实现拉普拉斯修正的朴素贝叶斯分类器
编码实现拉普拉斯修正的朴素贝叶斯分类器,基于给定的训练数据,对测试样本进行判别。
import numpy as np
def loaddata():
X = np.array([[1,'S'],[1,'M'],[1,'M'],[1,'S'],
[1, 'S'], [2, 'S'], [2, 'M'], [2, 'M'],
[2, 'L'], [2, 'L'], [3, 'L'], [3, 'M'],
[3, 'M'], [3, 'L'], [3, 'L']])
y = np.array([-1,-1,1,1,-1,-1,-1,1,1,1,1,1,1,1,-1])
return X, y
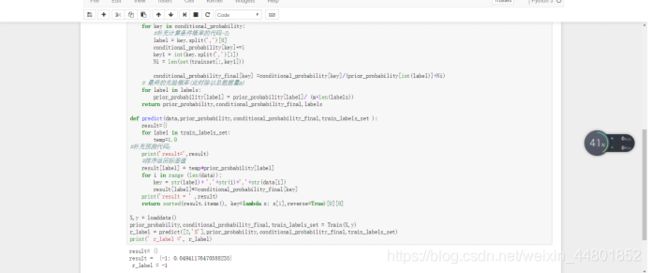
def Train(trainset,train_labels):
m = trainset.shape[0]
n = trainset.shape[1]
prior_probability = {}# 先验概率 key是类别值,value是类别的概率值
conditional_probability ={}# 条件概率 key的构造:类别,特征,特征值
#类别的可能取值
labels = set(train_labels)
# 计算先验概率(此时没有除以总数据量m)
for label in labels:
prior_probability[label] = len(train_labels[train_labels == label])+1
#计算条件概率
for i in range(m):
for j in range(n):
# key的构造:类别,特征,特征值
#补充计算条件概率的代码-1;
key = str(train_labels[i])+','+str(j)+','+str(trainset[i][j])
conditional_probability[key] = (conditional_probability[key]+1 if (key in conditional_probability) else 1)
conditional_probability_final = {}
for key in conditional_probability:
#补充计算条件概率的代码-2;
label = key.split(',')[0]
conditional_probability[key]+=1
key1 = int(key.split(',')[1])
Ni = len(set(trainset[:,key1]))
conditional_probability_final[key] =conditional_probability[key]/(prior_probability[int(label)]+Ni)
# 最终的先验概率(此时除以总数据量m)
for label in labels:
prior_probability[label] = prior_probability[label]/ (m+len(labels))
return prior_probability,conditional_probability_final,labels
def predict(data):
result={}
for label in train_labels_set:
temp=1.0
#补充预测代码;
print('result=',result)
#排序返回标签值
result[label] = temp*prior_probability[label]
for i in range (len(data)):
key = str(label)+ ','+str(i)+','+str(data[i])
result[label]*=conditional_probability_final[key]
print('result=',result)
#排序返回标签值
return sorted(result.items(), key=lambda x: x[1],reverse=True)[0][0]
X,y = loaddata()
prior_probability,conditional_probability,train_labels_set = Train(X,y)
r_label = predict([2,'S'])
print(' r_label =', r_label)