Hive整合hbase及导入数据测试
1,Hive与Hbase的区别
1.1Hive(数据仓库)
Hive是由Facebook实现并开源,是基于Hadoop的一个数据仓库工具,底层依赖于HDFS存储数据,利用MapReduce进行计算,可以将结构化的数据映射为一张数据库表,并提供HQL。Hive的本质是将 SQL 语句转换为 MapReduce 任务运行。Hive提供了三种协议访问 Hive数据:Thrift RPC、JDBC、ODBC。
注意:以上是Hive之前的定义。如今随着大数据的发展Hive逐步舍弃了MR。Hive2.X版本已经建议不再使用MR,而在新出来的Hive3.X版本中,直接舍弃了使用MR作为底层运行机制,改为使用Tez。后来由于Spark的出现,许多公司开始使用Spark代替MapReduce作为Hive的执行引擎,使Hive运行在Spark上。也就是Hive on Spark。
1.2Hbase(数据库)
HBase 是 BigTable 的开源(源码使用 Java 编写)版本。是 Apache Hadoop 的数据库,是建立在 HDFS 之上,被设计用来提供高可靠性、高性能、列存储、可伸缩、多版本的非关系型的分布式数据存储系统,实现对大型数据的实时、随机的读写访问。
HBase 依赖于 HDFS 做底层的数据存储,BigTable 依赖 Google GFS 做数据存储。
HBase 依赖于 MapReduce 做数据计算,BigTable 依赖 Google MapReduce 做数据计算。
HBase 依赖于 ZooKeeper 做服务协调,BigTable 依赖 Google Chubby 做服务协调。
1.3hive与hbase区别
Hbase,其实是Hadoop database的简称,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。HBase作为支持查询的数据管理器,仅HBase不能用于分析查询,因为它没有专用的查询语言。为了运行CRUD(创建,读取,更新和删除)和搜索查询,它具有基于JRuby的shell,该shell提供了简单的数据操作可能性,例如Get,Put和Scan。
Hive,Hadoop数据仓库,通过SQL来处理和计算HDFS的数据,Hive会将SQL翻译为Mapreduce来处理数据,适用于离线的批量数据计算。Hive作为分析查询引擎,是专门为启用数据分析而设计的,专用的Hive查询语言(HiveQL)与SQL类似。最初,Hive将HiveQL查询转换为Hadoop MapReduce作业执行,而如今,Apache Hive还能够将查询转换为Apache Tez或Apache Spark作业。2.Hive整合Hbase
实验环境准备:
Hive-2.3.3
Hbase-1.3.1
2.1实验原理:
Hive与HBase整合的实现是利用两者本身对外的API接口互相通信来完成的,其具体工作交由Hive的lib目录中的hive-hbase-*.jar工具类来实现

整合的意义:
(一)通过Hive把数据加载到HBase中,数据源可以是文件也可以是Hive中的表。
(二)通过整合,让HBase支持JOIN、GROUP等SQL查询语法。
(三)通过整合,不仅可完成HBase的数据实时查询,也可以使用Hive查询HBase中的数据完成复杂的数据分析。
(四)通过结合,可以设计一个高速写入,后面接入实时分析的海量数据分析系统。
3.实验步骤
3.1查看进程
xcall.sh jps
cd /opt/software/hive-2.3.3/lib/
ll

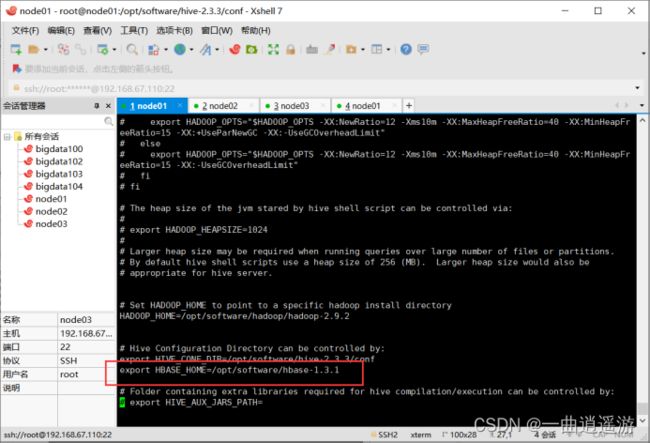
3.2修改hive-site.xml文件以及hive-env.sh文件配置(仅当hbase为集群模式时)
hive-site.xml:
h ive.zookeeper.quorum
node01,node02,node03
hbase.zookeeper.quorum
node01,node02,node03
hive.aux.jars.path
file:///opt/software/hive/lib/hive-hbase-handler-2.3.3.jar,file:///opt/software/hive/lib/zoo keeper-3.4.10.jar,file:///opt/software/hive/lib/hbase-client-1.3.1.jar,file:///opt/software/hive/lib/hbase-common-1.3.1-tests.jar,file:///opt/software/hive/lib/hbase-server-1.3.1.jar,file:///opt/software/hive/lib/hbase-common-1.3.1.jar,file:///opt/software/hive/lib/hbase-protocol-1.3.1.jar,file:///opt/software/hive/lib/htrace-core-3.1.0-incubating.jar


3.3将hbase lib目录下的所有文件复制到hive lib目录中
/opt/software/hive/lib目录下:
rm -rf hbase-*
/opt/software/hbase/lib目录下:
cp * /opt/software/hive/lib/

3.4在hive中创建映射表,创建完成后在hbase中查看是否同时在hbase中也创建成功(创建之前要先启动hbase)



4,导入数据测试:
Hive 导入数据,Hbase查看数据:
1)vi hive_hbase.txt
2)在hive中创表,导入数据:
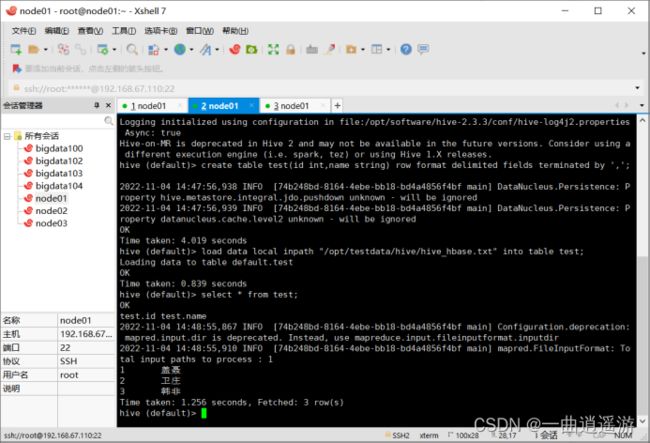
create table test(id int,name string) row format delimited fields terminated by ',';
load data local inpath "/opt/testdata/hive/hive_hbase.txt" into table test;
select * from test;
3)将hive的test表中的数据加载到hive_hbase_test表
insert overwrite table hive_hbase_test select * from test;

4)通过Hbase put添加数据,Hive查看添加数据
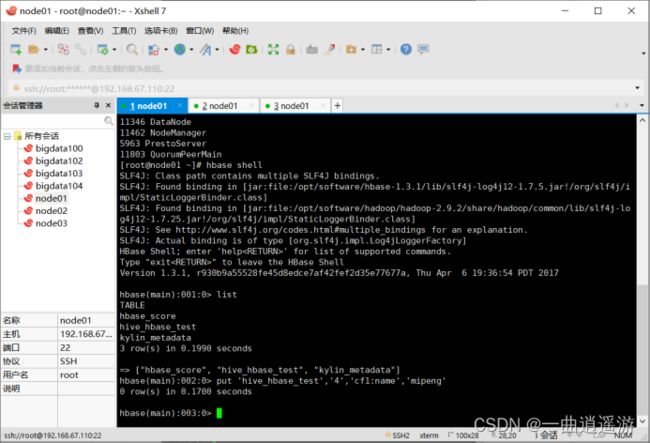
1)在hbase shell中对表hive_hbase_test添加数据
put 'hive_hbase_test','4','cf1:name','mipeng'
2)在hive中查看数据是否添加进来:
select * from hive_hbase_test;

注意事项:
整合完成之后,如果在hive当中创建的为内部表,那么在hive中删除该表时,hbase上对应的表也会删除;如果在hive当中创建的为外部表,那么在hive中删除该表时,不会影响hbase。
补充:
hive中创建外部映射表步骤:
1.在hbase中创建对应名称、对应列簇的表:
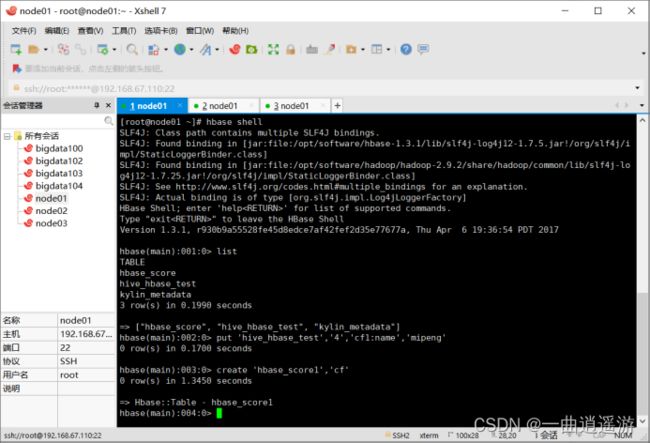
create 'hbase_score1','cf'
2.在hive中创建外部表:
create external table hbase_score1(id int,name string,score int) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping" = "cf:name,cf:score") tblproperties("hbase.table.name" = "hbase_score1");
3.在hive中向外部表内导入数据:(参考导入数据测试)
4.在hbase中添加数据:(参考导入数据测试)