【NumPy】NumPy基本功能与常用方法总结
Numpy是一个开源的Python科学计算库,它是python科学计算库的基础库,许多其他著名的科学计算库如Pandas,Scikit-learn等都要用到Numpy库的一些功能。
ndarray对象
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
ndarray 对象是用于存放同类型元素的多维数组。
ndarray 中的每个元素在内存中都有相同存储大小的区域。
ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
- 数据类型或 dtype,描述在数组中的固定大小值的格子。
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。
ndarray 的内部结构:
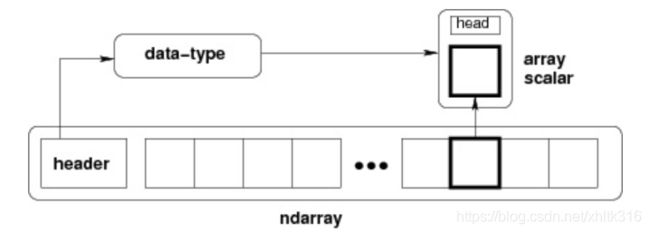
跨度可以是负数,这样会使数组在内存中后向移动,切片中 obj[::-1] 或 obj[:,::-1] 就是如此。
ndarray数组的创建
numpy.array
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
| 参数 | 描述 |
|---|---|
| object | 数组或嵌套的数列 |
| dtype | 数组元素的数据类型,可选 |
| copy | 对象是否需要复制,可选 |
| order | 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
| subok | 默认返回一个与基类类型一致的数组 |
| ndmin | 指定生成数组的最小维度 |
ndarray 数组除了可以使用底层 ndarray 构造器来创建外,也可以通过以下几种方式来创建。
numpy.empty
numpy.empty 方法用来创建一个指定形状(shape)、数据类型(dtype)且未初始化的数组:
numpy.empty(shape, dtype = float, order = 'C')
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | 有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。 |
注意 − 数组元素为随机值,因为它们未初始化。
numpy.zeros
创建指定大小的数组,数组元素以 0 来填充:
numpy.zeros(shape, dtype = float, order = 'C')
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | ‘C’ 用于 C 的行数组,或者 ‘F’ 用于 FORTRAN 的列数组 |
numpy.ones
创建指定形状的数组,数组元素以 1 来填充:
numpy.ones(shape, dtype = None, order = 'C')
| 参数 | 描述 |
|---|---|
| shape | 数组形状 |
| dtype | 数据类型,可选 |
| order | ‘C’ 用于 C 的行数组,或者 ‘F’ 用于 FORTRAN 的列数组 |
numpy.asarray
numpy.asarray 类似 numpy.array,但 numpy.asarray 参数只有三个,比 numpy.array 少两个。
numpy.asarray(a, dtype = None, order = None)
| 参数 | 描述 |
|---|---|
| a | 任意形式的输入参数,可以是,列表, 列表的元组, 元组, 元组的元组, 元组的列表,多维数组 |
| dtype | 数据类型,可选 |
| order | 可选,有"C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。 |
numpy.frombuffer
numpy.frombuffer 用于实现动态数组。
numpy.frombuffer 接受 buffer 输入参数,以流的形式读入转化成 ndarray 对象。
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)
| 参数 | 描述 |
|---|---|
| buffer | 可以是任意对象,会以流的形式读入。 |
| dtype | 返回数组的数据类型,可选 |
| count | 读取的数据数量,默认为-1,读取所有数据。 |
| offset | 读取的起始位置,默认为0。 |
numpy.fromiter
numpy.fromiter 方法从可迭代对象中建立 ndarray 对象,返回一维数组。
numpy.fromiter(iterable, dtype, count=-1)
| 参数 | 描述 |
|---|---|
| iterable | 可迭代对象 |
| dtype | 返回数组的数据类型 |
| count | 读取的数据数量,默认为-1,读取所有数据 |
numpy.arange
numpy 包中的使用 arange 函数创建数值范围并返回 ndarray 对象,函数格式如下:
numpy.arange(start, stop, step, dtype)
根据 start 与 stop 指定的范围以及 step 设定的步长,生成一个 ndarray。
| 参数 | 描述 |
|---|---|
| start | 起始值,默认为0 |
| stop | 终止值(不包含) |
| step | 步长,默认为1 |
| dtype | 返回ndarray的数据类型,如果没有提供,则会使用输入数据的类型。 |
numpy.linspace
numpy.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的,格式如下:
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
| 参数 | 描述 |
|---|---|
| start | 序列的起始值 |
| stop | 序列的终止值,如果endpoint为true,该值包含于数列中 |
| num | 要生成的等步长的样本数量,默认为50 |
| endpoint | 该值为 true 时,数列中包含stop值,反之不包含,默认是True。 |
| retstep | 如果为 True 时,生成的数组中会显示间距,反之不显示。 |
| dtype | ndarray 的数据类型 |
numpy.logspace
numpy.logspace 函数用于创建一个于等比数列。格式如下:
np.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)
base 参数意思是取对数的时候 log 的下标。
| 参数 | 描述 |
|---|---|
| start | 序列的起始值为:base ** start |
| stop | 序列的终止值为:base ** stop。如果endpoint为true,该值包含于数列中 |
| num | 要生成的等步长的样本数量,默认为50 |
| endpoint | 该值为 true 时,数列中中包含stop值,反之不包含,默认是True。 |
| base | 对数 log 的底数。 |
| dtype | ndarray 的数据类型 |
numpy.reshape
numpy.reshape 函数可以在不改变数据的条件下修改形状,也可以用于创建新的数组
numpy.reshape(arr, newshape, order='C')
ndarray数组的属性
NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推。
在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)。比如说,二维数组相当于是两个一维数组,其中第一个一维数组中每个元素又是一个一维数组。所以一维数组就是 NumPy 中的轴(axis),第一个轴相当于是底层数组,第二个轴是底层数组里的数组。而轴的数量——秩,就是数组的维数。
很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作。
NumPy 的数组中比较重要 ndarray 对象属性有:
| 属性 | 说明 |
|---|---|
| ndarray.ndim | 秩,即轴的数量或维度的数量 |
| ndarray.shape | 数组的维度,对于矩阵,n 行 m 列 |
| ndarray.size | 数组元素的总个数,相当于 .shape 中 n*m 的值 |
| ndarray.dtype | ndarray 对象的元素类型 |
| ndarray.itemsize | ndarray 对象中每个元素的大小,以字节为单位 |
| ndarray.flags | ndarray 对象的内存信息 |
| ndarray.real | ndarray元素的实部 |
| ndarray.imag | ndarray 元素的虚部 |
| ndarray.data | 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性 |
| ndarray.nbytes | 整个数组所需的字节数量,其值等于数组的size属性值乘以itemsize属性值 |
| ndarray.flat | 返回一个numpy.flatiter对象,即可迭代的对象。可用来索引或赋值 |
| ndarray.T | 数组转置 |
ndarray数组的切片和索引
基本索引
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。
ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新数组,也可以通过冒号分隔切片参数 start:stop:step 来进行切片操作。
NumPy 比一般的 Python 序列提供更多的索引方式。除了之前看到的用整数和切片的索引外,数组可以由整数数组索引、布尔索引及花式索引。
高级索引
整数数组索引
要获取二维数组中(x1, y1)和(x2, y2)的值可以写成:
y = x[ [x1, x2], [y1, y2] ]
布尔索引
通过一个布尔数组来索引目标数组。
布尔索引通过布尔运算(如:比较运算符)来获取符合指定条件的元素的数组。
花式索引
花式索引指的是利用整数数组进行索引。
花式索引根据索引数组的值作为目标数组的某个轴的下标来取值。对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应下标的行,如果目标是二维数组,那么就是对应位置的元素。
花式索引跟切片不一样,它总是将数据复制到新数组中。
可以传入顺序、逆序或多个(要使用np.ix_)索引数组。
ndarray数组的形状转换
reshape()和resize()
函数resize()的作用跟reshape()类似,但是会改变所作用的数组,相当于有inplace=True的效果。
ravel()和flatten()
两者的区别在于返回拷贝(copy)还是返回视图(view),flatten()返回一份拷贝,需要分配新的内存空间,对拷贝所做的修改不会影响原始矩阵,而ravel()返回的是视图(view),会影响原始矩阵。
transpose()
二维数组中:
ndarray.transpose((0,1))或无参数,01轴变换,无变化。
ndarray.transpose((1,0)),10轴变换,数组转置,效果同上述ndarray.T。
高维数组同理。
ndarray数组的堆叠
水平叠加
np.column_stack()函数以列方式对数组进行叠加,功能类似np.hstack()
垂直叠加
np.row_stack()函数以行方式对数组进行叠加,功能类似np.vstack()
任意叠加
np.concatenate()方法,通过设置axis的值来设置叠加方向
axis=1时,沿水平方向叠加
axis=0时,沿垂直方向叠加
深度叠加
np.dstack()
ndarray数组的拆分
水平拆分
np.hsplit()
垂直拆分
np.vsplit()
任意拆分
np.split()方法,通过设置axis的值来设置拆分方向
axis=1时,沿水平方向拆分
axis=0时,沿垂直方向拆分
深度拆分
np.dsplit()
ndarray数组的类型转换
tolist()
数组转换成list
astype()
转换成指定类型
ndarray数组的拷贝
视图或浅拷贝
ndarray.view() 方会创建一个新的数组对象,该方法创建的新数组的维数变化不会改变原始数据的维数。而使用切片创建视图修改数据会影响到原始数组。
副本或深拷贝
ndarray.copy() 函数创建一个副本。 对副本数据进行修改,不会影响到原始数据,它们物理内存不在同一位置。
ndarray数组的排序、条件刷选函数
NumPy 提供了多种排序的方法。 这些排序函数实现不同的排序算法,每个排序算法的特征在于执行速度,最坏情况性能,所需的工作空间和算法的稳定性。 下表显示了三种排序算法的比较。
| 种类 | 速度 | 最坏情况 | 工作空间 | 稳定性 |
|---|---|---|---|---|
| ‘quicksort’(快速排序) | 1 | O(n^2) | 0 | 否 |
| ‘mergesort’(归并排序) | 2 | O(n*log(n)) | ~n/2 | 是 |
| ‘heapsort’(堆排序) | 3 | O(n*log(n)) | 0 | 否 |
numpy.sort()
numpy.sort() 函数返回输入数组的排序副本。函数格式如下:
numpy.sort(a, axis, kind, order)
参数说明:
- a: 要排序的数组
- axis: 沿着它排序数组的轴,如果没有数组会被展开,沿着最后的轴排序, axis=0 按列排序,axis=1 按行排序
- kind: 默认为’quicksort’(快速排序)
- order: 如果数组包含字段,则是要排序的字段
numpy.argsort()
numpy.argsort() 函数返回的是数组值从小到大的索引值。
numpy.lexsort()
numpy.lexsort() 用于对多个序列进行排序。把它想象成对电子表格进行排序,每一列代表一个序列,排序时优先照顾靠后的列。
msort、sort_complex、partition、argpartition
| 函数 | 描述 |
|---|---|
| msort(a) | 数组按第一个轴排序,返回排序后的数组副本。np.msort(a) 相等于 np.sort(a, axis=0)。 |
| sort_complex(a) | 对复数按照先实部后虚部的顺序进行排序。 |
| partition(a, kth[, axis, kind, order]) | 指定一个数,对数组进行分区 |
| argpartition(a, kth[, axis, kind, order]) | 可以通过关键字 kind 指定算法沿着指定轴对数组进行分区 |
numpy.argmax() 和 numpy.argmin()
numpy.argmax() 和 numpy.argmin()函数分别沿给定轴返回最大和最小元素的索引。
numpy.nonzero()
numpy.nonzero() 函数返回输入数组中非零元素的索引。
numpy.where()
numpy.where() 函数返回输入数组中满足给定条件的元素的索引。
numpy.extract()
numpy.extract() 函数根据某个条件从数组中抽取元素,返回满条件的元素。
ndarray数组的常用统计函数
注意函数在使用时需要指定axis轴的方向,若不指定,默认统计整个数组。
- np.sum(),返回求和
- np.mean(),返回均值
- np.max(),返回最大值
- np.min(),返回最小值
- np.ptp(),数组沿指定轴返回最大值减去最小值,即(max-min)
- np.std(),返回标准偏差(standard deviation)
- np.var(),返回方差(variance)
- np.cumsum(),返回累加值
- np.cumprod(),返回累乘积值