独家 | 利用Python实现主题建模和LDA 算法(附链接)
作者:Susan Li翻译:陈之炎校对:陈汉青
本文约1900字,建议阅读5分钟在这篇文章,我们将LDA应用于一组文档,并将文档按照主题分类。
标签:LDA 算法
主题建模是一种用于找出文档集合中抽象“主题”的统计模型。LDA(Latent Dirichlet Allocation)是主题模型的一个示例,用于将文档中的文本分类为特定的主题。LDA算法为每一个文档构建出一个主题,再为每一个主题添加一些单词,该算法按照Dirichlet分布来建模。
那便开始吧!
数据
在这里将使用到的数据集是15年内发布的100多万条新闻标题的列表,可以从Kaggle下载。

先来看看数据。

1048575

图1
数据预处理
执行以下步骤:
标记化——将文本分成句子,将句子分成单词,把单词变为小写,去掉标点符号。
删除少于3个字符的单词。
删除所有的句号。
词形还原——将第三人称的单词改为第一人称,将过去和未来时态中的动词改为现在时。
词根化——将单词简化为词根形式。
加载gensim 和nltk库
[nltk_data] Downloading package wordnet to[nltk_data]
C:\Users\SusanLi\AppData\Roaming\nltk_data…[nltk_data] Package wordnet is already up-to-date!
True
编写一个函数,对数据集执行词形还原和词干预处理。

预处理之后选择要预览的文档。
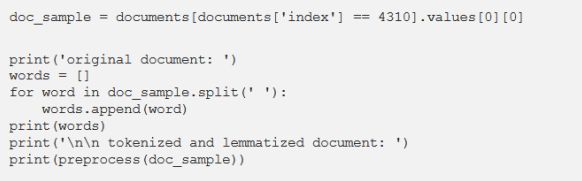
源文件:
[‘rain’, ‘helps’, ‘dampen’, ‘bushfires’]
标记化和词形还原后的文件:
[‘rain’, ‘help’, ‘dampen’, ‘bushfir’]
成了!
预处理标题文本,将结果保存为“processed_docs’


图2
数据集的词袋
由 “processed_docs”创建一个字典,其中包含单词出现在训练集中的次数。

0 broadcast
1 communiti
2 decid
3 licenc
4 awar
5 defam
6 wit
7 call
8 infrastructur
9 protect
10 summit
Gensim filter_extremes
过滤出以下几种情况下的单词:
在少于15个文档中出现(绝对数)或
在总语料库中占比分数超过0.5
以上两步之后,只保留前10万最频繁出现的单词。
![]()
Gensim doc2bow
为每个文档创建一个字典来报告单词和这些单词出现的次数,将其保存到“bow_corpus”,然后再次检查选定的文档。

[(76, 1), (112, 1), (483, 1), (3998, 1)]
预览样本预处理文件的词袋。

Word 76 (“bushfir”) appears 1 time.
Word 112 (“help”) appears 1 time.
Word 483 (“rain”) appears 1 time.
Word 3998 (“dampen”) appears 1 time.
TF-IDF
利用models.TfidfModel模型,创建 ‘bow_corpus’的 tf-idf模型对象,并将其保存到“tfidf”。对整个语料库进行tfidf转换,并将其命名为“corpus_tfidf’。最后,预览第一份文件的TF-IDF分数值。

[(0, 0.5907943557842693),
(1, 0.3900924708457926),
(2, 0.49514546614015836),
(3, 0.5036078441840635)]
使用词袋运行LDA
使用gensim.models.LdaMulticore训练LDA模型并将其保存到“lda_model’

计算每个主题下出现的单词及其相对权重。



图3
你能用每个主题中的单词及其相应的权重来区分不同的主题吗?
利用TF-IDF 运行LDA


图4
现在,你能用每个主题中的单词及其相应的权重来区分不同的主题吗?
评估利用LDA词袋模型对样本文档进行分类的效果
检查将测试文件归为哪一类。
![]()
[‘rain’, ‘help’, ‘dampen’, ‘bushfir’]


图5
测试文档被模型精确归类为可能性最大的那个主题,说明分类准确。
评估LDA TF-IDF模型对样本文档进行分类的效果


图6
测试文档被模型精确归类为可能性最大的那个主题,说明分类准确。
隐含文档上的测试模型


图7
源代码可以在GitHub上找到。期待听到您的反馈或问题。
参考资料:
https://www.udacity.com/course/natural-language-processing-nanodegree--nd892
原文标题:
利用Python实现主题建模和LDA 算法
原文链接:
https://towardsdatascience.com/topic-modeling-and-latent-dirichlet-allocation-in-python-9bf156893c24
编辑:王菁
校对:汪雨晴
译者简介

陈之炎,北京交通大学通信与控制工程专业毕业,获得工学硕士学位,历任长城计算机软件与系统公司工程师,大唐微电子公司工程师,现任北京吾译超群科技有限公司技术支持。目前从事智能化翻译教学系统的运营和维护,在人工智能深度学习和自然语言处理(NLP)方面积累有一定的经验。业余时间喜爱翻译创作,翻译作品主要有:IEC-ISO 7816、伊拉克石油工程项目、新财税主义宣言等等,其中中译英作品“新财税主义宣言”在GLOBAL TIMES正式发表。能够利用业余时间加入到THU 数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织