NER项目--github--A Unified MRC Framework for Named Entity Recognition
A Unified MRC Framework for Named Entity Recognition项目代码
- 简述
- 项目结构
- models
-
- model_config.py
- classifier.py
- bert_tagger.py
- bert_query_ner.py
- train
-
- mrc_ner_trainer.py
- ner2mrc
-
- msra2mrc.py
- datasets
-
- mrc_ner_dataset.py
- evaluate
-
- mrc_ner_evaluate.py
- inference
-
- mrc_ner_inference.py
- 总结
- 后记
项目链接:https://github.com/ShannonAI/mrc-for-flat-nested-ner
论文链接:https://arxiv.org/abs/1910.11476
简述
论文将命名实体识别任务转换为机器阅读理解任务/MRC,即通过问一个问题去提取文本序列中对应的实体;一般是对具体的类别提问,如要提取org类别的实体,query就可以为“文本序列中哪些是组织?”。其使用BERT作为backbone,将文本与问句作为序列对送入BERT,使用两个二分类器对BERT最后的数据进行分类,一个分类器判断每个token是实体开始索引的可能性,另一个分类器判断每个token作为实体结束索引的可能性。

项目结构
- datasets --构建数据集的文件
- evaluate --用于评估的文件
- inference --用于前向推理的文件
- metrics --实现metric的文件
- models --构建模型的文件
- ner2mrc --将数据转换为mrc所需格式的文件
- scripts --在各个数据集上训练的启动文件
- tests --测试所需的文件
- train --模型训练的文件
- utils --其他的辅助文件
- README.md --项目详情
- requirements.txt --项目所需的python包
下文是对官方代码进行适当的修改和详细的注释,通过阅读下面的代码以及注释能对该项目有一个清晰的认识,不过需要较多的时间反复揣摩;有效的方法是将官方代码库下载,运行整个pipeline中的主题文件,弄清楚各个模块输入、输出的转换过程
models
先针对models路径下的文件解析,了解模型搭建的整个过程
model_config.py
文件中对使用MRC框架的实体抽取任务和Tag方式的实体抽取任务分别定义了所需的config类
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# file: model_config.py
from transformers import BertConfig
class BertQueryNerConfig(BertConfig): # 使用MRC框架的实体抽取所需的config
def __init__(self, **kwargs):
super(BertQueryNerConfig, self).__init__(**kwargs)
self.mrc_dropout = kwargs.get("mrc_dropout", 0.1)
self.classifier_intermediate_hidden_size = kwargs.get("classifier_intermediate_hidden_size", 1024)
self.classifier_act_func = kwargs.get("classifier_act_func", "gelu")
class BertTaggerConfig(BertConfig): # 使用tag方式的实体抽取所需的config
def __init__(self, **kwargs):
super(BertTaggerConfig, self).__init__(**kwargs)
self.num_labels = kwargs.get("num_labels", 6)
self.classifier_dropout = kwargs.get("classifier_dropout", 0.1)
self.classifier_sign = kwargs.get("classifier_sign", "multi_nonlinear")
self.classifier_act_func = kwargs.get("classifier_act_func", "gelu")
self.classifier_intermediate_hidden_size = kwargs.get("classifier_intermediate_hidden_size", 1024)
classifier.py
为两种实体抽取方式分别定义分类头
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# file: classifier.py
import torch.nn as nn
from torch.nn import functional as F
class SingleLinearClassifier(nn.Module): # 通过一个全连接层直接进行类别预测
def __init__(self, hidden_size, num_label):
super(SingleLinearClassifier, self).__init__()
self.num_label = num_label
self.classifier = nn.Linear(hidden_size, num_label)
def forward(self, input_features):
features_output = self.classifier(input_features)
return features_output
class MultiNonLinearClassifier(nn.Module): # MRC框架使用的分类头,使用了两个全连接层对bert输出的特征进行处理
def __init__(self, hidden_size, num_label, dropout_rate, act_func="gelu", intermediate_hidden_size=None):
super(MultiNonLinearClassifier, self).__init__()
self.num_label = num_label
self.intermediate_hidden_size = hidden_size if intermediate_hidden_size is None else intermediate_hidden_size
self.classifier1 = nn.Linear(hidden_size, self.intermediate_hidden_size)
self.classifier2 = nn.Linear(self.intermediate_hidden_size, self.num_label)
self.dropout = nn.Dropout(dropout_rate)
self.act_func = act_func
def forward(self, input_features):
features_output1 = self.classifier1(input_features)
if self.act_func == "gelu":
features_output1 = F.gelu(features_output1)
elif self.act_func == "relu":
features_output1 = F.relu(features_output1)
elif self.act_func == "tanh":
features_output1 = F.tanh(features_output1)
else:
raise ValueError
features_output1 = self.dropout(features_output1)
features_output2 = self.classifier2(features_output1)
return features_output2
class BERTTaggerClassifier(nn.Module): # tag方式的分类头
def __init__(self, hidden_size, num_label, dropout_rate, act_func="gelu", intermediate_hidden_size=None):
super(BERTTaggerClassifier, self).__init__()
self.num_label = num_label
self.intermediate_hidden_size = hidden_size if intermediate_hidden_size is None else intermediate_hidden_size
self.classifier1 = nn.Linear(hidden_size, self.intermediate_hidden_size)
self.classifier2 = nn.Linear(self.intermediate_hidden_size, self.num_label)
self.dropout = nn.Dropout(dropout_rate)
self.act_func = act_func
def forward(self, input_features):
features_output1 = self.classifier1(input_features)
if self.act_func == "gelu":
features_output1 = F.gelu(features_output1)
elif self.act_func == "relu":
features_output1 = F.relu(features_output1)
elif self.act_func == "tanh":
features_output1 = F.tanh(features_output1)
else:
raise ValueError
features_output1 = self.dropout(features_output1)
features_output2 = self.classifier2(features_output1)
return features_output2
bert_tagger.py
使用bert进行tag方式的实体抽取
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# file: bert_tagger.py
#
import torch.nn as nn
from transformers import BertModel, BertPreTrainedModel
from models.classifier import BERTTaggerClassifier
# 直接把bert最后一层输出的隐含状态直接连接一个分类器进行状态分类
class BertTagger(BertPreTrainedModel):
def __init__(self, config):
super(BertTagger, self).__init__(config)
self.bert = BertModel(config) # 基于config初始化bert模型
self.num_labels = config.num_labels
self.hidden_size = config.hidden_size
self.dropout = nn.Dropout(config.hidden_dropout_prob)
if config.classifier_sign == "multi_nonlinear": # 调用tag方式的分类头
self.classifier = BERTTaggerClassifier(self.hidden_size, self.num_labels,
config.classifier_dropout,
act_func=config.classifier_act_func,
intermediate_hidden_size=config.classifier_intermediate_hidden_size)
else:
self.classifier = nn.Linear(self.hidden_size, self.num_labels)
self.init_weights()
def forward(self, input_ids, token_type_ids=None, attention_mask=None,):
last_bert_layer, pooled_output = self.bert(input_ids, token_type_ids, attention_mask)
last_bert_layer = last_bert_layer.view(-1, self.hidden_size)
last_bert_layer = self.dropout(last_bert_layer)
logits = self.classifier(last_bert_layer)
return logits
bert_query_ner.py
如论文中一样,分别对文本序列中每个token进行实体开始索引预测和结束索引预测,再计算开始索引与结束索引的匹配预测结果进行返回
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# file: bert_query_ner.py
import torch
import torch.nn as nn
from transformers import BertModel, BertPreTrainedModel
from models.classifier import MultiNonLinearClassifier
class BertQueryNER(BertPreTrainedModel):
def __init__(self, config):
super(BertQueryNER, self).__init__(config)
self.bert = BertModel(config) # 初始化bert
self.start_outputs = nn.Linear(config.hidden_size, 1) # 用于计算实体开始索引
self.end_outputs = nn.Linear(config.hidden_size, 1) # 用于计算实体结束索引
# 判断i、j是否为一个匹配
self.span_embedding = MultiNonLinearClassifier(config.hidden_size * 2, 1, config.mrc_dropout,
intermediate_hidden_size=config.classifier_intermediate_hidden_size)
self.hidden_size = config.hidden_size
self.init_weights()
def forward(self, input_ids, token_type_ids=None, attention_mask=None):
"""
Args:
input_ids: bert input tokens, tensor of shape [seq_len]
token_type_ids: 0 for query, 1 for context, tensor of shape [seq_len],query在前,文本在后
attention_mask: attention mask, tensor of shape [seq_len]
Returns:
start_logits: start/non-start probs of shape [seq_len]
end_logits: end/non-end probs of shape [seq_len]
match_logits: start-end-match probs of shape [seq_len, 1],此处的1表示匹配行的得分
"""
bert_outputs = self.bert(input_ids, token_type_ids=token_type_ids, attention_mask=attention_mask)
sequence_heatmap = bert_outputs[0] # [batch, seq_len, hidden]
batch_size, seq_len, hid_size = sequence_heatmap.size()
start_logits = self.start_outputs(sequence_heatmap).squeeze(-1) # [batch, seq_len, 1],开始索引预测
end_logits = self.end_outputs(sequence_heatmap).squeeze(-1) # [batch, seq_len, 1],结束索引预测
# for every position $i$ in sequence, should concate $j$ to
# predict if $i$ and $j$ are start_pos and end_pos for an entity.
# [batch, seq_len, hidden]->[batch, seq_len, 1, hidden]->[batch, seq_len, seq_len, hidden]
start_extend = sequence_heatmap.unsqueeze(2).expand(-1, -1, seq_len, -1)
# [batch, seq_len, hidden]->[batch, 1, seq_len, hidden]->[batch, seq_len, seq_len, hidden]
end_extend = sequence_heatmap.unsqueeze(1).expand(-1, seq_len, -1, -1)
# [batch, seq_len, seq_len, hidden]+[batch, seq_len, seq_len, hidden]->[batch, seq_len, seq_len, hidden*2]
span_matrix = torch.cat([start_extend, end_extend], 3)
# [batch, seq_len, seq_len, hidden*2]->[batch, seq_len, seq_len, 1]->[batch, seq_len, seq_len]
span_logits = self.span_embedding(span_matrix).squeeze(-1) # 开始索引和结束索引匹配情况的预测
return start_logits, end_logits, span_logits
train
mrc_ner_trainer.py
该项目主要使用Pytoch Lightning框架实现训练、测试等过程,使用Pytorch Lightning只用定义主要的训练/training_step()、验证/validation_step()和测试/test_step()函数,而不用写复杂的for循环,框架会自动进行训练。代码如下,该代码是在官方代码的基础上进行调整,增加了使用WandbLogger进行数据记录,可配合笔记进行阅读
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# file: mrc_ner_trainer.py
import os
import re
import argparse
import logging
from collections import namedtuple
from typing import Dict
import torch
import pytorch_lightning as pl
from pytorch_lightning import Trainer
from pytorch_lightning.callbacks.model_checkpoint import ModelCheckpoint
from tokenizers import BertWordPieceTokenizer
from torch import Tensor
from torch.nn.modules import CrossEntropyLoss, BCEWithLogitsLoss
from torch.utils.data import DataLoader
from transformers import AdamW, get_linear_schedule_with_warmup, get_polynomial_decay_schedule_with_warmup
from torch.optim import SGD
from pytorch_lightning.loggers import WandbLogger
from datasets.mrc_ner_dataset import MRCNERDataset
from datasets.truncate_dataset import TruncateDataset
from datasets.collate_functions import collate_to_max_length
from metrics.query_span_f1 import QuerySpanF1
from models.bert_query_ner import BertQueryNER
from models.model_config import BertQueryNerConfig
from utils.get_parser import get_parser
from utils.random_seed import set_random_seed
set_random_seed(0) # 设置随机数种子,固定随机数,保证模型的复现性
os.environ["TOKENIZERS_PARALLELISM"] = "false"
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 使用GPU_0
class BertLabeling(pl.LightningModule): # 使用pytorch lightning定义网络结构时,要继承其的LightningModule类,类似于nn.Module类
def __init__(self, args: argparse.Namespace):
"""Initialize a model, tokenizer and config."""
super().__init__()
format = '%(asctime)s - %(name)s - %(message)s'
if isinstance(args, argparse.Namespace): # argparse.Namespace是parse_args(
# )默认使用的简单类,用于创建一个包含属性的对象,并返回这个对象;此处表示训练模式
self.save_hyperparameters(args) # 将args中的参数保存在检查点,可通过self.hparams进行访问
self.args = args
logging.basicConfig(format=format, filename=os.path.join(self.args.default_root_dir, "eval_result_log.txt"),
level=logging.INFO) # 创建日志记录文件,设置日志等级和格式
else:
# eval mode
TmpArgs = namedtuple("tmp_args", field_names=list(args.keys()))
self.args = args = TmpArgs(**args)
logging.basicConfig(format=format, filename=os.path.join(self.args.default_root_dir, "eval_test.txt"),
level=logging.INFO)
self.bert_dir = args.bert_config_dir # bert预训练模型路径
self.data_dir = self.args.data_dir # 数据所在路径
# 构建bert的config
bert_config = BertQueryNerConfig.from_pretrained(args.bert_config_dir,
hidden_dropout_prob=args.bert_dropout,
attention_probs_dropout_prob=args.bert_dropout,
mrc_dropout=args.mrc_dropout,
classifier_act_func=args.classifier_act_func,
classifier_intermediate_hidden_size=args.classifier_intermediate_hidden_size)
# 初始化BertQueryNER模型
self.model = BertQueryNER.from_pretrained(args.bert_config_dir, config=bert_config)
logging.info(str(args.__dict__ if isinstance(args, argparse.ArgumentParser) else args)) # 日志中记录args/训练参数
self.result_logger = logging.getLogger(__name__)
self.result_logger.setLevel(logging.INFO)
self.result_logger.info(str(args.__dict__ if isinstance(args, argparse.ArgumentParser) else args))
self.bce_loss = BCEWithLogitsLoss(reduction="none") # 损失函数
# 设置三个损失的权重
weight_sum = args.weight_start + args.weight_end + args.weight_span
self.weight_start = args.weight_start / weight_sum
self.weight_end = args.weight_end / weight_sum
self.weight_span = args.weight_span / weight_sum
self.flat_ner = args.flat # /数据集是否包含嵌套实体
self.span_f1 = QuerySpanF1(flat=self.flat_ner) # 自定义计算SpanF1的nn.module
self.chinese = args.chinese # 是否为中文
self.optimizer = args.optimizer # 优化器
self.span_loss_candidates = args.span_loss_candidates
@staticmethod
def add_model_specific_args(parent_parser): # 补充模型训练所需的其他的超参数
parser = argparse.ArgumentParser(parents=[parent_parser], add_help=False)
parser.add_argument("--mrc_dropout", type=float, default=0.3,
help="mrc dropout rate")
parser.add_argument("--bert_dropout", type=float, default=0.1,
help="bert dropout rate")
parser.add_argument("--classifier_act_func", type=str, default="gelu") # 分类头的激活函数
parser.add_argument("--classifier_intermediate_hidden_size", type=int, default=1024) # 分类头中的中间隐变量大小
parser.add_argument("--weight_start", type=float, default=1.0) # 开始索引损失的权重
parser.add_argument("--weight_end", type=float, default=1.0) # 结束索引损失的权重
parser.add_argument("--weight_span", type=float, default=0.1) # 开始索引和结束索引匹配损失的权重
parser.add_argument("--flat", action="store_true", help="is flat ner") # 数据集是否是flat
parser.add_argument("--span_loss_candidates", choices=["all", "pred_and_gold", "pred_gold_random", "gold"],
default="pred_and_gold", help="Candidates used to compute span loss") # span_loss
parser.add_argument("--chinese", action="store_true",
help="is chinese dataset") # 数据集是否是中文
parser.add_argument("--optimizer", choices=["adamw", "sgd", "torch.adam"], default="adamw",
help="loss type") # 可选优化器
parser.add_argument("--final_div_factor", type=float, default=20,
help="final div factor of linear decay scheduler") # 线性衰减策略的最终div因子
parser.add_argument("--lr_scheduler", type=str, default="onecycle", ) # 学习率策略
parser.add_argument("--lr_mini", type=float, default=-1) # 最小的学习率值
return parser
def configure_optimizers(self):
"""Prepare optimizer and schedule (linear warmup and decay),准备优化器的优化策略"""
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [ # 在no_dacay列表中的数据类型不会衰减
{
"params": [p for n, p in self.model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": self.args.weight_decay,
},
{
"params": [p for n, p in self.model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
}, ]
# 设置优化器
if self.optimizer == "adamw":
optimizer = AdamW(optimizer_grouped_parameters,
betas=(0.9, 0.98), # according to RoBERTa paper
lr=self.args.lr,
eps=self.args.adam_epsilon, )
elif self.optimizer == "torch.adam":
optimizer = torch.optim.AdamW(optimizer_grouped_parameters,
lr=self.args.lr,
eps=self.args.adam_epsilon,
weight_decay=self.args.weight_decay)
else:
optimizer = SGD(optimizer_grouped_parameters, lr=self.args.lr, momentum=0.9)
num_gpus = len([x for x in str(self.args.gpus).split(",") if x.strip()]) # 计算传入的可使用gpu数量
t_total = (len(self.train_dataloader()) // (
self.args.accumulate_grad_batches * num_gpus) + 1) * self.args.max_epochs # 计算总共要优化的次数,step的次数
# 设置优化策略
if self.args.lr_scheduler == "onecycle":
scheduler = torch.optim.lr_scheduler.OneCycleLR(
optimizer, max_lr=self.args.lr, pct_start=float(self.args.warmup_steps / t_total),
final_div_factor=self.args.final_div_factor,
total_steps=t_total, anneal_strategy='linear')
elif self.args.lr_scheduler == "linear":
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=self.args.warmup_steps,
num_training_steps=t_total)
elif self.args.lr_scheduler == "polydecay":
if self.args.lr_mini == -1:
lr_mini = self.args.lr / 5
else:
lr_mini = self.args.lr_mini
scheduler = get_polynomial_decay_schedule_with_warmup(optimizer, self.args.warmup_steps, t_total,
lr_end=lr_mini)
else:
raise ValueError
return [optimizer], [{"scheduler": scheduler, "interval": "step"}]
def forward(self, input_ids, attention_mask, token_type_ids): # 与nn.module中的forward一致,模型的前向计算过程
return self.model(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
# 损失计算
def compute_loss(self, start_logits, end_logits, span_logits,
start_labels, end_labels, match_labels, start_label_mask, end_label_mask):
batch_size, seq_len = start_logits.size()
start_float_label_mask = start_label_mask.view(-1).float()
end_float_label_mask = end_label_mask.view(-1).float()
match_label_row_mask = start_label_mask.bool().unsqueeze(-1).expand(-1, -1, seq_len)
match_label_col_mask = end_label_mask.bool().unsqueeze(-2).expand(-1, seq_len, -1)
match_label_mask = match_label_row_mask & match_label_col_mask
match_label_mask = torch.triu(match_label_mask, 0) # start should be less equal to end
if self.span_loss_candidates == "all":
# naive mask
float_match_label_mask = match_label_mask.view(batch_size, -1).float()
else:
# use only pred or golden start/end to compute match loss
start_preds = start_logits > 0
end_preds = end_logits > 0
if self.span_loss_candidates == "gold":
match_candidates = ((start_labels.unsqueeze(-1).expand(-1, -1, seq_len) > 0)
& (end_labels.unsqueeze(-2).expand(-1, seq_len, -1) > 0))
elif self.span_loss_candidates == "pred_gold_random":
gold_and_pred = torch.logical_or(
(start_preds.unsqueeze(-1).expand(-1, -1, seq_len)
& end_preds.unsqueeze(-2).expand(-1, seq_len, -1)),
(start_labels.unsqueeze(-1).expand(-1, -1, seq_len)
& end_labels.unsqueeze(-2).expand(-1, seq_len, -1))
)
data_generator = torch.Generator()
data_generator.manual_seed(0)
random_matrix = torch.empty(batch_size, seq_len, seq_len).uniform_(0, 1)
random_matrix = torch.bernoulli(random_matrix, generator=data_generator).long()
random_matrix = random_matrix.cuda()
match_candidates = torch.logical_or(
gold_and_pred, random_matrix
)
else:
match_candidates = torch.logical_or(
(start_preds.unsqueeze(-1).expand(-1, -1, seq_len)
& end_preds.unsqueeze(-2).expand(-1, seq_len, -1)),
(start_labels.unsqueeze(-1).expand(-1, -1, seq_len)
& end_labels.unsqueeze(-2).expand(-1, seq_len, -1))
)
match_label_mask = match_label_mask & match_candidates
float_match_label_mask = match_label_mask.view(batch_size, -1).float()
start_loss = self.bce_loss(start_logits.view(-1), start_labels.view(-1).float())
start_loss = (start_loss * start_float_label_mask).sum() / start_float_label_mask.sum()
end_loss = self.bce_loss(end_logits.view(-1), end_labels.view(-1).float())
end_loss = (end_loss * end_float_label_mask).sum() / end_float_label_mask.sum()
match_loss = self.bce_loss(span_logits.view(batch_size, -1), match_labels.view(batch_size, -1).float())
match_loss = match_loss * float_match_label_mask
match_loss = match_loss.sum() / (float_match_label_mask.sum() + 1e-10)
return start_loss, end_loss, match_loss
def training_step(self, batch, batch_idx): # 相当于训练的每一小步
tf_board_logs = {
"lr": self.trainer.optimizers[0].param_groups[0]['lr']} # 记录学习率
# batch中存放的就是一整个batch的训练数据
tokens, token_type_ids, start_labels, end_labels, start_label_mask, end_label_mask, match_labels, sample_idx, label_idx = batch
# num_tasks * [bsz, length, num_labels]
attention_mask = (tokens != 0).long() # 获取计算attention的mask
# 此处直接使用self()计算各个logits是pytorch lightning的特性,也可只用self.forward()来进行计算
start_logits, end_logits, span_logits = self(tokens, attention_mask, token_type_ids)
# 计算损失
start_loss, end_loss, match_loss = self.compute_loss(start_logits=start_logits,
end_logits=end_logits,
span_logits=span_logits,
start_labels=start_labels,
end_labels=end_labels,
match_labels=match_labels,
start_label_mask=start_label_mask,
end_label_mask=end_label_mask)
# 使用各个损失的权重获得最终的损失
total_loss = self.weight_start * start_loss + self.weight_end * end_loss + self.weight_span * match_loss
# 记录各种损失
tf_board_logs[f"train_loss"] = total_loss
tf_board_logs[f"start_loss"] = start_loss
tf_board_logs[f"end_loss"] = end_loss
tf_board_logs[f"match_loss"] = match_loss
# TODO 此处调用self.log()会将设置的数据记录到wandb中
self.log('train_start_loss', start_loss)
self.log('train_end_loss', end_loss)
self.log('train_match_loss', match_loss)
self.log('train_loss', total_loss)
return {'loss': total_loss, 'log': tf_board_logs} # 将损失和记录的logs返回
def validation_step(self, batch, batch_idx): # 相当于验证的每一小步
output = {}
tokens, token_type_ids, start_labels, end_labels, start_label_mask, end_label_mask, match_labels, sample_idx, label_idx = batch
attention_mask = (tokens != 0).long()
start_logits, end_logits, span_logits = self(tokens, attention_mask, token_type_ids)
start_loss, end_loss, match_loss = self.compute_loss(start_logits=start_logits,
end_logits=end_logits,
span_logits=span_logits,
start_labels=start_labels,
end_labels=end_labels,
match_labels=match_labels,
start_label_mask=start_label_mask,
end_label_mask=end_label_mask)
total_loss = self.weight_start * start_loss + self.weight_end * end_loss + self.weight_span * match_loss
output[f"val_loss"] = total_loss
output[f"start_loss"] = start_loss
output[f"end_loss"] = end_loss
output[f"match_loss"] = match_loss
# TODO 此处调用self.log()会将设置的数据记录到wandb中
self.log('val_start_loss', start_loss)
self.log('val_end_loss', end_loss)
self.log('val_match_loss', match_loss)
self.log('val_loss', total_loss)
start_preds, end_preds = start_logits > 0, end_logits > 0
# 计算span_f1,输出分别包含tp、fp、fn
span_f1_stats = self.span_f1(start_preds=start_preds, end_preds=end_preds, match_logits=span_logits,
start_label_mask=start_label_mask, end_label_mask=end_label_mask,
match_labels=match_labels)
output["span_f1_stats"] = span_f1_stats
return output
def validation_epoch_end(self, outputs): # 每训练完一个epoch,当完成验证之后会运行的代码,此处的outputs是validation_step输出的集合
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean() # 平均验证损失
tensorboard_logs = {'val_loss': avg_loss}
self.log('val_avg_loss', avg_loss)
all_counts = torch.stack([x[f'span_f1_stats'] for x in outputs]).view(-1, 3).sum(0) # 将所有step中的三个值累加
span_tp, span_fp, span_fn = all_counts
span_recall = span_tp / (span_tp + span_fn + 1e-10) # 召回率
span_precision = span_tp / (span_tp + span_fp + 1e-10) # 准确率
span_f1 = span_precision * span_recall * 2 / (span_recall + span_precision + 1e-10) # f1 score
tensorboard_logs[f"span_precision"] = span_precision
tensorboard_logs[f"span_recall"] = span_recall
tensorboard_logs[f"span_f1"] = span_f1
self.log('val_span_precision', span_precision)
self.log('val_span_recall', span_recall)
self.log('val_span_f1', span_f1)
self.result_logger.info(
f"EVAL INFO -> current_epoch is: {self.trainer.current_epoch}, current_global_step is: {self.trainer.global_step} ")
self.result_logger.info(
f"EVAL INFO -> valid_f1 is: {span_f1}; precision: {span_precision}, recall: {span_recall}.")
return {'val_loss': avg_loss, 'log': tensorboard_logs}
# 基本逻辑与验证的一致,但测试时关心的主要目标是metrics,故test_step只输出了span_f1_stats,而test_epoch_end中记录召回率、准确率和f1值
def test_step(self, batch, batch_idx): # 相当于测试的每一小步
""""""
output = {}
tokens, token_type_ids, start_labels, end_labels, start_label_mask, end_label_mask, match_labels, sample_idx, label_idx = batch
attention_mask = (tokens != 0).long()
start_logits, end_logits, span_logits = self(tokens, attention_mask, token_type_ids)
start_preds, end_preds = start_logits > 0, end_logits > 0
span_f1_stats = self.span_f1(start_preds=start_preds, end_preds=end_preds, match_logits=span_logits,
start_label_mask=start_label_mask, end_label_mask=end_label_mask,
match_labels=match_labels)
output["span_f1_stats"] = span_f1_stats
return output
def test_epoch_end(self, outputs) -> Dict[str, Dict[str, Tensor]]: # 每训练完一个epoch,当完成测试之后会运行的代码
tensorboard_logs = {}
all_counts = torch.stack([x[f'span_f1_stats'] for x in outputs]).view(-1, 3).sum(0)
span_tp, span_fp, span_fn = all_counts
span_recall = span_tp / (span_tp + span_fn + 1e-10)
span_precision = span_tp / (span_tp + span_fp + 1e-10)
span_f1 = span_precision * span_recall * 2 / (span_recall + span_precision + 1e-10)
self.log('test_span_precision', span_precision)
self.log('test_span_recall', span_recall)
self.log('test_span_f1', span_f1)
print(f"TEST INFO -> test_f1 is: {span_f1} precision: {span_precision}, recall: {span_recall}")
self.result_logger.info(
f"TEST INFO -> test_f1 is: {span_f1} precision: {span_precision}, recall: {span_recall}")
return {'log': tensorboard_logs}
def train_dataloader(self) -> DataLoader:
return self.get_dataloader("train")
def val_dataloader(self) -> DataLoader:
return self.get_dataloader("dev")
def test_dataloader(self) -> DataLoader:
return self.get_dataloader("test")
def get_dataloader(self, prefix="train", limit: int = None) -> DataLoader:
"""get training dataloader"""
"""
load_mmap_dataset
"""
json_path = os.path.join(self.data_dir, f"mrc-ner.{prefix}") # 通过prefix获取对应的数据集路径
vocab_path = os.path.join(self.bert_dir, "vocab.txt")
dataset = MRCNERDataset(json_path=json_path,
tokenizer=BertWordPieceTokenizer(vocab_path), # 分词器
max_length=self.args.max_length,
is_chinese=self.chinese,
pad_to_maxlen=False)
if limit is not None: # limit不是空,就对数据集进行截取
dataset = TruncateDataset(dataset, limit)
dataloader = DataLoader(
dataset=dataset,
batch_size=self.args.batch_size,
num_workers=self.args.workers,
shuffle=True if prefix == "train" else False,
collate_fn=collate_to_max_length) # 在一个batch中将所有的序列长度pad到该batch最长序列的大小
return dataloader
# 从日志eval_result_log.txt中找到验证数据集中最好的f1及其对应的保存的权重文件的路径
def find_best_checkpoint_on_dev(output_dir: str, log_file: str = "eval_result_log.txt",
only_keep_the_best_ckpt: bool = False):
with open(os.path.join(output_dir, log_file)) as f:
log_lines = f.readlines()
F1_PATTERN = re.compile(r"span_f1 reached \d+\.\d* \(best")
# val_f1 reached 0.00000 (best 0.00000)
CKPT_PATTERN = re.compile(r"saving model to \S+ as top")
checkpoint_info_lines = []
for log_line in log_lines:
if "saving model to" in log_line:
checkpoint_info_lines.append(log_line)
# example of log line
# Epoch 00000: val_f1 reached 0.00000 (best 0.00000), saving model to /data/xiaoya/outputs/0117/debug_5_12_2e-5_0.001_0.001_275_0.1_1_0.25/checkpoint/epoch=0.ckpt as top 20
best_f1_on_dev = 0
best_checkpoint_on_dev = ""
for checkpoint_info_line in checkpoint_info_lines:
current_f1 = float(
re.findall(F1_PATTERN, checkpoint_info_line)[0].replace("span_f1 reached ", "").replace(" (best", ""))
current_ckpt = re.findall(CKPT_PATTERN, checkpoint_info_line)[0].replace("saving model to ", "").replace(
" as top", "")
if current_f1 >= best_f1_on_dev:
if only_keep_the_best_ckpt and len(best_checkpoint_on_dev) != 0:
os.remove(best_checkpoint_on_dev)
best_f1_on_dev = current_f1
best_checkpoint_on_dev = current_ckpt
return best_f1_on_dev, best_checkpoint_on_dev
def main():
"""main"""
parser = get_parser() # 调用utils中的get_parser()函数获取已包含一定参数的AugmentParser对象
# add model specific args,添加更多具体的参数
parser = BertLabeling.add_model_specific_args(parser)
# add all the available trainer options to argparse
# ie: now --gpus --num_nodes ... --fast_dev_run all work in the cli
# parser = Trainer.add_argparse_args(parser)
args = parser.parse_args() # 将包含参数的AugmentParser对象解析
filename = os.path.join(args.default_root_dir, "eval_result_log.txt")
model = BertLabeling(args) # 初始化模型
# if args.pretrained_checkpoint:
# model.load_state_dict(torch.load(args.pretrained_checkpoint,
# map_location=torch.device('cpu'))["state_dict"])
# TODO 初始化WandbLogger
wandb_logger = WandbLogger(project='mrc_ner', name='run1')
wandb_logger.watch(model, log='all')
# 模型保存
checkpoint_callback = ModelCheckpoint(
dirpath=args.default_root_dir, # 默认根目录
save_top_k=args.max_keep_ckpt,
verbose=True,
monitor="val_span_f1", # 监控目标
# period=-1,
mode="max",
)
trainer = Trainer.from_argparse_args(
args,
checkpoint_callback=checkpoint_callback,
deterministic=True,
default_root_dir=args.default_root_dir,
logger=wandb_logger) # TODO 设置logger
trainer.fit(model) # 训练
# after training, use the model checkpoint which achieves the best f1 score on dev set to compute the f1 on test set.
# best_f1_on_dev, path_to_best_checkpoint = find_best_checkpoint_on_dev(args.default_root_dir, )
best_f1_on_dev, path_to_best_checkpoint = find_best_checkpoint_on_dev(
'D:/GithubProjects/mrc-for-flat-nested-ner-master/train_logs/zh_onto/zh_onto_adamw_lr1e-5_maxlen128_spanw0.1', )
model.result_logger.info("=&" * 20)
model.result_logger.info(f"Best F1 on DEV is {best_f1_on_dev}")
model.result_logger.info(f"Best checkpoint on DEV set is {path_to_best_checkpoint}")
checkpoint = torch.load(path_to_best_checkpoint)
checkpoint = torch.load(
'./train_logs/zh_onto/zh_onto_adamw_lr1e-5_maxlen128_spanw0.1/lightning_logs/version_0/checkpoints/epoch=4-step=39309.ckpt')
model.load_state_dict(checkpoint['state_dict'])
trainer.test(model) # 测试
model.result_logger.info("=&" * 20)
if __name__ == '__main__':
print(os.getcwd())
os.chdir('D:/GithubProjects/mrc-for-flat-nested-ner-master')
print(os.getcwd())
main()
ner2mrc
大部分常规的实体标注方法是将问句中的每个token分开,每一行放置一个token以及其对应的类别,句子直接用空格分开,如图所示;但使用mrc框架进行训练时需要对数据标注方法进行调整,mrc模块要求的数据如图所示。可基于常规的标注数据转换为mrc框架要求的数据格式

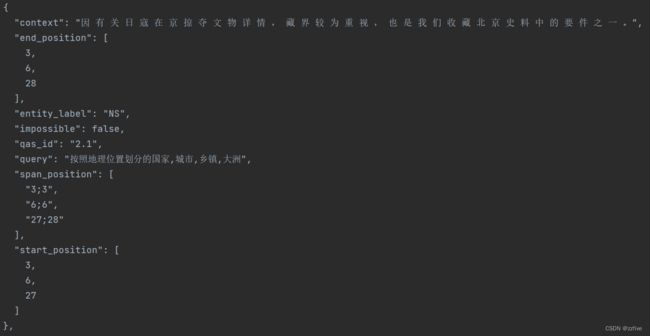
可借鉴msra2mrc.py进行数据转换
msra2mrc.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# file: msra2mrc.py
import os
from utils.bmes_decode import bmes_decode
import json
def convert_file(input_file, output_file, tag2query_file):
"""
Convert MSRA raw data to MRC format
"""
origin_count = 0
new_count = 0
tag2query = json.load(open(tag2query_file, encoding='utf-8'))
mrc_samples = []
with open(input_file, encoding='utf-8') as fin:
srcs = [] # 存放一个完整句子多有的token
labels = [] # 存放token对应的label
for line in fin:
line = line.strip()
if line: # 当line非空时,即还没有遍历到一个句子的结束点,需要继续下一行获取该句子的token和label
# origin_count += 1
src, label = line.split(" ")
srcs.append(src)
labels.append(label)
else: # 当当前line为空,表明已获取完整的句子
# 调用bmes_decode()函数进行解析,获取实体的开头和结尾的索引
tags = bmes_decode(char_label_list=[(char, label) for char, label in zip(srcs, labels)])
for i, (label, query) in enumerate(tag2query.items()): # tag2query存放label与query的对应关系
start_position = [tag.begin for tag in tags if tag.tag == label] # 获取当前lable实体的开始索引
end_position = [tag.end-1 for tag in tags if tag.tag == label] # 获取当前lable实体的结束索引
span_position = [str(s)+';'+str(e) for s, e in zip(start_position, end_position)] # 将开始索引和结束匹配
impossible = "true"
if start_position:
impossible = "false"
mrc_samples.append(
{
"qas_id": str(new_count) + "." + str(i+1), # 数据id,小数点前面是问句的位数,小数点后面表示query的位数
"context": " ".join(srcs), # 将srcs中所有的token用空格拼接,方便后续tokenizer.encoder_plus使用
"entity_label": label, # 该标注数据中实体的label
"start_position": start_position, # 所有实体的开始索引
"end_position": end_position, # 所有实体的结束索引
"span_position": span_position, # 所有实体的span
"impossible": impossible, # 如果问句中存在label对应的实体就为fasle,否则没有实体就为true
"query": query # 问句
}
)
new_count += 1
# 清空srcs和labels,用于存放下一个句子的token和label
srcs = []
labels = []
json.dump(mrc_samples, open(output_file, "w", encoding='utf-8'), ensure_ascii=False, sort_keys=True, indent=2)
def main():
msra_raw_dir = "zh_msra/zh_msra/"
msra_mrc_dir = "zh_msra/zh_msra/mrc_format/"
tag2query_file = "queries/zh_msra.json"
os.makedirs(msra_mrc_dir, exist_ok=True)
# for phase in ["train", "dev", "test"]:
for phase in ["train"]:
old_file = os.path.join(msra_raw_dir, f"{phase}.char.bmes")
new_file = os.path.join(msra_mrc_dir, f"mrc-ner.{phase}")
convert_file(old_file, new_file, tag2query_file)
if __name__ == '__main__':
main()
上述代码中调用的bmes_decode()函数以及自定义的Tag类的代码如下
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# file: bmes_decode.py
from typing import Tuple, List
class Tag(object): # 将实体的token组成、开始、结束索引等进行封装
def __init__(self, term, tag, begin, end):
self.term = term # token
self.tag = tag # 该实体具体数据的类型
self.begin = begin # 开始索引
self.end = end # 结束索引
def to_tuple(self):
return tuple([self.term, self.begin, self.end])
def __str__(self):
return str({key: value for key, value in self.__dict__.items()})
def __repr__(self):
return str({key: value for key, value in self.__dict__.items()})
def bmes_decode(char_label_list: List[Tuple[str, str]]) -> List[Tag]:
"""
decode inputs to tags
Args:
char_label_list: list of tuple (word, bmes-tag)
Returns:
tags
Examples:
>>> x = [("Hi", "O"), ("Beijing", "S-LOC")]
>>> bmes_decode(x)
[{'term': 'Beijing', 'tag': 'LOC', 'begin': 1, 'end': 2}]
"""
idx = 0 # 相当于遍历的指针
length = len(char_label_list) # 等同于一个问句中token的数量
tags = []
while idx < length:
term, label = char_label_list[idx]
current_label = label[0] # 实际表示token的实体状态的label的第一个字符
# correct labels
# 以下为一种特殊情况,即当idx访问到最后一个token,并且其token状态为B时等同于状态为S
if idx + 1 == length and current_label == "B":
current_label = "S"
# merge chars
if current_label == "O": # 如果为O,表示该token为背景,直接跳过
idx += 1
continue
if current_label == "S": # 如果为S,表示对应的单个token就表示一个实体
tags.append(Tag(term, label[2:], idx, idx + 1)) # 将读取的实体封装到Tag中,并保存
idx += 1
continue
if current_label == "B": # 表示一个实体的开始
end = idx + 1
# 在没有超过总长度的前提下,遍历完所有的为M的token
while end + 1 < length and char_label_list[end][1][0] == "M": # M表示实体的中间部分
end += 1
# 如果end对应E,表示访问到了实体的结束token,将实体所有的token拼接起来作为term封装到Tag中
if char_label_list[end][1][0] == "E": # end with E
# 以下都往后多取了一位,与S状态时一致
entity = "".join(char_label_list[i][0] for i in range(idx, end + 1))
tags.append(Tag(entity, label[2:], idx, end + 1))
idx = end + 1
else: # end with M/B
# 如果不是E,就全部都不多取一位
entity = "".join(char_label_list[i][0] for i in range(idx, end))
tags.append(Tag(entity, label[2:], idx, end))
idx = end
continue
else:
raise Exception("Invalid Inputs")
return tags
datasets
将常规的实体识别标注数据转换为mrc框架要求的数据后,就要将其转换为模型计算所需的数值型数据,主要过程见mrc_ner_dataset.py
mrc_ner_dataset.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# file: mrc_ner_dataset.py
import json
import torch
from tokenizers import BertWordPieceTokenizer
from torch.utils.data import Dataset
class MRCNERDataset(Dataset):
"""
MRC NER Dataset
Args:
json_path: path to mrc-ner style json,MRC风格表述数据的路径
tokenizer: BertTokenizer,分词器
max_length: int, max length of query+context,query加上context的最大长度
possible_only: if True, only use possible samples that contain answer for the query/context
is_chinese: is chinese dataset,是否为中文数据集
"""
def __init__(self, json_path, tokenizer: BertWordPieceTokenizer, max_length: int = 512, possible_only=False,
is_chinese=False, pad_to_maxlen=False):
self.all_data = json.load(open(json_path, encoding="utf-8"))
self.tokenizer = tokenizer
self.max_length = max_length
self.possible_only = possible_only
if self.possible_only: # 只是有包含实体的样例数据
self.all_data = [
x for x in self.all_data if x["start_position"] # 如果x中的start_position存放,就将其添加
]
self.is_chinese = is_chinese
self.pad_to_maxlen = pad_to_maxlen
def __len__(self): # 重载len,可返回MRCNERDataset实例的长度
return len(self.all_data)
def __getitem__(self, item): # 重载getitem,实现通过下标访问数据
"""
Args:
item: int, idx
Returns:
tokens: tokens of query + context, [seq_len],文本序列
token_type_ids: token type ids, 0 for query, 1 for context, [seq_len],文本序列类型
start_labels: start labels of NER in tokens, [seq_len],开始索引的序列
end_labels: end labelsof NER in tokens, [seq_len],结束索引的序列
label_mask: label mask, 1 for counting into loss, 0 for ignoring. [seq_len]
match_labels: match labels, [seq_len, seq_len],开始索引和结束索引匹配的实际label
sample_idx: sample id
label_idx: label id
"""
data = self.all_data[item] # 此处的data就是一个样例数据
tokenizer = self.tokenizer
qas_id = data.get("qas_id", "0.0")
sample_idx, label_idx = qas_id.split(".")
sample_idx = torch.LongTensor([int(sample_idx)]) # 该样例数据的问句在问句集合中的序号
label_idx = torch.LongTensor([int(label_idx)]) # 该样例数据中query对应的实体的label在所有label中的序号,就相当于实例的label值
query = data["query"] # 问句
context = data["context"] # 文本
start_positions = data["start_position"] # 包含开始索引的列表
end_positions = data["end_position"] # 包含结束索引的列表
if self.is_chinese: # 如果是中文数据集
context = "".join(context.split())
end_positions = [x+1 for x in end_positions] # 将所有结束索引的数值加一
else:
# add space offsets
words = context.split()
start_positions = [x + sum([len(w) for w in words[:x]]) for x in start_positions]
end_positions = [x + sum([len(w) for w in words[:x + 1]]) for x in end_positions]
query_context_tokens = tokenizer.encode(query, context, add_special_tokens=True)
tokens = query_context_tokens.ids
type_ids = query_context_tokens.type_ids
offsets = query_context_tokens.offsets
# find new start_positions/end_positions, considering
# 1. we add query tokens at the beginning
# 2. word-piece tokenize
origin_offset2token_idx_start = {} # 存放context中每个token作为实体开始的索引在现在序列对中的索引位置
origin_offset2token_idx_end = {} # 存放context中每个token作为实体结束的索引在现在序列对中的索引位置
for token_idx in range(len(tokens)):
# skip query tokens,跳过query语句的token,其中不存在实体
if type_ids[token_idx] == 0:
continue
token_start, token_end = offsets[token_idx]
# skip [CLS] or [SEP]
if token_start == token_end == 0: # 如果都为0,表示该token为特殊字符
continue
origin_offset2token_idx_start[token_start] = token_idx
origin_offset2token_idx_end[token_end] = token_idx
# 直接用context中原始的索引值获取现在序列对中的索引值
new_start_positions = [origin_offset2token_idx_start[start] for start in start_positions]
new_end_positions = [origin_offset2token_idx_end[end] for end in end_positions]
label_mask = [ # 其中前、中、后三个特殊token的以及query的所有token都为0,其他会1
(0 if type_ids[token_idx] == 0 or offsets[token_idx] == (0, 0) else 1)
for token_idx in range(len(tokens))
]
start_label_mask = label_mask.copy()
end_label_mask = label_mask.copy()
# the start/end position must be whole word
if not self.is_chinese: # 如果为英文数据集
for token_idx in range(len(tokens)):
current_word_idx = query_context_tokens.words[token_idx]
next_word_idx = query_context_tokens.words[token_idx+1] if token_idx+1 < len(tokens) else None
prev_word_idx = query_context_tokens.words[token_idx-1] if token_idx-1 > 0 else None
if prev_word_idx is not None and current_word_idx == prev_word_idx:
start_label_mask[token_idx] = 0
if next_word_idx is not None and current_word_idx == next_word_idx:
end_label_mask[token_idx] = 0
assert all(start_label_mask[p] != 0 for p in new_start_positions)
assert all(end_label_mask[p] != 0 for p in new_end_positions)
assert len(new_start_positions) == len(new_end_positions) == len(start_positions)
assert len(label_mask) == len(tokens)
start_labels = [(1 if idx in new_start_positions else 0)
for idx in range(len(tokens))] # 将new_start_positions中索引对应的值设为1,其他全为0
end_labels = [(1 if idx in new_end_positions else 0)
for idx in range(len(tokens))] # 将new_end_positions中索引对应的值设为1,其他全为0
# truncate
tokens = tokens[: self.max_length]
type_ids = type_ids[: self.max_length]
start_labels = start_labels[: self.max_length]
end_labels = end_labels[: self.max_length]
start_label_mask = start_label_mask[: self.max_length]
end_label_mask = end_label_mask[: self.max_length]
# make sure last token is [SEP],最后一个token必须是[SEP],如果不是就替换成[SEP]
sep_token = tokenizer.token_to_id("[SEP]")
if tokens[-1] != sep_token:
assert len(tokens) == self.max_length
tokens = tokens[: -1] + [sep_token]
start_labels[-1] = 0
end_labels[-1] = 0
start_label_mask[-1] = 0
end_label_mask[-1] = 0
if self.pad_to_maxlen: # 对多有数据进行pad
tokens = self.pad(tokens, 0) # token用0进行pad
type_ids = self.pad(type_ids, 1) # type用1进行pad
start_labels = self.pad(start_labels)
end_labels = self.pad(end_labels)
start_label_mask = self.pad(start_label_mask)
end_label_mask = self.pad(end_label_mask)
seq_len = len(tokens)
match_labels = torch.zeros([seq_len, seq_len], dtype=torch.long)
for start, end in zip(new_start_positions, new_end_positions):
if start >= seq_len or end >= seq_len:
continue
match_labels[start, end] = 1 # 构造match_labels,是一个二维张量,只有(start, end)处为1,其他全为0
return [
torch.LongTensor(tokens),
torch.LongTensor(type_ids),
torch.LongTensor(start_labels),
torch.LongTensor(end_labels),
torch.LongTensor(start_label_mask),
torch.LongTensor(end_label_mask),
match_labels,
sample_idx,
label_idx
]
def pad(self, lst, value=0, max_length=None):
max_length = max_length or self.max_length
while len(lst) < max_length:
lst.append(value)
return lst
构造dataloader时还可能用到collate_to_max_length()函数和TruncateDataset类,前者是将一个batch数据中的序列pad到该batch中最大序列的大小,后者是可对dataset的数量进行指定截取,两者均在mrc_ner_trainer.py的训练代码中使用,代码如下:
import torch
from typing import List
def collate_to_max_length(batch: List[List[torch.Tensor]]) -> List[torch.Tensor]:
"""
pad to maximum length of this batch,将一个batch中所有序列长度pad到该batch最长序列的大小
Args:
batch: a batch of samples, each contains a list of field data(Tensor):
tokens, token_type_ids, start_labels, end_labels, start_label_mask, end_label_mask, match_labels, sample_idx, label_idx
Returns:
output: list of field batched data, which shape is [batch, max_length]
"""
batch_size = len(batch)
max_length = max(x[0].shape[0] for x in batch) # 获取batch中最长序列的长度
output = []
# 输入的batch中共有九种不同的数据,此处是构建前六种,即tokens, token_type_ids, start_labels, end_labels, start_label_mask, end_label_mask
for field_idx in range(6):
# 以0构建一个大小为batch_size,序列长度为max_length的背景二维张量
pad_output = torch.full([batch_size, max_length], 0, dtype=batch[0][field_idx].dtype)
for sample_idx in range(batch_size):
data = batch[sample_idx][field_idx]
# 如果data.shape[0]比max_length大,那么pad_output中也只有max_length对应的部分改变;如果max_length更大,就是前data.shape[0]被data重新赋值,其他部分还是为0
pad_output[sample_idx][: data.shape[0]] = data
output.append(pad_output)
# 以0构建一个大小为batch_size,序列长度为max_length的背景三维张量
pad_match_labels = torch.zeros([batch_size, max_length, max_length], dtype=torch.long)
for sample_idx in range(batch_size):
data = batch[sample_idx][6]
pad_match_labels[sample_idx, : data.shape[1], : data.shape[1]] = data
output.append(pad_match_labels)
# 这两个都不是序列,也不参与计算,不需要进行pad或truncate
output.append(torch.stack([x[-2] for x in batch]))
output.append(torch.stack([x[-1] for x in batch]))
return output # 返回后前其中数据的序列长度均被设置为max_length;如果原来过长就被truncate,如果原来果断,就被0填充
from torch.utils.data import Dataset
class TruncateDataset(Dataset):
"""Truncate dataset to certain num"""
def __init__(self, dataset: Dataset, max_num: int = 100):
self.dataset = dataset
self.max_num = min(max_num, len(self.dataset))
def __len__(self):
return self.max_num
def __getitem__(self, item):
return self.dataset[item]
def __getattr__(self, item):
"""other dataset func"""
return getattr(self.dataset, item)
evaluate
mrc_ner_evaluate.py
测试
import sys
from pytorch_lightning import Trainer
from train.mrc_ner_trainer import BertLabeling
from utils.random_seed import set_random_seed
set_random_seed(0)
def evaluate(ckpt, hparams_file, gpus=[0, 1], max_length=300):
trainer = Trainer(gpus=gpus, distributed_backend="dp") # 设置trainer
# 加载保存的模型数据
model = BertLabeling.load_from_checkpoint(
checkpoint_path=ckpt,
hparams_file=hparams_file,
map_location=None,
batch_size=1,
max_length=max_length,
workers=0
)
trainer.test(model=model) # 测试
if __name__ == '__main__':
# example of running evaluate.py
# CHECKPOINTS = "/mnt/mrc/train_logs/zh_msra/zh_msra_20200911_for_flat_debug/epoch=2_v1.ckpt"
# HPARAMS = "/mnt/mrc/train_logs/zh_msra/zh_msra_20200911_for_flat_debug/lightning_logs/version_2/hparams.yaml"
# GPUS="1,2,3"
CHECKPOINTS = sys.argv[1]
HPARAMS = sys.argv[2]
try:
GPUS = [int(gpu_item) for gpu_item in sys.argv[3].strip().split(",")]
except:
GPUS = [0]
try:
MAXLEN = int(sys.argv[4])
except:
MAXLEN = 300
evaluate(ckpt=CHECKPOINTS, hparams_file=HPARAMS, gpus=GPUS, max_length=MAXLEN)
inference
mrc_ner_inference.py
加载训练好的模型进行推理
import os
import torch
import argparse
from torch.utils.data import DataLoader
from utils.random_seed import set_random_seed
set_random_seed(0)
from train.mrc_ner_trainer import BertLabeling
from tokenizers import BertWordPieceTokenizer
from datasets.mrc_ner_dataset import MRCNERDataset
from metrics.functional.query_span_f1 import extract_flat_spans, extract_nested_spans
def get_dataloader(config, data_prefix="test"): # 加载测试数据集
data_path = os.path.join(config.data_dir, f"mrc-ner.{data_prefix}")
vocab_path = os.path.join(config.bert_dir, "vocab.txt")
data_tokenizer = BertWordPieceTokenizer(vocab_path)
dataset = MRCNERDataset(json_path=data_path,
tokenizer=data_tokenizer,
max_length=config.max_length,
is_chinese=config.is_chinese,
pad_to_maxlen=False)
dataloader = DataLoader(dataset=dataset, batch_size=1, shuffle=False)
return dataloader, data_tokenizer
def get_query_index_to_label_cate(dataset_sign): # 根据label类别号获取对应的类别
# NOTICE: need change if you use other datasets.
# please notice it should in line with the mrc-ner.test/train/dev json file
if dataset_sign == "conll03":
return {1: "ORG", 2: "PER", 3: "LOC", 4: "MISC"}
elif dataset_sign == "ace04":
return {1: "GPE", 2: "ORG", 3: "PER", 4: "FAC", 5: "VEH", 6: "LOC", 7: "WEA"}
def get_parser() -> argparse.ArgumentParser:
parser = argparse.ArgumentParser(description="inference the model output.")
parser.add_argument("--data_dir", type=str, required=True)
parser.add_argument("--bert_dir", type=str, required=True)
parser.add_argument("--max_length", type=int, default=256)
parser.add_argument("--is_chinese", action="store_true")
parser.add_argument("--model_ckpt", type=str, default="") # 待加载的checkpoint文件
parser.add_argument("--hparams_file", type=str, default="")
parser.add_argument("--flat_ner", action="store_true", )
parser.add_argument("--dataset_sign", type=str, choices=["ontonotes4", "msra", "conll03", "ace04", "ace05"],
default="conll03")
return parser
def main():
parser = get_parser()
args = parser.parse_args() # 获取各类参数
# 初始化模型,加载模型参数
trained_mrc_ner_model = BertLabeling.load_from_checkpoint(
checkpoint_path=args.model_ckpt,
hparams_file=args.hparams_file,
map_location=None,
batch_size=1,
max_length=args.max_length,
workers=0)
# 加载数据
data_loader, data_tokenizer = get_dataloader(args, )
# load token
vocab_path = os.path.join(args.bert_dir, "vocab.txt")
with open(vocab_path, "r") as f:
subtokens = [token.strip() for token in f.readlines()]
idx2tokens = {}
for token_idx, token in enumerate(subtokens):
idx2tokens[token_idx] = token
query2label_dict = get_query_index_to_label_cate(args.dataset_sign)
for batch in data_loader:
tokens, token_type_ids, start_labels, end_labels, start_label_mask, end_label_mask, match_labels, sample_idx, label_idx = batch
attention_mask = (tokens != 0).long() # 获取计算attention的mask
start_logits, end_logits, span_logits = trained_mrc_ner_model.model(tokens, attention_mask=attention_mask,
token_type_ids=token_type_ids)
# 认为大于0的值是预测的实体索引,返回的序列对应位置为True,相当于1,其他位置为Fasle,相当于0
start_preds, end_preds, span_preds = start_logits > 0, end_logits > 0, span_logits > 0
subtokens_idx_lst = tokens.numpy().tolist()[0] # 获取token的序列值
subtokens_lst = [idx2tokens[item] for item in subtokens_idx_lst] # 将序列值转换为实际的字符
label_cate = query2label_dict[label_idx.item()] # 获取batch中每个样例数据中实体的真实类型
readable_input_str = data_tokenizer.decode(subtokens_idx_lst, skip_special_tokens=True) # 对token的序列值进行解码
if args.flat_ner: # flat任务
entities_info = extract_flat_spans(torch.squeeze(start_preds), torch.squeeze(end_preds),
torch.squeeze(span_preds), torch.squeeze(attention_mask),
pseudo_tag=label_cate) # 直接用样例数据的真实label
entity_lst = []
if len(entities_info) != 0: # 返回的包含实体信息的序列进行解析
for entity_info in entities_info:
start, end = entity_info[0], entity_info[1]
entity_string = " ".join(subtokens_lst[start: end])
entity_string = entity_string.replace(" ##", "")
entity_lst.append((start, end, entity_string, entity_info[2]))
else:
match_preds = span_logits > 0
entities_info = extract_nested_spans(start_preds, end_preds, match_preds, start_label_mask, end_label_mask,
pseudo_tag=label_cate) # 直接用样例数据的真实label
entity_lst = []
if len(entities_info) != 0: # 返回的包含实体信息的序列进行解析
for entity_info in entities_info:
start, end = entity_info[0], entity_info[1]
entity_string = " ".join(subtokens_lst[start: end + 1])
entity_string = entity_string.replace(" ##", "")
entity_lst.append((start, end + 1, entity_string, entity_info[2]))
print("*=" * 10)
print(f"Given input: {readable_input_str}")
print(f"Model predict: {entity_lst}")
# entity_lst is a list of (subtoken_start_pos, subtoken_end_pos, substring, entity_type)
if __name__ == "__main__":
main()
上述代码中还分别调用了extract_flat_spans()、extract_nested_spans()函数进行预测结果解析,代码如图下:
def extract_flat_spans(start_pred, end_pred, match_pred, label_mask, pseudo_tag = "TAG"):
"""
Extract flat-ner spans from start/end/match logits
Args:
start_pred: [seq_len], 1/True for start, 0/False for non-start
end_pred: [seq_len, 2], 1/True for end, 0/False for non-end
match_pred: [seq_len, seq_len], 1/True for match, 0/False for non-match
label_mask: [seq_len], 1 for valid boundary.
Returns:
tags: list of tuple (start, end)
Examples:
>>> start_pred = [0, 1]
>>> end_pred = [0, 1]
>>> match_pred = [[0, 0], [0, 1]]
>>> label_mask = [1, 1]
>>> extract_flat_spans(start_pred, end_pred, match_pred, label_mask)
[(1, 2)]
"""
pseudo_input = "a"
bmes_labels = ["O"] * len(start_pred)
# 获取start_pred和label_mask中统一索引对应的值为True的idx,为有效的预测开始索引
start_positions = [idx for idx, tmp in enumerate(start_pred) if tmp and label_mask[idx]]
# 获取end_pred和label_mask中统一索引对应的值为True的idx,为有效的预测结束索引
end_positions = [idx for idx, tmp in enumerate(end_pred) if tmp and label_mask[idx]]
for start_item in start_positions:
bmes_labels[start_item] = f"B-{pseudo_tag}" # 在背景中将开始索引的值设为B-a
for end_item in end_positions:
bmes_labels[end_item] = f"E-{pseudo_tag}" # 在背景中将结束索引的值设为E-a
for tmp_start in start_positions: # 以开始索引为基点去和不同的结束索引匹配,判断有效的索引匹配
tmp_end = [tmp for tmp in end_positions if tmp >= tmp_start] # 结束索引要大于开始索引
if len(tmp_end) == 0:
continue
else:
tmp_end = min(tmp_end) # 因为是flat任务,不存在实体重叠,直接取离开始索引最近的作为结束索引
if match_pred[tmp_start][tmp_end]: # 如果在match_pred中[tmp_start][tmp_end]坐标对应的位置也存在,说明匹配成功
if tmp_start != tmp_end: # 如果start和end不同,就说明该实体包括多个token
for i in range(tmp_start+1, tmp_end): # 将start和end中间的token都设置为M
bmes_labels[i] = f"M-{pseudo_tag}"
else:
bmes_labels[tmp_end] = f"S-{pseudo_tag}" # 如果start和end相等,说明该实体只有一个token,则将原来的B改为S
tags = bmes_decode([(pseudo_input, label) for label in bmes_labels])
return [(entity.begin, entity.end, entity.tag) for entity in tags]
def extract_nested_spans(start_preds, end_preds, match_preds, start_label_mask, end_label_mask, pseudo_tag="TAG"):
start_label_mask = start_label_mask.bool()
end_label_mask = end_label_mask.bool()
bsz, seq_len = start_label_mask.size()
start_preds = start_preds.bool()
end_preds = end_preds.bool()
# 有效的预测匹配,就是在start_preds、end_preds、match_preds、tart_label_mask、 end_label_mask都是有效的
match_preds = (match_preds & start_preds.unsqueeze(-1).expand(-1, -1, seq_len) & end_preds.unsqueeze(1).expand(-1, seq_len, -1)) # start_preds、end_preds、match_preds三者与运算,获取有效的匹配
match_label_mask = (start_label_mask.unsqueeze(-1).expand(-1, -1, seq_len) & end_label_mask.unsqueeze(1).expand(-1, seq_len, -1)) # 有效的mask
match_label_mask = torch.triu(match_label_mask, 0) # start should be less or equal to end,start应该小于等于end
match_preds = match_label_mask & match_preds # preds和mask与运算
match_pos_pairs = np.transpose(np.nonzero(match_preds.numpy())).tolist() # 获取非0的坐标
return [(pos[0], pos[1], pseudo_tag) for pos in match_pos_pairs]
总结
至此,本笔记论文的主要思路,官方项目代码中从数据集构建、转换,模型搭建、训练以及后续的验证和推理整个过程进行了完整的解析。通过对代码学习发现,官方的github代码不是很全,有些地方需要自己补充。本笔记中的代码对官方代码进行适当的补充和详细的注释,可根据自身项目适当修改后再使用
后记
- 最后推理时才意识到,模型中是没有计算label的损失的,其损失全部都是是由索引损失组成的,没有对抽取的实体的label类型进行预测,而是直接使用数据集中的实际label。原因可能是,该模型在使用时,是需要通过query进行实体抽取的,作者可能认为在确认query时就一定决定了所有抽取的实体的类型。该想法不知是否正确,后续会继续补充