Pytorch自带数据集介绍
Pytorch01——数据集介绍
参考:https://pytorch.org/docs/stable/torchvision/datasets.html
本文主要是对Pytorch图像数据集的官方文档翻译,以及梳理和总结。有错误的地方请诸位大佬指正!转载请注明来源!
主要涉及Libraries库中的torchvision.datasets。
目录
Pytorch01——数据集介绍
整体介绍
EMNIST
MNIST
QMNIST
USPS
SVHN
KMNIST
Omniglot
Fashion-MNIST
CIFAR
LSUN
STL10
CelebA
Places365
Cityscapes
SBD
Flickr
HMDB51
Kinetics-400
UCF101
PhotoTour
SBU
ImageNet
VOC
COCO
FakeData
DatasetFolder
ImageFolder
整体介绍
用于image classification:
手写字符识别:EMNIST、MNIST、QMNIST、USPS、SVHN、KMNIST、Omniglot
实物分类:Fashion MNIST、CIFAR、LSUN、SLT-10、ImageNet
人脸识别:CelebA
场景分类:LSUN、Places365
用于object detection:SVHN、VOCDetection、COCODetection
用于semantic/instance segmentation:
语义分割:Cityscapes、VOCSegmentation
语义边界:SBD
用于image captioning:Flickr、COCOCaption
用于video classification:HMDB51、Kinetics
用于3D reconstruction:PhotoTour
用于shadow detectors:SBU
EMNIST
torchvision.datasets.EMNIST(root: str, split: str, **kwargs: Any)
Parameters:
root (string) – Root directory of dataset where EMNIST/processed/training.pt and EMNIST/processed/test.pt exist.
split (string) – The dataset has 6 different splits: byclass, bymerge, balanced, letters, digits and mnist. This argument specifies which one to use.
train (bool, optional) – If True, creates dataset from training.pt, otherwise from test.pt.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
下载地址:
https://www.nist.gov/itl/products-and-services/emnist-dataset
作者:
Gregory Cohen, Saeed Afshar, Jonathan Tapson, Andre van Schaik
The MARCS Institute for Brain, Behaviour and Development, Western Sydney University
引用:
Cohen, G., Afshar, S., Tapson, J., & van Schaik, A. (2017). EMNIST: an extension of MNIST to handwritten letters. Retrieved from http://arxiv.org/abs/1702.05373
简介:
EMNIST来自NIST Special Database 19,包含了数字和大小写字母。大小为1.65GB,分为6部分:

By Class和By Merge的数据分布:


Balanced:

Letters:

Digits 和 MNIST:

MNIST
torchvision.datasets.MNIST(root: str, train: bool = True, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
Parameters:
root (string) – Root directory of dataset where MNIST/processed/training.pt and MNIST/processed/test.pt exist.
train (bool, optional) – If True, creates dataset from training.pt, otherwise from test.pt.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
下载地址:
http://yann.lecun.com/exdb/mnist/
作者:
Yann LeCun, Courant Institute,,NYU
Corinna Cortes,Google Labs,New York
Christopher J.C. Burges,Microsoft Research,Redmond
简介:
前世:MNIST由NIST的Special Database 3和Special Database 1组成。
- 在NIST中SD-3由Census Bureau的雇员书写,作为训练集,SD-1由高中生书写,作为测试集,SD-3比SD-1更干净和便于识别。SD-1包含了58527张来自500位作者的手写数字图片。SD-3的数据是顺序写入的,同一个人写的10个数字是放在一起的,SD-1的数据是打乱的,但是数据中包含了作者的ID。
- 所以将SD-1的前250个作者写的近3万数字图像放入MNIST的训练集,剩下的由SD-3补全至6万张训练集。将SD-1的后250个作者写的3万数字图像放入MNIST的测试集,剩下的由SD-3补全至6万张测试集。但是,只能下载到6万张的训练集,和1万张的测试集(从6万张测试集选出)。
今生:MNIST训练集6万张图片,分别从SD-3和SD-1中选择3万张,测试集1万张图片,分别从SD-3和SD-1中选择5千张。训练集6万张图片大约来自250位作者,训练集和测试集中的作者不相交。
- 手写数字识别,样本为28*28的二值图,数字尺度统一,数字质心在图片正中。
- 训练集60k,测试集10k,共70k。分为10个数字类别,每类的图片数量相同。
QMNIST
torchvision.datasets.QMNIST(root: str, what: Optional[str] = None, compat: bool = True, train: bool = True, **kwargs: Any)
Parameters:
root (string) – Root directory of dataset whose ``processed’’ subdir contains torch binary files with the datasets.
what (string,optional) – Can be ‘train’, ‘test’, ‘test10k’, ‘test50k’, or ‘nist’ for respectively the mnist compatible training set, the 60k qmnist testing set, the 10k qmnist examples that match the mnist testing set, the 50k remaining qmnist testing examples, or all the nist digits. The default is to select ‘train’ or ‘test’ according to the compatibility argument ‘train’.
compat (bool,optional) – A boolean that says whether the target for each example is class number (for compatibility with the MNIST dataloader) or a torch vector containing the full qmnist information. Default=True.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
train (bool,optional,compatibility) – When argument ‘what’ is not specified, this boolean decides whether to load the training set ot the testing set. Default: True.
下载地址:
https://github.com/facebookresearch/qmnist
作者:
Facebook AI Research
New York University
引用:
Paszke, Adam, et al. "Advances in Neural Information Processing Systems 32." Curran Associates, Inc (2019): 8024-8035.
简介:
由于MNIST完整的测试集(6万)现在已经无法找到,而且当年MNIST数据集的制作方法也找不到了。
所以提出QMNIST,希望能从MNIST的源头NIST SD-19,生成MNIST数据,尽可能的逼近原始MNIST的预处理效果。

USPS
torchvision.datasets.USPS(root: str, train: bool = True, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
Parameters:
root (string) – Root directory of dataset to store``USPS`` data files.
train (bool, optional) – If True, creates dataset from usps.bz2, otherwise from usps.t.bz2.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
Data Structure:
USPS Dataset. The data-format is : [label [index:value ]*256 n] * num_lines, where label lies in [1, 10]. The value for each pixel lies in [-1, 1]. Here we transform the label into [0, 9] and make pixel values in [0, 255].
下载地址:
https://www.kaggle.com/bistaumanga/usps-dataset
简介:
与MNIST类似,包含了10个数字类别,训练集7291,测试集2007,共有9298。图片为16*16的灰度图。
SVHN
torchvision.datasets.SVHN(root: str, split: str = 'train', transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
Parameters:
root (string) – Root directory of dataset where directory SVHN exists.
split (string) – One of {‘train’, ‘test’, ‘extra’}. Accordingly dataset is selected. ‘extra’ is Extra training set.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
Data Structure
SVHN Dataset. Note: The SVHN dataset assigns the label 10 to the digit 0. However, in this Dataset, we assign the label 0 to the digit 0 to be compatible with PyTorch loss functions which expect the class labels to be in the range [0, C-1]

下载地址:
http://ufldl.stanford.edu/housenumbers/
简介:
The Street View House Numbers Dataset (SVHN),包含两类图像,一种是原始实景图+标记框,另一种是类似于MNIST的单个数字图像。
KMNIST
torchvision.datasets.KMNIST(root: str, train: bool = True, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
Parameters:
root (string) – Root directory of dataset where KMNIST/processed/training.pt and KMNIST/processed/test.pt exist.
train (bool, optional) – If True, creates dataset from training.pt, otherwise from test.pt.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
下载地址:
http://codh.rois.ac.jp/kmnist/index.html.en
作者:
"KMNIST Dataset" (created by CODH), adapted from "Kuzushiji Dataset" (created by NIJL and others), doi:10.20676/00000341
引用:
Tarin Clanuwat, Mikel Bober-Irizar, Asanobu Kitamoto, Alex Lamb, Kazuaki Yamamoto, David Ha, "Deep Learning for Classical Japanese Literature", arXiv:1812.01718.
简介:
Kuzushiji-MNIST
28*28的灰度图,共70k张图片,与MNIST结构相同。包含了10个Hiragana字符。21MB+35KB
Kuzushiji-49
28*28的灰度图,共270912张图片,包含了48个Hiragane字符和一个Hiragana迭代符,每类的数量并不相同。74MB+250KB
Kuzushiji-Kanji
64*64的灰度图,共140426张图片,包含了3832个Kanji字符,每类数量并不相同。310MB
Omniglot
torchvision.datasets.Omniglot(root: str, background: bool = True, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
Parameters:
background (bool, optional) – If True, creates dataset from the “background” set, otherwise creates from the “evaluation” set. This terminology is defined by the authors.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
download (bool, optional) – If true, downloads the dataset zip files from the internet and puts it in root directory. If the zip files are already downloaded, they are not downloaded again.
Usage:
Omniglot Dataset. :param root: Root directory of dataset where directory omniglot-py exists.
下载地址:
https://www.kaggle.com/watesoyan/omniglot
简介:
包含了1623种手写字符,来自50个字符表,每种字符由20个不同的人手写。数据集大小为8MB。
Fashion-MNIST
torchvision.datasets.FashionMNIST(root: str, train: bool = True, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
Parameters:
root (string) – Root directory of dataset where FashionMNIST/processed/training.pt and FashionMNIST/processed/test.pt exist.
train (bool, optional) – If True, creates dataset from training.pt, otherwise from test.pt.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.下载地址:
https://www.kaggle.com/zalando-research/fashionmnist
作者:
Zalando Research
简介:
提出Fashion MNIST,是为了代替MNIST成为benchmark。包含了10类,分别为T-shirt/top、Trouser、Pullover、Dress、Coat、Sandal、Shirt、Sneaker、Bag、Ankle boot。与MNIST的数据集划分一样,包含了60k训练集,10k测试集,共70k数据,200MB大小。
CIFAR
torchvision.datasets.CIFAR10(root: str, train: bool = True, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
torchvision.datasets.CIFAR100(root: str, train: bool = True, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
Parameters:
root (string) – Root directory of dataset where directory cifar-10-batches-py exists or will be saved to if download is set to True.
train (bool, optional) – If True, creates dataset from training set, otherwise creates from test set.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
下载地址:
https://www.cs.toronto.edu/~kriz/cifar.html
作者:
Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton
引用:
Learning Multiple Layers of Features from Tiny Images, Alex Krizhevsky, 2009.
简介:
CIFAR10和CIFAR100是 80 million tiny images数据集的子集。
CIFAR10包含了60k 32*32 的彩色图片,一共10类,每类6k图片,其中50k用于训练,分为5个batch,10k用于测试,分为1个batch。Test batch从10类中的每一类随机采样1k。训练集的每个batch中的各个类的数量不一定相同。
CIFAR100包含了60k 32*32 的彩色图片,一共100类,每类600图片,100个小类被划分为20个大类,每张图片包含了两个标签“fine label”表明小类,“coarse label”表明大类。
LSUN
torchvision.datasets.LSUN(root: str, classes: Union[str, List[str]] = 'train', transform: Optional[Callable] = None, target_transform: Optional[Callable] = None)
Parameters:
root (string) – Root directory for the database files.
classes (string or list) – One of {‘train’, ‘val’, ‘test’} or a list of categories to load. e,g. [‘bedroom_train’, ‘church_outdoor_train’].
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
下载地址:
https://www.yf.io/p/lsun
引用:
Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser and Jianxiong Xiao
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
arXiv:1506.03365 [cs.CV], 10 Jun 2015
简介:
利用深度网络辅助人工,对大型数据集进行标注,产生的新数据集。
包含了1million带标签的图像,10个场景类别,20个物体类别。
STL10
torchvision.datasets.STL10(root: str, split: str = 'train', folds: Optional[int] = None, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
Parameters:
root (string) – Root directory of dataset where directory stl10_binary exists.
split (string) – One of {‘train’, ‘test’, ‘unlabeled’, ‘train+unlabeled’}. Accordingly dataset is selected.
folds (int, optional) –
One of {0-9} or None. For training, loads one of the 10 pre-defined folds of 1k samples for the
standard evaluation procedure. If no value is passed, loads the 5k samples.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
下载地址:
https://cs.stanford.edu/~acoates/stl10/
引用:
Adam Coates, Honglak Lee, Andrew Y. Ng An Analysis of Single Layer Networks in Unsupervised Feature Learning AISTATS, 2011.
简介:
用于无监督学习。来自ImageNet,训练集500张,测试集800张,还包括无标签的100k,96*96的彩色图片,一共有10类。相较于CIFAR10,每类只有很少的带标签训练数据。
CelebA
torchvision.datasets.CelebA(root: str, split: str = 'train', target_type: Union[List[str], str] = 'attr', transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = False)
Parameters:
root (string) – Root directory where images are downloaded to.
split (string) – One of {‘train’, ‘valid’, ‘test’, ‘all’}. Accordingly dataset is selected.
target_type (string or list, optional) –
Type of target to use, attr, identity, bbox, or landmarks. Can also be a list to output a tuple with all specified target types. The targets represent:
attr (np.array shape=(40,) dtype=int): binary (0, 1) labels for attributes identity (int): label for each person (data points with the same identity are the same person) bbox (np.array shape=(4,) dtype=int): bounding box (x, y, width, height) landmarks (np.array shape=(10,) dtype=int): landmark points (lefteye_x, lefteye_y, righteye_x,
righteye_y, nose_x, nose_y, leftmouth_x, leftmouth_y, rightmouth_x, rightmouth_y)
Defaults to attr. If empty, None will be returned as target.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.ToTensor
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.下载地址:
http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
作者:
Ziwei Liu, Ping Luo, Xiaogang Wang, Xiaoou Tang
Multimedia Laboratory, The Chinese University of Hong Kong
引用:
Liu, Ziwei, et al. "Deep learning face attributes in the wild." Proceedings of the IEEE international conference on computer vision. 2015.
简介:
包含了200k名人图像,每个图像包含了40个属性标签。
图像涵盖了较大范围的姿势变化和背景杂波。
CelebA具有种类多,数量多,注释丰富的特点。
包含了10,177个身份,202,599张人脸图像,以及5个地标位置。
应用场景:
face attribute recognition
face detection
landmark (or facial part) localization
face editing & synthesis.
Places365
torchvision.datasets.Places365(root: str, split: str = 'train-standard', small: bool = False, download: bool = False, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, loader: Callable[str, Any] = )
Parameters:
root (string) – Root directory of the Places365 dataset.
split (string, optional) – The dataset split. Can be one of train-standard (default), train-challendge, val.
small (bool, optional) – If True, uses the small images, i. e. resized to 256 x 256 pixels, instead of the high resolution ones.
download (bool, optional) – If True, downloads the dataset components and places them in root. Already downloaded archives are not downloaded again.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
loader – A function to load an image given its path.
Raises:
RuntimeError – If download is False and the meta files, i. e. the devkit, are not present or corrupted.
RuntimeError – If download is True and the image archive is already extracted. 
下载地址:
http://places2.csail.mit.edu/challenge.html
引用:
Bolei Zhou, Aditya Khosla, Agata Lapedriza, Antonio Torralba and Aude Oliva
Places: A 10 million Image Database for Scene Recognition.
arXiv:1610.02055
简介:
数据集一共包含了10+million图片,400+场景类别。
挑战赛:训练:8million,验证:36k,测试:328k。包含了365个场景。
训练集中每类场景的样本数量不同。
Cityscapes
torchvision.datasets.Cityscapes(root: str, split: str = 'train', mode: str = 'fine', target_type: Union[List[str], str] = 'instance', transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, transforms: Optional[Callable] = None)
Parameters:
root (string) – Root directory of dataset where directory leftImg8bit and gtFine or gtCoarse are located.
split (string, optional) – The image split to use, train, test or val if mode=”fine” otherwise train, train_extra or val
mode (string, optional) – The quality mode to use, fine or coarse
target_type (string or list, optional) – Type of target to use, instance, semantic, polygon or color. Can also be a list to output a tuple with all specified target types.
transform (callable, optional) – A function/transform that takes in a PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
transforms (callable, optional) – A function/transform that takes input sample and its target as entry and returns a transformed version.
Examples:
Get semantic segmentation target
dataset = Cityscapes('./data/cityscapes', split='train', mode='fine',
target_type='semantic')
img, smnt = dataset[0]
Get multiple targets
dataset = Cityscapes('./data/cityscapes', split='train', mode='fine',
target_type=['instance', 'color', 'polygon'])
img, (inst, col, poly) = dataset[0]
Validate on the “coarse” set
dataset = Cityscapes('./data/cityscapes', split='val', mode='coarse',
target_type='semantic')
img, smnt = dataset[0] 
下载地址:
https://www.cityscapes-dataset.com/dataset-overview/
简介:
Cityscapes数据集专注于城市街景的语义理解。
包含了语义分割,车和人的实例分割,共有30类
包含了50个城市,春、夏、秋多个季节,一天的不同时间段,不同的天气
包含了5k精准标注,和20k粗标注

SBD
torchvision.datasets.SBDataset(root: str, image_set: str = 'train', mode: str = 'boundaries', download: bool = False, transforms: Optional[Callable] = None)
Parameters:
root (string) – Root directory of the Semantic Boundaries Dataset
image_set (string, optional) – Select the image_set to use, train, val or train_noval. Image set train_noval excludes VOC 2012 val images.
mode (string, optional) – Select target type. Possible values ‘boundaries’ or ‘segmentation’. In case of ‘boundaries’, the target is an array of shape [num_classes, H, W], where num_classes=20.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
transforms (callable, optional) – A function/transform that takes input sample and its target as entry and returns a transformed version. Input sample is PIL image and target is a numpy array if mode=’boundaries’ or PIL image if mode=’segmentation’.
NOTE:
Please note that the train and val splits included with this dataset are different from the splits in the PASCAL VOC dataset. In particular some “train” images might be part of VOC2012 val. If you are interested in testing on VOC 2012 val, then use image_set=’train_noval’, which excludes all val images.
下载地址:
http://home.bharathh.info/pubs/codes/SBD/download.html
作者:
Tomas F. Yago Vicente, Le Hou, Chen-Ping Yu, Minh Hoai, and Dimitris Samaras
引用:
Bharath Hariharan, Pablo Arbelaez, Lubomir Bourdev, Subhransu Maji and Jitendra Malik. Semantic contours from inverse detectors. In International Conference on Computer Vision, 2011.
简介:
11355张图片来自PASCAL VOC 2011 数据集。包含了类别和实例的分割,类别位VOC2011的20类。
Flickr
torchvision.datasets.Flickr8k(root: str, ann_file: str, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None)
torchvision.datasets.Flickr30k(root: str, ann_file: str, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None)
Parameters:
root (string) – Root directory where images are downloaded to.
ann_file (string) – Path to annotation file.
transform (callable, optional) – A function/transform that takes in a PIL image and returns a transformed version. E.g, transforms.ToTensor
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
下载地址:
https://www.kaggle.com/hsankesara/flickr-image-dataset
简介:
Flickr30k是基于语句的图像描述任务的基准。
包含了158k字幕,244k coreference chains,276k标注框。
这个任务包含了image-text embedding, detectors for common objects, color classifier, bias towards selecting larger objects.
Flickr8k包含了8092张图像,每个图像5个字幕。
HMDB51
torchvision.datasets.HMDB51(root, annotation_path, frames_per_clip, step_between_clips=1, frame_rate=None, fold=1, train=True, transform=None, _precomputed_metadata=None, num_workers=1, _video_width=0, _video_height=0, _video_min_dimension=0, _audio_samples=0)
Parameters:
root (string) – Root directory of the HMDB51 Dataset.
annotation_path (str) – Path to the folder containing the split files.
frames_per_clip (int) – Number of frames in a clip.
step_between_clips (int) – Number of frames between each clip.
fold (int, optional) – Which fold to use. Should be between 1 and 3.
train (bool, optional) – If True, creates a dataset from the train split, otherwise from the test split.
transform (callable, optional) – A function/transform that takes in a TxHxWxC video and returns a transformed version.
Introduction:
HMDB51 is an action recognition video dataset. This dataset consider every video as a collection of video clips of fixed size, specified by frames_per_clip, where the step in frames between each clip is given by step_between_clips.
To give an example, for 2 videos with 10 and 15 frames respectively, if frames_per_clip=5 and step_between_clips=5, the dataset size will be (2 + 3) = 5, where the first two elements will come from video 1, and the next three elements from video 2. Note that we drop clips which do not have exactly frames_per_clip elements, so not all frames in a video might be present.
Internally, it uses a VideoClips object to handle clip creation.下载:
https://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/#Downloads
引用:
The benchmark and database are described in the following article. We request that authors cite this paper in publications describing work carried out with this system and/or the video database.
H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre. HMDB: A Large Video Database for Human Motion Recognition. ICCV, 2011.
The first benchmark STIP features are described in the following paper and we request the authors cite this paper if they use STIP features.
I. Laptev, M. Marszalek, C. Schmid, and B. Rozenfeld. Learning Realistic Human Actions From Movies. CVPR, 2008.
The second benchmark C2 features are described in the following paper and we request the authors cite this paper if they use C2 codes.
H. Jhuang, T. Serre, L. Wolf, and T. Poggio. A Biologically Inspired System for Action Recognition. ICCV, 2007.
简介:
HMDB51,大约2GB,7k短片,51个动作类别,每个类最少101个短片。
动作分为五种类型:
1. 一般的面部动作微笑,大笑,咀嚼,交谈。
2. 通过物体操纵进行面部动作:吸烟,进食,饮水。
3. 全身动作:车轮,拍手,攀爬,爬楼梯,潜水,掉在地板上,反手翻转,倒立,跳跃,向上拉,向上推,奔跑,坐下,坐下,翻筋斗,站起来,转身,步行,波。
4. 与物体互动的身体动作:刷头发,抓,拔剑,运球,打高尔夫球,击球,踢球,接球,倒球,推东西,骑自行车,骑马,射击球,射击弓箭,射击枪,挥杆棒球棒,剑术,扔。
5. 与人体互动的身体动作:击剑,拥抱,踢人,亲吻,拳打,握手,打剑。
Kinetics-400
torchvision.datasets.Kinetics400(root, frames_per_clip, step_between_clips=1, frame_rate=None, extensions=('avi', ), transform=None, _precomputed_metadata=None, num_workers=1, _video_width=0, _video_height=0, _video_min_dimension=0, _audio_samples=0, _audio_channels=0)
Parameters:
root (string) – Root directory of the Kinetics-400 Dataset.
frames_per_clip (int) – number of frames in a clip
step_between_clips (int) – number of frames between each clip
transform (callable, optional) – A function/transform that takes in a TxHxWxC video and returns a transformed version.
Introduction:
Kinetics-400 is an action recognition video dataset. This dataset consider every video as a collection of video clips of fixed size, specified by frames_per_clip, where the step in frames between each clip is given by step_between_clips.
To give an example, for 2 videos with 10 and 15 frames respectively, if frames_per_clip=5 and step_between_clips=5, the dataset size will be (2 + 3) = 5, where the first two elements will come from video 1, and the next three elements from video 2. Note that we drop clips which do not have exactly frames_per_clip elements, so not all frames in a video might be present.
Internally, it uses a VideoClips object to handle clip creation.下载地址:
https://deepmind.com/research/open-source/kinetics
作者:
Deepmind
简介:
650k视频短片的URL,包含了400/600/700种人类动作,每类动作至少包含400/600/700个视频短片。
每个短片只有一个动作标签,大约10s时长。
UCF101
torchvision.datasets.UCF101(root, annotation_path, frames_per_clip, step_between_clips=1, frame_rate=None, fold=1, train=True, transform=None, _precomputed_metadata=None, num_workers=1, _video_width=0, _video_height=0, _video_min_dimension=0, _audio_samples=0)
Parameters:
root (string) – Root directory of the UCF101 Dataset.
annotation_path (str) – path to the folder containing the split files
frames_per_clip (int) – number of frames in a clip.
step_between_clips (int, optional) – number of frames between each clip.
fold (int, optional) – which fold to use. Should be between 1 and 3.
train (bool, optional) – if True, creates a dataset from the train split, otherwise from the test split.
transform (callable, optional) – A function/transform that takes in a TxHxWxC video and returns a transformed version.
Introduction:
UCF101 is an action recognition video dataset. This dataset consider every video as a collection of video clips of fixed size, specified by frames_per_clip, where the step in frames between each clip is given by step_between_clips.
To give an example, for 2 videos with 10 and 15 frames respectively, if frames_per_clip=5 and step_between_clips=5, the dataset size will be (2 + 3) = 5, where the first two elements will come from video 1, and the next three elements from video 2. Note that we drop clips which do not have exactly frames_per_clip elements, so not all frames in a video might be present.
Internally, it uses a VideoClips object to handle clip creation.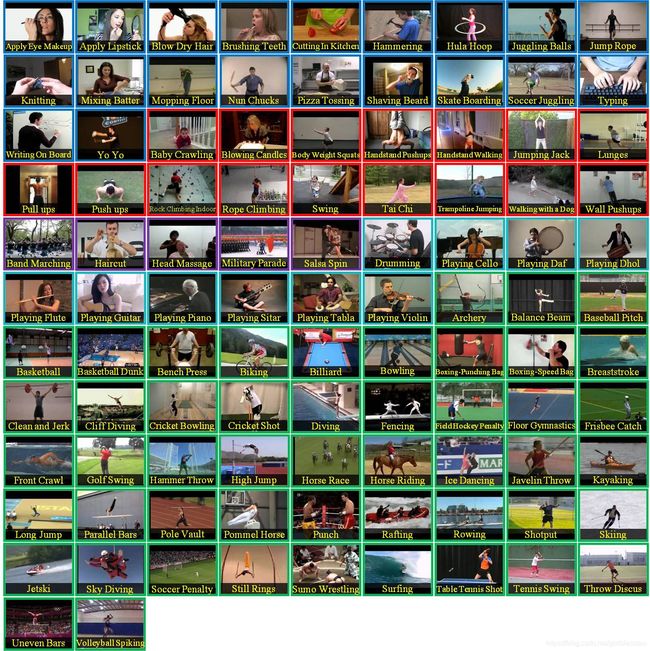
下载地址:
https://www.crcv.ucf.edu/data/UCF101.php
作者:
University of Central Florida, Center for Research in Computer Vision
引用:
Khurram Soomro, Amir Roshan Zamir and Mubarak Shah, UCF101: A Dataset of 101 Human Action Classes From Videos in The Wild, CRCV-TR-12-01, November, 2012.
简介:
视频动作检测,包含了101类动作(分为25组,每类包含4到7个视频),13320个短片
PhotoTour
torchvision.datasets.PhotoTour(root: str, name: str, train: bool = True, transform: Optional[Callable] = None, download: bool = False)
Parameters:
root (string) – Root directory where images are.
name (string) – Name of the dataset to load.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version.
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
下载地址:
http://phototour.cs.washington.edu/datasets/
引用:
Fisher Yu, Ari Seff, Yinda Zhang, Shuran Song, Thomas Funkhouser and Jianxiong Xiao
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
arXiv:1506.03365 [cs.CV], 10 Jun 2015
简介:
用于3D重构。数据集包含了一组Flickr的图像和重构数据。
包含了715张图片的巴黎圣母院大教堂重构。
SBU
torchvision.datasets.SBU(root: str, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, download: bool = True)
Parameters:
root (string) – Root directory of dataset where tarball SBUCaptionedPhotoDataset.tar.gz exists.
transform (callable, optional) – A function/transform that takes in a PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
download (bool, optional) – If True, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
下载地址:
https://www3.cs.stonybrook.edu/~cvl/projects/shadow_noisy_label/index.html
作者:
Tomas F. Yago Vicente, Le Hou, Chen-Ping Yu, Minh Hoai, and Dimitris Samaras
引用:
Large-scale Training of Shadow Detectors with Noisily-Annotated Shadow Examples, Vicente, T.F.Y., Hou, L., Yu, C.-P., Hoai, M., Samaras, D., Proceedings of European Conference on Computer Vision (ECCV), 2016.
简介:
阴影检测。
ImageNet
torchvision.datasets.ImageNet(root: str, split: str = 'train', download: Optional[str] = None, **kwargs: Any)
Parameters:
root (string) – Root directory of the ImageNet Dataset.
split (string, optional) – The dataset split, supports train, or val.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
loader – A function to load an image given its path.
Introduction:
ImageNet 2012 Classification Dataset.
下载地址:
http://image-net.org/index
引用:
Olga Russakovsky*, Jia Deng*, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg and Li Fei-Fei. (* = equal contribution) ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015.
简介:
Imagenet Large Scale Visual Recognition Challenge, ILSVRC 2010-2017
每一年基本包含了image classification, object localization, object detection。Pytorch只包含了2012年的图像分类数据集。
详细情况太多,请自行到官网查看。
VOC
torchvision.datasets.VOCSegmentation(root: str, year: str = '2012', image_set: str = 'train', download: bool = False, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, transforms: Optional[Callable] = None)
Parameters:
root (string) – Root directory of the VOC Dataset.
year (string, optional) – The dataset year, supports years 2007 to 2012.
image_set (string, optional) – Select the image_set to use, train, trainval or val
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
transforms (callable, optional) – A function/transform that takes input sample and its target as entry and returns a transformed version.torchvision.datasets.VOCDetection(root: str, year: str = '2012', image_set: str = 'train', download: bool = False, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, transforms: Optional[Callable] = None)
Parameters:
root (string) – Root directory of the VOC Dataset.
year (string, optional) – The dataset year, supports years 2007 to 2012.
image_set (string, optional) – Select the image_set to use, train, trainval or val
download (bool, optional) – If true, downloads the dataset from the internet and puts it in root directory. If dataset is already downloaded, it is not downloaded again. (default: alphabetic indexing of VOC’s 20 classes).
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, required) – A function/transform that takes in the target and transforms it.
transforms (callable, optional) – A function/transform that takes input sample and its target as entry and returns a transformed version.
下载地址:
http://host.robots.ox.ac.uk/pascal/VOC/
作者:
Mark Everingham (University of Leeds)
Luc van Gool (ETHZ, Zurich)
Chris Williams (University of Edinburgh)
John Winn (Microsoft Research Cambridge)
Andrew Zisserman (University of Oxford)
简介:
VOC 2005-2012 Challenge,包含了classification和detection,segementation
COCO
torchvision.datasets.CocoCaptions(root: str, annFile: str, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, transforms: Optional[Callable] = None)
Parameters:
root (string) – Root directory where images are downloaded to.
annFile (string) – Path to json annotation file.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.ToTensor
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
transforms (callable, optional) – A function/transform that takes input sample and its target as entry and returns a transformed version.torchvision.datasets.CocoDetection(root: str, annFile: str, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, transforms: Optional[Callable] = None)
Parameters:
root (string) – Root directory where images are downloaded to.
annFile (string) – Path to json annotation file.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.ToTensor
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
transforms (callable, optional) – A function/transform that takes input sample and its target as entry and returns a transformed version.下载地址:
https://cocodataset.org/#home
简介:
COCO是一个大型数据集,包含了目标检测,图像分割,图像解释等。详细信息请到官网查看。
FakeData
torchvision.datasets.FakeData(size: int = 1000, image_size: Tuple[int, int, int] = (3, 224, 224), num_classes: int = 10, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, random_offset: int = 0)
Parameters:
size (int, optional) – Size of the dataset. Default: 1000 images
image_size (tuple, optional) – Size if the returned images. Default: (3, 224, 224)
num_classes (int, optional) – Number of classes in the datset. Default: 10
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
random_offset (int) – Offsets the index-based random seed used to generate each image. Default: 0
Introduction:
A fake dataset that returns randomly generated images and returns them as PIL images该函数可以随机产生图片。
DatasetFolder
torchvision.datasets.DatasetFolder(root: str, loader: Callable[str, Any], extensions: Optional[Tuple[str, ...]] = None, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, is_valid_file: Optional[Callable[str, bool]] = None)
Parameters:
root (string) – Root directory path.
loader (callable) – A function to load a sample given its path.
extensions (tuple[string]) – A list of allowed extensions. both extensions and is_valid_file should not be passed.
transform (callable, optional) – A function/transform that takes in a sample and returns a transformed version. E.g, transforms.RandomCrop for images.
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
is_valid_file – A function that takes path of a file and check if the file is a valid file (used to check of corrupt files) both extensions and is_valid_file should not be passed.
Introduction:
A generic data loader where the samples are arranged in this way:
root/class_x/xxx.ext
root/class_x/xxy.ext
root/class_x/xxz.ext
root/class_y/123.ext
root/class_y/nsdf3.ext
root/class_y/asd932_.ext该函数是一个通用数据加载器。可以加载各种类型的数据,比如图像、文本等。
ImageFolder
torchvision.datasets.ImageFolder(root: str, transform: Optional[Callable] = None, target_transform: Optional[Callable] = None, loader: Callable[str, Any] = , is_valid_file: Optional[Callable[str, bool]] = None)
Parameters:
root (string) – Root directory path.
transform (callable, optional) – A function/transform that takes in an PIL image and returns a transformed version. E.g, transforms.RandomCrop
target_transform (callable, optional) – A function/transform that takes in the target and transforms it.
loader (callable, optional) – A function to load an image given its path.
is_valid_file – A function that takes path of an Image file and check if the file is a valid file (used to check of corrupt files)
Introduction:
A generic data loader where the images are arranged in this way:
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png 该函数是一个通用图像加载器。可以加载各类型的图像数据。