时间序列分类算法
A common task for time series machine learning is classification. Given a set of time series with class labels, can we train a model to accurately predict the class of new time series?
时间序列机器学习的常见任务是分类。 给定一组带有类别标签的时间序列,我们可以训练模型来准确预测新时间序列的类别吗?
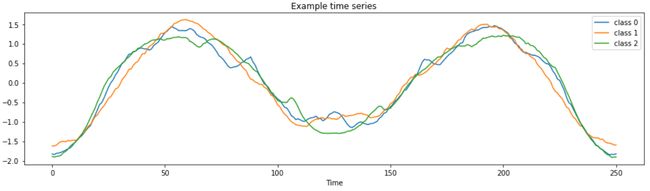
There are many algorithms dedicated to time series classification! This means you don’t have wrangle your data into a scikit-learn classifier or to turn to deep learning to solve every time series classification task.
有许多专用于时间序列分类的算法! 这意味着您无需将数据纠缠到scikit-learn分类器中,也无需转向深度学习来解决每个时间序列分类任务。
In this article, I will introduce five categories of time series classification algorithms with details of specific algorithms. These specific algorithms have been shown to perform better on average than a baseline classifier (KNN) over a large number of different datasets [1].
在本文中,我将介绍五种时间序列分类算法,以及特定算法的详细信息。 在大量不同的数据集上,这些特定算法的平均表现优于基线分类器(KNN)[1]。
- Distance-based (KNN with dynamic time warping) 基于距离(具有动态时间扭曲的KNN)
- Interval-based (TimeSeriesForest) 基于时间间隔(TimeSeriesForest)
- Dictionary-based (BOSS, cBOSS) 基于字典(BOSS,cBOSS)
- Frequency-based (RISE — like TimeSeriesForest but with other features) 基于频率的(RISE-与TimeSeriesForest类似,但具有其他功能)
- Shapelet-based (Shapelet Transform Classifier) 基于Shapelet(Shapelet变换分类器)
I conclude with brief guidance on selecting an appropriate algorithm.
最后,我将对选择合适的算法进行简要指导。
The algorithms described in this article have been implemented in the sktime python package.
本文介绍的算法已在sktime python软件包中实现。
为什么要使用时间序列专用算法? (Why dedicated algorithms for time series?)
Time series classification algorithms tend to perform better than tabular classifiers on time series classification problems.
在时间序列分类问题上,时间序列分类算法的性能往往优于表格分类器。
A common, but problematic solution to time series classification is to treat each time point as a separate feature and directly apply a standard learning algorithm (e.g. scikit-learn classifiers). In this approach, the algorithm ignores information contained in the time order of the data. If the feature order were scrambled, the predictions wouldn’t change.
时间序列分类的一个常见但有问题的解决方案是将每个时间点视为一个单独的功能,并直接应用标准学习算法(例如scikit-learn分类器)。 在这种方法中,算法将忽略数据时间顺序中包含的信息。 如果功能顺序被打乱,则预测不会改变。
It is also common to use deep learning to classify time series. LSTMs and CNNs are capable of mining dynamical characteristics of time series, hence their success. Yet neural networks have some challenges that make them unsuitable for many classification tasks:
使用深度学习对时间序列进行分类也是很常见的。 LSTM和CNN能够挖掘时间序列的动态特征,因此很成功。 然而,神经网络面临一些挑战,使它们不适用于许多分类任务:
- Selecting an efficient architecture 选择高效的架构
- Hyper-parameter tuning超参数调整
- Limited data (neural networks need many examples)数据有限(神经网络需要很多示例)
- Slow to train 训练慢
In spite of these challenges, there do exist specific neural network architectures for time series classification. These have been implemented in the sktime-dl python package.
尽管存在这些挑战,但确实存在用于时间序列分类的特定神经网络体系结构。 这些已在sktime-dl python包中实现。
时间序列分类的基本概念 (Foundational Concepts of Time Series Classification)
时间序列转换(Time Series Transformations)
Many time series specific algorithms are compositions of transformed time series and conventional classification algorithms, such as those in scikit-learn.
许多特定于时间序列的算法是变换后的时间序列和常规分类算法(例如scikit-learn中的算法)的组合。
Feature extraction is very diverse and complex.
特征提取非常多样化和复杂。
Features can be extracted globally (over the entire time series) or locally (over regular intervals/bins, random intervals, sliding windows of intervals, and so on).
可以全局(在整个时间序列上)或局部(在常规间隔/区间,随机间隔,间隔的滑动窗口等)上提取要素。
Series can be transformed into primitive values (e.g. mean, standard deviation, slope) or into other series (e.g. Fourier transform, series of fitted auto-regressive coefficients).
级数可以转换为原始值(例如,均值,标准差,斜率),也可以转换为其他级数(例如,傅立叶变换,拟合的自回归系数系列)。
Last, transformations can one-dimensional or multi-dimensional.
最后,转换可以是一维或多维的。
承包 (Contracting)
Contracting is a key concept used in most algorithms described in this article.
合同是本文描述的大多数算法中使用的关键概念。
Simply stated, contracting limits the run time of an algorithm. Until the allotted time expires, the algorithm continues iterating to learn the given task.
简而言之,合同限制了算法的运行时间。 在分配的时间到期之前,算法将继续迭代以学习给定的任务。
基于距离的分类 (Distance-Based Classification)
These classifiers use distance metrics to determine class membership.
这些分类器使用距离度量来确定类成员身份。
时间序列的K最近邻(具有动态时间规整) (K-Nearest Neighbors (with Dynamic Time Warping) for Time Series)
The popular k-nearest neighbors (KNN) algorithm can be adapted for time series by replacing the Euclidean distance metric with the dynamic time warping (DTW) metric. DTW measures similarity between two sequences that may not align exactly in time, speed, or length. (Click here for my explanation of DTW for time series clustering).
通过用动态时间规整(DTW)度量代替欧几里得距离度量,可以将流行的k最近邻(KNN)算法应用于时间序列。 DTW测量可能在时间,速度或长度上未完全对齐的两个序列之间的相似性。 (单击此处可了解我对时间序列聚类的DTW的解释)。
KNN with DTW is commonly used as a benchmark for evaluating time series classification algorithms because it is simple, robust, and does not require extensive hyperparameter tuning.
具有DTW的KNN通常用作评估时间序列分类算法的基准,因为它简单,健壮并且不需要大量的超参数调整。
While useful, KNN with DTW requires a lot of space and time to compute. During classification, the KNN-DTW compares each object with all the other objects in the training set. Further, KNN provides limited information about why a series was assigned to a certain class.
虽然有用,但带有DTW的KNN需要大量空间和时间来进行计算。 在分类期间,KNN-DTW将每个对象与训练集中的所有其他对象进行比较。 此外,KNN提供了有关为什么将系列分配给某个类别的有限信息。
KNN may also perform poorly with noisy series — the noise in a series may overpower subtle differences in shape that are useful for class discrimination [4].
在嘈杂的序列中,KNN的性能也可能很差-序列中的噪声可能会克服形状上细微的差异,这对于分类识别很有用[4]。
基于间隔的分类器 (Interval-based Classifiers)
These classifiers base classification on information contained in various intervals of series.
这些分类器基于各个系列间隔中包含的信息进行分类。
时间序列森林分类器 (Time Series Forest Classifier)
A time series forest (TSF) classifier adapts the random forest classifier to series data.
时间序列森林(TSF)分类器使随机森林分类器适应序列数据。
- Split the series into random intervals, with random start positions and random lengths. 将序列分为随机间隔,随机起始位置和随机长度。
- Extract summary features (mean, standard deviation, and slope) from each interval into a single feature vector. 从每个间隔中提取摘要特征(均值,标准差和斜率)到单个特征向量中。
- Train a decision tree on the extracted features. 在提取的特征上训练决策树。
- Repeat steps 1–3 until the required number of trees have been built or time runs out. 重复步骤1-3,直到建立了所需的树数或时间耗尽为止。
New series are classified according to a majority vote of all the trees in the forest. (In a majority vote, the prediction is the class that is predicted by the most trees is the prediction of the forest).
新系列根据森林中所有树木的多数票进行分类。 (在多数表决中,预测是由最多树木预测的类别是森林的预测)。
Experimental studies have demonstrated that time series forest can outperform baseline competitors, such as nearest neighbors with dynamic time warping [1, 7].
实验研究表明,时间序列森林可以胜过基准竞争对手,例如具有动态时间扭曲的最近邻居[1,7]。
Time series forest is also computationally efficient.
时间序列林在计算上也很有效。
Last, time series forest is an interpretable model. Time feature importance can be extracted from time series forest, as shown in the sktime univariate time series classification demo.
最后,时间序列森林是一种可解释的模型。 可以从时间序列林中提取时间特征重要性,如sktime单变量时间序列分类演示中所示。
基于字典的分类 (Dictionary-Based Classification)
Dictionary-based classifiers first transform real-valued time series into a sequence of discrete “words”. Classification is then based on the distribution of the extracted symbolic words.
基于字典的分类器首先将实值时间序列转换为离散的“单词”序列。 然后基于提取的符号词的分布进行分类。
Dictionary classifiers all use the same core process: A sliding window of length w is run across a series. For each window, the numeric series is transformed into a “word” of length l. This word consists of α possible letters.
字典分类器都使用相同的核心过程:长度为w滑动窗口贯穿一系列序列。 对于每个窗口,数字序列被转换为长度为l的“单词”。 这个词由α可能的字母组成。
袋SFA符号(BOSS) (Bag of SFA Symbols (BOSS))
Word features for BOSS classifiers are extracted from series using the Symbolic Fourier Approximation (SFA) transformation:
使用符号傅立叶近似(SFA)变换从系列中提取BOSS分类器的单词特征:
Calculate the Fourier transform of the window (the first term is ignored if normalization occurs)
计算窗口的傅立叶变换(如果发生规范化,则忽略第一项)
Discretize the first
lFourier terms into symbols to form a “word” using Multiple Coefficient Binning (MCB). MCB is a supervised algorithm that bins continuous time series into a sequence of letters.使用多重系数合并(MCB)将前
l傅立叶项离散化为符号,以形成一个“单词”。 MCB是一种监督算法,可将连续时间序列分为字母序列。

A dictionary of these words is constructed as the window slides, recording a count of each word’s frequency. If the same word is produced by two or more consecutive windows, the word will only be counted once. When the sliding window has completed, the series is transformed into a histogram based on the dictionary.
当窗口滑动时,将构造这些单词的字典,记录每个单词的频率计数。 如果同一单词由两个或多个连续的窗口产生,则该单词将仅计数一次。 滑动窗口完成后,该序列将基于字典转换为直方图。
Finally, any classifier can be trained on the word histograms extracted from the series.
最后,可以对从该系列中提取的单词直方图进行任何分类器训练。
BOSS合奏 (The BOSS Ensemble)
The original BOSS algorithm is actually an ensemble of the BOSS classifiers previously described. The BOSS ensemble conducts grid-search across the parameters (l, α, w and p) of the individual BOSS classifier. (p controls whether the subseries is normalized.) The ensemble only retains the members whose accuracy is within 92% accuracy of the best classifier.
原始的BOSS算法实际上是前面所述的BOSS分类器的集合。 BOSS集合对各个BOSS分类器的参数( l , α , w和p )进行网格搜索。 ( p控制子系列是否被归一化。)集成仅保留其精度在最佳分类器的92%以内的成员。
The BOSS ensemble uses a nearest-neighbor algorithm as its classifier. The classifier uses a custom non-symmetric distance function: a partial Euclidian distance that only includes words contained in the test instance’s histogram.
BOSS集成使用最近邻算法作为其分类器。 分类器使用自定义的非对称距离函数:部分欧几里得距离,仅包括测试实例的直方图中包含的单词。
Due to searching over a large pre-defined parameter space, BOSS carries time overhead and risks instability in memory usage.
由于搜索了很大的预定义参数空间,因此BOSS会占用时间,并有可能导致内存使用不稳定。
The BOSS ensemble was the most accurate dictionary-based classifier in the Great Time Series Classification Bake-off paper [1].
BOSS集成是《大时间序列分类》 [1]中最准确的基于字典的分类器。
可收缩的BOSS(cBOSS) (Contractable BOSS (cBOSS))
The cBOSS algorithm is an order of magnitude faster than BOSS. Compared to BOSS, cBOSS had no significant difference in accuracy on datasets in the UCR Classification Archive.
cBOSS算法比BOSS快一个数量级。 与BOSS相比,cBOSS在UCR分类存档中的数据集准确性上没有显着差异。
Instead of doing grid search across the full parameter space like BOSS, cBOSS randomly samples from the parameter space without replacement. cBOSS then subsamples the data for each base classifier.
cBOSS不会像BOSS这样在整个参数空间上进行网格搜索,而是从参数空间中随机采样而不进行替换。 然后,cBOSS对每个基本分类器的数据进行二次采样。
cBOSS improves the memory requirements of BOSS by retaining a fixed number of base classifiers, instead of retaining all classifiers above a given performance threshold. Last, cBOSS exponentially weights the contribution of each base classifier according to train accuracy.
cBOSS通过保留固定数量的基本分类器而不是保留高于给定性能阈值的所有分类器来改善BOSS的内存要求。 最后,cBOSS根据训练的准确性对每个基本分类器的贡献进行指数加权。
基于频率 (Frequency-based)
Frequency-based classifiers rely on frequency data extracted from series.
基于频率的分类器依赖于从序列中提取的频率数据。
随机间隔谱集合(RISE) (Random Interval Spectral Ensemble (RISE))
Random Interval Spectral Ensemble, or RISE, is a popular variant of time series forest.
随机间隔频谱合奏(RISE)是时间序列森林的一种流行变体。
RISE differs from time series forest in two ways. First, it uses a single time series interval per tree. Second, it is trained using spectral features extracted from the series, instead of summary statistics.
RISE与时间序列林有两个不同之处。 首先,它对每棵树使用单个时间序列间隔。 其次,使用从系列中提取的光谱特征而不是摘要统计信息对其进行训练。
RISE use several series-to-series feature extraction transformers, including:
RISE使用了几个串联到串联的特征提取变压器,包括:
- Fitted auto-regressive coefficients 拟合的自回归系数
- Estimated autocorrelation coefficients估计的自相关系数
- Power spectrum coefficients (the coefficients of the Fourier transform)功率谱系数(傅立叶变换的系数)
The RISE algorithm is straightforward:
RISE算法很简单:
- Select random interval of a series (length is a power of 2). (For the first tree, use the whole series) 选择一系列随机间隔(长度为2的幂)。 (对于第一棵树,请使用整个系列)
- For the same interval on each series, apply the series-to-series feature extraction transformers (autoregressive coefficients, autocorrelation coefficients, and power spectrum coefficients) 对于每个系列的相同间隔,应用系列到系列特征提取变压器(自回归系数,自相关系数和功率谱系数)
- Form a new training set by concatenating the extracted features 通过串联提取的特征形成新的训练集
- Train a decision tree classifier训练决策树分类器
- Ensemble 1–4合奏1-4
Class probabilities are calculated as a proportion of base classifier votes. RISE controls the run time by creating an adaptive model of the time to build a single tree. This is important for long series (such as audio), where very large intervals can mean very few trees.
类别概率按基本分类器投票的比例计算。 RISE通过创建时间自适应模型来构建一棵树来控制运行时间。 这对于较长的系列(例如音频)很重要,在这种情况下,很大的间隔可能意味着很少的树木。
基于Shapelet的分类器 (Shapelet-Based Classifiers)
Shapelets are subsequences, or small sub-shapes of time series that are representative of a class. They can be used to detect “phase-independent localised similarity between series within the same class” [1].
小形状是代表一个类的时间序列的子序列或小子形状。 它们可用于检测“同一类别内系列之间的相位无关的局部相似性” [1]。

A single shapelet is an interval in a time series. The intervals in any series can be enumerated. For example, [1,2,3,4] has 5 intervals: [1,2], [2,3], [3,4], [1,2,3], [2,3,4].
单个小波是时间序列中的间隔。 可以列举任何系列的间隔。 例如, [1,2,3,4]具有5个间隔: [1,2] , [2,3] , [3,4] , [1,2,3] , [2,3,4] 。
Shapelet-based classifiers search for shapelets with discriminatory power.
基于Shapelet的分类器搜索具有判别力的Shapelet。
These shapelet features can then be used to interpret a shapelet-based classifier — the presence of certain shapelets make one class more likely than another.
然后,这些shapelet特征可用于解释基于shapelet的分类器-某些shapelet的存在使一类比另一类更有可能。
Shapelet变换分类器 (Shapelet Transform Classifier)
In the Shapelet Transform Classifier, the algorithm first identifies the top k shapelets in the dataset.
在Shapelet变换分类器中,算法首先识别数据集中的前k个Shapelet。
Next, k features for the new dataset are calculated. Each feature is computed as the distance of the series to each one of the k shapelets, with one column per shapelet.
接下来,计算新数据集的k个特征。 将每个特征计算为系列与ks个小链中每个小链的距离,每个小形有一列。
Finally, any vector-based classification algorithm can be applied to the shapelet-transformed dataset. In [1], a weighted ensemble classifier was used. In [2], the authors only used a Rotation Forest classifier, a tree-based ensemble that constructs each tree on a subset of features transformed by PCA [5]. On average, rotation forest is the best classifier for problems with continuous features, as shown in [6].
最终,任何基于矢量的分类算法都可以应用于经过Shapelet转换的数据集。 在[1]中,使用了加权集成分类器。 在[2]中,作者仅使用了Rotation Forest分类器,这是一种基于树的集成,可在PCA转换后的特征子集上构建每棵树[5]。 平均而言,旋转林是连续特征问题的最佳分类器,如[6]所示。
In sktime, a Random Forest classifier (500 trees) is used by default because rotation forest is not yet available in python [8].
在sktime ,默认情况下使用随机森林分类器(500棵树),因为python中尚未提供旋转森林[8]。
How does the algorithm identify and select shapelets?
该算法如何识别和选择shapelet?
In sktime, the shapelet search process does not fully enumerate and evaluate all possible shapelets. Instead, it randomly searches for shapelets to evaluate.
在sktime ,shapelet搜索过程无法完全枚举和评估所有可能的shapelet。 而是随机搜索shapelet进行评估。
Each shapelet considered is evaluated according to information gain. The strongest non-overlapping shapelets are retained.
根据信息增益评估考虑的每个形状。 保留最强的不重叠形状。
You can specify the amount of time to search for shapelets before performing the shapelet transform. The default time in sktime is 300 minutes.
您可以指定执行shapelet转换之前搜索shapelet的时间。 sktime的默认时间为300分钟。
整体分类器 (Ensemble Classifiers)
HIVE-COTE(HIVE-COTE)
The Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE) is a meta ensemble built on the classifiers discussed previously.
基于转换的集成的分层投票集合(HIVE-COTE)是建立在前面讨论的分类器上的元集合。
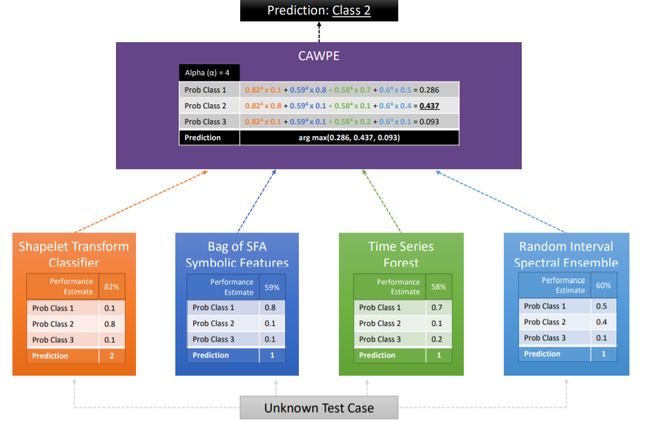
HIVE-COTE predictions are a weighted average of predictions produced by its members: shapelet transform classifier, BOSS, Time Series Forest, and RISE.
HIVE-COTE预测是其成员产生的预测的加权平均值:shapelet变换分类器,BOSS,时间序列森林和RISE。
Each sub-classifier estimates the probability of each class. The control unit then combines these probabilities (CAPWE). The weights are assigned as the relative estimated quality of the classifier found on the training data.
每个子分类器估计每个分类的概率。 然后,控制单元将这些概率(CAPWE)合并。 权重被分配为在训练数据上找到的分类器的相对估计质量。
使用哪个分类器? (Which Classifier to Use?)
There are three main considerations when selecting a time series classifier: predictive accuracy, time/memory complexity, and data representation.
选择时间序列分类器时,主要考虑三个方面:预测准确性,时间/内存复杂度和数据表示形式。
With no data-specific information, start with ROCKET or HIVE-COTE. (ROCKET is a simple linear classifier based on random convolutional kernels — random length, weights, bias, dilation, and padding). The authors of [2] argue that “with no expert knowledge to the contrary, the most accurate algorithm design is to ensemble classifiers built on different representations.” On average, ROCKET is not worse than HIVE-COTE and is much faster.
没有特定于数据的信息,请从ROCKET或HIVE-COTE开始。 (ROCKET是基于随机卷积核(随机长度,权重,偏差,膨胀和填充)的简单线性分类器)。 [2]的作者认为“没有相反的专业知识,最准确的算法设计就是对基于不同表示形式的分类器进行集成。” 平均而言,ROCKET不比HIVE-COTE差,并且速度要快得多。
Shapelet-based classifiers will be better when the best feature might be the presence or absence of a phase-independent pattern in a series.
当最好的功能可能是序列中是否存在与相位无关的模式时,基于Shapelet的分类器会更好。
Dictionary-based (BOSS) or frequency-based (RISE) classifiers will be better when you can discriminate using the frequency of a pattern.
当您可以使用模式的频率进行区分时,基于字典(BOSS)或基于频率(RISE)的分类器会更好。
最后的话 (A Final Word)
If you enjoyed this article, please follow me for more content on data science topics! I plan to continue writing about time series classification, clustering, and regression.
如果您喜欢本文,请关注我以获取有关数据科学主题的更多内容! 我计划继续写有关时间序列分类,聚类和回归的文章。
Thank you to Markus Loning for his feedback on this article and to Anthony Bagnall for guidance on model selection.
感谢Markus Loning对本文的反馈以及Anthony Bagnall对模型选择的指导。
翻译自: https://towardsdatascience.com/a-brief-introduction-to-time-series-classification-algorithms-7b4284d31b97
时间序列分类算法