山东大学软件学院人工智能导论复习笔记
完全针对考试范围对教材和PPT重点部分进行整理
时间:2020/9/4
山东大学软件学院大二下人工智能导论课程
第一章 绪论
- 弱人工智能:指不能真正实现推理和解决问题的智能机器,这些机器表面看像是智能的,但是并不真正拥有智能,也不会有自主意识。
- 强人工智能:指真正能思维的智能机器,并且认为这样的机器是有知觉的和自我意识的,这类机器可分为类人(机器的思考和推理类似人的思维)与非类人(机器产生了和人完全不一样的知觉和意识,使用和人完全不一样的推理方式)两大类。
- 人工智能:用人工的方法在机器(计算机)上实现的智能,也称为机器智能。
第二章 知识表示
- 相关概念(知道就行,不需要记住准确定义):谓词(大写)、常量、变元、函数(小写)、连接词(非、与(合取)、或(析取)、蕴含、等价,已按优先级顺序写出) 、量词(全称量词、存在量词)、谓词公式、量词的辖域、永真性、可满足性、不可满足性(永假性)、等价性(注意逆否律)、永真蕴含(主要的永真蕴含式:假言推理、拒取式推理、假言三段论、全称固化、存在固化、反证法)。
- 一阶谓词逻辑表示步骤:
(1)定义谓词及个体,确定每个谓词及个体的确切定义。
(2)根据要表达的事物或概念,为谓词中的变元赋以特定的值。
(3)根据语义用恰当的连接符号将各个谓词连接起来,形成谓词公式。
例题:




注:定义谓词时,不要定义成负面的。“都是、必”用“蕴含”,“不”用“非”,“所有”用“任意”,“有些”用“存在”,“不是所有”用“非 任意”,“没有一个”用“非 存在”,“是、既…又…”用“合取”,“并列的句子”用“析取”。个人认为,也要把为变元赋予的特定值写明出来。所有的表示基本都要加量词。个人认为,谓词首字母大写,函数首字母小写,人名首字母大写。
- 产生式系统:把一组产生式放在一起,让它们互相配合,协同作用,一个产生式生成的结论可以供另一个产生式作为已知事实使用,以求得问题的解,这样的系统称为产生式系统。
- 产生式系统的基本结构:一般来说,一个产生式系统由规则库、控制系统(推理机)、综合数据库三部分组成。
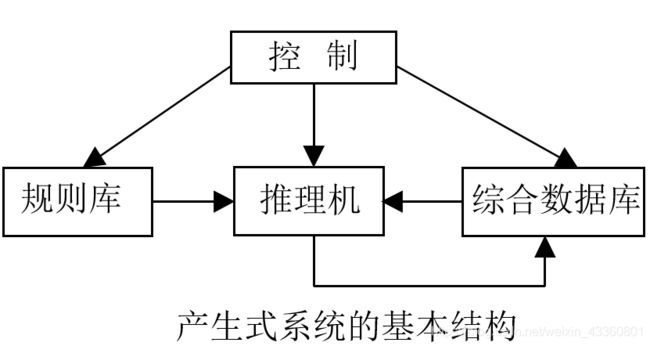
注:根据教材,此图要注意将“推理机”改为“推理”,将“控制”和“推理”用虚线框在一起,并在其中写上“推理机”。
- 产生式系统各部分:
(1)规则库:用于描述相应领域内知识的产生式集合称为规则库。
(2)综合数据库:综合数据库又称为事实库、上下文、黑板等。它是一个存放问题求解过程中各种当前信息的数据结构,如问题的初始状态、原始证据、推理中得到的中间结论及最终结论。
(3)推理机:推理机有一组程序组成,负责整个产生式系统的运行,实现对问题的求解。推理机要做以下工作:推理、冲突消解、执行规则、检查推理终止条件。 - 产生式系统的工作过程(原理):不断地从规则库中选择可用规则与综合数据库中的已知事实进行匹配,规则的每一次成功匹配都使综合数据库增加了新的内容,并朝着问题的解决方向前进了一步,这就是产生式系统的工作过程(原理)。
- 产生式与谓词逻辑中的蕴涵式的区别:
(1)除逻辑蕴涵外,产生式还包括各种操作、规则、变换、算子、函数等。例如,“如果炉温超过上限,则立即关闭风门”是一个产生式,但不是蕴含式。
(2)蕴涵式只能表示精确知识,而产生式不仅可以表示精确的知识,还可以表示不精确知识。蕴涵式的匹配总要求是精确的。产生式匹配可以是精确的,也可以是不精确的,只要按某种算法求出的相似度落在预先指定的范围内就认为是可匹配的。
第三章 确定性推理方法
- 推理:从初始证据出发,按照某种策略不断运用知识库中的已知知识,逐步推出结论的过程称为推理。
- 演绎推理 (deductive reasoning) :从全称判断推导出单称判断的过程,即由一般性知识推出适合某一具体情况的结论。这是从一般到个体的推理。
- 归纳推理:从足够多的事例中归纳出一般性结论的推理过程。是从个别到一般的推理。(完全归纳推理和不完全归纳推理 P50)
- 默认推理(缺省推理):在知识不完全的情况下假设某些条件具备所进行的推理。
- 确定性推理:推理时所用的知识与证据都是确定的,推出的结论也是确定的,其真值或者为真或者为假。
- 不确定性推理:推理时所用的知识与证据不都是确定的,推出的结论也是不确定的。
- 单调推理:随着推理向前推进及新知识的加入,推出的结论越来越接近最终目标。
- 非单调推理:由于新知识的加入,不仅没有加强已推出的结论,反而要否定它,使推理退回到前面的某一步,然后重新开始。
- 如果推理过程中运用与推理有关的启发性知识,则称为启发式推理,否则称为非启发式推理。
- 冲突消解:按一定的策略从匹配成功的多个知识中挑出一个知识用于当前的推理的过程称为冲突消解。解决冲突时所用的策略称为冲突消解策略。目前已有的多种消解冲突的策略,其基本思想都是对知识进行排序。
- 冲突消解策略常用的几种:按规则的针对性进行排序、按已知事实的新鲜性排序、按匹配度排序、按条件个数进行排序。
- 自然演绎推理:从一组已知为真的事实出发,运用经典逻辑的推理规则推出结论的过程称为自然演绎推理。
(1)首先定义谓词
(2)把上述已知事实及待求证的问题用谓词公式表示出来
(3)应用推理规则进行推理 - 谓词公式化为子句集
(1)消去谓词中的“蕴含”和“等价”符号
(2)把否定符号移到紧靠谓词的位置上
(3)变量标准化
(4)消去存在量词
(5)化为前束型
(6)化为Skolem标准型
(7)略去全称量词
(8)消去合取词
(9)子句变量标准化,即使每个子句中的变量符号不同
谓词公式不可满足的充要条件是其子句集不可满足。 - 归结原理(一定要看书)
- 归结反演:应用归结原理证明定理的过程称为归结反演。
(1)将已知前提表示为谓词公式F
(2)将待证明的结论表示为谓词公式Q,并否定得到非Q
(3)把谓词公式集{F, 非Q}化为子句集S
(4)应用归结原理对子句集S中的子句进行归结,并把每次归结得到的归结式都并入到S中。如此反复进行,若出现了空子句,则停止归结,此时就证明了Q为真。 - 应用归结原理求解问题
(1)已知前提F用谓词公式表示,并化为子句集S
(2)把待求解的问题Q用谓词公式表示,并否定Q,再与ANSWER构成析取式(﹁ Q ∨ ANSWER );
(3)把(﹁ Q∨ ANSWER) 化为子句集,并入到子句集S中,得到子句集S’
(4)对S’ 应用归结原理进行归结
(5)若得到归结式ANSWER,则答案就在ANSWER中
注:本章节多看书中例题
第四章 不确定性推理方法
- 不确定推理的概念:不确定性推理从不确定性的初始证据出发,通过运用不确定性知识,最终推出具有一定程度的不确定性但却是合理或者近乎合理的结论的思维过程。
- 三种不确定性推理方法:可信度方法、证据理论(D-S理论)、模糊推理。
- C-F模型:C-F模型是基于可信度表示的不确定性推理的基本方法。
- 证据理论:
概率分配函数

概率分配函数的作用是把D的任意一个子集A都映射为[0, 1]上的一个数M(A)。概率分配函数实际上就是对D的各个子集进行信任分配,M(A )表示分配给A的那一部分。
信任函数

似然函数
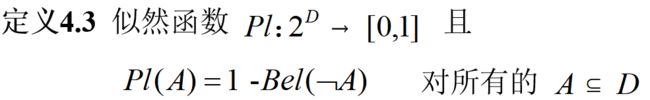
由于Bel(A)表示对A为真的信任程度,所有Bel(非A)表示对非A为真的信任程度,即A为假的信任程度,由此推出Pl(A)表示对A为非假的信任程度。

- 模糊推理:
模糊逻辑给集合中每一个元素赋予一个介于0和1之间的实数,描述其属于一个集合的强度,该实数称为元素属于一个集合的隶属度。集合中所有元素的隶属度全体构成集合的隶属函数。 - 模糊关系是普通关系的推广。普通关系是描述两个集合中的元素之间是否有关联。模糊关系描述的是两个模糊集合中的元素之间的关联程度。
第五章 搜索求解策略
- 状态空间是利用状态变量和操作符号,表示系统或问题的有关知识的符号体系。状态看空间可以用一个四元组表示(S, O, S0, G)。(S是状态集合,O是操作算子的集合,S0是初始状态,G是目标状态)
- 状态空间搜索是搜索某个状态空间以求得操作算子序列的一个解答的过程。
- 搜索策略的主要任务是确定选取操作算子的方式。它有两种基本方式:盲目搜索和启发式搜索。
- 回溯策略是当遇到不可解结点时回溯到路径中最近的父结点上,查看该结点是否还有其他的子结点未被扩展。若有,则沿这些子结点继续搜索;如果找到目标,就成功退出搜索,返回解题路径。
回溯策略的三张表:路径状态表(PS)、新的路径状态表(NPS)、不可解状态表(NSS)。
路径状态表:保存当前搜索路径上的状态。
新的路径状态:包含了等待搜索的状态,其后裔状态还为被搜索到,即未被扩展。
不可解状态表:找不到解路径的状态。
PS = [Start], NPS = [Start], NSS = [], CS = Start
while NPS != []
if CS == 目的状态 return PS
if CS没有子状态
while (PS != []) and (CS == PS中的第一个元素)
将CS加入到NSS中
从PS中删除第一个元素CS
从NPS中删除第一个元素CS
CS = NPS中的第一个元素
将CS加入到PS中
else
将CS子状态(不包括PS、NPS、NSS中已有的)加入到NPS中
CS = NPS中的第一个元素
将CS加入到PS中
return false // 没有解
书中例题:
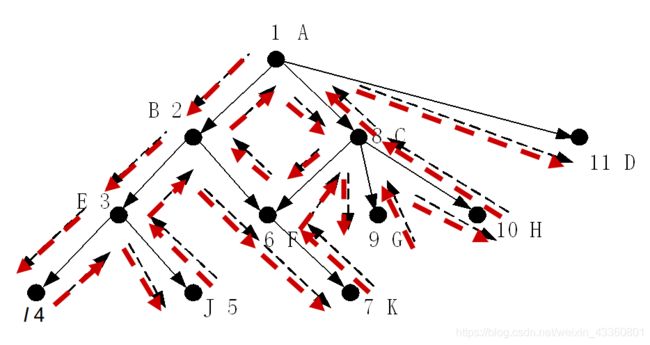
| 重复 | CS | PS | NPS | NSS |
|---|---|---|---|---|
| 0 | A | [A] | [A] | |
| 1 | B | [BA] | [BCDA] | |
| 2 | E | [EBA] | [EFBCDA] | |
| 3 | I | [IEBA] | [IJEFBCDA] | |
| 4 | J | [JEBA] | [JEFBCDA] | [I] |
| 5 | F | [FBA] | [FBCDA] | [EJI] |
| 6 | K | [KFBA] | [KFBCDA] | [EJI] |
| 7 | C | [CA] | [CDA] | [BFKEJI] |
| 8 | G | [GCA] | [GHDCA] | [BFKEJI] |
- 宽度优先搜索策略是根据状态空间的图描述,一层一层地扩展下去,直到搜索到目的状态(如果目的状态存在)。
使用两张表:open表、closed表。
open表:表中状态的排列次序就是搜索的次序。
closed表:记录了已被生成扩展过的状态。
open = [Start], closed = []
while open != []
从open中删除第一个状态,称之为n
将n加入到closed中
if n == 目的状态 return true
生成n的所有子状态
从n的子状态中删除已在open或closed中已出现的状态
将n的其余子状态按生成的次序加入到open表的后端
return false
由于宽度优先搜索总是在生成扩展完N层所有结点之后才转向N+1层,所以如果有解,那么它一定能找到最优解。
书中例题:积木问题

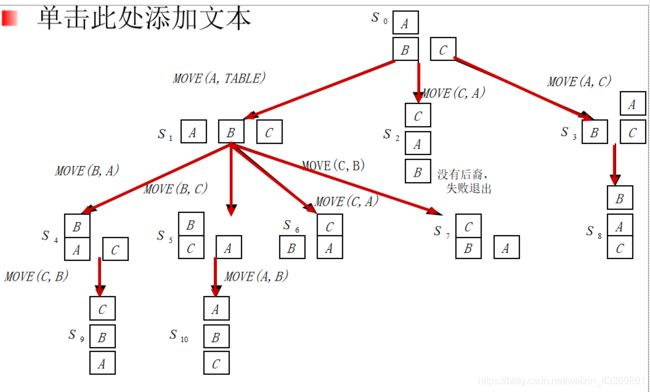
- 深度优先搜索策略
open = [Start], closed = [], d = 深度限制值
while open != []
从open中删除第一个状态,称之为n
将n加入到closed中
if n == 目的状态 return true
if n的深度 < d
生成n的所有子状态
从n的子状态中删除已在open或closed中已出现的状态
将n的其余子状态按生成的次序加入到open表的前端
return false
书中例题:卒子穿阵问题
- 启发式策略就是利用与问题有关的起发信息引导搜索。
书中例题:一字棋游戏的启发式策略 - 估价函数f(n)定义为从初始结点经过n结点到达目的结点的路径的最小代价估计值,其一般形式是f(n) = g(n) + h(n)
- 八数码问题的估价函数
- 启发式图搜索算法有两张表:open表、closed表
open表:保留所有已生成而未扩展的状态。
closed表:记录已扩展过的状态。 - A搜索算法是基于估价函数的一种加权启发式图搜索算法。
open = [Start], closed = [Start], f(s) = g(s) + h(s)
while open != []
从open中删除第一个状态,称之为n
if n == 目的状态 return true
生成n的所有子状态
if n没有任何子状态 continue
for n的每个子状态
case 子状态不在open或closed中
计算该子状态估价函数值
将该子状态加入到open表中
case 子状态在open中
if 子状态是沿着一条比在closed中已有的更短路径而到达
记录更短路径走向及估价函数值
case 子状态在closed中
if 子状态是沿着一条比在closed中已有的更短路径而到达
将该子状态从closed中移到open中
记录更短路径走向及估价函数值
将n加入到closed中
根据估价函数值,从小到大重新排列open表
return false
书中例题:八数码f(n) = d(n) + w(n)
d(n)代表深度,每步为单位代价;w(n)表示以“不在位”的数码作为启发信息的度量。
- A搜索算法:定义h(n)为状态n到达目的状态的最优路径的代价,则当A搜算算法的启发函数h(n)小于等于h*(n),即满足
h(n)≤h*(n),对所有节点n
时,被称为A搜索算法。
如果某一问题有解,那么利用A搜索算法对该问题进行搜索则一定能搜索到解,并且一定能搜索到最优的解而结束。


第六章 智能计算及其应用
- 进化算法(EA):是基于自然选择和自然遗传等生物进化机制的一种搜索算法。
- 遗传算法(GA):一类借鉴生物界自然选择和自然遗传机制的随机搜索算法,非常适用于处理传统搜索方法难以解决的复杂和非线性优化问题。
- 基本遗传算法(SGA)只使用选择、交叉、变异这三种基本遗传算子
- 遗传算法基本思想:在求解问题时从多个解开始,然后通过一定的法则进行逐步迭代以产生新的解。
- 遗传算法中包括的5个基本要素:参数编码,初始群体的设定,适应度函数的设计,遗传操作设计和控制参数设定。
- 6.2.3-6.2.8全部自己看,理解概念就行,不需要背公式
- 群智能算法(SI):受动物群体智能启发的算法,称为群智能算法。
- 群体智能:这些由简单个体组成的群落与环境以及个体之间的互动行为,称为群体智能。
- 粒子群优化算法(PSO)是一种利用群智能理论的全局优化算法,通过群体中粒子间的合作与竞争产生的群体智能指导优化搜索。
- 进化计算方法强调种群的达尔文主义的进化模型;群体智能方法则注重对群体中个体之间的相互作用与分布式协同的模拟。
第七章 专家系统与机器学习
- 专家系统的概念:专家系统是一种智能计算机程序,它运用知识和推理来解决只有专家才能解决的复杂问题。
- 专家系统的一般结构:完整的专家系统一般包括人机接口、推理机、知识库、数据库、知识获取机构和解释机构六部分。
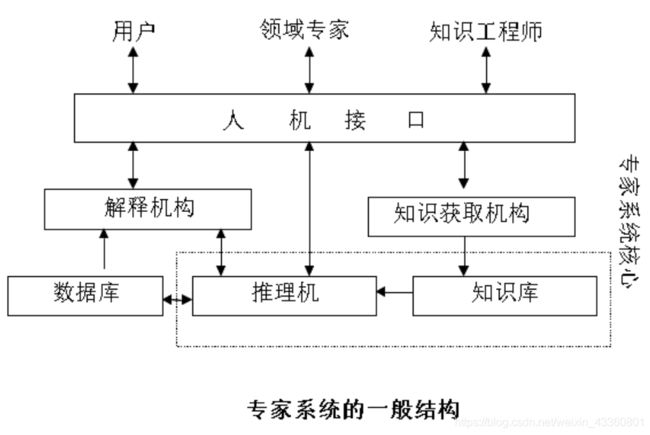
专家系统的核心是知识库和推理机。
(1)知识库主要用来存放领域专家提供的有关问题求解的专门知识。
(2)推理机的功能是模拟领域专家的思维过程,控制并执行对问题的求解。
(3)综合数据库又称动态数据库或黑板,主要用于存放初始事实、问题描述及系统运行过程中得到的中间结果、最终结果等信息。
(4)知识获取机构把知识转换为计算机可存储的内部形式,然后把它们存入知识库。
(5)人机接口是专家系统与领域专家、知识工程师、一般用户之间进行交互的界面,由一组程序及相应的硬件组成,用于完成输入输出工作。
(6)解释机构回答用户提出的问题,解释系统的推理过程。
- 机器学习的基本概念:机器学习使计算机能模拟人的学习行为,自动地通过学习来获取知识和技能,不断改善性能,实现自我完善。
- 知识发现(KDD)的概念:从数据库中发现知识。
- 数据挖掘(DM)的概念:从大量数据中,提取隐含在其中的、人们事先不知道的但又有可能有用的信息和知识的过程。
第八章 人工神经网络及其应用
- 人工神经网络(artificial neural networks, ANN): 模拟人脑神经系统的结构和功能,运用大量简单处理单元经广泛连接而组成的人工网络系统。
- 神经元的数学模型(MP模型):

两个操作,即加权求和与非线性变换
3. 什么是感知机:

- 感知机模型只能解决线性问题,不能解决非线性问题。
- 增加更多的层次有什么好处?更深入的表示特征,以及更强的函数模拟能力。
(1)更深入的表示特征可以这样理解,随着网络的层数增加,每一层对于前一层次的抽象表示更深入。在神经网络中,每一层神经元学习到的是前一层神经元值的更抽象的表示。例如第一个隐藏层学习到的是“边缘”的特征,第二个隐藏层学习到的是由“边缘”组成的“形状”的特征,第三个隐藏层学习到的是由“形状”组成的“图案”的特征,最后的隐藏层学习到的是由“图案”组成的“目标”的特征。通过抽取更抽象的特征来对事物进行区分,从而获得更好的区分与分类能力。
(2)更强的函数模拟能力是由于随着层数的增加,整个网络的参数就越多。而神经网络其实本质就是模拟特征与目标之间的真实关系函数的方法,更多的参数意味着其模拟的函数可以更加的复杂,可以有更多的容量(capcity)去拟合真正的关系。
注:上面的解释也只是其中的一种。 - 机器学习模型训练的目的:就是使得参数尽可能的与真实的模型逼近。
- 机器学习模型训练的具体做法:首先给所有参数赋上随机值。我们使用这些随机生成的参数值,来预测训练数据中的样本。样本的预测目标为yp,真实目标为y。那么,定义一个值loss,计算公式如下。loss = (yp – y)2这个值称之为损失(loss),我们的目标就是使对所有训练数据的损失和尽可能的小。如果将先前的神经网络预测的矩阵公式带入到yp中(因为有z=yp),那么我们可以把损失写为关于参数(parameter)的函数,这个函数称之为损失函数(loss function)。下面的问题就是求如何优化参数,能够让损失函数的值最小。
- 反向传播算法:反向传播算法利用了神经网络的结构进行的计算。不一次计算所有参数的梯度,而是从后往前。首先计算输出层的梯度,然后是第二个参数矩阵的梯度,接着是中间层的梯度,再然后是第一个参数矩阵的梯度,最后是输入层的梯度。计算结束以后,所要的两个参数矩阵的梯度就都有了。
注:反向传播算法就是根据损失函数,通过链式法则,从后往前,不断地更新参数,达到学习的目的。
第九章 智能体与多智能体系统
-
智能体的概念:Agent可以看做是一个程序或者一个实体,它嵌入在环境中,通过传感器(sensors)感知环境,通过效应器(effectors)自治地作用于环境并满足设计要求。
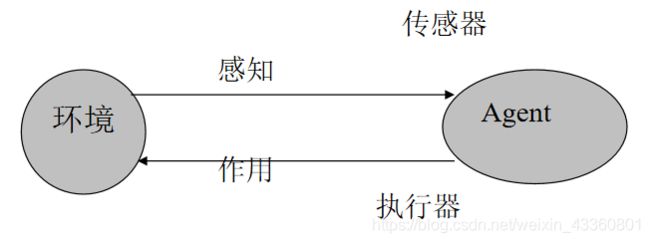
-
智能体的特性:自主性、反应性、社会性、进化性。
-
多智能体系统:一个应用系统中往往包括多个智能体,这些智能体不仅具备自身的问题求解能力和行为目标,而且能够相互协作,达到共同的整体目标,这样的系统称为多智能体系统(MAS)。
-
合同网协作方法的基本思想:人们在商务过程中用于管理商品和服务的合同机制。
-
合同网协作方法:在合同网方法中,所有智能体分为两种角色:管理者和工作者。智能体的角色在协作过程中的角色可以变化:任何智能体通过发布任务通知书而成为管理者;相反,任何智能体通过应答任务通知书而成为工作者。
管理者Agent的职责:
(1)对每个待求解任务建立任务通知书,将任务通知书发送给有关的工作者agent,向工作者发出竞标信息。
(2)接受并评估来自工作者的投标值。
(3)根据任务竞标要求,选择最合适的工作者,并与之签订工作合同。
(4)在工作者履行合同的同时,对工作者进行监督和管理。
(5)对任务执行结果进行综合和分析。
工作者Agent的职责:
(1)接收相关的任务通知书。
(2)评价任务书,根据自身的情况设定任务投标的投标值。
(3)向管理者发送投标信息。
(4)若获得投标成功,则和管理者签订合同,并按照合同要求执行合同所分配的任务。
(5)当所分配的任务完成时,通知管理者,并报告求解的结果。
- 黑板模型协作方法的基本思想:多个人类专家或智能体专家协同求解一个问题,黑板是一个共享的问题求解工作空间,多个专家都能“看到”黑板。
- 黑板模型协作方法:当问题和初始数据记录到黑板上,求解开始。所有专家通过“看”黑板寻找利用其专家经验知识求解问题的机会。当一个专家发现黑板上的信息足以支持他进一步求解问题时,他就将求解结果记录在黑板上。新增加的信息有可能使其它专家继续求解。重复这一过程直到整个问题彻底求解,获得最终结果。
- 黑板模型由三个基本模块组成:知识源、黑板、监控机制。
① 知识源,即Agent,是作为求解问题的独立单元,具有不同的专门知识,独立完成特定的任务。
② 黑板,即公共工作区,为知识源提供信息和数据,同时,供知识源进行修改。
③ 监控机制,根据黑板当前的问题求解状态,以及各知识源的不同求解能力,对其进行监控,使之能实时响应黑板变化,及时进行问题求解。