深入浅出对话系统——拥抱笑脸Transformer库的使用
引言
本文参考资料是Hugging Face官网的课程,主要介绍了transformer库的使用。
Pipeline
Transformer库中最基本的对象是pipeline(管道),将模型与其他必要预处理和后处理步骤组合起来,使我们可以直接输入任何文本并获得可理解的答案:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier(
[
"This restaurant is awesome",
"I hate this so much!",
]
)
No model was supplied, defaulted to distilbert-base-uncased-finetuned-sst-2-english (https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)
[{'label': 'POSITIVE', 'score': 0.9998743534088135},
{'label': 'NEGATIVE', 'score': 0.9994558691978455}]
我们在pipeline中仅传入任务名称sentiment-analysis(情感分析),此时,管道默认选择一个特定的预训练模型,该模型已经对英文情感分析进行了微调。第一次运行会下载并缓存该模型。
将一些文本传递到管道时涉及三个主要步骤:
- 预处理: 文本被预处理为模型可以理解的格式
- 输入模型: 构建模型,将预处理的输入传递给模型
- 后处理: 模型预测的结果经过后处理,变成人类可理解的格式
目前可用的一些管道有:
- feature-extraction (获取文本的向量表示)
- fill-mask填充给定文本中的空白(完形填空)
- ner (named entity recognition)词性标注
- question-answering问答
- sentiment-analysis情感分析
- summarization摘要生成
- text-generation文本生成
- translation翻译
- zero-shot-classification零样本分类
我们也可以从 Hub 中针对特定任务来选择特定模型的管道 例如,情绪分析。
管道API可以处理不同的NLP任务,可以使用完整的编码器-解码器架构,也可以使用编码器或解码器,这取决于你要解决的具体任务:
| 模型 | 例子 | 任务 |
|---|---|---|
| Encoder | ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa | 句子分类、命名实体识别、抽取式问答 |
| Decoder | CTRL, GPT, GPT-2, Transformer XL | 文本生成 |
| Encoder-decoder | BART, T5, Marian, mBART | 摘要生成、翻译、生成式问答 |
我们上面演示的例子是为特定任务编程的,不能执行她们的变体,在下一节中,我们将了解管道内部的内容以及如何自定义其行为。
Pipeline的背后
让我们从一个完整的例子开始,看看当我们在第1节中执行以下代码时,幕后发生了什么:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier(
[
"This restaurant is awesome",
"I hate this so much!",
]
)
[{'label': 'POSITIVE', 'score': 0.9998743534088135},
{'label': 'NEGATIVE', 'score': 0.9994558691978455}]
正如我们在前面看到的,这个管道将三个步骤组合在一起:预处理、传递输入到模型和后处理:
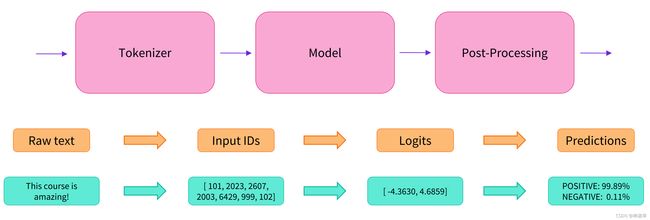
tokenizer预处理
与其他神经网络一样,Transformer模型也不能直接处理原始文本,因此我们管道的第一步就是将文本输入转换为模型可以理解的数字。为此,我们使用了一个分词器tokenizer,它负责:
- 将输入拆分为称为标记的单词、子词(subword)或符号(symbols,如标点符号)
- 将每个标记映射成一个整数
- 添加可能对模型有用的其他输入
我们可以使用 AutoTokenizer 类及其 from_pretrained 方法,以保证所有这些预处理都以与模型预训练时完全相同的方式完成。
设定模型的checkpoint(检查点)名称,它会自动获取与模型的Tokenizer关联的数据并缓存它(所以它只在你第一次运行下面的代码时下载)。
由于情感分析管道的默认检查点是 distilbert-base-uncased-finetuned-sst-2-english,我们可以运行以下命令得到我们需要的tokenizer:
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint) # 自动加载该模型训练时所用的分词器
有了分词器后,我们可以调用分词器来完成上面所说的过程:
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
# padding=True 填充输入序列,使得批次内序列长度一致
# truncation=True 截断过长的序列
# return_tensors="pt" 返回PyTorch 张量
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
{
'input_ids': tensor([
[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
])
}
可以看到,我们得到了两组张量。input_ids就是分词后的标记转换为数字的形式,其中0表示填充标记;而attention_mask中非1的标记是不需要注意的,这里是因为它们都是填充标记。
模型
我们也可以像分词器一样下载我们的预训练模型, Transformers 提供了一个 AutoModel 类,它也有一个 from_pretrained 方法:
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
AutoModel类可以从checkpoint实例化任何模型,而且这是一种比较好的实例化模型方法。
在上面的代码中,我们下载了之前在管道中使用的相同检查点,并用它实例化了一个模型。
但是这个架构只包含基本的Transformer模块:给定一些输入,它会输出隐藏状态。通常这些隐藏状态会作为模型另一部分的输入,即模型Head。
模型Head
我们可以使用相同的模型架构执行不同的任务,但是每个任务都有与之关联的不同的模型head。
Model heads:将隐藏状态的高维向量(也就是logits向量)作为输入,并将它们投影到不同的维度上。 它们通常由一个或几个线性层组成:
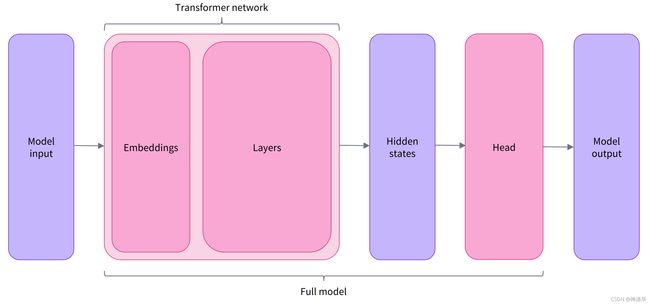
从上图可以看到,输入经过嵌入层输出logits向量,产生句子的最终表征。
然后可以附加不同的模型Head,下面列举了部分:
- Model (retrieve the hidden states)
- ForCausalLM
- ForMaskedLM
- ForMultipleChoice
- ForQuestionAnswering
- ForSequenceClassification
- ForTokenClassification
以情感分析为例,我们需要一个带有序列分类的模型Head(能将句子分为正面或负面)。因此,我们实际上不会使用AutoModel类,而是使用AutoModelForSequenceClassification,因为它包含了我们想要的模型Head。
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
模型head将我们之前看到的高维向量作为输入,并输出包含两个值(每个标签一个)的向量:
print(outputs.logits.shape)
torch.Size([2, 2])
由于我们只有两个句子和两个标签,因此我们从模型中得到的结果是 2 x 2 的形状。
后处理
我们从模型中获得的输出值本身不一定有意义,比如:
print(outputs.logits)
tensor([[-1.5607, 1.6123],
[ 4.1692, -3.3464]], grad_fn=<AddmmBackward>)
我们的模型预测了第一个句子结果 [-1.5607, 1.6123] 和第二个句子的结果 [4.1692, -3.3464]。但这些不是概率,而是 logits,即模型最后一层输出的原始非标准化分数。 要转换为概率,它们需要经过一个 SoftMax 层。所有 Transformers 模型都输出 logits,这是因为训练的损失函数一般会将最后一个激活函数(比如SoftMax)和实际的交叉熵损失函数相融合。文章Softmax回归中的数值稳定中有详细介绍。
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
tensor([[4.0195e-02, 9.5980e-01],
[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward>)
这次输出是可识别的概率分数。
要获得每个位置对应的标签,我们可以检查模型配置的 id2label 属性:
model.config.id2label
{0: 'NEGATIVE', 1: 'POSITIVE'}
现在我们可以得出结论,该模型预测了以下内容:
第一句:NEGATIVE:0.0402,POSITIVE:0.9598
第二句:NEGATIVE:0.9995,POSITIVE:0.0005
构建Trainer
Trainer可以让我们用自己的数据集微调预训练模型。
这里我们用官方提供的数据集来做。
下载datatset
MRPC 数据集是构成 GLUE 基准的 10 个数据集之一。而GLUE 基准是一种学术基准,用于衡量 ML 模型在 10 个不同文本分类任务中的性能。
Datasets库提供了一个非常简单的命令来下载和缓存Hub上的dataset。 我们可以像这样下载 MRPC 数据集:
from datasets import load_dataset
raw_datasets = load_dataset("glue", "mrpc")
raw_datasets
DatasetDict({
train: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 3668
})
validation: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 408
})
test: Dataset({
features: ['sentence1', 'sentence2', 'label', 'idx'],
num_rows: 1725
})
})
load_dataset 方法, 可以从不同的地方构建数据集
- 从 HuggingFace Hub
- 从本地文件, 如CSV/JSON/text/pandas
- 从内存数据,如python字典或pandas的dataframe
和字典一样,raw_datasets 可以通过索引访问其中的句子对:
raw_train_dataset = raw_datasets["train"]
raw_train_dataset[0]
{'idx': 0,
'label': 1,
'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .'}
import pandas as pd
validation=pd.DataFrame(raw_datasets['validation'])
validation

raw_train_dataset.features
{'sentence1': Value(dtype='string', id=None),
'sentence2': Value(dtype='string', id=None),
'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None),
'idx': Value(dtype='int32', id=None)}
label是 ClassLabel 类型,label=1表示这对句子互为paraphrases,label=0表示句子对意思不一致。
数据集预处理
通过tokenizer可以将文本转换为模型能理解的数字。
from transformers import AutoTokenizer
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
让我们看一个示例:
inputs = tokenizer("This is the first sentence.", "This is the second one.")
inputs
{ 'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
所以将句子对列表传给tokenizer,就可以对整个数据集进行分词处理。因此,预处理训练数据集的一种方法是:
tokenized_dataset = tokenizer(
raw_datasets["train"]["sentence1"],
raw_datasets["train"]["sentence2"],
padding=True,
truncation=True,
)
这种处理方法的缺点是处理之后tokenized_dataset不再是一个dataset格式,而是返回字典(带有我们的键:input_ids、attention_mask 和 token_type_ids,对应键值对的值)。
为了使我们的数据保持dataset的格式,我们将使用更灵活的Dataset.map 方法。此方法可以完成更多的预处理而不仅仅是分词。 map 方法是对数据集中的每个元素应用同一个函数,所以让我们定义一个函数来对输入进行tokenize预处理:
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
这个函数接受的是一个字典(就像我们dataset的items),返回的也是一个字典(有三个键:input_ids、attention_mask 和 token_type_ids )。
在tokenization函数中省略了padding 参数,这是因为padding到该批次中的最大长度时的效率,会高于所有序列都padding到整个数据集的最大序列长度。 当输入序列长度很不一致时,这可以节省大量时间和处理能力!
以下是对整个数据集应用tokenization方法。 我们在 map 调用中使用了 batched=True,因此该函数一次应用于数据集的整个batch元素,而不是分别应用于每个元素。 这样预处理速度会更快。
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets
Datasets库应用这种处理的方式是向数据集添加新字段,如下所示:
DatasetDict({
train: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 3668
})
validation: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 408
})
test: Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 1725
})
})
最后,当我们将输入序列进行批处理时,要将所有输入序列填充到本批次最长序列的长度——我们称之为动态填充技术dynamic padding。
动态填充:即将每个批次的输入序列填充到一样的长度。具体内容放在最后。
使用Trainer API进行微调
数据预处理完成后,只需要几个简单的步骤来定义Trainer的参数,就可以进行模型的基本训练循环了。
trainer主要参数包括:
- Model:用于训练、评估或用于预测的模型
- args (TrainingArguments):训练调整的参数。如果未提供,将默认为 TrainingArguments 的基本实例
- data_collator(DataCollator,可选)– 用于批处理train_dataset 或 eval_dataset 的的函数
- train_dataset:训练集
- eval_dataset:验证集
- compute_metrics:用于计算评估指标的函数。必须传入EvalPrediction 并将返回一个字典,键值对是metric和其value。
- callbacks (回调函数,可选):用于自定义训练循环的回调列表(List of TrainerCallback)
- optimizers:一个包含优化器和学习率调整器的元组,默认优化器是AdamW,默认的学习率是线性的学习率,从5e-5 到 0
最后我们用代码总结:
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc") #MRPC判断两个句子是否互为paraphrases
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)#动态填充,即将每个批次的输入序列填充到一样的长度
训练
Trainer第一个参数是TrainingArguments类,包含用于训练和评估的所有超参数。
from transformers import TrainingArguments
training_args = TrainingArguments("test-trainer")
接着,定义模型。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)#标签数为2也就是二分类
有了模型之后,就可以定义一个训练器Trainer了,将上面构建的所有对象传递给它进行模型微调:
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
像上面这样传递tokenizer时,参数data_collator 是之前定义的动态填充DataCollatorWithPadding,所以此调用中的 data_collator=data_collator行可以跳过。
要在我们的数据集上微调模型,我们只需要调用 Trainer 的 train方法:
trainer.train()
The following columns in the training set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence2, idx, sentence1. If sentence2, idx, sentence1 are not expected by `BertForSequenceClassification.forward`, you can safely ignore this message.
/usr/local/lib/python3.7/dist-packages/transformers/optimization.py:309: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
FutureWarning,
***** Running training *****
Num examples = 3668
Num Epochs = 3
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 1377
[1377/1377 03:14, Epoch 3/3]
Step Training Loss
500 0.528600
1000 0.312000
Saving model checkpoint to test-trainer/checkpoint-500
Configuration saved in test-trainer/checkpoint-500/config.json
Model weights saved in test-trainer/checkpoint-500/pytorch_model.bin
tokenizer config file saved in test-trainer/checkpoint-500/tokenizer_config.json
Special tokens file saved in test-trainer/checkpoint-500/special_tokens_map.json
Saving model checkpoint to test-trainer/checkpoint-1000
Configuration saved in test-trainer/checkpoint-1000/config.json
Model weights saved in test-trainer/checkpoint-1000/pytorch_model.bin
tokenizer config file saved in test-trainer/checkpoint-1000/tokenizer_config.json
Special tokens file saved in test-trainer/checkpoint-1000/special_tokens_map.json
Training completed. Do not forget to share your model on huggingface.co/models =)
TrainOutput(global_step=1377, training_loss=0.35565512995834186, metrics={'train_runtime': 194.8661, 'train_samples_per_second': 56.47, 'train_steps_per_second': 7.066, 'total_flos': 406183858377360.0, 'train_loss': 0.35565512995834186, 'epoch': 3.0})
在colab上用了4分钟不到。
我们可以先看看验证集预处理后的结构:
tokenized_datasets["validation"]
Dataset({
features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'],
num_rows: 408
})
我们可以使用 Trainer.predict 命令获得模型的预测结果:
predictions = trainer.predict(tokenized_datasets["validation"])
print(predictions.predictions.shape, predictions.label_ids.shape)
(408, 2) (408,)
predict 方法输出一个具有三个字段的元组。
- predictions: 预测值,形状为:[batch_size, num_labels], 是logits 而不是经过softmax之后的结果
- label_ids:真实的的label id
- metrics:评价指标,默认是training loss,以及一些time metrics (预测所需的总时间和平均时间)。但是一旦我们传入了 compute_metrics 函数给 Trainer,那么该函数的返回值也会一并输出。
metrics={'train_runtime': 194.8661, 'train_samples_per_second': 56.47, 'train_steps_per_second': 7.066, 'total_flos': 406183858377360.0, 'train_loss': 0.35565512995834186, 'epoch': 3.0})
predictions是一个二维数组,形状为 408 x 2(验证集408组数据,两个标签)。 要预测结果与标签进行比较,我们需要在predictions第二个轴上取最大值的索引:
import numpy as np
preds = np.argmax(predictions.predictions, axis=-1)
同时,从上面训练过程可以看到:模型每 500 步报告一次训练损失。 但是,它不会告诉你模型的表现如何。 这是因为:
- 没有设置evaluation_strategy 参数,告诉模型多少个“steps”(eval_steps)或“epoch”来评估一次损失。
- Trainer的compute_metrics 可以计算训练时具体的评估指标的值(比如acc、F1分数等等)。不设置compute_metrics 就只显示training loss,这不是一个直观的数字。
而如果我们将compute_metrics 函数写好并将其传递给Trainer后,metrics字段也将包含compute_metrics 返回的metrics值。
评估函数
现在看看如何构造compute_metrics 函数。这个函数:
- 必须传入 EvalPrediction 参数。 EvalPrediction是一个具有 predictions字段和 label_ids 字段的元组。
- 返回一个字典,键值对是key:metric 名字(string类型),value:metric 值(float类型)。
为了构建我们的 compute_metric 函数,我们将依赖 Datasets 库中的metric。 通过 load_metric 函数,我们可以像加载数据集一样轻松加载与 MRPC 数据集关联的metric。
from datasets import load_metric
metric = load_metric("glue", "mrpc")
metric.compute(predictions=preds, references=predictions.label_ids)
{'accuracy': 0.8627450980392157, 'f1': 0.9027777777777778}
每次训练时model head的随机初始化可能会改变最终的metric值,所以这里的最终结果可能和你跑出的不一样。 acc和F1 是用于评估 GLUE 基准的 MRPC 数据集结果的两个指标。
将以上内容整合到一起,得到 compute_metrics 函数:
def compute_metrics(eval_preds):
metric = load_metric("glue", "mrpc")
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
再设定每个epoch查看一次验证评估。所以下面就是我们设定compute_metrics参数之后的Trainer:
training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
请注意,我们创建了一个新的 TrainingArguments,其evaluation_strategy 设置为“epoch”和一个新模型——否则,我们只会继续训练我们已经训练过的模型。 要启动新的训练运行,我们执行:
trainer.train()
下面我们来看一个实例,微调Transformer来做机器翻译任务。
机器翻译任务
对于机器翻译任务,我们将看到如何加载数据集、使用Trainer对模型进行微调。
选择模型
选择一个预训练模型:
model_checkpoint = "Helsinki-NLP/opus-mt-en-ro"
加载数据
数据加载和评测方式加载只需要简单使用load_dataset和load_metric即可。我们使用WMT数据集中的English/Romanian双语翻译。
from datasets import load_dataset, load_metric
raw_datasets = load_dataset("wmt16", "ro-en")
metric = load_metric("sacrebleu") # 需要先执行 pip install sacrebleu
这个datasets对象本身是一种DatasetDict数据结构. 对于训练集、验证集和测试集,只需要使用对应的key(train,validation,test)即可得到相应的数据。
raw_datasets
DatasetDict({
train: Dataset({
features: ['translation'],
num_rows: 610320
})
validation: Dataset({
features: ['translation'],
num_rows: 1999
})
test: Dataset({
features: ['translation'],
num_rows: 1999
})
})
下面随机选择几个样本进行展示:
import datasets
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=5):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items():
if isinstance(typ, datasets.ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
display(HTML(df.to_html()))
show_random_elements(raw_datasets["train"])

我们使用compute方法来对比predictions和labels,从而计算得分。predictions和labels都需要是一个list:
fake_preds = ["hello there", "general kenobi"]
fake_labels = [["hello there"], ["general kenobi"]]
metric.compute(predictions=fake_preds, references=fake_labels)
{'bp': 1.0,
'counts': [4, 2, 0, 0],
'precisions': [100.0, 100.0, 0.0, 0.0],
'ref_len': 4,
'score': 0.0,
'sys_len': 4,
'totals': [4, 2, 0, 0]}
数据预处理
在将数据喂入模型之前,我们需要对数据进行预处理。预处理的工具叫Tokenizer。Tokenizer首先对输入进行tokenize,然后将tokens转化为预模型中需要对应的token ID,再转化为模型需要的输入格式。
为了达到数据预处理的目的,我们使用AutoTokenizer.from_pretrained方法实例化我们的tokenizer,这样可以确保:
- 我们得到一个与预训练模型一一对应的tokenizer。
- 使用指定的模型checkpoint对应的tokenizer的时候,我们也下载了模型需要的词表库vocabulary,准确来说是tokens vocabulary。
这个被下载的tokens vocabulary会被缓存起来,从而再次使用的时候不会重新下载。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
以我们使用的mBART模型为例,我们需要正确设置source语言和target语言:
if "mbart" in model_checkpoint:
tokenizer.src_lang = "en-XX"
tokenizer.tgt_lang = "ro-RO"
tokenizer既可以对单个文本进行预处理,也可以对一对文本进行预处理,tokenizer预处理后得到的数据满足预训练模型输入格式:
tokenizer("Hello, this one sentence!")
{'input_ids': [125, 778, 3, 63, 141, 9191, 23, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
上面看到的token IDs也就是input_ids一般来说随着预训练模型名字的不同而有所不同。原因是不同的预训练模型在预训练的时候设定了不同的规则。但只要tokenizer和model的名字一致,那么tokenizer预处理的输入格式就会满足model需求的。
注意:为了给模型准备好翻译的targets,我们使用as_target_tokenizer来控制targets所对应的特殊token:
with tokenizer.as_target_tokenizer():
print(tokenizer("Hello, this one sentence!"))
model_input = tokenizer("Hello, this one sentence!")
tokens = tokenizer.convert_ids_to_tokens(model_input['input_ids'])
# 打印看一下special token
print('tokens: {}'.format(tokens))
{'input_ids': [10334, 1204, 3, 15, 8915, 27, 452, 59, 29579, 581, 23, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
tokens: ['▁Hel', 'lo', ',', '▁', 'this', '▁o', 'ne', '▁se', 'nten', 'ce', '!', '']
为了代码的兼容性,如果使用的是T5预训练模型的checkpoints,需要对特殊的前缀进行检查。T5使用特殊的前缀来告诉模型具体要做的任务,具体前缀例子如下:
if model_checkpoint in ["t5-small", "t5-base", "t5-larg", "t5-3b", "t5-11b"]:
prefix = "translate English to Romanian: "
else:
prefix = ""
现在我们可以把所有内容放在一起组成我们的预处理函数了。我们对样本进行预处理的时候,我们还会truncation=True这个参数来确保我们超长的句子被截断。默认情况下,对与比较短的句子我们会自动padding。
max_input_length = 128
max_target_length = 128
source_lang = "en"
target_lang = "ro"
def preprocess_function(examples):
inputs = [prefix + ex[source_lang] for ex in examples["translation"]]
targets = [ex[target_lang] for ex in examples["translation"]]
model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(targets, max_length=max_target_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
以上的预处理函数可以处理一个样本,也可以处理多个样本exapmles。如果是处理多个样本,则返回的是多个样本被预处理之后的结果list。
preprocess_function(raw_datasets['train'][:2])
{'input_ids': [[393, 4462, 14, 1137, 53, 216, 28636, 0], [24385, 14, 28636, 14, 4646, 4622, 53, 216, 28636, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], 'labels': [[42140, 494, 1750, 53, 8, 59, 903, 3543, 9, 15202, 0], [36199, 6612, 9, 15202, 122, 568, 35788, 21549, 53, 8, 59, 903, 3543, 9, 15202, 0]]}
接下来对数据集datasets里面的所有样本进行预处理,处理的方式是使用map函数,将预处理函数prepare_train_features应用到(map)所有样本上。
tokenized_datasets = raw_datasets.map(preprocess_function, batched=True)
这会花一定的诗句。不过,返回的结果会自动被缓存,避免下次处理的时候重新计算。
如果想清理这个缓存。清理的方式是使用load_from_cache_file=False参数。
微调transformer模型
既然数据已经准备好了,现在我们需要下载并加载我们的预训练模型,然后微调预训练模型。既然我们是做seq2seq任务,那么我们需要一个能解决这个任务的模型类。我们使用AutoModelForSeq2SeqLM这个类。和tokenizer相似,from_pretrained方法同样可以帮助我们下载并加载模型,同时也会对模型进行缓存,就不会重复下载模型了。
from transformers import AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
由于我们微调的任务是机器翻译,而我们加载的是预训练的seq2seq模型,所以不会提示我们加载模型的时候扔掉了一些不匹配的神经网络参数(比如:预训练语言模型的神经网络head被扔掉了,同时随机初始化了机器翻译的神经网络head)。
为了能够得到一个Seq2SeqTrainer训练工具,我们还需要3个要素,其中最重要的是训练的设定/参数Seq2SeqTrainingArguments。这个训练设定包含了能够定义训练过程的所有属性:
batch_size = 16
args = Seq2SeqTrainingArguments(
"test-translation",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=1,
predict_with_generate=True,
fp16=False,
)
上面evaluation_strategy = "epoch"参数告诉训练代码:我们每个epcoh会做一次验证评估。
由于我们的数据集比较大,同时Seq2SeqTrainer会不断保存模型,所以我们需要告诉它至多保存save_total_limit=3个模型。
最后我们需要一个数据收集器data collator,将我们处理好的输入喂给模型。
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
设置好Seq2SeqTrainer还剩最后一件事情,那就是我们需要定义好评估方法。我们使用metric来完成评估。将模型预测送入评估之前,我们也会做一些数据后处理:
import numpy as np
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [[label.strip()] for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
result = {"bleu": result["score"]}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
result = {k: round(v, 4) for k, v in result.items()}
return result
最后将所有的参数/数据/模型传给Seq2SeqTrainer即可:
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
调用train方法进行微调训练。
trainer.train()
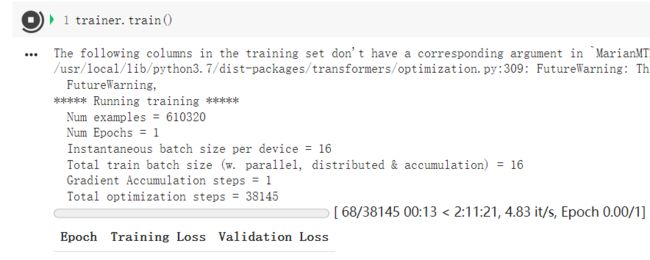
需要跑两个小时左右,这里就不看结果了。
参考
- 贪心学院课程