论文阅读 + 复现:(LRCNs)Long-term Recurrent Convolutional Networks for Visual Recognition and Description
目录
写在前面
网络架构
论文中的训练细节
复现代码时遇到的问题 & 解决方案
1、如何动态调整 pretrained model 中的 layer?
2、RuntimeError: Input and parameter tensors are not at the same device, found input tensor at cpu and parameter tensor at cuda:0
3、torch.nn.Linear 用法
4、torch.nn.LSTM & torch.nn.LSTMCell 用法和区别
5、RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
论文名称:Long-term Recurrent Convolutional Networks for Visual Recognition and Description
论文地址:https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Donahue_Long-Term_Recurrent_Convolutional_2015_CVPR_paper.pdf
论文作者:Jeff Donahue, Lisa Anne Hendricks, Marcus Rohrbach, Subhashini Venugopalan, Sergio Guadarrama, Kate Saenko, Trevor Darrell
复现代码:https://github.com/BizhuWu/LRCN_PyTorch(可以的话,github 上给个小星星嘛)
写在前面
这篇论文思想较简单,这里就不详细讲论文的细节了,主要讲讲论文里的网络架构,了解一下主要思想就好。
顺便感叹一下,本篇论文实验是真的做得多,涉及三大任务:activity recognition、image description 和 video description。最后发了 TPAMI,羡慕的泪水流到肚子里。。。
网络架构
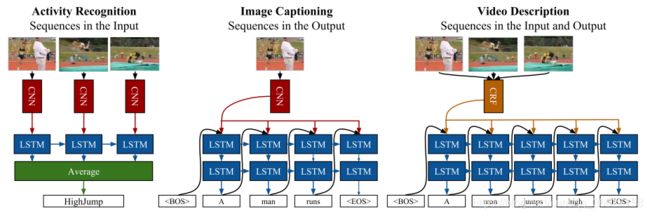
这里只讲讲 activity recognition,其他两大任务不太熟。
其实图片已经把网络架构和思想表达得很清楚了。其思想就是:一个 video clip 就相当于一句话,每一帧就相当于这个句子中的单词 / 字。所以 activity recognition 也是可以用自然语言处理领域中的 LSTM(Long Short Term Memory)来学习的。那我们要做的就是提取出每一帧的图片特征,每一帧的图片特征就可以作为 LSTM 的每一个输入,即“单词”,再让 LSTM 学习这个 video clip 里所有帧的时序关系,以此达到动作识别的效果。
论文中的训练细节
- 作者提取帧数据特征的 CNN 用的是 AlexNet
The CNN base of LRCN in our activity recognition experiments is a hybrid of the CaffeNet [12] reference model (a minor variant of AlexNet [17])
- 作者做实验的时候有使用 Single Input Type(RGB / Optical Flow),也有使用 Weighted Average。我在这里以简单复现为主,就只使用 RGB 作为 input 了

- LSTM hidden units 的个数为 256
We thus use 1024 hidden units for flow inputs, and 256 for RGB inputs.
- 当使用 RGB 作为输入时,两种 models:“全连接层里只使用了 AlexNet 中的 fc6 层” 或者 “使用 fc6 + fc7 层” 二者实验结果区别不大,所以作者选择使用 “全连接层里只使用了 AlexNet 中的 fc6 层” 的模型
When using RGB images as input, the difference between using fc6 or fc7 features is quite small; using fc6 features only increases accuracy by 0.2%. Because both models perform better with fc6 features, we train our final models using fc6 features (denoted by LRCN-fc6).
复现代码时遇到的问题 & 解决方案
1、如何动态调整 pretrained model 中的 layer?
由于论文中是只是用了 fc6,所以需要把 fc6 后面的层删除了。
模型结构原来长这样:
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
也就是说需要把 classifier 中 index 为 2-6 的层都删除了。
Sequential 的动态添加用的 torch.nn.Module.add_module()
network3 = nn.Sequential()
network3.add_module('flat', nn.Flatten(start_dim=1))
network3.add_module('hidden', nn.Linear(in_features, out_features))
network3.add_module('output', nn.Linear(out_features, out_classes))但是注意 Sequential 没有动态删除的方法!所以要删除只能是覆盖一个新的 Sequential
参考:https://discuss.pytorch.org/t/how-to-delete-layer-in-pretrained-model/17648
model.classifier = nn.Sequential(*list(model.classifier.children())[:-5])
2、RuntimeError: Input and parameter tensors are not at the same device, found input tensor at cpu and parameter tensor at cuda:0
刚遇到这个问题的时候很奇怪,明明传入网络和数据都已经 to(device) 了,为什么还说 input tensor 在 cpu 上呢?
model = LCRN().to(device)
video_clips = video_clips.to(device)
label = label.to(device)
output = model(video_clips)后面仔细对比了一下以前的代码,唯一不同的地方就是我在 model 的 forward 函数里对传入进来的 video_clip 进行了操作:先对 video_clip 里的每一帧丢入 CNN 中提取特征,再把所有帧的特征组合起来丢入 LSTM 中。所以就开始怀疑是不是在操作的时候代码又把 tensor 放回了 cpu。请教了实验室里大神后,证实了我的想法,帮我找到了错误,感谢感谢!
torch.empty() 不设置 device 的话,会设置为默认的 tensor type,我这里之前没改过默认的 tensor type,所以也就是 CPU tensor!
frameFeatures = torch.empty(size=(video_clip.size()[0], video_clip.size()[2], config.input_size), device='cuda')
参考:
- https://pytorch.org/docs/stable/generated/torch.empty.html
- https://pytorch.org/tutorials/beginner/basics/tensorqs_tutorial.html
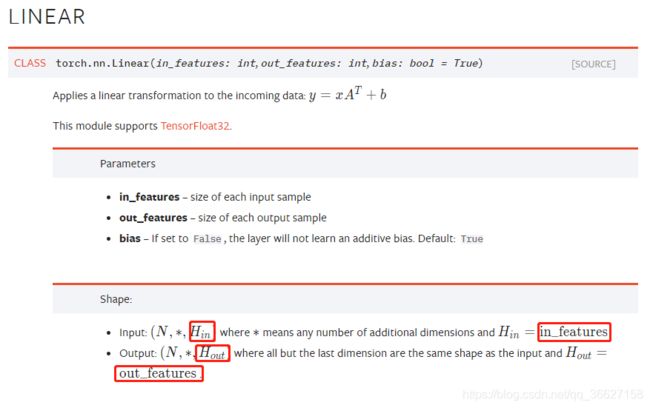
3、torch.nn.Linear 用法
参考:https://pytorch.org/docs/stable/generated/torch.nn.Linear.html?highlight=linear#torch.nn.Linear
4、torch.nn.LSTM & torch.nn.LSTMCell 用法和区别
torch.nn.LSTM:

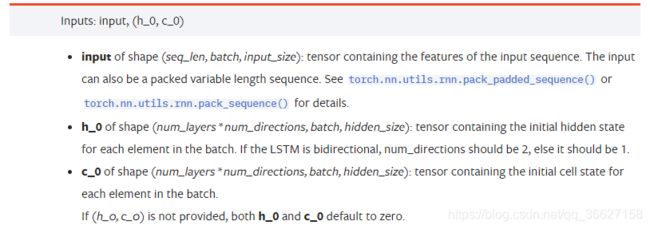
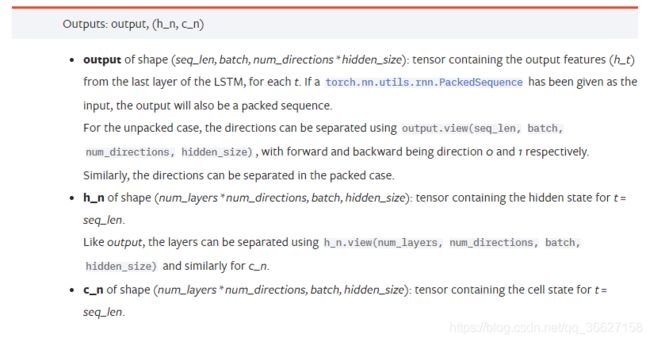
区别:
LSTMCell 的输入是一个时间步x_t,需要写一个循环跑一个完整的序列。
LSTM 的输入是SEQUENCE of inputs x_1,x_2,…,x_T,因此不需要写循环。
参考:
- https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html#torch.nn.LSTM
- https://pytorch.org/docs/stable/generated/torch.nn.LSTMCell.html#torch.nn.LSTMCell
- http://t.zoukankan.com/jiangkejie-p-10600185.html
5、RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
一开始报这个错误的时候,我是有点懵的,维度我是算过也输出过的,怎么会报错呢?
报错原因分析:
nn.LSTM() 函数里 batch_first 这个参数设置为 True 了,导致 tensor reshape 了,所以 output 是不连续的!
参考:
- https://discuss.pytorch.org/t/problem-reshaping-an-lstm-output-with-view-when-batch-first-true/1358
- https://discuss.pytorch.org/t/output-of-rnn-is-not-contiguous/298
解决方法:
后面把 .view() 换成了 .reshape() 之后就不报错了,于是查了一下两者的区别:
同:
从功能上来看,它们的作用是相同的,都是将原张量元素(按顺序)重组为新的shape。
异:
我的理解是,有两种情况:如果一个 tensor 原本在内存中是连续的,此时可以直接使用 view(),也可以直接使用 reshape() 方法。
如果原 tensor 经过了 transpose 之类的操作,改变了 tensor 中的元素(比如交换了元素的位置),但是 tensor 在内存空间中的存储位置没有改变,那么变换后的 tensor 在内存空间中的存储就不连续了。
此时若想 reshape 变换后的 tensor,可以有两种方法:
1、先调用 .contiguous() 方法,使 tensor 的元素在内存空间中连续,然后调用 .view();
2、直接调用 .reshape(),此时由于 tensor 的元素内存地址不连续,reshape 方法返回的就不是原 tensor 的 view,而是原 tensor 的一份 copy。
参考:
- https://blog.csdn.net/vam_kindred/article/details/107121759
- https://blog.csdn.net/qq_39507748/article/details/105381089