机器学习中软投票和硬投票的不同含义和理解
分类问题:目标值是离散型的,比如男女,大小等
回归问题:目标值是连续的,在某一区间内任意取值,比如房价等
设置一个场景,比如对于今天音乐会韩红会出现的概率三个人三个观点
A:韩红出现的概率为47%
B:韩红出现的概率为57%
C:韩红出现的概率为97%
软投票:软投票会认为韩红出现的概率为1/3*(47%+57%+97%)=67%
硬投票:硬投票会认为韩红出现的概率为97%直接取最大
显然从字面上理解,软投票要比硬投票靠谱得多
试验测试一下
硬投票实验:
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
import numpy as np
x,y=make_moons(n_samples=500,noise=0.3,random_state=42)
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=42)
print(np.shape(x))
print(np.shape(y))
plt.plot(x[:,0][y==0], x[:,1][y==0],'yo',alpha=0.6)
plt.plot(x[:,0][y==1], x[:,1][y==1],'bs',alpha=0.6)
##投票器
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
##逻辑回归
from sklearn.linear_model import LogisticRegression
##SVM分类器
from sklearn.svm import SVC
####硬投票
log_cls=LogisticRegression() ##线性回归实例化
rand_cls=RandomForestClassifier() ##随机森林实例化
svm_cls=SVC() ##SVM分类器实例化
##投票分类器
voting_clf=VotingClassifier(estimators=[('lr',log_cls),('rf',rand_cls),('svc',svm_cls)],voting='hard')##voting='hard'设置为硬投票
voting_clf.fit(x_train,y_train)
#看准确率的 https://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html#sklearn.metrics.accuracy_score
from sklearn.metrics import accuracy_score
for clf in (log_cls,rand_cls,svm_cls,voting_clf):
clf.fit(x_train,y_train)
y_pred=clf.predict(x_test)
print(clf.__class__.__name__,accuracy_score(y_test,y_pred))
#硬投票的意思就是取最大的概率值
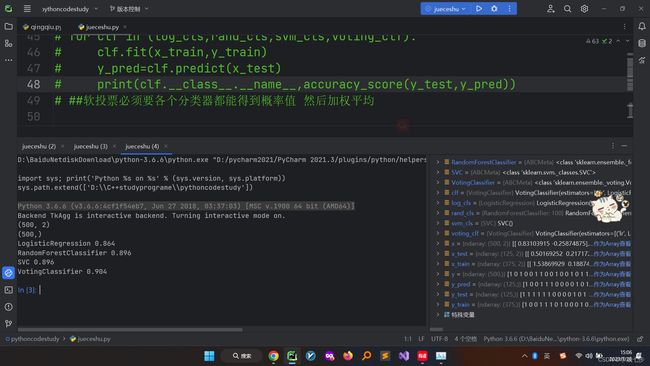
LogisticRegression 0.864
RandomForestClassifier 0.896
SVC 0.896
VotingClassifier 0.904
###软投票
log_cls=LogisticRegression(random_state=42) ##线性回归实例化
rand_cls=RandomForestClassifier(random_state=42) ##随机森林实例化
svm_cls=SVC(probability=True,random_state=42) ##SVM分类器实例化
##投票分类器
voting_clf=VotingClassifier(estimators=[('lr',log_cls),('rf',rand_cls),('svc',svm_cls)],voting='soft')##voting='soft'设置为软投票
voting_clf.fit(x_train,y_train)
#看准确率的 https://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html#sklearn.metrics.accuracy_score
from sklearn.metrics import accuracy_score
for clf in (log_cls,rand_cls,svm_cls,voting_clf):
clf.fit(x_train,y_train)
y_pred=clf.predict(x_test)
print(clf.__class__.__name__,accuracy_score(y_test,y_pred))
##软投票必须要各个分类器都能得到概率值 然后加权平均
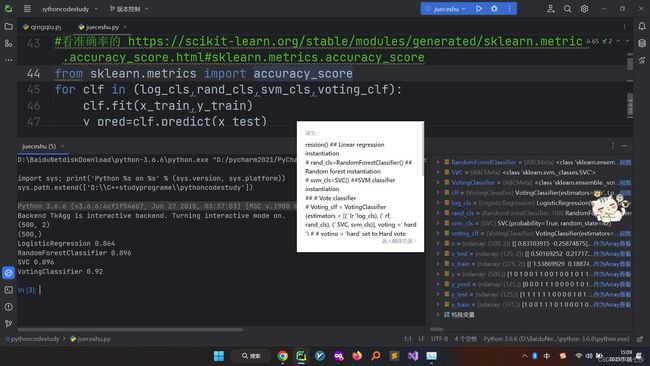
LogisticRegression 0.864
RandomForestClassifier 0.896
SVC 0.896
VotingClassifier 0.92
实验看来 软投票也更靠谱,所以,直接用软投票吧 别折腾了
至于有人私信问我为什么random_state = 42random_state 参数为什么要设置为42,至于这个问题,透过问题看本质,这个参量的意思是设置随机种子,42的话就是习惯了,可以理解为行业标准。
- 泰坦尼克号与冰山相撞时时速为42公里。
- 在哈利波特与魔法石的第 42 页,哈利发现自己是个巫师。
- 在启示录中,预言兽将在地球上统治 42 个月。
- 42 是圆整到彩虹出现的整数度的角度(临界角)。
- 数学家刘易斯卡罗尔在他的作品中多次使用这个数字。
无法解释,以后就记住就可以了。random_state=42