GRET: Global Representation Enhanced Transformer----AAAI 2020
整理一下阅读的关于transformer的应用相关的论文,这是第一篇。这篇论文直接利用了Transformer的结构并且做了相应的改进,主要创新点在于使用了胶囊神经网络以及引入了一些门控机制,解决的主要问题是Transformer只能表示词级别的信息表示(论文里面说的是局部表示),但是不管是翻译问题还是摘要问题等这些自然语言生成问题中生成的内容都是用句子来表示具体的含义,所以希望模型可以表示句子级别(文中说的全局信息)的表示。具体的内容看下面的内容。
本文论文链接:GRET: Global Representation Enhanced Transformer
胶囊网络是18年提出来的,最初也是用于图像处理领域的,它的工作原理我还尚不清楚,下面给出胶囊网络原文论文,感兴趣的可以先去了解一下。胶囊网络:Dynamic Routing Between Capsules
目录
Abstract
1 Introduction
2 Approach
2.1 建模全局表示
2.2 融入解码过程
2.3 训练
3 实验
3.1 实现细节
3.2 主要实验结果
3.3 消融实验
3.4 不同模型设置的有效性
3.5 胶囊网络分析
3.5 探测实验
4 相关工作
5 结论
摘要
Transformer是一种基于encoder-decoder的结构,它在很多自然语言生成任务上都取得了SOTA的效果。encoder将inputs句子中的单词映射到一个隐藏状态(hidden states)序列,这个隐藏状态序列然后被放进decoder用来生成输出句子。这些隐藏状态反应了输入单词并且专注于捕捉局部信息。然而,全局(句子级别)的信息几乎被忽略了,给提高生成质量提供了空间。(本文主要创新点就在于捕获句子的全局信息)。在本文中,我们提出了一个全新的全局表示增强Transformer(GRET),用Transformer网络构建一个具体的全局表示模型。具体地,在提出的模型中,从编码器生成用于全局表示的外部状态。全局表示然后被投入decoder中用于解码过程,来提高生成质量。本文在两个生成任务上进行了实验:机器翻译和文本摘要。实验结果在四个WMT机器翻译任务和LCSTS数据集上的文本摘要任务证明了本文提出的方法在自然语言生成上的有效性。
1 简介
Transformer在机器翻译,文本摘要等自然语言生成任务上其他方法更有效。通常来说Transformer是基于encoder-decoder结构,包含了两部分:一个encoder网络和一个decoder网络。encoder将输入序列编码成隐藏状态序列,每个隐藏状态对应了句子中一个特定的单词。decoder逐个单词的产生输出。在解码的每个时间步中,解码器进行注意力读取以获得输入隐藏状态并且决定应该生成哪个单词。
正如上面所提到的,解码过程中Transformer只依赖于隐藏状态的表示。然而,有研究表明Transformer的encoder的隐藏状态只获取了局部表示,仅仅关注于单词级别的信息。之前的一些工作(不详细列举了)显示了Transformer的encoder生成的隐藏状态更多的关注了单词到单词的映射关系,注意力机制的权重确定了哪个单词将会被产生,这类似于单词对齐。
正如Frazier指出的,全局信息,表示的是整个句子的信息而不是单独单词的信息,在生成一个句子的时候也应该作为一种重要因素被考虑进去。在自然语言生成任务上,这种全局表示扮演了重要的角色。基于RNN的模型在文本摘要任务上显示了引入全局信息的表示可以提高生成质量并且减少重复。之前也有一些相关工作表明了全局信息在目前的神经网络模型中的有效性。然而,相比于RNN和CNN来说,自注意力机制可以获得更长程的依赖,目前在Transformer中没有明确的机制显示出它可以整个句子的信息。因此,为Transformer提供这种全局表示是一个有吸引力的挑战。
在本文中,我们将这个挑战划分成了两个问题:1)如何对全局上下文信息进行编码;2)如何在生成的过程中使用全局信息。本文提出了GRET模型来解决这两个问题。对于第一个问题,我们建议在编码阶段通过两种互补方法基于局部单词级别表示生成全局表示。一方面来说,我们采用一个调整过的胶囊网络,基于从局部单词级别的表示中提取的特征来生成全局表示。局部表示通常和词到词的映射相关,这通常是多余或者有噪声的。直接用它们生成全局表示。而没有任何过滤是不可取的。胶囊网络,有很强的特征提取能力,可以从局部表示中提取更多合适的特征。相比于其他网络比如CNN来说,胶囊网络可以同时感知所有的局部信息,然后经过多次审议之后提取特征向量。
在另一方面,我们提出了一个layer-wise的循环结构进一步增强全局表示。之前的工作显示出每一层有不同方面的信息表示,比如,下层包含更多语法信息,而更高的层包含更多的语义信息。完整的全局上下文应具有信息的不同方面。 但是,由胶囊网络生成的全局表示仅获得层内信息。 所提出的逐层递归结构是通过汇总来自所有层的表示来组合层间信息的有用补充。 这两种方法可以通过充分利用本地表示中的不同粒度信息来对全局表示进行建模。
对于第二个问题,我们建议在每个步骤中使用上下文门控机制动态控制应将来自全局表示的多少信息融合到解码器中。 在生成过程中,每个解码器状态在输出字之前都应获取全局上下文信息。 他们对全局信息的需求在输出句子中的单词之间也有所不同。 所提出的门控机制可以通过为每个状态提供自定义表示,有效地利用全局表示来提高发电质量。
在四个WMT翻译任务和LCSTS文本摘要任务上的实验结果表明,我们的GRET模型在强大的基线和先前的一些研究中带来了显着的改进。
2 方法
我们的GRET模型包括两个步骤:在编码阶段对全局表示进行建模,并将其合并到解码过程中。 我们将在本节中基于 Transformer(Vaswani et al.2017)描述我们的方法。
2.1 建模全局表示
在编码阶段,我们提出了两种以不同粒度对全局表示进行建模的方法。 我们首先使用胶囊网络从局部词级表示中提取特征,并基于这些特征生成全局表示。 然后,随后采用分层递归结构,以通过汇总来自编码器所有层的表示来增强全局表示。 第一种方法侧重于利用词级信息来生成句子级表示,而第二种方法侧重于组合句子级信息的不同方面以获得更完整的全局表示。
层内表示生成 我们建议使用具有动态路由的胶囊从局部表示中提取特定和合适的特征,以进行更强大的全局表示建模,这是一种有效而强大的特征提取方法(Sabour,Frosst和Hinton,2017年; Zhang,Liu和Song,2018年。 ) 编码器隐藏状态的特征被概括为多个胶囊,并且通过动态路由算法迭代地更新隐藏状态和胶囊之间的权重(路径)。
正式地,给定具有M层和输入语句X(由I个单词组成)的Transformer的编码器。encoder第m层的隐藏状态序列H通过以下公式计算:
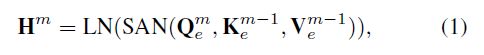
Q,K,V是查询,键,值向量和m-1层的隐藏状态一致。LN(·)表示层归一化函数,SAN(·)表示自注意力网络。这里省略了残差网络。
然后,通过Hm生成大小为K的胶囊Um。 具体而言,第k个胶囊umk的计算公式为:

其中q(·)是非线性壁球函数(咋翻译):
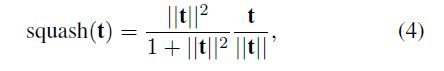
ck计算公式为:
![]()
其中矩阵B由零初始化,其行和列分别为K和I。 当所有胶囊被产生时,该矩阵将被更新。
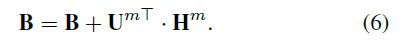
该算法在算法1中显示。胶囊Um的序列可用于生成全局表示。

与使用连接方法生成最终表示形式的原始胶囊网络不同,我们使用细心池化方法来生成全局表示形式2。 正式地,在第m层中,全局表示:
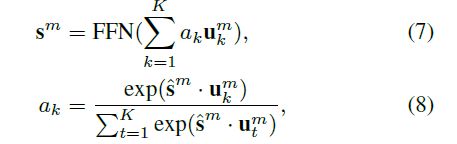
FFN(·)是一个前馈神经网络,sm计算公式如下:
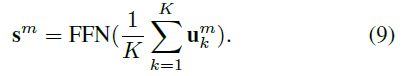
这种注意力的方法可以考虑胶囊网络的不同作用,并更好地对全局表示进行建模。 生成全局表示的过程概述如图1所示。

层间表示聚类 通常来说,Transformer模型仅仅把最后一层的隐藏状态向量Hm作为输入句子的表示放进decoder中去生成输出句子。根据这一点,我们可以将最后一层的全局表示Sm直接喂到decoder中去。然而,目前的全局表示仅仅包含了层内的信息,其他层的表示被忽略掉了,不同层表示的是不同方面的信息(之前的一些工作对此得到了证实)。基于这个前提条件,我们提出了一个逐层(layer-wise)的递归结构来整合解码器encoder中,所有不同层的胶囊网络产生的表示来完成全局表示的建模。
逐层递归结构通过门控递归单元聚合每个层的内部全局状态(Cho等人,2014,GRU),这可以实现与上一层的全局表示不同的信息方面。 正式地,我们通过以下方式调整sm的计算方法:
![]()
ATP(·)是注意力池化操作,计算公式如等式7-9所示。GRU单元可以通过忘记无用的信息并捕获合适的信息来控制信息流,从而可以有效地汇总前一层的表示形式。 逐层递归结构可以实现更精美和完整的表示。 此外,所提出的结构在编码阶段仅需要再多一步,这是不费时的。 聚合结构的概述如图2所示。

2.2 融入解码过程
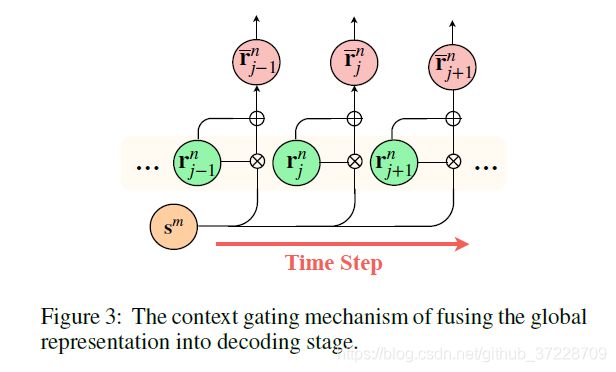
在生成输出字之前,每个解码器状态应考虑全局上下文信息。 我们将解码过程中的全局表示与对解码器最后一层的加法运算相结合,以指导状态输出真字。 但是,对每个目标词的全局信息的需求是不同的。 因此,我们提出了一种上下文门控机制,可以根据每个解码器的隐藏状态提供特定的信息。
具体地,给定具有N层的解码器和在训练阶段具有J个单词的目标句子y,从该解码器的第N层计算隐藏状态RN是通过以下公式计算得到:

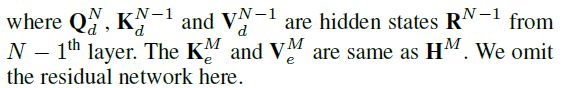
对每一个隐藏状态r(N,j)和R(N),上下文门控计算公式为:
![]()
包含了所需的全局信息的新状态的计算公式如下:

进一步,输出概率通过输出层的隐状态计算得到:
![]()
这种方法使每个状态都能获得其自定义的全局信息。 概述如图3所示。
2.3 训练
我们的GRET模型的训练过程与标准Transformer相同。 通过在给定输入语句x的情况下最大化输出语句y的似然度来优化网络,用Ltrans表示:
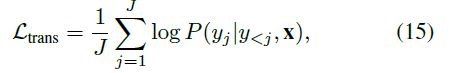
![]() 的定义是式(14)。
的定义是式(14)。
3 实验
3.1 实现细节
数据集 WMT的机器翻译数据集和LCSTS文本摘要数据集,具体细节看论文。
实验设置 机器翻译任务中,我们采取了字节对编码(BPE)对所有语言对进行编码,并且限制词汇表的大小为32k。在文本摘要任务中限制词汇表的大小为3500,并且是基于词级别的词汇表。离线此用UNK来表示了。
Transformer中的encoder和decoder的维度设置为512前馈网络设置为2048.我们采用了8个并行的注意力头。encoder和decoder的层数设置为6层。句子对按近似的句子长度分批处理。 每批有50个句子,一个句子的最大长度限制为100。我们将dropout的值设置为0.1。 我们使用Adam(Kingma and Ba 2014)来更新参数,在4000步的热启动策略下学习率有所不同(Vaswani et al.2017)。 其他细节在Vaswani等人中显示。 (2017)。 胶囊网络数设置为32,默认迭代时间设置为3。在DE→EN任务上,Transformer的训练时间约为6天。当使用基线参数作为初始化时,GRET模型的训练时间约为12小时。
在训练阶段之后,我们使用beam搜索进行启发式解码,并将beam大小设置为4。我们使用NIST-BLEU来测量翻译质量和ROUGE(Lin 2004)评测摘要质量。
3.2 主要实验结果
实验结果直接看表格比较清晰。


3.3 消融实验
本节介绍了论文的消融实验,特别的,我们研究了胶囊网络,整合结构以及门控机制的作用在全局表示上的表现。
实验结果在表3中表示出来了。
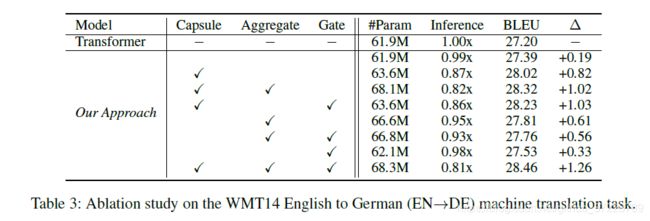
消融实验实验结论1:具体来说,如果没有胶囊网络,性能会降低0.7 BLEU,这意味着从局部表示中迭代提取特征可以减少冗余信息和噪音。
结论2:如果没有门控机制,性能将降低0.24 BLEU分数,这表明上下文门控机制对于控制每个解码步骤中使用全局表示的比例很重要。 尽管GRET模型将花费更多时间,但我们认为在大多数情况下通过降低效率来提高生成质量是值得的。
3.4 不同模型设置的有效性

3.5 胶囊网络分析

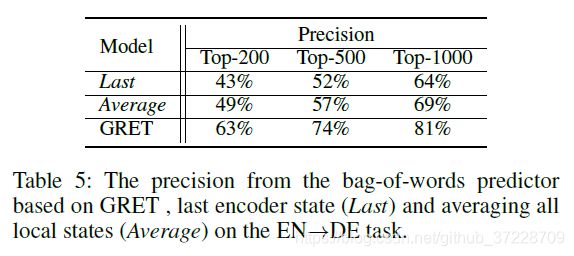
3.5 探测实验
4 相关工作
略
5 结论
在本文中,我们解决了Transformer无法建模全局上下文信息的问题,这会降低生成质量。 然后,我们提出了一种新颖的GRET模型,该模型可以通过包含全局信息的编码器生成外部状态,并将其动态融合到解码器中。 我们的方法解决了如何建模以及如何使用全局上下文信息这两个问题。我们将提出的GRET与最新的Transformer模型进行了比较。 在四个翻译任务和一个文本摘要任务上的实验结果证明了该方法的有效性。 将来我们会做更多的分析并将其与有关增强局部表示的方法相结合,以进一步提高生成性能。