chinese)
[17] HE,K M,et al. "Spatial pyramid pooling in deep convolutional networks for visual recognition. " Eu⁃ ropean Conference on Computer Vision. Springer International Publishing,2014.
[18] Lin T Y,DOLLAR,P,GIRSHICK R,et al. Feature pyramid networks for object detection[C]. Proceedings of the IEEE conference on computer vi⁃ sion and pattern recognition,2017:2117-2125.
[19] LIU S ,QI L ,QIN H,et al. Path aggregation network for instance segmentation[C]. Proceed⁃ings of the IEEE conference on computer vision and pattern recognition,2018:8759-8768.
[20] HU J,SHEN L,ALBANIE S. Squeeze-and-exci⁃ tation networks[C]. Proceedings of the IEEE con⁃ ference on computer vision and pattern recognition, 2018:7132-7141.
END