基础夯实:基础数据结构与算法(二)
基础夯实:基础数据结构与算法(二)
- 常见的10种算法
-
- 1、递归算法
-
- 例题1:计算n!
- 例题2:斐波那契数列
- 例题3:递归将整形数字转换为字符串
- 例题4:汉诺塔
- 例题5:猴子吃桃
- 例题6:N皇后问题
- 2、排序算法
-
- 冒泡排序:
- 快速排序:
- 3、二分查找算法
- 4、搜索算法
- 5、哈希算法
- 6、贪心算法
- 7、分治算法
-
- 求x的n次幂
- 归并排序
- 8、回溯算法
- 9、动态规划(DP)算法
- 10、字符串匹配算法
- 参考文献
上一章我们说了常见的10种数据结构,接下来我们说常见的10种算法。
上一章地址:基础夯实:基础数据结构与算法(一),不怎么清楚的可以去瞅瞅。
常见的10种算法
数据结构研究的内容:就是如何按一定的逻辑结构,把数据组织起来,并选择适当的存储表示方法把逻辑结构组织好的数据存储到计算机的存储器里。
算法研究的目的是为了更有效的处理数据,提高数据运算效率。数据的运算是定义在数据的逻辑结构上,但运算的具体实现要在存储结构上进行。
一般有以下几种常用运算:
- 检索:检索就是在数据结构里查找满足一定条件的节点。一般是给定一个某字段的值,找具有该字段值的节点。
- 插入:往数据结构中增加新的节点。
- 删除:把指定的结点从数据结构中去掉。
- 更新:改变指定节点的一个或多个字段的值。
- 排序:把节点按某种指定的顺序重新排列。例如递增或递减。
1、递归算法
递归算法:是一种直接或者间接地调用自身的算法。在计算机编写程序中,递归算法对解决一大类问题是十分有效的,它往往使算法的描述简洁而且易于理解。
递归过程一般通过函数或子过程来实现。
递归算法的实质:是把问题转化为规模缩小了的同类问题的子问题。然后递归调用函数(或过程)来表示问题的解。
递归算法解决问题的特点:
- 递归就是在过程或函数里调用自身。
- 在使用递归策略时,必须有一个明确的递归结束条件,称为递归出口。
- 递归算法解题通常显得很简洁,但递归算法解题的运行效率较低。所以一般不提倡用递归算法设计程序。
- 在递归调用的过程当中系统为每一层的返回点、局部量等开辟了栈来存储。递归次数过多容易造成栈溢出等。所以一般不提倡用递归算法设计程序。
下面来详细分析递归的工作原理。
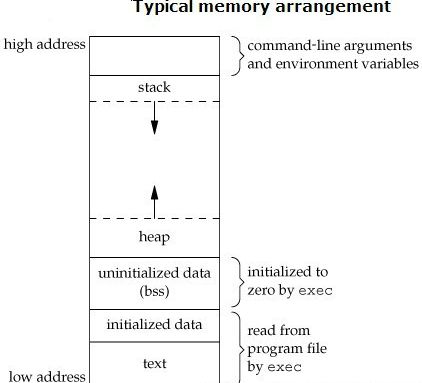
先看看C语言中函数的执行方式,需要了解一些关于C程序在内存中的组织方式:
堆的增长方向为从低地址到高地址向上增长,而栈的增长方向刚好相反(实际情况与CPU的体系结构有关)。
当C程序中调用了一个函数时,栈中会分配一块空间来保存与这个调用相关的信息,每一个调用都被当作是活跃的。
栈上的那块存储空间称为活跃记录或者栈帧。
栈帧由5个区域组成:输入参数、返回值空间、计算表达式时用到的临时存储空间、函数调用时保存的状态信息以及输出参数,参见下图:
栈是用来存储函数调用信息的绝好方案,然而栈也有一些缺点:
栈维护了每个函数调用的信息直到函数返回后才释放,这需要占用相当大的空间,尤其是在程序中使用了许多的递归调用的情况下。
除此之外,因为有大量的信息需要保存和恢复,因此生成和销毁活跃记录需要消耗一定的时间。
我们需要考虑采用迭代的方案。幸运的是我们可以采用一种称为尾递归的特殊递归方式来避免前面提到的这些缺点。
例题1:计算n!
计算n的阶乘,数学上的计算公式为:
n!=n×(n-1)×(n-2)……2×1
使用递归的方式,可以定义为:

以递归方式实现阶乘函数的实现:
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include 
例题2:斐波那契数列
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include 例题3:递归将整形数字转换为字符串
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include 例题4:汉诺塔
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include 例题5:猴子吃桃
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include 例题6:N皇后问题
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include 2、排序算法

排序是程序设计中常做的操作,初学者往往只知道冒泡排序算法,其实还有很多效率更高的排序算法,比如希尔排序、快速排序、基数排序、归并排序等。
不同的排序算法,适用于不同的场景,本章最后从时间性能,算法稳定性等方面,分析各种排序算法。
排序算法,还分为内部排序算法和外部排序算法,之间的区别是,前者在内存中完成排序,而后者则需要借助外部存储器。
这里介绍的是内部排序算法。
冒泡排序:
起泡排序,别名“冒泡排序”,该算法的核心思想是将无序表中的所有记录,通过两两比较关键字,得出升序序列或者降序序列。
例如,对无序表{49,38,65,97,76,13,27,49}进行升序排序的具体实现过程如图 1 所示:

如下冒泡排序例子
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include 快速排序:
快速排序算法是在起泡排序的基础上进行改进的一种算法,
其实现的基本思想是:通过一次排序将整个无序表分成相互独立的两部分,其中一部分中的数据都比另一部分中包含的数据的值小,然后继续沿用此方法分别对两部分进行同样的操作,
直到每一个小部分不可再分,所得到的整个序列就成为了有序序列。

该操作过程的具体实现代码为:
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include 更多点击 排序算法:http://data.biancheng.net/sort/ (插入排序算法、快速排序算法、选择排序算法、归并排序和基数排序等)
3、二分查找算法
二分査找就是折半查找,
其基本思想是:首先选取表中间位置的记录,将其关键字与给定关键字 key 进行比较,若相等,则査找成功;
若 key 值比该关键字值大,则要找的元素一定在右子表中,则继续对右子表进行折半查找;
若 key 值比该关键宇值小,则要找的元素一定在左子表中,继续对左子表进行折半査找。
如此递推,直到査找成功或査找失败(或査找范围为 0)。
例如:
要求用户输入数组长度,也就是有序表的数据长度,并输入数组元素和査找的关键字。
程序输出查找成功与否,以及成功时关键字在数组中的位置。
例如,在有序表 11、13、18、 28、39、56、69、89、98、122 中査找关键字为 89 的元素。
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include 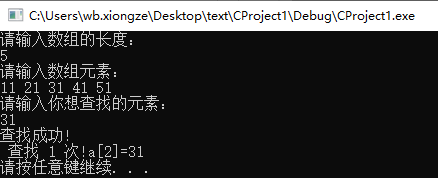
4、搜索算法
搜索算法是利用计算机的高性能来有目的的穷举一个问题解空间的部分或所有的可能情况,从而求出问题的解的一种方法。
现阶段一般有枚举算法、深度优先搜索、广度优先搜索、A*算法、回溯算法、蒙特卡洛树搜索、散列函数等算法。
在大规模实验环境中,通常通过在搜索前,根据条件降低搜索规模;
根据问题的约束条件进行剪枝;利用搜索过程中的中间解,避免重复计算这几种方法进行优化。
这里介绍的是深度优先搜索,感兴趣的可以百度查询更多搜索算法。
内容很多,大家可以百度查询感兴趣的用法:也可以点击 深度优先搜索 查看更多。
深度优先搜索
- 深度优先遍历首先访问出发点v,并将其标记为已访问过;然后依次从v出发搜索v的每个邻接点w。若w未曾访问过,则以w为新的出发点继续进行深度优先遍历,直至图中所有和源点v有路径相通的顶点均已被访问为止。
- 若此时图中仍有未访问的顶点,则另选一个尚未访问的顶点作为新的源点重复上述过程,直至图中所有顶点均已被访问为止。
深度搜索与广度搜索的相近,最终都要扩展一个结点的所有子结点.
区别在于对扩展结点过程,深度搜索扩展的是E-结点的邻接结点中的一个,并将其作为新的E-结点继续扩展,当前E-结点仍为活结点,待搜索完其子结点后,回溯到该结点扩展它的其它未搜索的邻接结点。
而广度搜索,则是扩展E-结点的所有邻接结点,E-结点就成为一个死结点。
5、哈希算法
1. 什么是哈希
Hash,一般翻译做散列、杂凑,或音译为哈希,是一个典型的利用空间换取时间的算法,把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。
如有一个学生信息表:
学生的学号为:年纪+学院号+班级号+顺序排序号【如:19(年纪)+002(2号学院)+01(一班)+17(17号)—à190020117】类似于一个这样的信息,
当我们需要找到这个学号为【190020117】的学生,在不适用哈希的时候,我们通常是使用一个顺序遍历的方式在数据中进行查询大类,再查询子类得到,
这样的作法很明显不够快 ,需要O(n)左右的时间花费,对于大型的数据规模而言这显然不行,
而哈希的做法是,根据一定的规律(比如说年纪不存在过老和过小的情况,以此将【190020117】进行压缩成一个简短的数据如:
【192117】)并且将这个数据直接作用于内存的地址,届时我们查询【190020117】只需要进行一次压缩并访问【192117】这个地址即可,而这个压缩的方法(函数),就可以称之为哈希函数。
一般的对于哈希函数需要考虑如下内容:
计算散列地址所需要的时间(即hash函数本身不要太复杂)
关键字的长度
表长(不宜过长或过短,避免内存浪费和算力消耗)
关键字分布是否均匀,是否有规律可循
设计的hash函数在满足以上条件的情况下尽量减少冲突
2.哈希与哈希表
在理解了哈希的思维之后,我们要了解什么是哈希表,哈希表顾名思义就是经过哈希函数进行转换后的一张表,
通过访问哈希表,我们可以快速查询哈希表,从而得出所需要得到的数据,构建哈希表的核心就是要考虑哈希函数的冲突处理(即经过数据压缩之后可能存在多数据同一个地址,需要利用算法将冲突的数据分别存储)。
冲突处理的方法有很多,最简单的有+1法,即地址数直接+1,当两个数据都需要存储进【2019】时,可以考虑将其中的一个存进【2020】
此外还有,开放定址法,链式地址发,公共溢出法,再散列法,质数法等等,各方法面对不同的数据特征有不同的效果。
3.哈希的思维
Hash算法是一个广义的算法,也可以认为是一种思想,使用Hash算法可以提高存储空间的利用率,可以提高数据的查询效率,也可以做数字签名来保障数据传递的安全性。
所以Hash算法被广泛地应用在互联网应用中。
比如,利用哈希的思维在O(1)的复杂度情况下任意查询1000以内所有的质数(在创建是否是质数的时候并不是O(1)的复杂度),
注意本样例只是演示思维,面对本需求可以有更好的空间利用方式(本写法比较浪费空间,仅供了解)。
如下例子:
【电话聊天狂人】
给定大量手机用户通话记录,找出其中通话次数最多的聊天狂人。
输入格式:
输入首先给出正整数N(≤105),为通话记录条数。随后N行,每行给出一条通话记录。简单起见,这里只列出拨出方和接收方的11位数字构成的手机号码,其中以空格分隔。
输出格式:
在一行中给出聊天狂人的手机号码及其通话次数,其间以空格分隔。如果这样的人不唯一,则输出狂人中最小的号码及其通话次数,并且附加给出并列狂人的人数。
输入样例:
4
13005711862 13588625832
13505711862 13088625832
13588625832 18087925832
15005713862 13588625832
输出样例:
13588625832 3
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include 6、贪心算法
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。
也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解。
贪心算法不是对所有问题都能得到整体最优解,但对范围相当广泛的许多问题他能产生整体最优解或者是整体最优解的近似解。
贪心算法的基本思路是从问题的某一个初始解出发一步一步地进行,根据某个优化测度,每一步都要确保能获得局部最优解。每一步只考虑一个数据,他的选取应该满足局部优化的条件,直到把所有数据枚举完。
贪心算法的思想如下:
建立数学模型来描述问题;
把求解的问题分成若干个子问题;
对每一子问题求解,得到子问题的局部最优解;
把子问题的解局部最优解合成原来解问题的一个解。
与动态规划不同的是,贪心算法得到的是一个局部最优解(即有可能不是最理想的),而动态规划算法得到的是一个全局最优解(即必须是整体而言最理想的),
一个有趣的事情是,动态规划中的01背包问题就是一个典型的贪心算法问题。
如下例子: 贪心算法货币统计问题
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include 
7、分治算法
分治算法的基本思想是将一个规模为N的问题分解为K个规模较小的子问题,这些子问题相互独立且与原问题性质相同。
求出子问题的解,就可得到原问题的解。即一种分目标完成程序算法,简单问题可用二分法完成。
求x的n次幂
复杂度为 O(lgn)
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include "stdio.h"
#include "stdlib.h"
int power(int x, int n)
{
int result;
if (n == 1)
return x;
if (n % 2 == 0)
result = power(x, n / 2) * power(x, n / 2);
else
result = power(x, (n + 1) / 2) * power(x, (n - 1) / 2);
return result;
}
void main()
{
int x = 5;
int n = 3;
printf("power(%d,%d) = %d \n", x, n, power(x, n));
system("PAUSE");//结束不退出
}
归并排序
时间复杂度是O(NlogN)O(NlogN),空间复制度为O(N)O(N)(归并排序的最大缺陷)
归并排序(Merge Sort)完全遵循上述分治法三个步骤:
- 分解:将要排序的n个元素的序列分解成两个具有n/2个元素的子序列;
- 解决:使用归并排序分别递归地排序两个子序列;
- 合并:合并两个已排序的子序列,产生原问题的解。
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include "stdio.h"
#include "stdlib.h"
#include "assert.h"
#include "string.h"
void print_arr(int *arr, int len)
{
int i = 0;
for (i = 0; i < len; i++)
printf("%d ", arr[i]);
printf("\n");
}
void merge(int *arr, int low, int mid, int hight, int *tmp)
{
assert(arr && low >= 0 && low <= mid && mid <= hight);
int i = low;
int j = mid + 1;
int index = 0;
while (i <= mid && j <= hight)
{
if (arr[i] <= arr[j])
tmp[index++] = arr[i++];
else
tmp[index++] = arr[j++];
}
while (i <= mid) //拷贝剩下的左半部分
tmp[index++] = arr[i++];
while (j <= hight) //拷贝剩下的右半部分
tmp[index++] = arr[j++];
memcpy((void *)(arr + low), (void *)tmp, (hight - low + 1) * sizeof(int));
}
void mergesort(int *arr, int low, int hight, int *tmp)
{
assert(arr && low >= 0);
int mid;
if (low < hight)
{
mid = (hight + low) >> 1;
mergesort(arr, low, mid, tmp);
mergesort(arr, mid + 1, hight, tmp);
merge(arr, low, mid, hight, tmp);
}
}
//只分配一次内存,避免内存操作开销
void mergesort_drive(int *arr, int len)
{
int *tmp = (int *)malloc(len * sizeof(int));
if (!tmp)
{
printf("out of memory\n");
exit(0);
}
mergesort(arr, 0, len - 1, tmp);
free(tmp);
}
void main()
{
int data[10] = { 8, 7, 2, 6, 9, 10, 3, 4, 5, 1 };
int len = sizeof(data) / sizeof(data[0]);
mergesort_drive(data, len);
print_arr(data, len);
system("PAUSE");//结束不退出
}
还有更多例子可以百度,这里就不一一举例了。
8、回溯算法
回溯算法,又称为“试探法”。解决问题时,每进行一步,都是抱着试试看的态度,如果发现当前选择并不是最好的,或者这么走下去肯定达不到目标,立刻做回退操作重新选择。
这种走不通就回退再走的方法就是回溯算法。
例如,在解决列举集合 {1,2,3} 中所有子集的问题中,就可以使用回溯算法。
从集合的开头元素开始,对每个元素都有两种选择:取还是舍。当确定了一个元素的取舍之后,再进行下一个元素,直到集合最后一个元素。
其中的每个操作都可以看作是一次尝试,每次尝试都可以得出一个结果。将得到的结果综合起来,就是集合的所有子集。
#define _CRT_SECURE_NO_WARNINGS //避免scanf报错
#include 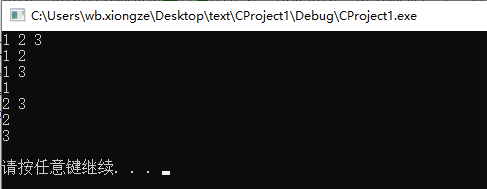
很多人认为回溯和递归是一样的,其实不然。在回溯法中可以看到有递归的身影,但是两者是有区别的。
回溯法从问题本身出发,寻找可能实现的所有情况。和穷举法的思想相近,不同在于穷举法是将所有的情况都列举出来以后再一一筛选,而回溯法在列举过程如果发现当前情况根本不可能存在,就停止后续的所有工作,返回上一步进行新的尝试。
递归是从问题的结果出发,例如求 n!,要想知道 n!的结果,就需要知道 n*(n-1)! 的结果,而要想知道 (n-1)! 结果,就需要提前知道 (n-1)*(n-2)!。这样不断地向自己提问,不断地调用自己的思想就是递归。
使用回溯法解决问题的过程,实际上是建立一棵“状态树”的过程。
例如,在解决列举集合{1,2,3}所有子集的问题中,对于每个元素,都有两种状态,取还是舍,所以构建的状态树为:

回溯算法的求解过程实质上是先序遍历“状态树”的过程。树中每一个叶子结点,都有可能是问题的答案。图 1 中的状态树是满二叉树,得到的叶子结点全部都是问题的解。
在某些情况下,回溯算法解决问题的过程中创建的状态树并不都是满二叉树,因为在试探的过程中,有时会发现此种情况下,
再往下进行没有意义,所以会放弃这条死路,回溯到上一步。在树中的体现,就是在树的最后一层不是满的,即不是满二叉树,需要自己判断哪些叶子结点代表的是正确的结果。
9、动态规划(DP)算法
动态规划过程:每一次决策依赖于当前的状态,即下一状态的产生取决于当前状态。一个决策序列就是在变化的状态中产生的,这种多阶段最优化问题的求解过程就是动态规则过程。
基本思想原理
与分而治之原理类似,将待求解的问题划分成若干个子问题(阶段)求解,顺序求解各个子问题(阶段),前一子问题(阶段)为后一子问题(阶段)的求解提供有用的信息。
通过各个子问题(阶段)的求解,依次递进,最终得到初始问题的解。一般情况下,能够通过动态规划求解的问题也可通过递归求解。
动态规划求解的问题多数有重叠子问题的特点,为了减少重复计算,对每个子问题只求解一次,将不同子问题(阶段)的解保存在数组中。
与分而治之的区别:
分而治之得到的若干子问题(阶段)一般彼此独立,各个子问题(阶段)之间没有顺序要求。而动态规划中各子问题(阶段)求解有顺序要求,具有重叠子问题(阶段),后一子问题(阶段)求解取决于前一子问题(阶段)的解。
与递归区别:
与递归求解区别不大,都是划分成各个子问题(阶段),后一子问题(阶段)取决于前一子问题(阶段),但递归需要反复求解同一个子问题(阶段),相较于动态规划做了很多重复性工作。
适用解决问题
采用动态规划求解的问题一般具有如下性质:
- 最优化原理:求解问题包含最优子结构,即,可由前一子问题(阶段)最优推导得出后一子问题(阶段)最优解,递进得到初始问题的最优解。
- 无后效性:某状态以后的过程不会影响以前的状态,只与当前状态有关。
- 有重叠子问题:子问题(阶段)之间不是独立的,一个子问题(阶段)的解在下一子问题(阶段)中被用到。(不是必需的条件,但是动态规划优于其他方法的基础)
比如斐波那契数列,就是一个简单的例子。
定义:
Fab(n)= Fab(n-1)+Fab(n-2)
Fab(1)=Fab(2)=1;
实现1:
static int GetFab(int n)
{
if (n == 1) return 1;
if (n == 2) return 1;
return GetFab(n - 1) + GetFab(n - 2);
}
假如我们求Fab(5) 。那我们需要求Fab(4) +Fab(3)。
Fab(4)=Fab(3)+Fab(2)…显然。 Fab(3)被计算机不加区别的计算了两次。而且随着数字的增大,计算量是指数增长的。
如果我们使用一个数组,记录下Fab的值。当Fab(n)!=null 时。
直接读取。那么,我们就能把时间复杂度控制在 n 以内。
实现2:
static int[] fab = new int[6];
static int GetFabDynamic(int n)
{
if (n == 1) return fab[1] = 1;
if (n == 2) return fab[2] = 1;
if (fab[n] != 0)//如果存在,就直接返回。
{
return fab[n];
}
else //如果不存在,就进入递归,并且记录下求得的值。
{
return fab[n] = GetFabDynamic(n - 1) + GetFabDynamic(n - 2);
}
}
这就是,动态规划算法的 备忘录模式。只需要把原来的递归稍微修改就行了。
下面是0-1背包问题的解法。
可以对比一下。(一个限重w的背包,有许多件物品。sizes[n]保存他们的重量。values[n]保存它们的价值。求不超重的情况下背包能装的最大价值)
static int[] size = new int[] { 3, 4, 7, 8, 9 };// 5件物品每件大小分别为3, 4, 7, 8, 9 且是不可分割的 0-1 背包问题
static int[] values = new int[] { 4, 5, 10, 11, 13 }; 5件物品每件的价值分别为4, 5, 10, 11, 13
static int capacity = 16;
static int[,] dp = new int[6, capacity + 1];
static int knapsack(int n, int w)
{
if (w < 0) return -10000;
if (n == 0) return 0;
if (dp[n, w] != 0)
{
return dp[n, w];
}
else
{
return dp[n, w] = Math.Max(knapsack(n - 1, w), knapsack(n - 1, w - size[n - 1]) + values[n - 1]);
/*
* knapsack(n,w) 指在前N件物品在W剩余容量下的最大价值。
* 这个公式的意思是,对于某一件物品,
* 1、如果选择装进去,那么,当前价值=前面的n-1件物品在空位w - size(n)下的最大价值(因为空位需要留出,空位也隐含了价值)。
* 再加上这件物品的价值。等于 knapsack(n - 1, w - size[n - 1]) + values[n - 1]
* 2、 如果我们选择不装进去,那么,在n-1物品的情况下空位仍然在,当前价值 = 前面n-1件物品在空位w下的最大价值。
* 等于knapsack(n - 1, w)
* 注意:随着演算,某一情况下的价值不会一成不变。
* 此时我们做出决策:到底是在装入时的价值大,还是不装入时的价值大呢?我们选择上面两种情况中值较大的。并记录在案。
* 最后dp[N,M]就是我们要求的值。
*/ }
}
10、字符串匹配算法
字符串匹配问题的形式定义:
- 文本(Text)是一个长度为 n 的数组 T[1…n];
- 模式(Pattern)是一个长度为 m 且 m≤n 的数组 P[1…m];
- T 和 P 中的元素都属于有限的字母表 Σ 表;
- 如果 0≤s≤n-m,并且 T[s+1…s+m] = P[1…m],即对 1≤j≤m,有 T[s+j] = P[j],则说模式 P
在文本 T 中出现且位移为 s,且称 s 是一个有效位移(Valid Shift)。
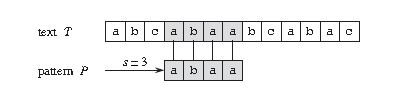
比如上图中,目标是找出所有在文本 T = abcabaabcabac 中模式 P = abaa 的所有出现。
该模式在此文本中仅出现一次,即在位移 s = 3 处,位移 s = 3 是有效位移。
解决字符串匹配的算法包括:
- 朴素算法(Naive Algorithm)、
- Rabin-Karp 算法、
- 有限自动机算法(Finite Automation)、
- Knuth-Morris-Pratt 算法(即 KMP Algorithm)、Boyer-Moore 算法、Simon
算法、Colussi 算法、
Galil-Giancarlo 算法、Apostolico-Crochemore 算法、Horspool 算法和 Sunday 算法等)。
字符串匹配算法通常分为两个步骤:预处理(Preprocessing)和匹配(Matching)。所以算法的总运行时间为预处理和匹配的时间的总和。
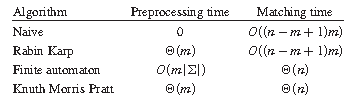
上图描述了常见字符串匹配算法的预处理和匹配时间。
这里设计的很多,大家可以根据需求学习指定算法。
字符串匹配算法、C语言实现字符串匹配KMP算法
参考文献
排序算法:http://data.biancheng.net/sort/
C语言二分查找算法,折半查找算法:http://c.biancheng.net/view/536.html
16图的搜索算法之先深:https://www.cnblogs.com/gd-luojialin/p/10384761.html
贪心算法:https://blog.csdn.net/yongh701/article/details/49256321
字符串匹配算法:https://www.cnblogs.com/gaochundong/p/string_matching.html
C语言实现字符串匹配KMP算法:https://www.jb51.net/article/54123.htm
欢迎关注订阅微信公众号【熊泽有话说】,更多好玩易学知识等你来取
作者:熊泽-学习中的苦与乐
公众号:熊泽有话说
QQ群:711838388
出处1:https://www.cnblogs.com/xiongze520/p/15816597.html
出处2:https://blog.csdn.net/qq_35267585/article/details/122573608
您可以随意转载、摘录,但请在文章内注明作者和原文链接。
