Multi-View Stereo for Community Photo Collections 论文阅读笔记
Multi-View Stereo for Community Photo Collections 论文阅读笔记
上一篇论文笔记,主要介绍了如何从photo collection中获得点云(point clouds),这一篇论文主要介绍,获得点云之后该做怎样的处理,来获得一个surface(更确切的是稠密点云)。因为在网上没有找到类似的笔记,就只能一边阅读,一边做笔记了,如有错误,欢迎指正。
Abstract
We present a multi-view stereo algorithm that addresses the extreme changes in lighting, scale, clutter, and other effects in large online community photo collections. Our idea is to intelligently choose images to match, both at a per-view and per-pixel level.(从view级别和piexl级别选取图片进行匹配) We show that such adaptive view selection enables robust performance even with dramatic appearance variability.(很牛逼) The stereo matching technique takes as input sparse 3D points reconstructed from structure-from-motion methods(就是通过sfm获得的3D点云) and iteratively grows surfaces from these points.(通过迭代生成surface–可以翻译为表面?) Optimizing for surface normals within a photoconsistency measure significantly improves the matching results(通过照片的图像一致性进行优化,很多MVS都是通过这一个思路进行). While the focus of our approach is to estimate high-quality depth maps(估计高质量的深度图), we also show examples of merging the resulting depth maps into compelling scene reconstructions(利用深度图进行重建). We demonstrate our algorithm on standard multi-view stereo datasets and on casually acquired photo collections of famous scenes gathered from the Internet.(测试)
abstract的话,主要就是讲了本篇文章的目的,以及大体使用到的方法,总结,这篇文章很牛逼,over。
1 Introduction
With the recent rise in popularity of Internet photo sharing sites like Flickr and Google, community photo collections (CPCs) have emerged as a powerful new type of image dataset. For example, a search for “Notre Dame Paris” on Flickr yields more than 50,000 images showing the cathedral from myriad viewpoints and appearance conditions. This kind of data presents a singular opportunity: to reconstruct the world’s geometry using the largest known, most diverse, and largely untapped, multi-view stereo dataset ever assembled. What makes the dataset unusual is not only its size, but the fact that it has been captured “in the wild”— not in the laboratory—leading to a set of fundamental new challenges in multi-view stereo research.
这一段,就是在说我们的数据来源于生活,更具有现实意义。
In particular, CPCs exhibit tremendous variation in appearance and viewing parameters, as they are acquired by an assortment of cameras at different times of day and in various weather. As illustrated in Figures 1 and 2, lighting, foreground clutter, and scale can differ substantially from image to image. Traditionally, multi-view stereo algorithms have considered images with far less appearance variation, where computing correspondence is significantly easier, and have operated on somewhat regular distributions of viewpoints (e.g., photographs regularly spaced around an object, or video streams with spatiotemporal coherence). In this paper we present a stereo matching approach that starts from irregular distributions of viewpoints, and produces robust high-quality depth maps in the presence of extreme appearance variations.
这一段跟上一段讲的几乎是一个内容,大概就是说,传统的算法都对用来重建物体的照片或者视频有特殊的要求,因此重建也会比较简单,但是我们这里要做的就是通过随机(可以这么说)的照片还原物体的几何结构,对照片几乎没什么特别要求。
Our approach is based on the following observation: given the massive numbers of images available online, there should be large subsets of images of any particular site that are captured under compatible lighting, weather, and exposure conditions, as well as sufficiently similar resolutions(分辨率) and wide enough baselines(基线).(灵感来源,尽管网上的图片有很多,但是大多可以形成关于一个site(地点)的子集,因此我们可以根据每一个site形成一个clutter) By automatically identifying such subsets, we can dramatically simplify the problem, matching images that are similar in appearance and scale while providing enough parallax(视差) for accurate reconstruction.(存在一定的容错率) While this idea is conceptually simple, its effective execution requires reasoning(推论?) both (1) at the image level, to approximately match scale and appearance and to ensure wide-enough camera baseline, and (2) at the pixel level, to handle clutter, occlusions, and local lighting variations and to encourage matching with both horizontal and vertical parallax.(从图片和像素两个方面的要求) Our main contribution is the design and analysis of such an adaptive view selection process. We have found the approach to be effective over a wide range of scenes and CPCs. In fact, our experiments indicate that simple matching metrics tolerate a surprisingly wide range of lighting variation over significant portions of many scenes.(总之,很有效) While we hope that future work will extend this operating range and even exploit large changes in appearance, we believe that view selection combined with simple metrics is an effective tool, and an important first step in the reconstruction of scenes from Internet-derived collections.
这一段主要讲的就是灵感的来源,以及大体的解决思路
Motivated by the specific challenges in CPCs, we also present a new multi-view stereo matching algorithm that uses a surface growing approach to iteratively reconstruct robust and accurate depth maps. (abstract中介绍的迭代获得表面的做法)This surface growing approach takes as input sparse feature points, leveraging the success of structure-from-motion techniques [2, 23] which produce such output and have recently been demonstrated to operate effectively on CPCs. Instead of obtaining a discrete depth map, as is common in many stereo methods [21], we opt instead to reconstruct a sub-pixel-accurate continuous depth map(没有找到翻译,暂且叫它精准连续的子像素深度图,手动滑稽). To greatly improve resilience(恢复力) to appearance differences in the source views, we use a photometric window(翻译为光学窗?也没找到翻译) matching approach in which both surface depth and normal are optimized together(normal是指的法向量), and we adaptively discard views that do not reinforce cross-correlation of the matched windows.(丢弃对匹配窗没有增强效果的view) Used in conjunction with a depth-merging approach, the resulting approach is shown to be competitive with the current top-performing multi-view stereo reconstruction methods on the Middlebury benchmarks [22].
感觉这一段就是在埋伏笔,讲的有点模糊,看完后面应该就会明白了吧。不过总的来说就是通过一个photometric window的方法创造一个depth map这个map不同于其它方法的map,而是sub-pixel-accurate continuous depth map。
2 Previous Work
Here we describe the most closely related work in multiview stereo (MVS), focusing on view selection, matching with appearance variations, region growing, and normal optimization. We refer the reader to [22] (大郎,起来看论文啦,反正我是没看,不过,可以参考下这个大佬写的)for a detailed overview of the state-of-the-art in MVS.
这一段主要提示,提前了解一些MVS的方法。
Many MVS methods employ some form of global view selection to identify nearby views, motivated by efficiency and the desire to minimize occlusions(遮挡). Commonly, MVS methods assume a relatively uniform viewpoint distribution and simply choose the k nearest images for each reference view [19, 4, 6](假设存在相对一致的视点分布和简单地选取每个参考视图的k个最近照片,即对照片的选取具有一定的要求性). CPC datasets are more challenging in that they are non-uniformly distributed in a 7D viewpoint space of camera pose and focal length(7D 包括 位置三个坐标x y z变量、两个旋转变量、一个伸缩变量和focal length), thus representing an extreme case of unorganized image sets [12]. Furthermore, choosing the nearest views is often undesirable, since many images are nearly identical and thus offer little parallax.
这一段还是在说明CPC的难度
Local view selection has also been used before in MVS techniques to achieve robustness to occlusions. Kang et al. [13] exploit the assumption that the temporal order of images matches the spatial order(暂时的图片顺序和空间顺序相匹配), and use shiftable windows in time to adaptively choose frames to match(利用滑动窗灵活的选择frame进行匹配). A number of recent stereo matching methods have used outlier rejection techniques to identify occlusions in the matching step [4, 6]. We further develop this kind of approach and demonstrate that it can be generalized to handle many kinds of appearance variations beyond occlusions.
这一段在说一些传统的MVS方法在解决occlusion方面的贡献
A parallel thread of research in the stereo community is developing robust matching metrics(提高匹配矩阵的稳健性) that enable matching with variable lighting [10], non-Lambertian reflectance [11], and large appearance changes [15](以便在复杂的情况下也能够完成匹配). While we have found normalized cross correlation (NCC) to be surprisingly robust to appearance changes, use of more sophisticated techniques may further broaden the range of views that can be compared, and is thus complementary to the problem of view selection.(使用NCC和其它更复杂的技巧,可以拓展匹配的范围,扩大视野,并且是对view selection的一种补充) We note, however, that increased invariance can potentially lead to reduced discriminatory power and should be used with care.
这一段在说扩大视野的问题,因为local view selection的话是局限在一个地方,但是对于CPC来说,可能存在很大视域,因此,需要有一种方法能够在整个视域内进行匹配。
In its use of region-growing and normal optimization, our MVS approach builds on previous work in the computer vision and photogrammetry communities. Notably, Zhang et al. [24] present a binocular stereo method(双目立体算法) that employs normal optimization to obtain high quality results with structured lighting. Hornung and Kobbelt [10] propose a sample-and-fit approach to estimate planes and higher-order surfaces for photo-consistency computations. Concurrent with our work, Habbecke and Kobbelt [9] and Furukawa and Ponce [5] introduced region growing approaches for multi-view stereo that propagate a surface out from initial seed points. These two approaches use careful modeling of visibility to minimize the effects of outliers, whereas we rely solely on robust statistics and adaptive view selection to achieve reconstruction results of similar quality.
这一段介绍的一个问题是如何减小outlier的影响。
Our work builds on the framework of multiphoto geometrically constrained least squares matching (MPGC) from the photogrammetry literature [8, 1]. In particular, it extends the MPGC-based region-growing MVS algorithm by Otto and Chau [20] by imposing consistent surface normals between multiple views. In a related region-growing paper, Lhuillier and Quan [17] acknowledge the accuracy of [20] but point out two major drawbacks: the inability of an MPGC approach to define a uniqueness constraint to avoid bad matches, and the need for large patch sizes to achieve a stable match. In contrast, we show that even small patch sizes are sufficient for high quality reconstruction if we use a good view selection process and a suitable matching model. Other notable region-growing approaches include Zhang and Shan [25], who cast the problem in a probabilistic framework.
这一段是对region-growing的一点介绍,可以参考[这篇文章](https://blog.csdn-growing的一点介绍,可以参考这篇文章,跟爬虫的原理有点儿相像。
Our work is closely related to Kamberov et al.’s automatic geometry reconstruction pipeline for unstructured image sets [12]. The key algorithmic differences are our use of MVS instead of binocular stereo for each reference view and our view selection approach, which accounts for variations in image resolution and avoids matching narrow baselines. In addition, we demonstrate results on large CPCs with considerablly more variation in scene content and capture conditions.
这一段讲了我们这个算法与Kamberov的算法有点类似,但是不同点在于我们使用的是MVS而不是binocular stereo和我们选择的方法。
3 Algorithm Overview
Our approach to reconstructing geometry from Internet collections consists of several stages. First, we calibrate(校正) the cameras geometrically and radiometrically (Section 4). (第一步,校正相机)Next, we estimate a depth map for each input image(第二补,建立深度图) — each image serves as a reference view exactly once(每一张图片有且仅有一次作为参考view). In order to find good matches, we apply a two-level view selection algorithm(两个层次的选择算法,图片层次和像素层次). At the image level, global view selection(更广的视野) (Section 5.1) identifies for each reference view a set of good neighborhood images to use for stereo matching. Then, at the pixel level, local view selection(更精确的匹配) (Section 5.2) determines a subset of these images that yields a stable stereo match. This subset generally varies from pixel to pixel.
Stereo matching is performed at each pixel (Section 6) by optimizing for both depth and normal(第三步,利用深度图和法向量进行立体匹配,实质是在优化参数), starting from an initial estimate provided by SIFT feature points or copied from previously computed neighbors. During the stereo optimization, poorly matching views may be discarded and new ones added according to the local view selection criteria. The traversal of pixels is prioritized by their estimated matching confidence.(访问的优先度根据匹配的可信度决定) Pixels may be revisited and their depths updated if a higher-confidence match is found.(如果找到了更高可信度的匹配,则更新depths)
这两段主要就是大体介绍下,论文中会做的一些事情:第一步,校正相机;第二步,建立深度图;第三步,进行立体匹配,获得优化的参数。
4 Calibrating Internet Photos
Because our input images are harvested from community photo collections, the camera poses, intrinsics, and sensor response characteristics are generally not provided. Therefore we must first calibrate the set of images both geometrically and radiometrically.
这一段在说,由于我们处理的照片数据来自网络,因此缺乏必要的信息(传统建模),因此我们需要从几何角度和极几何角度进行标定。
First, when feasible, we remove radial distortion from the images using PTLens
(当可能时,我们利用PTLens去除图片中的径向畸变), a commercially available tool that extracts camera and lens information from the image metadata (EXIF tags) and corrects for radial distortion based on a database of camera and lens properties.(PTLens可以提取图片中的一些基本的信息,并且根据一些相机和镜头的属性数据库对图片中的径向畸变进行校正) Images that cannot be corrected are automatically removed from the CPC unless we know that they contain no significant lens distortion (e.g., in the case of the MVS evaluation datasets [22])(如果图片中的畸变不能被校正,那么我们将这些图片去除,除非这些图片原先就不存在非常严重的畸变). Next, the remaining images are entered into a robust, metric structure-from-motion (SfM) system [2, 23] (based on the SIFT feature detector [18]), which yields extrinsic and intrinsic calibration (position, orientation, focal length) for all successfully registered images.(将校正完成的图片和不需要校正的图片送入SFM框架中获取每一张图片对应的相机内参和相机外参,并以此对照片完成注册) It also generates a sparse scene reconstruction from the matched features, and for each feature a list of images in which it was detected.(同时会产生一个稀疏点云)
这一段主要说的是:首先判断图片是否存在畸变,如果存在,则使用PTLens进行校正,然后将校正过的图片送入SFM框架中获取到每张registered的图片,并且获取到一个稀疏点云。这一步骤可以参考我之前的一篇
文章
In order to model radiometric distortions, we attempt to convert all input images into a linear radiometric space.(为了模拟一下径向畸变,我们将所有的输入图片添加到了一个线性的径向空间) Unless the exact response curve of the capture system is known, we assume that the images are in standard sRGB color space and apply the inverse sRGB mapping.(除非相机的response curve
已经知道了,否则我们假设照片可以映射到标准的RGB色彩空间)。
这一段就是说了两个事情,一,将所有的图片映射到一个径向的线性空间,二,假设所有的图片都可以映射到标准的RGB色彩空间。
5 View Selection
5.1 Global View Selection
For each reference view R, global view selection seeks a set N of neighboring views that are good candidates for stereo matching in terms of scene content, appearance, and scale. (对于每一个参考视角,global view selection选择N个匹配的候选图片进行立体匹配)In addition, the neighboring views should provide sufficient parallax with respect to R(不是很懂,感觉他的意思是neighbouring views 应该保证足够的视差,否则就会达不到global view selection的目的–在足够大的范围内进行匹配,这里的R指的是reference view) and each other in order to enable a stable match. Here we describe a scoring function designed to measure the quality of each candidate neighboring view based on these desiderata.(为了保证选取的neighbouring view的质量,我们使用一个scoring function)
这一段主要是在说,在进行global view selection 时,我们需要选取参考view的N个临近view,并使用scoring 函数对view进行质量筛选。
To first order, the number of shared feature points reconstructed in the SfM phase is a good indicator of the compatibility of a given view V with the reference view R.(首先,V与R之间的公共feature point是一个很好的衡量V的指标) Indeed, images with many shared features generally cover a similar portion of the scene.(如果两个图片之间的feature point越多,代表两个图片覆盖同一部分的面积就越大—废话) Moreover, success in SIFT matching is a good predictor that pixel-level matching will also succeed across much of the image. In particular, SIFT selects features with similar appearance, and thus images with many shared features tend to have similar appearance to each other, overall. (feature point 越多越连续,那么在像素级别,连张图片就越连续,因此appearance就会越相似)
这一段主要是在说,我们可以使用SFM获得的每张图片V的feature point与R的feature point 之间的匹配数目作为衡量V匹配性的一个指标
However, the number of shared feature points is not sufficient to ensure good reconstructions. (光靠feature point的数目是不够的)First, the views with the most shared feature points tend to be nearly collocated and as such do not provide a large enough baseline for accurate reconstruction. (首先,如果两个view之间的feature point匹配越多,那么说明这两个图片可能是并列的关系,因此可能提供不了太多的基线来进行精确重建)Second, the scale invariance of the SIFT feature detector causes images of substantially different resolutions to match well, but such resolution differences are problematic for stereo matching.(伸缩不变性可以即便在分辨率不同的情况下也可以很好地对feature point进行匹配,但是在进行立体匹配时,这种分辨率的差异会导致很大的问题)
这一段主要是在说虽然feature point是一个很好地衡量指标,但是还得有很多的考虑。
Thus, we compute a global score gR for each view V within a candidate neighborhood N (which includes R) as a weighted sum over features shared with R:
where FX is the set of feature points observed in view X, and the weight functions are described below.

这里给出了一个抽象的score计算公式,根据上文说的随机选取一个R(reference view),获得它的N个neighbouring view,设gR代表每一个view 的score,gR(V)等于V中与R中匹配的feature point的weight之和,其中weight 等于两个分weight之积,后面将分别介绍这两个分weight。
To encourage a good range of parallax within a neighborhood, the weight function wN(f) is defined as a product over all pairs of views in N:
where wα(f,Vi,Vj) = min((α/αmax)2,1) and α is the angle between the lines of sight from Vi and Vj to f.(我感觉这个地方说的可能存在问题,这里我觉得不是指的feature point,而是指的feature point所map到的空间点,计算两个图片中的feature point到空间点的夹角,这个是可以计算的,所有的参数在sfm中均以获得) The function wα(f,Vi,Vj) downweights triangulation angles below αmax, which we set to 10 degrees(相当于一个阈值) in all of our experiments. The quadratic weight function serves to counteract the trend of greater numbers of features in common with decreasing angle. At the same time, excessively large triangulation angles are automatically discouraged by the associated scarcity of shared SIFT features. (后面解释为什么这么做,没怎么看懂,希望指出)
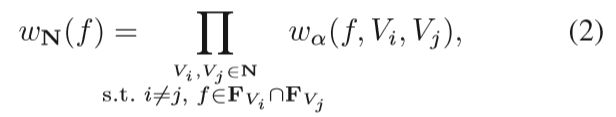
这一段讲的可能有点儿复杂,直接上图:(emmmm,字很丑)

The weighting function ws(f) measures similarity in resolution of images R and V at feature f.(计算R和V在f点的分辨率相似性) To estimate the 3D sampling rate of V in the vicinity of the feature f,(为了估计点附近的3D采样率) we compute the diameter sV (f) of a sphere centered at f whose projected diameter in V equals the pixel spacing in V . We similarly compute sR(f) for R and define the scale weight ws based on the ratio r = sR(f)/sV (f) using
This weight function favors views with equal or higher resolution than the reference view.
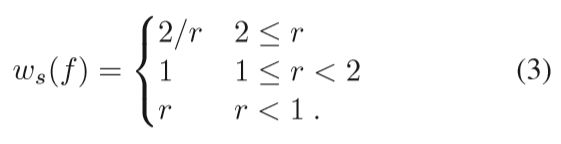
这一段主要讲的就是如何计算R与V之间分辨率的scale weight,其中的关键是计算sR(f)和sV(f),通过SFM我们可以计算出feature point到它空间中映射点的距离,在得知这个图片的pixel spacing之后,我们便可以大致计算出空间中点的之间sV(f):
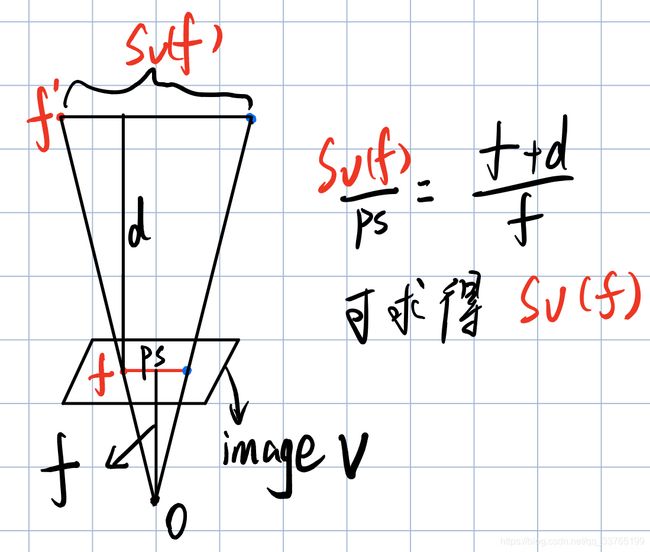
图中的红点表示feature point 蓝点表示feature point的临近像素点。
从ws(f)的公式中我们可以看出,当scale等于1附近时,ws(f)取得最大值1,否则小于1,这就很好地对scale进行了约束,使得V与R的resolution尽可能地相同
Having defined the global score for a view V and neighborhood N, we could now find the best N of a given size (usually |N| = 10)(通常取N为10), in terms of the sum of view scores sum(gR(V))V ∈N. For efficiency, we take a greedy approach and grow the neighborhood incrementally by iteratively adding to N the highest scoring view given the current N (which initially contains only R).
这一段主要是说,我们根据sum(gR(V)) (V∈R),选择|N|通常为10,另外,采用贪心的策略,每一次增加scoring最大的view进行迭代计算。
Rescaling Views Although global view selection tries to select neighboring views with compatible scale, some amount of scale mismatch is unavoidable due to variability in resolution within CPCs, and can adversely affect stereo matching.(global view selection 虽然会尽力去选择scale compatible较好的neighbouring view进入N,但是难免会有较大的resolution 差距 – mismatch,这些mismatch 会对立体匹配产生很大的影响) We therefore seek to adapt, through proper filtering, the scale of all views to a common, narrow range either globally or on a per-pixel basis.(通过filter,将views的scale进行归一化,尽量减小取值范围) We chose the former to avoid varying the size of the matching window in different areas of the depth map and to improve efficiency. Our approach is to find the lowest-resolution view Vmin ∈ N relative to R, resample R to approximately match that lower resolution, and then resample images of higher resolution to match R.(我们的方法是:首先计算相对与R,在N中的最低分辨率view Vmin,然后根据Vmin对R进行重采样,再利用重采样后的R对其余高分辨率的图像进行重采样)
这一段主要是在介绍,如何解决mismatch的问题,并且提出了大体的结局思路
Specifically, we estimate the resolution scale of a view V relative to R based on their shared features:
Vmin is then simply equal to argminV ∈N scaleR(V ).(找到scaleR(V)最小值所对应的V,定义为Vmin) If scaleR(Vmin) is smaller than a threshold t (in our case t = 0.6 which corresponds to mapping a 5×5 reference window on a 3×3 window in the neighboring view with the lowest relative scale), we rescale the reference view so that(如果scaleR(Vmin)<0.6,则对reference进行rescale), after rescaling, scaleR(Vmin) = t. We then rescale all neighboring views with scaleR(V ) > 1.2 to match the scale of the reference view(rescale 所有 scaleR(V)大于1.2的V,使其matchreference view) (which has possibly itself been rescaled in the previous step). Note that all rescaled versions of images are discarded when moving on to compute a depth map for the next reference view. (在计算深度图时,scale 的图片将都会被丢弃)

这一段主要讲了如何进行rescale的依据,以及如何进行rescale。
目前为止,已经讲完了global view selection(GVS),我们可以大体总结下GVS的主要作用就是根据一直的reference view R 和一个scoring函数,通过贪心的方式,添加每一次迭代中scoring最大的一个neighbouring view,但是由于N中的scsale可能不尽相同,所以需要在一定的范围内对各个view的resolution进行简单地统一化处理,方便match时更加准确,并且具有high efficiency。
5.2 Local View Selection
Global view selection determines a set N of good matching candidates for a reference view and matches their scale. Instead of using all of these views for stereo matching at a particular location in the reference view, we select a smaller set A ⊂ N of active views (typically |A|=4). Using such a subset naturally speeds up the depth computation.
这一段主要说,我们通过GVS获得到了每一个reference view 的neighbouring views N,并且对N进行了scale,但我们在接下来的stereo matching中,并不是直接选用N,而是使用它的一个子集A(|A| = 4),那么问题来了,我怎么样选择这个子集A呢?
During stereo matching we iteratively update A using a set of local view selection criteria designed to prefer views that, given a current estimate of depth and normal at a pixel, are photometrically consistent and provide a sufficiently wide range of observation directions.(我们为了选出A集合,设立了一个标准,这个标准倾向于选择光学一致性好的并且观测方向多的view) To measure photometric consistency, we employ mean-removed normalized cross correlation (NCC) between pixels within a window about the given pixel in R and the corresponding window in V (Section 6).(这里在看完NCC的基本原理后就知道了) If the NCC score is above a conservative threshold, then V is a candidate for being added to A.(如果V计算后的score大于一个保守的阈值,那么V就是一个候选)
这一段主要是在说如何获取到一个A的候选者,主要的方法就是通过计算每一个V相对于R的光学一致性(photometric consistency),使用的算法为NCC,具体可以参考下别人的文章。另外,补充下,这里在计算光学一致性时,只是计算某一个pixel附近的一致性,而不是整张图的一致性;这里有标注说mean-removed NCC但是查了好多资料每找到。
In addition, we aim for a useful range of parallax between all views in A.(拥有较大的视差) Viewpoints in a typical CPC are not equally distributed in 3D space. Most images are taken from the ground plane, along a path, or from a limited number of vantage points. At a minimum, as we did during global view selection, we need to avoid computing stereo with small triangulation angles.(避免计算在一个很小的三角角度内计算立体结构) In addition, we would like to observe points from directions that are not coplanar.(尽量从不共面的角度观察空间点) This is particularly important for images containing many line features such as architectural scenes, where matching can be difficult if views are distributed along similar directions.(如果观察的方向几乎一致,对于很多线性特点就太难了) For example, a horizontal line feature yields indeterminate(不确定的) matches for a set of viewpoints along a line parallel to that line feature
这一段的话主要在说,在选取的V中要存在较大的视差,否则,角度太小,会存在立体结构不清晰的问题。
. We can measure the angular distribution by looking at the span of directions from which a given scene point (based on the current depth estimate for the reference pixel) is observed. In practice, we instead consider the angular spread of epipolar lines(极线) obtained by projecting each viewing ray passing through the scene point into the reference view. When deciding whether to add a view V to the active set A, we compute the local score(在决定是否将view V添加到集合A中时,需要计算以下的score)
where we(V,V ′) = min(γ/γmax,1) and γ is the acute angle between the pair of epipolar lines in the reference view as described above. We always set γmax = 10 degrees.

这里主要的内容就是给出了一个计算V是否添加到A的score公式,其中gR(V)是上文公式(1)的计算结果,这里关键的地方是理解:epipolar lines(极线) obtained by projecting each viewing ray passing through the scene point into the reference view,这里的极线在很多的数学资料上都有介绍,见如下图示意:(截自吴福朝:计算机视觉中的数学方法)


了解了极线的定义后就很容易明白We(V,V’)的定义了。
补充下,这个地方的极线均过点m(上图),能用这个点计算的前提是已知该点所对应的深度,也就是初始化条件,因为已知深度,就可以计算出X的位置,之后就可以计算出X到另一个View相机中心的直线方程,也就很容易计算出该直线所对应的极线。
The local view selection algorithm then proceeds as follows. (介绍Local view selection—LVS算法了!!!)Given an initial depth estimate at the pixel, we find the view V with the highest score lR(V ).(由公式(5)计算得来) If this view has a sufficiently high NCC score (we use a threshold of 0.3), it is added to A(如果highest score View的NCC score大于我们给定的阈值0.3,那么我们将该View加入到A中); otherwise it is rejected(否则拒绝). We repeat the process(重复此操作步骤), selecting from among the remaining non-rejected views(从没有被拒绝的view中选择view), until either the set A reaches the desired size or no non-rejected views remain.(直到A达到了预先设定的个数–4 或者 所有被接受的view全部添加进去) During stereo matching, the depth (and normal) are optimized, and a view may be discarded (and labeled as rejected) as described in Section 6.(在立体匹配的过程中,view仍然可能被丢弃) We then attempt to add a replacement view, proceeding as before. It is easy to see that the algorithm terminates, since rejected views are never reconsidered.
这一段主要就是在介绍LVS算法的过程:首先给定一个初始化的深度图数据,然后根据公式(5)计算lR(V)。选出其中score最高的View–V,计算V相对于R的NCC score,如果大于阈值0.3,那么,这个View就是可以被接受的,否则不会被接受。重复此步骤在剩余的N集合中继续选择添加View,直到A达到了预定的size或者N中没有符合要求的View。
到这里LVS已经介绍完了,最核心的是最后一段,前面都是在介绍相关的数学算法。
补充,从后面可以看到LVS并不是在进行region-growing之前就计算好的,而是在该region-growing的过程中根据选取的像素点计算。
6 Multi-View Stereo Reconstruction
终于来到本文章的核心了!!!
可能有点儿长~
Our MVS algorithm has two parts. A region-growing framework maintains a prioritized queue Q of matching candidates (pixel locations in R plus initial values for depth and normals) [20].(region growing 维持一个优先队列,这个队列包含了R中pixel的位置以及初始化的深度信息和标准信息) And, a matching system takes a matching candidate as input and computes depth, normal, and a matching confidence(置信度) using neighboring views supplied by local view selection. If the match is successful, the data is stored in depth, normal, and confidence maps and the neighboring pixels in R are added as new candidates to Q.
这一段主要对MVS算法进行了一个大体的介绍,详细的还要看下文。
6.1 Region Growing
The idea behind the region growing approach is that a successfully matched depth sample provides a good initial estimate for depth, normal, and matching confidence for the neighboring pixel locations in R(一个匹配好的深度样本,可以用来初始化它的neighbor). The optimization process is nonlinear with numerous local minima, making good initialization critical, and it is usually the case that the depth and normal at a given pixel is similar to one of its neighbors. This heuristic(启发式的思路) may fail for non-smooth surfaces or at silhouettes(阴影).
这一段主要是在说初始化的方式,首先我们需要知道一个已经很好估计的样本,知道它的深度,之后我们就可以根据这个样本的深度信息,完成对他所有neighbours的信息初始化。但是这种初始化方式对非平滑表面和阴影是不适用的。
Region growing thus needs to be combined with a robust matching process and the ability to revisit the same pixel location multiple times with different initializations.(RG因此需要有一个稳健的匹配过程,并且具有多次访问同一个位置的能力,多次访问时的初始值时不一样的) Prioritizing the candidates is important in order to consider matches with higher expected matching confidence first.(置信度越高,越优先匹配,这个置信度是根据初始化获得的) This avoids growing into unreliable regions which in turn could provide bad matching candidates.(这样可以防止不可信的坏的匹配) We therefore store all candidates in a priority queue Q and always select the candidate with highest expected matching confidence for stereo matching.
这一段主要在说,我们在一个像素一像素match、计算中,需要维持一个优先队列,保证置信度最高的样本会优先得到匹配,这样的匹配更reliable,系统也更robust。
In some cases, a new match is computed for a pixel that has previously been processed.(原先被访问果) If the new confidence is higher than the previous one(新的置信度大于原先的置信度), then the new match information overwrites the old(新的信息覆盖原先的信息). In addition, each of the pixel’s 4neighbors are inserted in the queue with the same match information, if that neighboring pixel has not already been processed and determined to have a higher confidence.(除此之外,如果neighboring pixel没有被访问过,或者,新的置信度大于原先的置信度,那么就将新的信息插入到队列中,我觉得这里的四个neighbours应该是上下左右四个???) Note that, when revisiting a pixel, the set of active views A is reset and allowed to draw from the entire neighborhood set N using the local view selection criteria.(当重新访问一个pixel时,需要将A重置,并且要重新使用LVS算法从N中取得A,因为在LVS中需要根据一个pixel的初始化信息才能计算出A,每一个像素对应一个A)。
这一段,主要说了如何应对重新访问过的pixel情况,并且如何添加新的neighbours进入队列。
Initializing the Priority Queue The SfM features visible in R provide a robust but sparse estimate of the scene geometry and are therefore well suited to initialize Q.(利用R中的feature point去初始化Q) We augment this set with additional feature points visible in all the neighboring views in N, projecting them into R to determine their pixel locations.(我们将所有可以被neighboring View 可见的feature point所对应的空间点投影到R view(在R view上实质上不存在这些点),并将这些点添加到Q中) Note that this additional set can include points that are not actually visible in R; these bad initializations are likely to be over-written later.(虽然感觉可能时一种不好的初始化,但是这种初始化在后面的计算中会被覆盖)
这一段主要在说如何初始化的问题:将R中通过SFM计算得到的feature point 加入到队列Q中,同时添加一个additional集合。
Then, for each of the features points, we run the stereo matching procedure, initialized with the feature’s depth and a fronto-parallel normal, to compute a depth, normal, and confidence. The results comprise the initial contents of Q.
这一段主要在说,对于每一个feature point,我们运行立体匹配过程,计算每一个点的相关信息。
6.2 Stereo Matching as Optimization
We interpret an n × n pixel window centered on a pixel in the reference view R as the projection of a small planar patch in the scene.(这个地方给出了一个定义:planar patch(平面块)) Our goal in the matching phase is then to optimize over the depth and orientation of this patch to maximize photometric consistency with its projections into the neighboring views.(在本阶段,我们的主要任务是在depth和orientation方面进行优化,以此获得最大的photometric consistency 这个photometric consistency在计算时要与它在neighboring view中的投影进行比较) Some of these views might not match, e.g., due to occlusion or other issues. Such views are rejected as invalid for that patch and replaced with other neighboring views provided by the local view selection step.(如果找不到匹配的view,使用LVS提供的neighboing views进行替代)

这一段主要在说我们在算法的过程中的主要任务:在R中选取一个n x n的平面块投影,在LVS产生的A中选取V,获得平面块在V中的投影,然后,通过优化depth 和orientation使得photometric consistency最大化。
Scene Geometry Model We assume that scene geometry visible in the n × n pixel window centered at a pixel location (s,t) in the reference view is well modeled by a planar, oriented window at depth h(s,t) (see Figure 3). The 3D position xR(s,t) of the point projecting to the central pixel is then
![]()
where oR is the center of projection of view R and rR(s,t) is the normalized ray direction through the pixel. We encode the window orientation using per-pixel distance offsets hs(s,t) and ht(s,t), corresponding to the per-pixel rate of change of depth in the s and t directions, respectively. The 3D position of a point projecting to a pixel inside the matching window is then
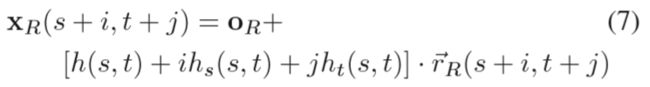
with i,j = −(n−1) /2 … (n−1)/ 2 . Note that this only approximates a planar window but we assume that the error is negligible for small n, i.e., when ~rR(s + i,t + j) ≈ ~rR(s,t). We can now determine the corresponding locations in a neighboring view k with sub-pixel accuracy using that view’s projection Pk(xR(s+i,t+j)). This formulation replaces the commonly used per-view window-shaping parameters (see e.g., [8]) with an explicit representation of surface orientation that is consistent between all views, thus eliminating excess degrees of freedom.
上面这一大段介绍了一个scene geometry model,基本的思路就是根据一个pixel作为几何中心,然后计算出它n x n 范围内的空间点坐标。
Photometric Model While we could in principle model a large number of reflectance effects to increase the ability to match images taken under varying conditions, this comes at the cost of adding more parameters. Doing so increases not only the computational effort but also decreases the stability of the optimization. (我们可以通过反射效应增加匹配图片的能力,但是,这样会增大计算量,并且会降低优化能力)We instead use a simple model for reflectance effects—a color scale factor ck for each patch projected into the k-th neighboring view. Given constant illumination(光照)over the patch area in a view (but different from view to view) and a planar surface, this perfectly models Lambertian reflectance. *The model fails for example when the illumination changes within the patch (e.g., at shadow boundaries or caustics) or when the patch contains a specular highlight. It also fails when the local contrast changes between views, e.g., for bumpy surfaces viewed under different directional illumination or for surfaces that are wet in some views but not others [16].
In practice, this model provides sufficient invariance to yield good results on a wide range of scenes, when used in combination with view selection.(模型失败的情况)Furthermore, the range of views reliably matched with this model is well-correlated to images that match well using the SIFT detector
上面这一大段介绍了一个光学模型,即使用一个简单的,不需要太多计算量的模型,Lambertian reflectance,这个模型在大多数的情况下成立,基本能够覆盖日常可以见到的场景。
MPGC Matching with Outlier Rejection Given the models in the previous section we can now relate the pixel intensities(像素强度) within a patch in R to the intensities in the k-th neighboring view:
with i,j = −(n−1)/ 2 …( n−1)/ 2 , k = 1…m where m = |A| is the number of neighboring views under consideration. Omitting the pixel coordinates (s,t) and substituting in Equation 7, we get
In the case of a 3-channel color image, Equation 9 represents three equations, one per color channel. Thus, considering all pixels in the window and all neighboring views, we have 3(n^2)m equations to solve for 3+3m unknowns: h, hs, ht, and the per-view color scale ck.(3m个) (In all of our experiments, we set n = 5 and m = 4.) To solve this overdetermined nonlinear system we follow the standard MPGC approach [8, 1] and linearize Equation 9:
Given an initial value for h, hs, and ht (which we then hold fixed), we can solve for dh, dhs, dht, and the ck using linear least squares. Then we update h, hs, and ht by adding to them dh, dhs, and dht, respectively, and iterate.


上面这些,围绕pixel intensities展开,根据前面对两个模型的介绍,我们跟容易得出公式(8)进一步得到公式(9)。
这个地方我也不是太明白为什么这样转化到公式(10),但是目的就是为了解决公式(9)这个非线性系统。具体运算的过程中就是对dh,dhs,dht,分别独立运算,并进行迭代。这样的话,我们就可以得到每一个点的深度信息了。
In this optimization we are essentially solving for the parameters that minimize the sum of squared differences (SSD) between pixels in the reference window and pixels in the neighboring views.(在最优化的过程中,我们本质上是在获得使SSD最小的参数) We could have instead optimized with respect to sums of NCC’s.(我们可以对NCC的和进行优化) The behaviors of these metrics are somewhat different, however. Consider the case of a linear gradient in intensity across a planar portion of the scene. After removing the mean and normalizing, NCC would permit shifted windows to match equally well, resulting in an unwanted depth ambiguity.(在移除平均值并进行规范化之后,NCC将允许移位的窗口匹配得同样好,从而导致不必要的深度模糊。) Now consider the case of an unshadowed planar region with constant albedo.(反射率) The SSD optimization, after estimating the scale factor, will converge to a minimum with nearly zero error, essentially fitting to the noise.(SSD优化在估计尺度因子后,收敛到最小值,误差接近于零,基本符合噪声) By contrast, after removing the mean, NCC is essentially measuring the correlation of the noise between two views, which will be low. In this case, NCC provides a good measure of how (un-)confident(置信度) we are in the solution. As described below, we have opted to use SSD for the parameter estimation, while using NCC to measure confidence, as well as convergence. (如下所述,我们选择使用SSD进行参数估计,同时使用NCC来度量置信度和收敛性。)
这一段的话主要在分析算法的一些特性,SSD和NCC。这里有讲到removing the mean,对应的就是之前讲的那个mean-removed
NCC。但是还是没有给出具体的公式。
While the iterative optimization approach described above tends to converge quickly (i.e., within a couple of iterations given good initial values), matching problems will yield slow convergence, oscillation(震荡), or convergence to the wrong answer [7]. We therefore include specific mechanisms(机制) into the optimization to prevent these effects.
迭代优化会更快地收敛,但是还是由很多地问题,需要引入一定地机制进行优化。
We first perform 5 iterations to allow the system to settle. (先迭代5次)After each subsequent iteration, we compute the NCC score between the patch in the reference view and each neighboring view. We then reject all views with an NCC score below an acceptance threshold (typically κ = 0.4). If no view was rejected and all NCC scores changed by no more than ǫ = 0.001 compared to the previous iteration, we assume that the iteration has converged.(收敛条件) Otherwise, we add missing views to the active set and continue to iterate.(否则加入没有被选入A地view进行继续迭代) The iteration fails if we do not reach convergence after 20 iterations or the active set contains less than the required number of views.(20次迭代都没有收敛,或者A的view数目小于预定值 4 就判定为迭代失败) In practice, we modify the above procedure in two ways to improve its behavior significantly. First, we update the normal and color scale factors only every fifth iteration or when the active set of neighboring views has changed. (每5次迭代或者A的view发生变化更新一下normal 和 color scale)This improves performance and reduces the likelihood of oscillation. Second, after the 14th iteration (i.e., just before an update to the color scale factors and normal), we reject all views whose NCC score changed by more than ǫ to stop a possible oscillation. If the optimization converges and the dot product between normal and the viewing ray ~rR(s,t) is above 0.1, we compute a confidence score C as the average NCC score between the patch in the reference view and all active neighboring views, normalized from [κ…1] to [0…1]. We use this score to determine how to update the depth, normal, and confidence maps and Q, as described in Section 6.1.
这一段主要讲了一些,在真正的计算过程中所做的一些改进和优化方法。
啊!终于看完了~总结下!
大体总结下该文章中所实现的MVS的一个总过程:
准备阶段
图片预处理。
SFM,完成相机的标定和稀疏点云的获取。正式开始阶段
Global View Selection,根据提供的R选择出neighboring views N。
在R中选取feature point 和 N中所有图像的feature point在R中的projection加入到Q(优先队列中)。
根据Q中各个pixel的置信度(confidence)依次取出,根据该pixel是否之前被访问过做出相应的逻辑处理,并添加或者替换它的4个neighbors 。
利用Local View Selection根据初始化的pixel选取一个集合A,为后面的计算做准备。
利用SSD对选出来的pixel进行参数(depth、normal)优化,同时利用NCC对pixel 的confidence进行重新计算。
遗留问题:
这篇文章看下来,感觉还是有很多地方不是很懂的,文中对region growing过程的结束条件没有说清楚,不过我感觉应该是将Q中所有的点计算完成后就会停止,跟BFS有点儿类似。另外,关于mean-removed NCC也没有给出一个详细的算法说明,查资料也查不到······这些的话,日后找找它的开源代码看下吧。
这篇论文在我三天的努力下,终于看完了,理解了个60%吧,还有很多地方感觉不是很清楚,以后有机会再补充下。
最终声明:本文一定会存在理解不到位或者错误的地方,欢迎指正!