Day07-集成学习-机器学习-投票法(DataWhale)
一、投票法
1.1 介绍
原理
遵循少数服从多数原则,通过多个模型的集成降低方差。理想情况,投票法的预测效果优于任何一个基模型的预测结果
分类
- 回归投票法:预测结果是所有模型预测结果的平均值
- 分类投票法:预测结果是所有模型中出现最多的预测结果
- 硬投票:所有投票结果出现最多的类
- 软投票:所有投票结果中概率和平均最大的类
原则
想要投票法产生较好的结果,需要满足:
- 基模型之间的效果不能差别很大。当某个模型相对于其他基模型效果差时,该模型可能是噪声
- 基模型之间应该有较小的同质性。例如在基模型预测效果近似的情况下,基于树模型与线性模型的投票,往往优于两个树模型或两个线性模型
投票模型是一种集合模型,适用于多个基模型,每个基模型位于整个数据集上。然后对单个预测进行平均值,形成最终预测。【将多个模型的结果结合起来形成最终的结果】
1.2 VotingRegressor
适用于回归
基础
sklearn.ensemble.VotingRegressor(estimators, *, weights=None, n_jobs=None, verbose=False)
参数
- estimators
- weights:权重序列
- verbose:为True时,拟合时经过的时间将拟合完成时打印出来
属性 - estimators_:估计器参数的元素,已在训练数据上拟合
- named_estimators_:按名称访问任何拟合的子估计器
方法 - fit(X)
- fit_transform(X):拟合估计器和变换数据集
- get_params
- predict
- score: R 2 R^2 R2
- set_params
- transform(X):返回每个估计器X的类标签或概率
实例
使用糖尿病数据集,从一组糖尿病患者中收集10个特征组成。该标签时基线一年后疾病进展的定量指标。
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.ensemble import GradientBoostingRegressor #1.补充知识
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import VotingRegressor
# 1.训练分类器
X, y = load_diabetes(return_X_y = True)
reg1 = GradientBoostingRegressor(random_state=1)
reg2 = RandomForestRegressor(random_state=1)
reg3 = LinearRegression()
reg1.fit(X,y)
reg2.fit(X,y)
reg3.fit(X,y)
ereg = VotingRegressor([('gb',reg1),('rf',reg2),('lr',reg3)])
ereg.fit(X,y)
VotingRegressor(estimators=[('gb', GradientBoostingRegressor(random_state=1)),
('rf', RandomForestRegressor(random_state=1)),
('lr', LinearRegression())])
# 2. 作出预测
xt = X[:20]
pred1 = reg1.predict(xt)
pred2 = reg2.predict(xt)
pred3 = reg3.predict(xt)
pred4 = ereg.predict(xt)
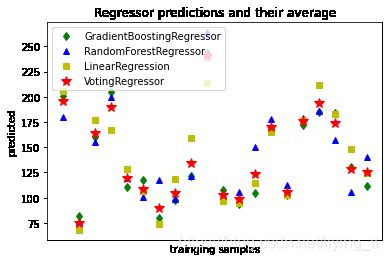
# 绘制结果
plt.figure()
plt.plot(pred1, 'gd', label='GradientBoostingRegressor')
plt.plot(pred2, 'b^', label='RandomForestRegressor')
plt.plot(pred3, 'ys', label='LinearRegression')
plt.plot(pred4, 'r*', ms=10, label='VotingRegressor')
plt.tick_params(axis='x', which='both', bottom=False, top=False, labelbottom=False)
plt.ylabel('predicted')
plt.xlabel('trainging samples')
plt.legend(loc='best')
plt.title('Regressor predictions and their average')
Text(0.5, 1.0, 'Regressor predictions and their average')
1.3 VotingClassifier
适用于分类
基础
sklearn.ensemble.VotingClassifier(estimators, *, voting='hard', weights=None, n_jobs=None, flatten_transform=True, verbose=False)
参数
- estimators
- voting:{‘hard’,‘soft’},default=‘hard’。hard:使用预测的类标签进行多数决定投票;soft:预测的类标签基于预测概率总和的最大值。
- weights
- n_jobs
- flatten_transform:若voting=‘soft’,则为True,返回(n_samples,n_classifiers*n_calsses)的矩阵。若为False,返回(n_classifiers,n_samples,n_calsses)
- verbose
属性 - estimators_
- named_estimators_
- classes_:类标签
方法 - fit(X,y)
- fit_transform
- get_params
- predict
- score
- set_params
- transform(X)
实例
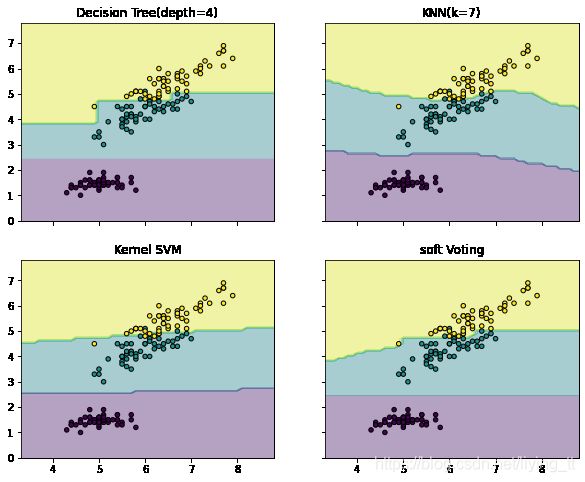
使用Iris数据集的两个特征绘制投票分类器的决策边界
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
iris = datasets.load_iris()
X = iris.data[:,[0,2]]
y = iris.target
# 1.训练分类器
clf1 = DecisionTreeClassifier(max_depth=4)
clf2 = KNeighborsClassifier(n_neighbors=7)
clf3 = SVC(gamma=0.1, kernel='rbf', probability=True)
eclf = VotingClassifier(estimators=[('dt',clf1),('knn',clf2),('svc',clf3)],
voting='soft',weights=[2,1,2])
clf1.fit(X,y)
clf2.fit(X,y)
clf3.fit(X,y)
eclf.fit(X,y)
VotingClassifier(estimators=[('dt', DecisionTreeClassifier(max_depth=4)),
('knn', KNeighborsClassifier(n_neighbors=7)),
('svc', SVC(gamma=0.1, probability=True))],
voting='soft', weights=[2, 1, 2])
# 2. 绘制决策边界
from itertools import product #product返回笛卡尔积
x_min, x_max = X[:,0].min()-1, X[:,0].max()+1
y_min, y_max = X[:,1].min()-1, X[:,1].max()+1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),
np.arange(y_min, y_max, 0.1))
f,axarr = plt.subplots(2, 2, sharex='col', sharey='row', figsize=(10,8))
for idx, clf, tt in zip(product([0,1],[0,1]),
[clf1, clf2, clf3, eclf],
['Decision Tree(depth=4)','KNN(k=7)','Kernel SVM','soft Voting']):
Z = clf.predict(np.c_[xx.ravel(),yy.ravel()]) #np.c_:按行连接矩阵;np.r_:按列连接矩阵。ravel():将多维降为一维
Z = Z.reshape(xx.shape)
axarr[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.4)
axarr[idx[0], idx[1]].scatter(X[:,0],X[:,1], c=y, s=20, edgecolor='k')
#contour和contourf都是画三维等高线图的,不同点在于contour() 是绘制轮廓线,contourf()会填充轮廓
axarr[idx[0],idx[1]].set_title(tt)
plt.show()
1.4 案例分析
# 1. 创建一个1000个样本,20个特征的随机数据集
from sklearn.datasets import make_classification
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
X,y = make_classification(n_samples=1000, n_features=20,
n_informative=15, n_redundant=5, random_state=2)
print(X.shape, y.shape)
(1000, 20) (1000,)
# 2. KNN模型作为基模型演示投票法,每个模型采用不同的邻居值k参数
# 得到投票模型get_voting()
def get_voting():
models = list()
models.append(('knn1',KNeighborsClassifier(n_neighbors=1)))
models.append(('knn3',KNeighborsClassifier(n_neighbors=3)))
models.append(('knn5',KNeighborsClassifier(n_neighbors=5)))
models.append(('knn7',KNeighborsClassifier(n_neighbors=7)))
models.append(('knn9',KNeighborsClassifier(n_neighbors=9)))
ensemble = VotingClassifier(estimators=models,voting='hard')
return ensemble
# 3. 评估投票带来的提升。get_models()函数可以创建模型列表进行评估
def get_models():
models = dict()
models['knn1'] = KNeighborsClassifier(n_neighbors=1)
models['knn3'] = KNeighborsClassifier(n_neighbors=3)
models['knn5'] = KNeighborsClassifier(n_neighbors=5)
models['knn7'] = KNeighborsClassifier(n_neighbors=7)
models['knn9'] = KNeighborsClassifier(n_neighbors=9)
models['hard_voting'] = get_voting()
return models
# 4. evaluate_model()函数接受模型实例,并以分层10倍交叉验证三次重复的分数列表的形式返回
def evaluate_model(model, X, y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
return scores
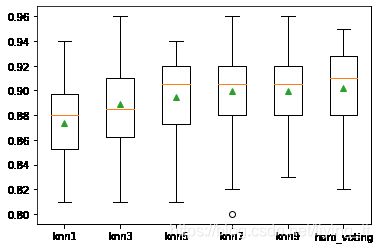
# 5. 报告每个算法的平均性能,并创建一个箱型图和须状图来比较每个算法的精度分数分布
models = get_models()
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model, X, y)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, np.mean(scores), np.std(scores)))
plt.boxplot(results, labels=names, showmeans=True)
plt.show()
>knn1 0.873 (0.030)
>knn3 0.889 (0.038)
>knn5 0.895 (0.031)
>knn7 0.899 (0.035)
>knn9 0.900 (0.033)
>hard_voting 0.902 (0.034)
Z1. sklearn.datasets.make_classification
sklearn.datasets.make_classification(n_samples=100, n_features=20, *, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None)
生成随机的n类分类问题
参数
- n_samples:样本数
- n_features:特征总数,包n_informative,n_redundant,n_repeated和其他无用特征
- n_informative
- n_redundant:冗余特征,作为信息特征的随机线性组合生成
- n_repeated:从信息特征和冗余特征中随机抽取的重复性特征的数量
- n_classes:分类问题的类
- n_clusters_per_class:每个类的簇数
- weights
- flip_y:类别随机分配的样本比例。较大的值会在标签中引入噪声,使分类任务更难
- hypercube:True:簇放置在超立方体的顶点。False:簇放置在随机多面体的顶点
- shift:指定值移动特征。None则将特征移动[-class_sep,class_sep]中绘制的随机值
- scale:将特征乘以指定值。None则将按[1,100]中绘制的随机值缩放。缩放发生在移动之后
- shuffle:shuffle样本和特征
- random_state:随机种子,确保生成随机数据的一致性
Z2. neighbors.KNeighborsClassifier
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None, **kwargs)
算法原理
未标记样本的类别,由距离其最近的k个邻居投票决定。计算待标记样本和数据集中每个样本的距离,取距离最近的k个样本。
- k值越大,模型的偏差越大,对噪声数据越不敏感,当k值很大时,可能造成欠拟合
- k值越小,模型的方差越小,k值太小时,会造成过拟合
参数
- n_neighbors
- weights
- algorithm:ball_tree\kd_tree\brute\auto
- leaf_size
- p:Minkowski指标的功率参数
- metric:树使用的距离度量。默认为minkoeski
- metric_params
属性
- classes_
- effective_metric_:使用的距离度量
- effective_metric_params
- outputs_2d_:在拟合期间,当y的形状为(n_samples,)或(n_samples,1)时为False,否则为True。
方法
- fit
- get_params
- kneighbors:查找点的k临近点
- kneighbors_graph:计算X中点的k临近点的(加权)图
- predict_proba:测试数据X的返回概率估计
- score
- set_params