【MobileNetV2硬件加速器工程】MobileNet V2量化方法的研究及使用Pytorch quantization包遇到的问题
关于工程信息
本工程的目的是在FPGA平台上实现MobileNetV2神经网络的加速器,使其能够对ImageNet数据集的处理进行加速。这也是我博士生涯中接下的第一个工程项目。在今后几个月的实现里,我将通过这个平台,完整地展现工程进行中遇到的各种问题、我们的解决方案、技术细节与心得体会,欢迎各位关注。
下图是MobileNet V2的两个主要结构:Inverse Residual Block与Bottleneck with Expansion Layer,放在这里美化一下这篇博客 (:

Pytorch Quantization所用的神经网络量化方法
实现这个设计,第一步考虑的问题就是,该怎样对这个模型进行量化?
所谓的量化(quantization),简而言之就是把一个训练好的网络所有的参数(weight, bias)与激励(activation)都转化为定点数表示。这样做一方面可以大大减少模型实现消耗的硬件资源与存储资源,这对FPGA尤其重要,另一方面一些关于量化的文献指出经过量化后的模型在推断精度方面损失不大,因而可以用较小的精度损失来节省大量的硬件资源消耗。
最原始的量化方法就是将一个训练好的浮点数模型作移位,把要量化的数向右移位n个bit以将浮点数全部转化为整形,由于weight与input feature map(ifmap)都进行移位了,它们相乘的结果相当于移位了2n,故在乘法计算完后,通常在ReLU层将结果(ofmap)向左移位n个bit,如此完成整个模型的量化。
但这样做的缺点是——在小模型如MobileNet上精度损失较大
故在pytorch的quantization类中,采用了一种新的量化方法,其思想参考Benoit Jacob的论文:Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference https://arxiv.org/pdf/1712.05877.pdf
知乎博主JermmyXu在他的博客《神经网络量化入门》里总结了该论文的主要思想,链接如下:神经网络量化入门--基本原理 - 知乎 (zhihu.com)
原本我想直接按照论文里给出的公式直接开始硬件设计,我们用Pytorch的quantization库实现了量化后的MobileNet V2模型,给这个模型输入一张图片,这张图片同样作为激励来对设计好的加速器进行仿真,没有想到的是,最后仿真得出来的结果和用pytorch量化模型得出来的结果不一样。
Pytorch量化模型输出的结果很好,分类很准确,那么出问题的地方就应该是我的硬件设计错误了,但经过反复检查,我并未在我的硬件设计上发现如何的错误,这让整个工程陷入到了一个尴尬的局面。为了解决这个问题,只能从底层出发,一点一点比照软件实现(Pytorch量化模型)与硬件时间(FPGA设计)的不同。为了尽可能地直观地观察Pytorch量化模型中各个tensor的计算过程,我们运用numpy复现了量化的过程。
探究quantization的量化过程
我的实验中所用的ILSVRC2012_val_00000293.jpg图片如下,直接下载并在程序中修改地址即可复现整个程序。

首先导入量化MobileNet V2模型,先对第一层,即3*3卷积层的输出结果进行分析。图像在输入神经网络之前进行了标准化。
import numpy as np
import torchvision
import torch
from torchvision import transforms, datasets
from PIL import Image
from torchvision import transforms
import torchextractor as tx
import math
#########################################################################################
##### Processing of input image
#########################################################################################
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,])
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
#image file destination
filename = "D:\Project_UM\MobileNet_VC709\MobileNet_pytorch\ILSVRC2012_val_00000293.jpg"
input_image = Image.open(filename)
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
#########################################################################################
#########################################################################################
#########################################################################################
#----First verify that the torchextractor class should not influent the inference outcome
# ofmp of layer1 before putting into torchextractor
a,b,c = quantize_tensor(input_batch)# to quantize the input tensor and return an int8 tensor, scale and zero point
input_qa = torch.quantize_per_tensor(torch.tensor(input_batch.clone().detach()), b, c, torch.quint8)# Using quantize_per_tensor method of torch
# Load a quantized mobilenet_v2 model
model_quantized = torchvision.models.quantization.mobilenet_v2(pretrained=True, quantize=True)
model_quantized.eval()
with torch.no_grad():
output = model_quantized.features[0][0](input_qa)# Ofmp of layer1, datatype : quantized_tensor
# print("FM of layer1 before tx_extractor:\n",output.int_repr())# Ofmp of layer1, datatype : int8 tensor
output1_clone = output.int_repr().detach().numpy()# Clone ofmp of layer1, datatype : ndarray
#########################################################################################
#########################################################################################
#########################################################################################
# ofmp of layer1 after adding torchextractor
model_quantized_ex = tx.Extractor(model_quantized, ["features.0.0"])#Capture of the module inside first layer
model_output, features = model_quantized_ex(input_batch)# Forward propagation
# feature_shapes = {name: f.shape for name, f in features.items()}
# print(features['features.0.0']) # Ofmp of layer1, datatype : quantized_tensor
out1_clone = features['features.0.0'].int_repr().numpy() # Clone ofmp of layer1, datatype : ndarray
if(out1_clone.all() == output1_clone.all()):
print('Model with torchextractor attached output the same value as the original model')
else:
print('Torchextractor method influence the outcome')上面这段程序调用了Pytorch quantization包对模型进行量化,并使用torchextractor包用于提取模型中每一层输出的feature map以便后续参与硬件设计的仿真。其运用了一个quantize_tensor的函数,将原本已经标准化与归一化的图片转化成了uint8的格式,其实现方式如下:
函数将一个普通tensor转化为一个量化tensor,并返回scale与zero_point的值。根据论文公式:

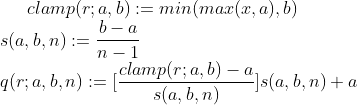
其中r为原浮点数,[a,b]为量化的范围,n为量化level,在8bit量化中,n取8;
# Convert a normal regular tensor to a quantized tensor with scale and zero_point
def quantize_tensor(x, num_bits=8):# to quantize the input tensor and return an int8 tensor, scale and zero point
qmin = 0.
qmax = 2.**num_bits - 1.
min_val, max_val = x.min(), x.max()
scale = (max_val - min_val) / (qmax - qmin)
initial_zero_point = qmin - min_val / scale
zero_point = 0
if initial_zero_point < qmin:
zero_point = qmin
elif initial_zero_point > qmax:
zero_point = qmax
else:
zero_point = initial_zero_point
# print(zero_point)
zero_point = int(zero_point)
q_x = zero_point + x / scale
q_x.clamp_(qmin, qmax).round_()
q_x = q_x.round().byte()
return q_x, scale, zero_point接下来对MobileNet V2第一层用Numpy实现,首先将参与运算的各个Tensor转化为Numpy表示。
#%%
# #############################################################################################
# --------- Simulate the inference process of layer0: conv33 using numpy
# #############################################################################################
# get the input_batch quantized buffer data
input_scale = b.item()
input_zero = c
input_quantized = a[0].detach().numpy()
# get the layer0 output scale and zero_point
output_scale = model_quantized.features[0][0].state_dict()['scale'].item()
output_zero = model_quantized.features[0][0].state_dict()['zero_point'].item()
# get the quantized weight with scale and zero_point
weight_scale = model_quantized.features[0][0].state_dict()["weight"].q_scale()
weight_zero = model_quantized.features[0][0].state_dict()["weight"].q_zero_point()
weight_quantized = model_quantized.features[0][0].state_dict()["weight"].int_repr().numpy()
# print(weight_quantized)
# print(weight_quantized.shape)
# bias_quantized,bias_scale,bias_zero= quantize_tensor(model_quantized.features[0][0].state_dict()["bias"])# to quantize the input tensor and return an int8 tensor, scale and zero point
# print(bias_quantized.shape)
bias = model_quantized.features[0][0].state_dict()["bias"].detach().numpy()
# print(input_quantized)
print(type(input_scale))
print(type(output_scale))
print(type(weight_scale))其次实现二维卷积操作
#%% numpy simulated layer0 convolution function define
def conv_cal(input_quantized, weight_quantized, kernel_size, stride, out_i, out_j, out_k):
weight = weight_quantized[out_i]
input = np.zeros((input_quantized.shape[0], kernel_size, kernel_size))
for i in range(weight.shape[0]):
for j in range(weight.shape[1]):
for k in range(weight.shape[2]):
input[i][j][k] = input_quantized[i][stride*out_j+j][stride*out_k+k]
# print(np.dot(weight,input))
# print(input,"\n")
# print(weight)
return np.multiply(weight,input).sum()
def QuantizedConv2D(input_scale, input_zero, input_quantized, output_scale, output_zero, weight_scale, weight_zero, weight_quantized, bias, kernel_size, stride, padding, ofm_size):
output = np.zeros((weight_quantized.shape[0],ofm_size,ofm_size))
input_quantized_padding = np.full((input_quantized.shape[0],input_quantized.shape[1]+2*padding,input_quantized.shape[2]+2*padding),0)
zero_temp = np.full(input_quantized.shape,input_zero)
input_quantized = input_quantized - zero_temp
for i in range(input_quantized.shape[0]):
for j in range(padding,padding + input_quantized.shape[1]):
for k in range(padding,padding + input_quantized.shape[2]):
input_quantized_padding[i][j][k] = input_quantized[i][j-padding][k-padding]
zero_temp = np.full(weight_quantized.shape, weight_zero)
weight_quantized = weight_quantized - zero_temp
for i in range(output.shape[0]):
for j in range(output.shape[1]):
for k in range(output.shape[2]):
output[i][j][k] = weight_scale*input_scale/output_scale*conv_cal(input_quantized_padding, weight_quantized, kernel_size, stride, i, j, k) + bias[i]/output_scale + output_zero
output[i][j][k] = round(output[i][j][k])
return output 最后,向Numpy模型中输入同样的weight、bias与ifmap,比较该模型与Pytorch版本的结果。
quantized_model_out1_int8 = np.squeeze(features['features.0.0'].int_repr().numpy())
print(quantized_model_out1_int8.shape)
print(quantized_model_out1_int8)
out1_np = QuantizedConv2D(input_scale, input_zero, input_quantized, output_scale, output_zero, weight_scale, weight_zero, weight_quantized, bias, 3, 2, 1, 112)
np.save("out1_np.npy",out1_np)
for i in range(quantized_model_out1_int8.shape[0]):
for j in range(quantized_model_out1_int8.shape[1]):
for k in range(quantized_model_out1_int8.shape[2]):
if(out1_np[i][j][k] < 0):
out1_np[i][j][k] = 0
print(out1_np)
flag = np.zeros(quantized_model_out1_int8.shape)
for i in range(quantized_model_out1_int8.shape[0]):
for j in range(quantized_model_out1_int8.shape[1]):
for k in range(quantized_model_out1_int8.shape[2]):
if(quantized_model_out1_int8[i][j][k] == out1_np[i][j][k]):
flag[i][j][k] = 1
out1_np[i][j][k] = 0
quantized_model_out1_int8[i][j][k] = 0
# Compare the simulated result to extractor fetched result, gain the total hit rate
print(flag.sum()/(112*112*32)*100,'%')Pytorch量化输出的ofmap中一个元素与Numpy量化输出的ofmap中对应的元素相等,则称为hit,统计总的hit率为:
![]()
可见有大概8%左右的数值在第一层的计算是错误的。比较这些错误的数值,发现大多数两者相差仅为1,但有少部分值相差较大,比如下图黑圈圈出来的部分(顺带说一句,用Spyder软件的Variable Explorer来看各个变量的值是真的方便!)。
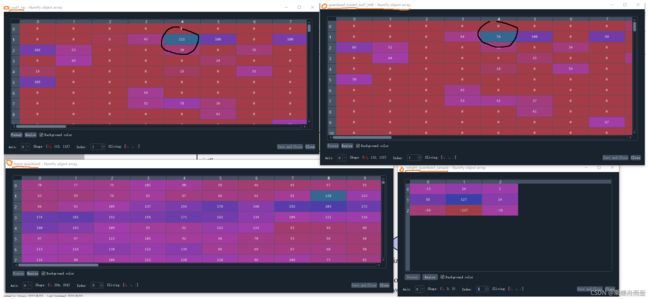
由于对numpy量化模型进行反复验证与测试后均未找到问题,不得不令人怀疑是不是Pytorch的quantization包有些地方搞错了(当然可能性比较小,毕竟是大名鼎鼎的Pytorch)。
唯一的方法,是将整个模型都用Numpy实现出来,然后查看用该numpy模型进行推断的结果,如果能用就用numpy的结果,不能用估计就真没辙了。 这个问题目前还没有发现比较好的解释,如能有高人指点,将感激不尽。
最后报告一下工程进度,目前工程神经网络部分硬件的设计与仿真均已完成,目前在整理前一阶段工作成果的同时,首先考虑为整个设计加入DRAM用于存储每一层的参数,之后将设计部署于正点原子领航者ZYNQ开发板上,并搭建视频流。下一篇博客将更新用Numpy实现整个量化MobileNet V2模型的过程,源码也将陆续更新至我的Github账号。