阿里天池 NLP 入门赛 Bert 方案 -2 Bert 源码讲解
前言
这篇文章用于记录阿里天池 NLP 入门赛,详细讲解了整个数据处理流程,以及如何从零构建一个模型,适合新手入门。
赛题以新闻数据为赛题数据,数据集报名后可见并可下载。赛题数据为新闻文本,并按照字符级别进行匿名处理。整合划分出 14 个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据。实质上是一个 14 分类问题。
赛题数据由以下几个部分构成:训练集 20w 条样本,测试集 A 包括 5w 条样本,测试集 B 包括 5w 条样本。
比赛地址:https://tianchi.aliyun.com/competition/entrance/531810/introduction
数据可以通过上面的链接下载。
代码地址:https://github.com/zhangxiann/Tianchi-NLP-Beginner
分为 3 篇文章介绍:
- 数据预处理
- Bert 源码讲解
- Bert 预训练与分类
在上一篇文章中,我们介绍了数据预处理的流程。
这篇文章主要讲解 Bert 源码。
Bert 代码讲解
Bert 模型来自于 Transformer 的编码器,主要代码是 modeling.py。
BertConfig
我们先看下 BertConfig 类,这个类用于配置 BertModel 的超参数。用于读取 bert_config.json 文件中的参数。
bert_config.json 中的参数以及解释如下:
{
"hidden_size": 256, # 隐藏层的输出向量长度
"hidden_act": "gelu", # 激活函数
"initializer_range": 0.02, # 参数初始化的范围
"vocab_size": 5981, # 字典大小
"hidden_dropout_prob": 0.1, # 隐藏层 dropout 概率
"num_attention_heads": 4, # 每个 隐藏层 的 attention head 个数
"type_vocab_size": 2, # segment_ids类别 [0,1],句子个数
"max_position_embeddings": 256, #一个大于seq_length的参数,用于生成position_embedding
"num_hidden_layers": 4, # 隐藏层数量
"intermediate_size": 1024, # 前馈神经网络中的升维维度
"attention_probs_dropout_prob": 0.1 # 计算 attention 时,softmax 后 dropout 概率
}
BertModel
BertModel 的输入参数如下:
- config:
BertConfig对象,用于配置超参数 - input_ids:经过 mask 的 token,形状是 [batch_size, seq_length]
- input_mask:句子的 mask 列表,1 表示对应的位置有 token,0 表示对应的位置没有 token,形状是 [batch_size, seq_length]
- token_type_ids:句子 id,形状是 [batch_size, seq_length]
- use_one_hot_embeddings:是否使用 one hot 来获取 embedding。如果词典比较大,使用 one hot 比较快;如果词典比较小,不使用 one hot 比较快。
主要流程如下:
- 调用
embedding_lookup(),把input_ids转换为embedding,返回embedding_output,embedding_table。 - 调用
embedding_postprocessor(),将embedding_output添加位置编码和句子 id 的编码。 - 调用
create_attention_mask_from_input_mask(),根据input_mask创建attention_mask。 - 调用
transformer_model,创建 Bert 模型,输入数据,得到最后一层 encoder 的输出sequence_output。 - 取出
sequence_output中第一个 token 的输出,经过全连接层,得到pooled_output。
class BertModel(object):
"""BERT model ("Bidirectional Encoder Representations from Transformers").
Example usage:
input_ids = tf.constant([[31, 51, 99], [15, 5, 0]])
# input_mask = tf.constant([[1, 1, 1], [1, 1, 0]])
# token_type_ids = tf.constant([[0, 0, 1], [0, 2, 0]])
#
# config = modeling.BertConfig(vocab_size=32000, hidden_size=512,
# num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
#
# model = modeling.BertModel(config=config, is_training=True,
# input_ids=input_ids, input_mask=input_mask, token_type_ids=token_type_ids)
#
# label_embeddings = tf.get_variable(...)
# pooled_output = model.get_pooled_output()
# logits = tf.matmul(pooled_output, label_embeddings)
# ...
def __init__(self,
config,
is_training,
input_ids,
input_mask=None,
token_type_ids=None,
use_one_hot_embeddings=False,
scope=None):
"""Constructor for BertModel.
Args:
config: `BertConfig` instance.
is_training: bool. true for training model, false for eval model. Controls
whether dropout will be applied.
input_ids: int32 Tensor of shape [batch_size, seq_length].
input_mask: (optional) int32 Tensor of shape [batch_size, seq_length].
token_type_ids: (optional) int32 Tensor of shape [batch_size, seq_length].
use_one_hot_embeddings: (optional) bool. Whether to use one-hot word
embeddings or tf.embedding_lookup() for the word embeddings.
scope: (optional) variable scope. Defaults to "bert".
Raises:
ValueError: The config is invalid or one of the input tensor shapes
is invalid.
"""
config = copy.deepcopy(config)
# 如果不是训练,那么就是测试,取消 dropout
if not is_training:
config.hidden_dropout_prob = 0.0
config.attention_probs_dropout_prob = 0.0
# 把 shape 转为 list
input_shape = get_shape_list(input_ids, expected_rank=2)
batch_size = input_shape[0]
seq_length = input_shape[1]
if input_mask is None:
input_mask = tf.ones(shape=[batch_size, seq_length], dtype=tf.int32)
if token_type_ids is None:
token_type_ids = tf.zeros(shape=[batch_size, seq_length], dtype=tf.int32)
with tf.variable_scope(scope, default_name="bert"):
with tf.variable_scope("embeddings"):
# Perform embedding lookup on the word ids.
# embedding_output: [batch_size, seq_length, hidden_size]
# embedding_table: [vocab_size, hidden_size]
(self.embedding_output, self.embedding_table) = embedding_lookup(
input_ids=input_ids,
vocab_size=config.vocab_size,
embedding_size=config.hidden_size,
initializer_range=config.initializer_range,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=use_one_hot_embeddings)
# Add positional embeddings and token type embeddings, then layer
# normalize and perform dropout.
# 添加位置的 embedding
# embedding_output: [batch_size, seq_length, hidden_size]
self.embedding_output = embedding_postprocessor(
input_tensor=self.embedding_output,
use_token_type=True,
token_type_ids=token_type_ids,
token_type_vocab_size=config.type_vocab_size,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=config.initializer_range,
max_position_embeddings=config.max_position_embeddings,
dropout_prob=config.hidden_dropout_prob)
with tf.variable_scope("encoder"):
# This converts a 2D mask of shape [batch_size, seq_length] to a 3D
# mask of shape [batch_size, seq_length, seq_length] which is used
# for the attention scores.
# attention_mask: [batch_size, seq_length, seq_length]
attention_mask = create_attention_mask_from_input_mask(
input_ids, input_mask)
# Run the stacked transformer.
# `sequence_output` shape = [batch_size, seq_length, hidden_size].
self.all_encoder_layers = transformer_model(
input_tensor=self.embedding_output,
attention_mask=attention_mask,
hidden_size=config.hidden_size,
num_hidden_layers=config.num_hidden_layers,
num_attention_heads=config.num_attention_heads,
intermediate_size=config.intermediate_size,
intermediate_act_fn=get_activation(config.hidden_act),
hidden_dropout_prob=config.hidden_dropout_prob,
attention_probs_dropout_prob=config.attention_probs_dropout_prob,
initializer_range=config.initializer_range,
do_return_all_layers=True)
# 取出最后一层 encoder 的输出
self.sequence_output = self.all_encoder_layers[-1]
# The "pooler" converts the encoded sequence tensor of shape
# [batch_size, seq_length, hidden_size] to a tensor of shape
# [batch_size, hidden_size]. This is necessary for segment-level
# (or segment-pair-level) classification tasks where we need a fixed
# dimensional representation of the segment.
with tf.variable_scope("pooler"):
# We "pool" the model by simply taking the hidden state corresponding
# to the first token. We assume that this has been pre-trained
# 取出第一个 token 对应的 输出,也就是 [CLS] 对应的输出
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
# 经过全连接层,得到最终的输出
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))
# 取出最后一层 encoder ,第一个 token 的输出
def get_pooled_output(self):
return self.pooled_output
# 获取最后一层 encoder 的 output
def get_sequence_output(self):
"""Gets final hidden layer of encoder.
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size] corresponding
to the final hidden of the transformer encoder.
"""
return self.sequence_output
# 获取所有隐藏层的输出
def get_all_encoder_layers(self):
return self.all_encoder_layers
# 返回经过 positional embedding、token type embedding、以及 layer norm 的数据
# [batch_size, seq_length, hidden_size]
def get_embedding_output(self):
"""Gets output of the embedding lookup (i.e., input to the transformer).
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size] corresponding
to the output of the embedding layer, after summing the word
embeddings with the positional embeddings and the token type embeddings,
then performing layer normalization. This is the input to the transformer.
"""
return self.embedding_output
# 返回词向量的矩阵: [vocab_size, hidden_size]
def get_embedding_table(self):
return self.embedding_table
代码注释中给出了使用 BertModel 的 demo,如下所示:
input_ids = tf.constant([[31, 51, 99], [15, 5, 0]])
input_mask = tf.constant([[1, 1, 1], [1, 1, 0]])
token_type_ids = tf.constant([[0, 0, 1], [0, 2, 0]])
config = modeling.BertConfig(vocab_size=32000, hidden_size=512, num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
model = modeling.BertModel(config=config, is_training=True, input_ids=input_ids, input_mask=input_mask, token_type_ids=token_type_ids)
label_embeddings = tf.get_variable(...)
pooled_output = model.get_pooled_output()
logits = tf.matmul(pooled_output, label_embeddings)
embedding_lookup()
embedding_lookup() 的作用是根据 input_ids,返回对应的词向量矩阵 embedding_output ,和整个词典的词向量矩阵 embedding_table。
主要流程如下:
- 首先获取词典的 embedding 矩阵
embedding_table。 - 判断是否使用 one hot,根据
input_ids获取对应的ouput。 - 返回
ouput和embedding_table。
def embedding_lookup(input_ids,
vocab_size,
embedding_size=128,
initializer_range=0.02,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=False):
"""Looks up words embeddings for id tensor.
Args:
input_ids: int32 Tensor of shape [batch_size, seq_length] containing word
ids.
vocab_size: int. Size of the embedding vocabulary.
embedding_size: int. Width of the word embeddings.
initializer_range: float. Embedding initialization range.
word_embedding_name: string. Name of the embedding table.
use_one_hot_embeddings: bool. If True, use one-hot method for word
embeddings. If False, use `tf.gather()`.
Returns:
float Tensor of shape [batch_size, seq_length, embedding_size].
"""
# This function assumes that the input is of shape [batch_size, seq_length,
# num_inputs].
#
# If the input is a 2D tensor of shape [batch_size, seq_length], we
# reshape to [batch_size, seq_length, 1].
if input_ids.shape.ndims == 2:
input_ids = tf.expand_dims(input_ids, axis=[-1])
# 获取 embedding table: [vocab_size, embedding_size]
embedding_table = tf.get_variable(
name=word_embedding_name,
shape=[vocab_size, embedding_size],
initializer=create_initializer(initializer_range))
# flat_input_ids: [batch_size * seq_length, 1]
flat_input_ids = tf.reshape(input_ids, [-1])
if use_one_hot_embeddings:
# # 如果是 one hot,直接相乘,就可以得到 embedding
one_hot_input_ids = tf.one_hot(flat_input_ids, depth=vocab_size)
output = tf.matmul(one_hot_input_ids, embedding_table)
else:
# 如果不是 one hot,那么根据 index 取出 embedding
output = tf.gather(embedding_table, flat_input_ids)
input_shape = get_shape_list(input_ids)
# output: [batch_size * seq_length, embedding_size]
# -> [batch_size, seq_length, embedding_size]
output = tf.reshape(output,
input_shape[0:-1] + [input_shape[-1] * embedding_size])
return (output, embedding_table)
embedding_postprocessor()
embedding_postprocessor() 的作用是将 embedding_output 添加位置编码和句子 id 的编码。
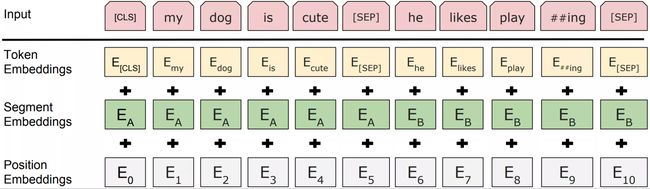
其中 Token Embeddings 对应 input_tensor;Segment Embedding 对应 token_type_embeddings;Position Embedding 对应 position_embeddings,3 者相加得到最终的输出。
流程如下:
- 首先把
input_tensor赋值给output。 - 根据
token_type_ids生成token_type_embeddings,表示句子 id 编码,加到output。 - 生成
position_embeddings,表示位置编码,加到output。代码中position_embeddings部分与论文中的方法不同。此代码中position_embeddings是训练出来的,而论文中的position_embeddings是固定值: P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d model ) , P E ( p o s , 2 i + 1 ) = cos ( p o s / 1000 0 2 i / d model ) \begin{aligned} P E_{(p o s, 2 i)} &=\sin \left(p o s / 10000^{2 i / d_{\text {model }}}\right), P E_{(p o s, 2 i+1)} =\cos \left(p o s / 10000^{2 i / d_{\text {model }}}\right) \end{aligned} PE(pos,2i)=sin(pos/100002i/dmodel ),PE(pos,2i+1)=cos(pos/100002i/dmodel )。
def embedding_postprocessor(input_tensor,
use_token_type=False,
token_type_ids=None,
token_type_vocab_size=16,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=0.02,
max_position_embeddings=512,
dropout_prob=0.1):
"""Performs various post-processing on a word embedding tensor.
Args:
input_tensor: float Tensor of shape [batch_size, seq_length,
embedding_size].
use_token_type: bool. Whether to add embeddings for `token_type_ids`.
token_type_ids: (optional) int32 Tensor of shape [batch_size, seq_length].
Must be specified if `use_token_type` is True.
token_type_vocab_size: int. The vocabulary size of `token_type_ids`.
token_type_embedding_name: string. The name of the embedding table variable
for token type ids.
use_position_embeddings: bool. Whether to add position embeddings for the
position of each token in the sequence.
position_embedding_name: string. The name of the embedding table variable
for positional embeddings.
initializer_range: float. Range of the weight initialization.
max_position_embeddings: int. Maximum sequence length that might ever be
used with this model. This can be longer than the sequence length of
input_tensor, but cannot be shorter.
dropout_prob: float. Dropout probability applied to the final output tensor.
Returns:
float tensor with same shape as `input_tensor`.
Raises:
ValueError: One of the tensor shapes or input values is invalid.
"""
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
# width 就是 embedding_size
width = input_shape[2]
# output: [batch_size, seq_length, embedding_size]
output = input_tensor
# 添加句子 id 的编码
if use_token_type:
if token_type_ids is None:
raise ValueError("`token_type_ids` must be specified if"
"`use_token_type` is True.")
# token_type_table: [token_type_vocab_size, embedding_size]
token_type_table = tf.get_variable(
name=token_type_embedding_name,
shape=[token_type_vocab_size, width],
initializer=create_initializer(initializer_range))
# This vocab will be small so we always do one-hot here, since it is always
# faster for a small vocabulary.
# flat_token_type_ids: [batch_size * seq_length]
flat_token_type_ids = tf.reshape(token_type_ids, [-1])
# one_hot_ids: [batch_size * seq_length, token_type_vocab_size]
one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size)
# 使用 one hot ,相乘得到 token_type_embeddings
token_type_embeddings = tf.matmul(one_hot_ids, token_type_table)
token_type_embeddings = tf.reshape(token_type_embeddings,
[batch_size, seq_length, width])
# 相加
# output: [batch_size, seq_length, embedding_size]
output += token_type_embeddings
if use_position_embeddings:
assert_op = tf.assert_less_equal(seq_length, max_position_embeddings)
with tf.control_dependencies([assert_op]):
# full_position_embeddings: [max_position_embeddings, embedding_size]
full_position_embeddings = tf.get_variable(
name=position_embedding_name,
shape=[max_position_embeddings, width],
initializer=create_initializer(initializer_range))
# Since the position embedding table is a learned variable, we create it
# using a (long) sequence length `max_position_embeddings`. The actual
# sequence length might be shorter than this, for faster training of
# tasks that do not have long sequences.
#
# So `full_position_embeddings` is effectively an embedding table
# for position [0, 1, 2, ..., max_position_embeddings-1], and the current
# sequence has positions [0, 1, 2, ... seq_length-1], so we can just
# perform a slice.
# 由于 full_position_embeddings 的长度是 max_position_embeddings,
# 而实际的句子长度是 seq_length。因此需要 slice 裁剪
# position_embeddings: [seq_length, embedding_size]
position_embeddings = tf.slice(full_position_embeddings, [0, 0],
[seq_length, -1])
num_dims = len(output.shape.as_list())
# Only the last two dimensions are relevant (`seq_length` and `width`), so
# we broadcast among the first dimensions, which is typically just
# the batch size.
position_broadcast_shape = []
for _ in range(num_dims - 2):
position_broadcast_shape.append(1)
# position_broadcast_shape: [1, seq_length, embedding_size]
position_broadcast_shape.extend([seq_length, width])
position_embeddings = tf.reshape(position_embeddings,
position_broadcast_shape)
# 相加
# output: [batch_size, seq_length, embedding_size]
output += position_embeddings
# layer norm
output = layer_norm_and_dropout(output, dropout_prob)
return output
create_attention_mask_from_input_mask()
create_attention_mask_from_input_mask() 的作用是根据 input_mask 创建 attention_mask,attention_mask 的形状是 [batch_size, from_seq_length, seq_length]。
# 从 2D 的 from_tensor
def create_attention_mask_from_input_mask(from_tensor, to_mask):
"""Create 3D attention mask from a 2D tensor mask.
Args:
from_tensor: 2D or 3D Tensor of shape [batch_size, from_seq_length, ...].
to_mask: int32 Tensor of shape [batch_size, to_seq_length].
Returns:
float Tensor of shape [batch_size, from_seq_length, to_seq_length].
"""
# from_tensor: [batch_size, seq_length]
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
batch_size = from_shape[0]
from_seq_length = from_shape[1]
# to_mask: [batch_size, seq_length]
to_shape = get_shape_list(to_mask, expected_rank=2)
# to_seq_length: seq_length
to_seq_length = to_shape[1]
# to_mask: [batch_size, 1, seq_length]
to_mask = tf.cast(
tf.reshape(to_mask, [batch_size, 1, to_seq_length]), tf.float32)
# We don't assume that `from_tensor` is a mask (although it could be). We
# don't actually care if we attend *from* padding tokens (only *to* padding)
# tokens so we create a tensor of all ones.
#
# `broadcast_ones` = [batch_size, from_seq_length, 1]
broadcast_ones = tf.ones(
shape=[batch_size, from_seq_length, 1], dtype=tf.float32)
# Here we broadcast along two dimensions to create the mask.
# mask: [batch_size, from_seq_length, seq_length]
mask = broadcast_ones * to_mask
return mask
transformer_model
transformer_model 就是 Bert 模型的真正实现,模型结构就是下图中的 左边部分。

主要流程如下:
- 输入
input_tensor的形状是[batch_size, seq_length, hidden_size],转换为prev_output,形状是[batch_size * seq_length, hidden_size]。 - 进入 for 循环,经过每一层 encoder:
- 输入
attention_layer,得到attention_head。attention_layer的作用是计算Self Attention。 attention_head经过一个全连接层和layer_norm层,得到attention_output。attention_output经过一个升维的全连接层和降维的全连接层,得到layer_output。- 将
attention_output和layer_output相加作为残差连接
- 输入
def transformer_model(input_tensor,
attention_mask=None,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
intermediate_act_fn=gelu,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False):
"""Multi-headed, multi-layer Transformer from "Attention is All You Need".
This is almost an exact implementation of the original Transformer encoder.
See the original paper:
https://arxiv.org/abs/1706.03762
Also see:
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py
Args:
input_tensor: float Tensor of shape [batch_size, seq_length, hidden_size].
attention_mask: (optional) int32 Tensor of shape [batch_size, seq_length,
seq_length], with 1 for positions that can be attended to and 0 in
positions that should not be.
hidden_size: int. Hidden size of the Transformer.
num_hidden_layers: int. Number of layers (blocks) in the Transformer.
num_attention_heads: int. Number of attention heads in the Transformer.
intermediate_size: int. The size of the "intermediate" (a.k.a., feed
forward) layer.
intermediate_act_fn: function. The non-linear activation function to apply
to the output of the intermediate/feed-forward layer.
hidden_dropout_prob: float. Dropout probability for the hidden layers.
attention_probs_dropout_prob: float. Dropout probability of the attention
probabilities.
initializer_range: float. Range of the initializer (stddev of truncated
normal).
do_return_all_layers: Whether to also return all layers or just the final
layer.
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size], the final
hidden layer of the Transformer.
Raises:
ValueError: A Tensor shape or parameter is invalid.
"""
# 如果 hidden_size 不能整除 num_attention_heads,那么抛出异常
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
# 计算每组 attention 的 size
attention_head_size = int(hidden_size / num_attention_heads)
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
# input_width 就是 hidden_size
input_width = input_shape[2]
# The Transformer performs sum residuals on all layers so the input needs
# to be the same as the hidden size.
# 由于后面需要做 residuals 操作,因此 hidden_size 需要等于 input_width
if input_width != hidden_size:
raise ValueError("The width of the input tensor (%d) != hidden size (%d)" %
(input_width, hidden_size))
# We keep the representation as a 2D tensor to avoid re-shaping it back and
# forth from a 3D tensor to a 2D tensor. Re-shapes are normally free on
# the GPU/CPU but may not be free on the TPU, so we want to minimize them to
# help the optimizer.
# prev_output: [batch_size * seq_length, hidden_size]
prev_output = reshape_to_matrix(input_tensor)
all_layer_outputs = []
for layer_idx in range(num_hidden_layers):
# 循环多层 encoder
with tf.variable_scope("layer_%d" % layer_idx):
# 获取前一层的输出
layer_input = prev_output
with tf.variable_scope("attention"):
attention_heads = []
with tf.variable_scope("self"):
# 计算 Self Attention
# attention_head: [batch_size * seq_length, hidden_size]
attention_head = attention_layer(
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
attention_heads.append(attention_head)
attention_output = None
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else:
# In the case where we have other sequences, we just concatenate
# them to the self-attention head before the projection.
attention_output = tf.concat(attention_heads, axis=-1)
# Run a linear projection of `hidden_size` then add a residual
# with `layer_input`.
with tf.variable_scope("output"):
# 普通的全连接层
# attention_output: [batch_size * seq_length, hidden_size]
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
attention_output = dropout(attention_output, hidden_dropout_prob)
# layer norm 层
attention_output = layer_norm(attention_output + layer_input)
# The activation is only applied to the "intermediate" hidden layer.
with tf.variable_scope("intermediate"): # tensor
# 升维全连接
# intermediate_output: [batch_size * seq_length, intermediate_size]
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# Down-project back to `hidden_size` then add the residual.
with tf.variable_scope("output"):
# 降维全连接
# layer_output: [batch_size * seq_length, hidden_size]
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
# 相加,作为残差连接
layer_output = layer_norm(layer_output + attention_output)
# 这一层的输出,作为下一层的输入
prev_output = layer_output
# 将这一层的输出保存到结果列表
all_layer_outputs.append(layer_output)
if do_return_all_layers:
# 返回所有层的输出
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output)
return final_outputs
else:
# 返回最后一层的输出
final_output = reshape_from_matrix(prev_output, input_shape)
return final_output
其中 attention_layer 真正实现了 Self Attention 的计算。
attention_layer()
attention_layer() 的作用就是计算 Self Attention。
主要输入参数有 2 个:from_tensor 和 to_tensor。
如果from_tensor 和 to_tensor 是一样的,那么表示计算 encoder 的 Attention;否则计算 decoder 的 Attention。
主要流程如下:
-
首先,把
from_tensor转换为from_tensor_2d,形状为[batch_size * from_seq_length, from_width]。 -
把
to_tensor转换为to_tensor_2d,形状为[batch_size * to_seq_length, to_width]。 -
首先根据
from_tensor,计算:query_layer(query矩阵),形状为[batch_size * from_seq_length, num_attention_heads * size_per_head]。 -
然后根据
to_tensor,计算key_layer(key矩阵)和value_layer(value矩阵),形状为[batch_size * to_seq_length, num_attention_heads * size_per_head]。 -
将
query_layer的形状转换为[batch_size, num_attention_heads, from_seq_length, size_per_head]。 -
将
key_layer和value_layer的形状转换为[batch_size, num_attention_heads, to_seq_length, size_per_head]。 -
将
query_layer和key_layer相乘,得到attention_scores,并除以 s i z e _ p e r _ h e a d \sqrt{size\_per\_head} size_per_head 做缩放,形状为[batch_size, num_attention_heads, from_seq_length, to_seq_length]。 -
将
attention_scores根据attention_mask进行处理。这里采用了一个巧妙的处理:将attention_mask构造adder,其中 mask 为 1 的地方,adder 为 0;mask 为 0 的地方,adder 为 -1000。最后将attention_scores和adder相加。这样,mask 为 1 对应的 attention 会不变,而 mask 为 0 对应的 attention 会变得非常小。 -
attention_scores经过 softmax,mask 为 0 对应的 attention 会接近于 0,达到了 mask 的目的,得到attention_probs,再经过 dropout。 -
将
attention_probs和value_layer相乘,得到context_layer,形状是[batch_size, num_attention_heads, from_seq_length, size_per_head]。 -
最后将
context_layer的形状转换为[batch_size, from_seq_length, num_attention_heads * size_per_head],返回context_layer。
def attention_layer(from_tensor,
to_tensor,
attention_mask=None,
num_attention_heads=1,
size_per_head=512,
query_act=None,
key_act=None,
value_act=None,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
do_return_2d_tensor=False,
batch_size=None,
from_seq_length=None,
to_seq_length=None):
"""Performs multi-headed attention from `from_tensor` to `to_tensor`.
This is an implementation of multi-headed attention based on "Attention
is all you Need". If `from_tensor` and `to_tensor` are the same, then
this is self-attention. Each timestep in `from_tensor` attends to the
corresponding sequence in `to_tensor`, and returns a fixed-with vector.
This function first projects `from_tensor` into a "query" tensor and
`to_tensor` into "key" and "value" tensors. These are (effectively) a list
of tensors of length `num_attention_heads`, where each tensor is of shape
[batch_size, seq_length, size_per_head].
Then, the query and key tensors are dot-producted and scaled. These are
softmaxed to obtain attention probabilities. The value tensors are then
interpolated by these probabilities, then concatenated back to a single
tensor and returned.
In practice, the multi-headed attention are done with transposes and
reshapes rather than actual separate tensors.
Args:
from_tensor: float Tensor of shape [batch_size, from_seq_length,
from_width].
to_tensor: float Tensor of shape [batch_size, to_seq_length, to_width].
attention_mask: (optional) int32 Tensor of shape [batch_size,
from_seq_length, to_seq_length]. The values should be 1 or 0. The
attention scores will effectively be set to -infinity for any positions in
the mask that are 0, and will be unchanged for positions that are 1.
num_attention_heads: int. Number of attention heads.
size_per_head: int. Size of each attention head.
query_act: (optional) Activation function for the query transform.
key_act: (optional) Activation function for the key transform.
value_act: (optional) Activation function for the value transform.
attention_probs_dropout_prob: (optional) float. Dropout probability of the
attention probabilities.
initializer_range: float. Range of the weight initializer.
do_return_2d_tensor: bool. If True, the output will be of shape [batch_size
* from_seq_length, num_attention_heads * size_per_head]. If False, the
output will be of shape [batch_size, from_seq_length, num_attention_heads
* size_per_head].
batch_size: (Optional) int. If the input is 2D, this might be the batch size
of the 3D version of the `from_tensor` and `to_tensor`.
from_seq_length: (Optional) If the input is 2D, this might be the seq length
of the 3D version of the `from_tensor`.
to_seq_length: (Optional) If the input is 2D, this might be the seq length
of the 3D version of the `to_tensor`.
Returns:
float Tensor of shape [batch_size, from_seq_length,
num_attention_heads * size_per_head]. (If `do_return_2d_tensor` is
true, this will be of shape [batch_size * from_seq_length,
num_attention_heads * size_per_head]).
Raises:
ValueError: Any of the arguments or tensor shapes are invalid.
"""
def transpose_for_scores(input_tensor, batch_size, num_attention_heads,
seq_length, width):
output_tensor = tf.reshape(
input_tensor, [batch_size, seq_length, num_attention_heads, width])
output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3])
return output_tensor
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
to_shape = get_shape_list(to_tensor, expected_rank=[2, 3])
if len(from_shape) != len(to_shape):
raise ValueError(
"The rank of `from_tensor` must match the rank of `to_tensor`.")
if len(from_shape) == 3:
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_seq_length = to_shape[1]
elif len(from_shape) == 2:
if (batch_size is None or from_seq_length is None or to_seq_length is None):
raise ValueError(
"When passing in rank 2 tensors to attention_layer, the values "
"for `batch_size`, `from_seq_length`, and `to_seq_length` "
"must all be specified.")
# Scalar dimensions referenced here:
# B = batch size (number of sequences)
# F = `from_tensor` sequence length
# T = `to_tensor` sequence length
# N = `num_attention_heads`
# H = `size_per_head`
# 把 from_tensor 转换为 [batch_size * from_seq_length, from_width]
from_tensor_2d = reshape_to_matrix(from_tensor)
# 把 to_tensor 转换为 [batch_size * to_seq_length, to_width]
to_tensor_2d = reshape_to_matrix(to_tensor)
# query_layer: [batch_size * from_seq_length, num_attention_heads * size_per_head]
query_layer = tf.layers.dense(
from_tensor_2d,
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
# key_layer: [batch_size * to_seq_length, num_attention_heads * size_per_head]
key_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
# key_layer: [batch_size * to_seq_length, num_attention_heads * size_per_head]
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
# `query_layer` = [B, N, F, H]
query_layer = transpose_for_scores(query_layer, batch_size,
num_attention_heads, from_seq_length,
size_per_head)
# `key_layer` = [B, N, T, H]
key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads,
to_seq_length, size_per_head)
# Take the dot product between "query" and "key" to get the raw
# attention scores.
# attention_scores: [batch_size, num_attention_heads, from_seq_length, to_seq_length]
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
# 除以 sqrt(d),缩放
attention_scores = tf.multiply(attention_scores,
1.0 / math.sqrt(float(size_per_head)))
# 对 attention 进行 mask
if attention_mask is not None:
# `attention_mask` = [B, 1, F, T]
attention_mask = tf.expand_dims(attention_mask, axis=[1])
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
attention_scores += adder
# Normalize the attention scores to probabilities.
# `attention_probs` = [B, N, F, T]
# 对 attention 进行 softmax
attention_probs = tf.nn.softmax(attention_scores)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
# 对 attention 进行 dropout
attention_probs = dropout(attention_probs, attention_probs_dropout_prob)
# `value_layer` = [B, T, N, H]
value_layer = tf.reshape(
value_layer,
[batch_size, to_seq_length, num_attention_heads, size_per_head])
# `value_layer` = [B, N, T, H]
value_layer = tf.transpose(value_layer, [0, 2, 1, 3])
# `context_layer` = [B, N, F, H]
# 将 attention 乘以 value_layer,得到 context_layer
context_layer = tf.matmul(attention_probs, value_layer)
# `context_layer` = [B, F, N, H]
context_layer = tf.transpose(context_layer, [0, 2, 1, 3])
if do_return_2d_tensor:
# `context_layer` = [B*F, N*H]
context_layer = tf.reshape(
context_layer,
[batch_size * from_seq_length, num_attention_heads * size_per_head])
else:
# `context_layer` = [batch_size, from_seq_length, num_attention_heads * size_per_head]
context_layer = tf.reshape(
context_layer,
[batch_size, from_seq_length, num_attention_heads * size_per_head])
return context_layer
至此,Bert 源码就讲解完了。在下一篇文章中,我们会讲解如何预训练 Bert,以及使用训练好的 Bert 模型进行分类。
如果你有疑问,欢迎留言。
参考
- 谷歌 BERT 预训练源码解析
- 阿里天池 NLP 入门赛 TextCNN 方案代码详细注释和流程讲解
如果你觉得这篇文章对你有帮助,不妨点个赞,让我有更多动力写出好文章。