如何学习开源项目,我又总结了套路
学算法认准 labuladong
后台回复课程查看精品课
点击卡片可搜索文章
在线学习网站:
https://labuladong.github.io/algo/
![]()
我在前文 加入开源社区,告别 CRUD 中讲到参与开源社区的种种好处,本文分享一下在使用或者学习开源项目源码的过程中的一些经验技巧。
因为我最近在研究 Apache Pulsar 这款消息队列,所以就以这个项目为例,不过本文介绍的都是通用的技巧,完全可以用在其他大型开源项目中。如果你也对消息队列相关技术感兴趣,可以参看前文 Apache Pulsar 架构设计 和 用 Pulsar 做一款联机小游戏。
下面就来具体介绍一些技巧,主要分两部分:
第一部分是文档篇,即能够哪里能够获取有效的信息解决问题;
第二部分是实操篇,即如何高效打断点或借助工具理解源码。
一、文档检索技巧
想学习了解一个开源项目,文档可以帮我们解决大部分问题。当然我这里所说的不单单指官网文档,还包括 issue、PR、源码中的注释和单元测试,这些地方都可以获得大量有用的信息,所以我把它们统称为文档,下面我们从最简单的开始。
1、官网文档,着重 quickstart 和 concept 部分。
官网文档无疑是最权威的资料来源,不过官网文档的问题是内容太多太全面,适合遇到问题或需求时当做功能手册去查阅。
所以官网的内容需要选择性地学习,我建议优先着重两个部分:
一是 quickstart 部分,也就是教你如何快速部署一个 demo 服务;二是 concept 部分,也就是名词解释、核心功能介绍等内容。
快速部署 demo 服务不用说了,是我们学习新技术的第一步,一般会被放在文档的第一章;而功能/名词的解释是我们接下来顺畅地学习进阶资料或参与社区讨论的重要铺垫。
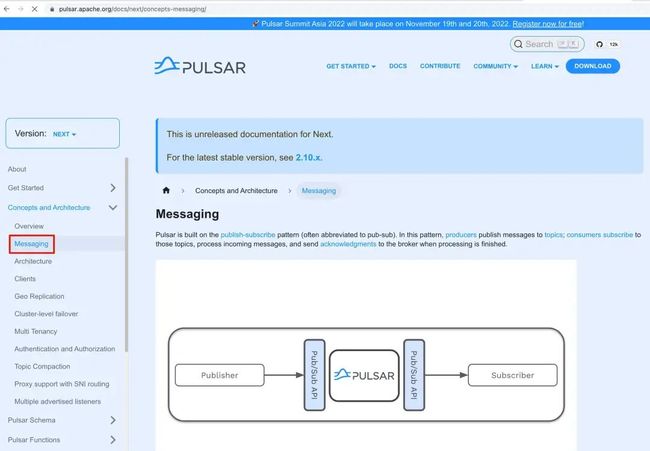
对 Pulsar 这样一个消息队列来说,收发消息显然是核心功能,所以官网 Concepts and Architecture 部分中的 Messaging 章节显然是很重要的,详细介绍了 Pulsar 中诸如订阅模式、死信队列等关键功能:
我在前文 Apache Pulsar 架构设计 介绍到 Pulsar 采用存算分离的架构,存储层依靠 Apache Bookkeeper。所以如果你的目标是学习 Pulsar,那么 Bookkeeper 的官网文档也是需要阅读的,因为 Pulsar 中的很多功能都会和 Bookkeeper 交互。
可以在本地启一个 Bookkeeper 集群用 client 玩一玩,阅读了解一下 Bookkeeper 中的专业术语,有助于理解 Pulsar 中的一些设计。
2、看完文档看单元测试用例,辅助我们准确理解每个功能的预期行为。
一般成熟开源项目的测试用例比较完备,会覆盖所有关键功能的预期行为,所以单测用例其实也是很好的学习资料,和文档搭配食用效果最佳。
比方说,有时候文档用文字描述某个功能可能会比较繁琐,让人看的云里雾里,又或者文档中并没有介绍一些技术设计的细节。
遇到这种情况,我们大概率可以在单测文件中找到对应的功能测试代码,根据测试代码很容易反推功能,正所谓「talk is cheap, show me the code」。
举个例子,有一次我看到 consumer 打出一条关于epoch的日志,我在分布式选主的场景倒是听说过这个名词,不过显然消费消息和分布式选主没什么关系,所以这个epoch到底是干什么的?
文档里没找到答案,这应该是一个具体实现中的术语,所以我就在源码中搜索包含testEpoch和epochTest这两个关键词的函数名,发现了几个测试用例:
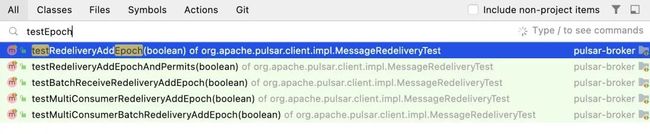
PS:测试函数名的 test 关键字可能在开头也可能在最后,所以需要都搜一下。
浏览了一下这几个测试用例的内容就大致理解了,原来这个epoch是消息重投递功能(redelivery)中的一个术语,主要用于防止重复消费消息。
3、善用 GitHub,从项目的 issue/PR/wiki 列表获取有效信息。
首先,issue 列表不用多说了,如果你在使用软件的过程中遇到了问题,首先考虑的就是去 issue 列表搜索。
虽然有时候搜出来的并不是直接的答案,但多换关键词搜几次,大概率就能找到一些思路解决问题了。
另外,PR 信息可以帮助我们了解某些代码片段的上下文背景。
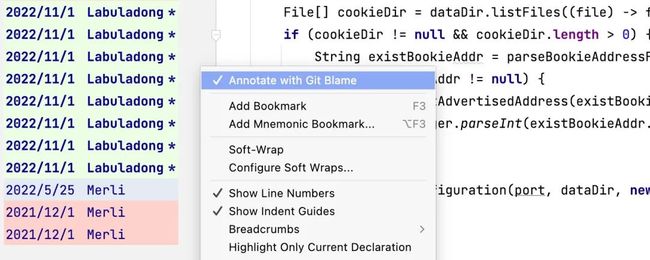
举个例子,比如你阅读某段代码时有疑惑,不明白这个代码的目的是什么,那么可以在 IDEA 中的代码左侧单击右键,打开「Annotate with Git Blame」就可看到这段代码是谁在什么时候添加上去的:
然后把鼠标悬停在作者昵称上两秒,就会弹出这个代码被合进 master 分支时的 PR 标题和链接:
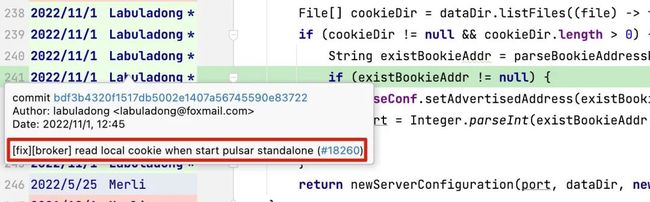
18260就是这个 PR 的编号,点击即可跳转到对应的 PR 页面:
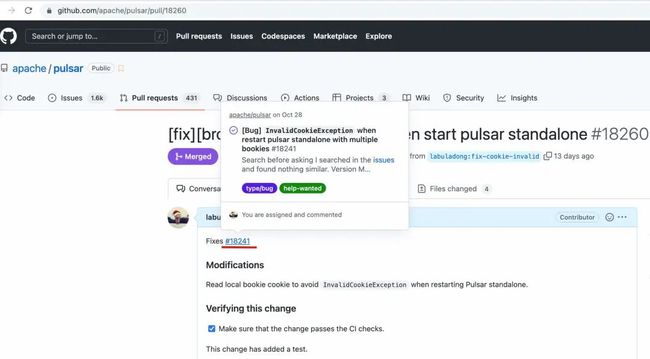
可以看到这个 PR 是用来修复18241号 issue 的,在18241号 issue 中详细描述了 bug 信息及复现方法:
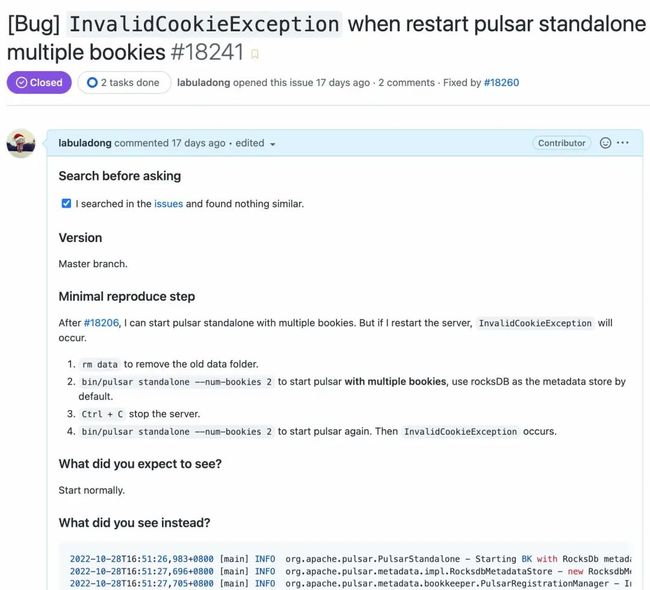
有了这些上下文信息,就可以避免我们阅读源码时的障碍了。
最后,wiki 页面可以帮我们了解一些重要的功能设计或改动。
拿 Pulsar 来说,如果需要做比较重要的改动,需要提出一个 PIP 提案(Pulsar Improvement Proposal),也就是一个专门讲解背景信息、设计思路的文档。
而这些 PIP 文档就收集在 wiki 页面:
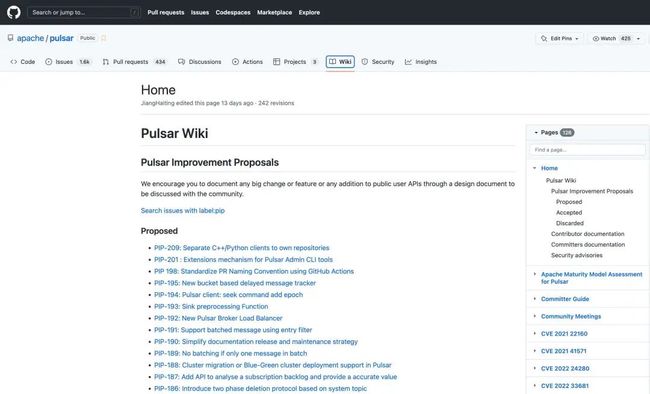
所以在了解某个功能模块的设计思路时,可以先去 wiki 页面看看是否有相关的 PIP 可供参考。
比如 Pulsar 的事务实现,就有一个专门的 PIP 详细介绍了设计思路,结合 PIP 的思路指引去学习源码就会容易很多:

我个人觉得,好的 PIP 结合源码,带我们把一个功能从讨论设计做到落地实现,这就是很好的教科书呀,多花精力去研究,肯定会有所收获的。
以上就是最常用的有效信息的获取途径,如果你在学习使用开源项目时遇到问题,那么可以尝试上述的方法去寻找答案。
当然,熟练掌握进行信息检索的工具进行高效检索也是重要的技能,比如说 IDEA 的各种搜索、GitHub issue/PR 的搜索语法,这些技巧网上可以很容易搜到,我就不赘述了。
二、源码阅读技巧
想真正了解一个项目,看源码肯定是逃不掉的一环。阅读源码的好处不用多说了,但阅读源码肯定会花费大量时间,而且这个过程不会很轻松。
你想嘛,成熟的开源项目经过多年的发展,功能不断演进,很多人往里面写过代码,恐怕没人能保证自己完全了解系统的每个细节。我们阅读源码,就好比探索一座庞大的城市,很容易迷失在某个犄角旮旯。
对于这个问题,我可以分享一些小技巧。
技巧一、不建议看「死代码」,建议在调试实际问题的过程中理解代码。
换句话说,不要拿着代码硬读,最好是通过动态调试来研究每个功能中做了什么。
拿 Pulsar 举例,我们可以在命令行启动 standalone 模式的 Pulsar broker:
$ bin/pulsar standalone然后用 Java client 创建一个 producer 发送一条消息:
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
.build();
Producer producer = client.newProducer()
.topic("testTopic")
.create();
MessageId messageId1 = producer.send(("hello1").getBytes());
client.close(); 我们就可以调试这个简单的场景,看看 producer 是如何创建的,消息是如何发送并存储在 Pulsar 中的。
但如果想跟踪调试这段代码,会遇到一些问题:
第一个问题是,我们自己的项目是通过 Maven 引入 client 包的,如果进入这些包看到的是反编译的 class 文件,无法直接看到源码。就算 IDEA 可以直接帮我们下载源码,但如果我们在从事 client 的开发,需要 master 分支的最新版代码,这和上传到 Maven 的源码还是不一样。
这个问题比较容易解决,我们直接从 GitHub 下载源码,在 client 包里面创建一个 test 文件写逻辑,这样就可以调试最新的 client 代码了。
第二个问题比较棘手,我们想调通整个 Pulsar 发送消息的流程,那么这里面肯定要涉及 Pulsar client 和 Pulsar broker 的交互,而 broker 是通过命令行启动的,我如何调试 broker 里面的代码呢?
我们可以观察一下,bin/pulsar这个文件其实就是个 shell 脚本,可以找到这样一段代码:
elif [ $COMMAND == "standalone" ]; then
PULSAR_LOG_FILE=${PULSAR_LOG_FILE:-"pulsar-standalone.log"}
exec $JAVA $LOG4J2_SHUTDOWN_HOOK_DISABLED $OPTS ${ZK_OPTS} -Dpulsar.log.file=$PULSAR_LOG_FILE -Dpulsar.config.file=$PULSAR_STANDALONE_CONF org.apache.pulsar.PulsarStandaloneStarter $@standalone命令其实就是运行java命令,输入一大堆参数,加载了一堆 jar 包,最终启动了PulsarStandaloneStarter这个类,所以我们可以使用 JVM 远程调试功能。
IDE 就给我们提供了 Remote JVM Debug 功能:
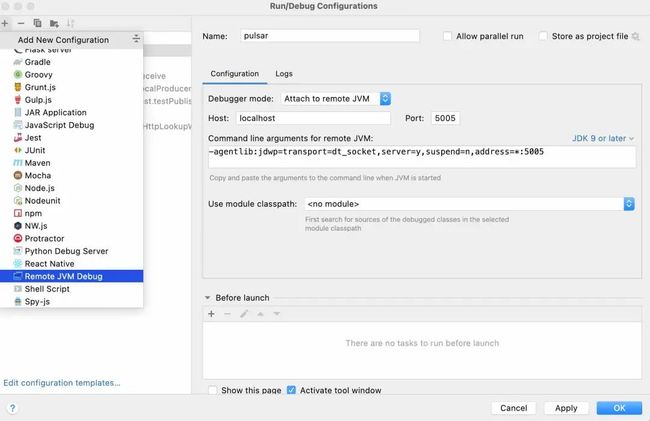
我新建一个远程调试,参数填默认的就行,这里 IDE 给我们自动生成了一段 JVM 参数:
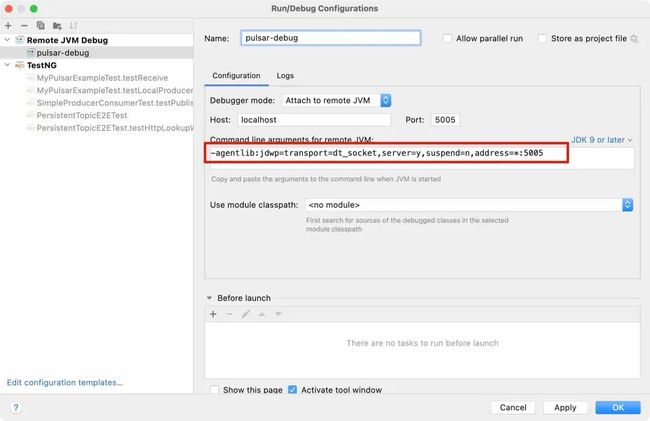
我们把这段 JVM 参数复制,把其中的suspend=n改成suspend=y,然后修改bin/pulsar文件,把这段参数添加到standalone模式的启动参数中:
elif [ $COMMAND == "standalone" ]; then
# 添加调试参数,注意 suspend=y
OPTS="${OPTS} -agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=*:5005"
PULSAR_LOG_FILE=${PULSAR_LOG_FILE:-"pulsar-standalone.log"}
exec $JAVA $LOG4J2_SHUTDOWN_HOOK_DISABLED $OPTS ${ZK_OPTS} -Dpulsar.log.file=$PULSAR_LOG_FILE -Dpulsar.config.file=$PULSAR_STANDALONE_CONF org.apache.pulsar.PulsarStandaloneStarter $@这样,我们本地命令行再执行执行bin/pulsar standalone时就会挂起:
$ bin/pulsar standalone --num-bookies 3
Listening for transport dt_socket at address: 5005此时,你在 IDE 里可以给代码随意打断点,点击 debug 按钮后 broker 才会启动,走到断点处将暂停,我们可以在 IDE 中查看变量、堆栈等信息。
这样我们就能在 IDE 中同时调试 client 端和 broker 端的代码了。
但是需要注意的是,进行远程调试的源代码必须和命令行启动的 broker 一致,否则会导致调试时行数对不上的问题。
如果出现源码对不上的情况,可以在 pulsar 项目的根目录用 maven 重新编译当前的源码:
$ mvn package -DskipTests -Dlicense.skip=true编译好的二进制包在distribution/server/target中,我们在新的包中的bin/pulsar脚本添加远程 debug 的参数,然后再次启动即可顺利调试。
技巧二、多猜,多搜索,可以在底层库(标准库、网络框架等)打条件断点过筛选出关键流程。
这句话其实是高效 debug 的关键。初看源码时「猜」是很重要且很有效的手段,结合 IDE 的搜索功能,能够帮我们快速定位关键代码。
为什么底层库适合打断点呢?因为出看大项目的代码很难搞清楚其中的细节,加上各种异步、多线程的操作,很容易把代码「跟丢」。如果把断点打在底层库的接口/方法上,就可以根据调用栈分析调用过程。
当然,底层库被调用的次数比较多,可能出现很多无关的调用,所以要结合条件断点来过滤掉无关的调用。
还是用 Pulsar 举例,我现在想探究 producer 发送消息的流程,那么 producer 和 broker 之间的网络通信过程就是一个重要的切入点。
首先发现 Pulsar 的网络协议使用的是 protobuf,而且注意到PulsarApi.proto这个文件中有一个BaseCommand定义:
message BaseCommand {
enum Type {
CONNECT = 2;
SUBSCRIBE = 4;
PRODUCER = 5;
SEND = 6;
SEND_RECEIPT= 7;
MESSAGE = 9;
ACK = 10;
PING = 18;
PONG = 19;
...
}
required Type type = 1;
optional CommandConnect connect = 2;
optional CommandConnected connected = 3;
...
}又发现 Pulsar 底层靠 netty 框架实现网络通信,那么我们可以大胆猜测,源码里肯定有一个大 switch 语句,来根据 command 里面的 type 分类处理对应的 command。
所以我们可以全局搜索一下case SEND_RECEIPT,就找到了PulsarDecoder这个文件:
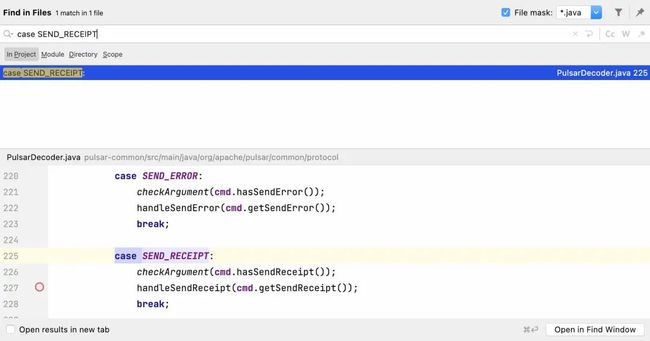
这里会根据不同的 command type 调用不同的 handle 函数,所以可以认为这里是 Pulsar 关键功能的入口。
而且注意这是 common 包,也就是说 client 和 broker 都会依赖这个包,所以断点打在 switch 这里就可以看到 client 和 broker 的网络交互,每次跳转的 case 就是网络命令的交互顺序:
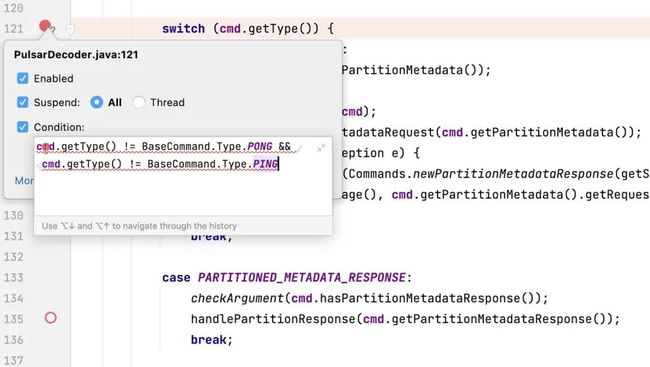
PS:因为 ping/pong 心跳消息在调试时很烦人,所以我们可以通过条件断点跳过心跳消息。另外,我们需要把 client 里面的各种 timeout 都调大一些,避免调试时出现超时的错误。
这样,启动我们的测试用例,仅仅通过这一个断点,就能搞明白 Pulsar 发消息的流程了:
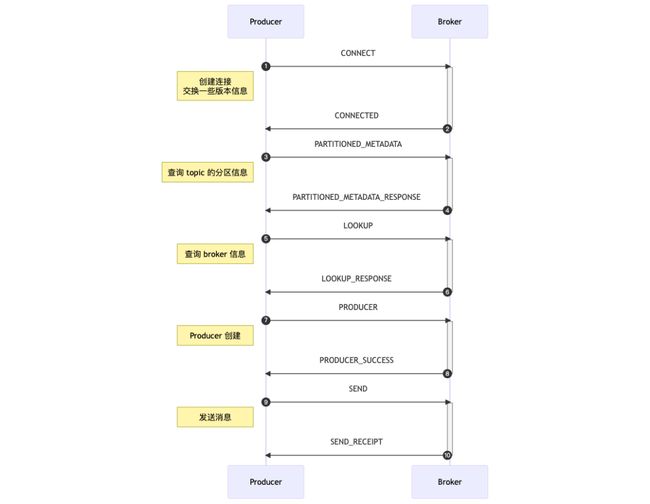
当然,如果你想探究每一步具体做了什么,就跳进具体的 handle 函数里一步步调试即可。
技巧三、利用各种可视化工具。
你比如,上面说的网络通信过程,我们知道了 produce 一条消息的流程,但每条 protobuf 数据包里面到底存了什么信息呢?
关于这个问题,社区有大佬写了一个 lua 脚本,可以用 wireshark 解析 Pulsar 协议格式,具体说明在这里:
https://github.com/apache/pulsar/tree/master/wireshark
按照说明配置并启动 wireshark 之后,可以使用如下过滤命令过滤掉无关的数据包:
tcp.port eq 6650 and pulsar and protobuf.field.name ne "ping" and protobuf.field.name ne "pong"接下来启动 standalone,通过 Java client 发送一条消息,就可以在 wireshark 抓到 10 个数据包,和刚才通过 debug 得到的流程是一样的:
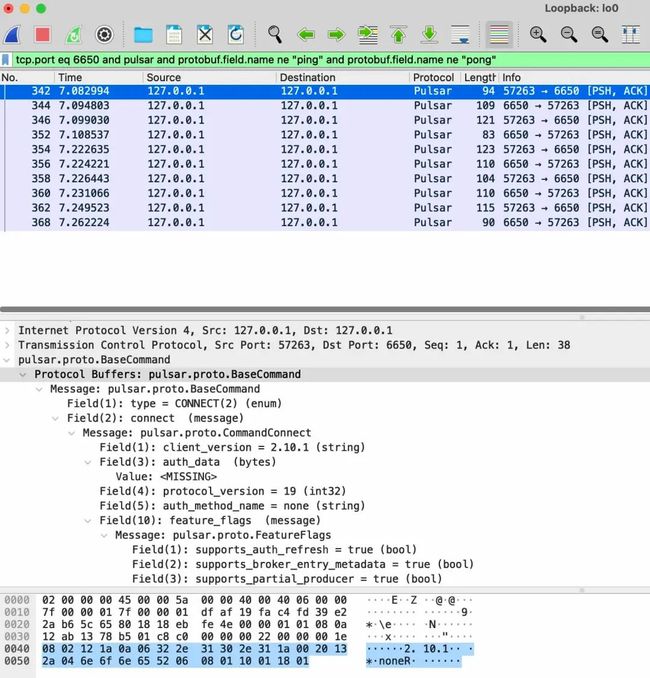
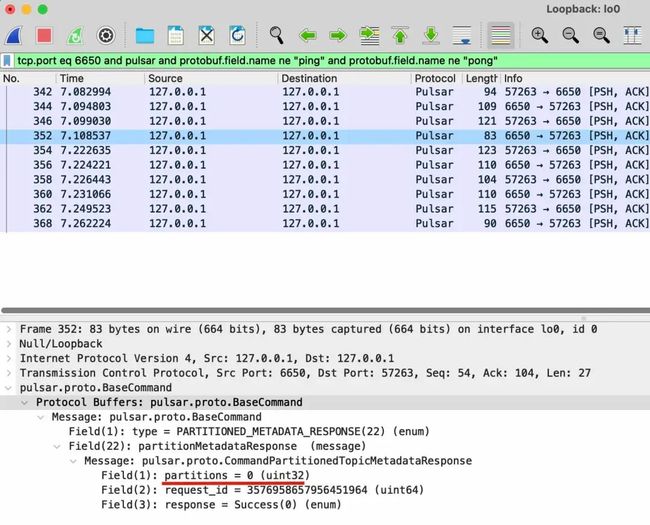
同时,我们还可以查看每个包的具体数据,比如PARTITITONED_METADATA命令就是在查询 topic 对应的 partition 有多少,因为这里是个非分区的 topic,所以PARTITITONED_METADATA_RESPONSE返回了 0:
再比如LOOKUP命令用来查询 broker 的 URL,因为我们启动的 standalone 只有一个 broker,所以LOOKUP_RESPONSE返回的只有一个 URL:
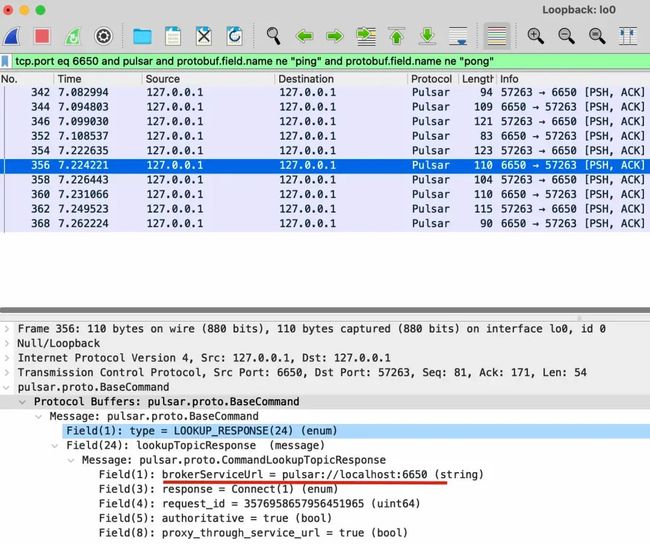
在真实的使用场景中肯定有多个 broker,所以这个LOOKUP_RESPONSE应该会返回多个 broker URL。
最后看一下真正发送消息的SEND命令里面具体有什么数据:
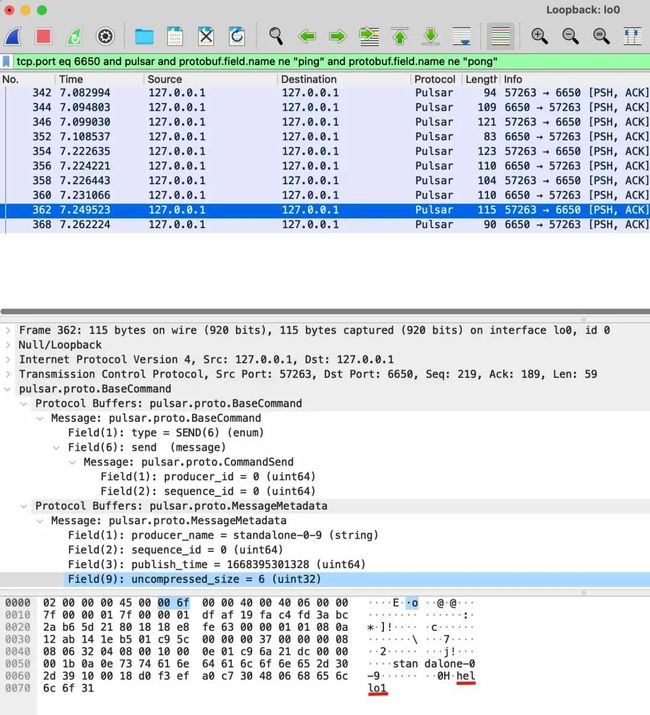
可以看到这里面有 producer_name, sequence_id 等数据,每条消息的 sequence_id 单调递增,用来防止由于网络重传导致的消息重复,和 tcp 里面的 seq 差不多的原理。
另外可以看到真正的消息数据放在数据包的最后,通过一个字段记录数据的长度。
具体的玩法可以有很多,我这里就不一一列举了,其实除了 wireshark 分析 Pulsar 的网络通信,还可以使用 zookeeper 的可视化工具查看 Pulsar 的元数据。
比如 prettyZoo 就是一款对 zookeeper 可视化的开源工具,那么我就可以在 Pulsar standalone 启动之后(会自动启动 zookeeper),让 prettyZoo 连接到 zookeeper 的端口,很直观地查看 zookeeper 里面的节点数据:
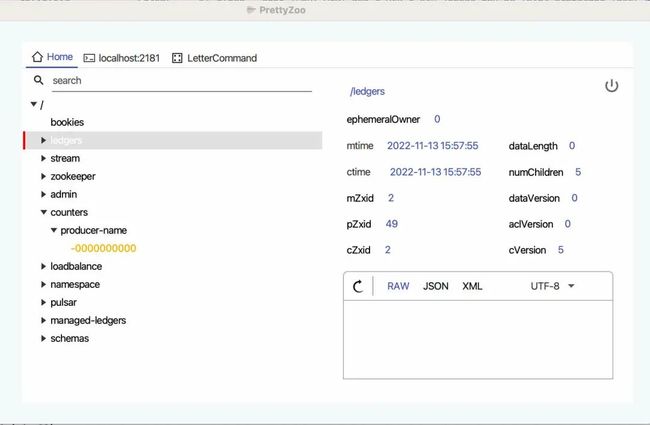
这里面很多数据可能不好理解,但我们手上有源码,这些路径大概率是以字符串常量的形式表现的,那全局搜索就行了。
比如这个producer-name的路径,我们搜一下就定位出来了:
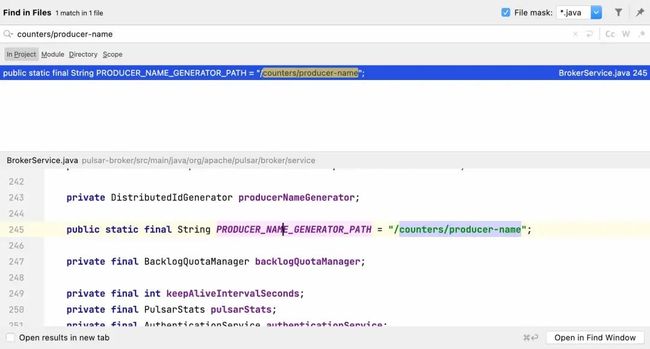
简单浏览一下源码,原来是借助 zookeeper 生成全局唯一的生产者名字。
最后
本文也够长了,主要介绍了一些阅读开源项目源码的实用技巧,总结来说就是:善于找资源,善于用工具。
虽然本文是以 Pulsar 为例,但这些技巧都是通用的,可以运用到任何比较成熟的开源项目上去。
如果你也有什么经验分享,可以留言告诉我,掌握技巧只是漫漫长路的第一步,让我们共同在开源社区里成长进步。