浅谈如何基于深度方法进行三维重建
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
后台回复【领域综述】获取自动驾驶全栈近80篇综述论文!
后台回复【数据集下载】获取计算机视觉近30种数据集!
在过去的两个半月,我对于三维重建这个新领域进行了详细的学习。初学时候还是遇到了很多细节问题,比如怎么进行二维点到三维点的转换,怎么验证数据收集对不对,怎么做相机标定等等。经过一段时间的踩坑,慢慢感觉对三维视觉渐渐熟悉起来。这里通过写文章的形式,简单记录下这个过程中我看到的很有意义的三篇论文。
1. 三维重建简介
本文主要介绍如何做场的三维重建。主要解决的问题是,基于给定的场扫描数据,尝试进行进行有效的三维重建,重建得到的形体(如果可以的话,还有染色)达到较高的质量。这里一般会考虑收集以下数据,分别是相机拍摄视频、每一帧对应的姿态、以及相关帧的深度信息。
从这些需要的数据就可以看出来,三维重建任务和一般任务的区别:首先需要的是RGB图像,这个是最基本的要求;此外还需要相机的姿态信息(一般相机姿态仅包括外参。本文提到的相机姿态是相机投影矩阵,也就是相机的内部参数+外部参数。
这里不区分opencv、opengl坐标系下不同矩阵的名称及叫法),这可以帮助我们估计出来,图像中某个像素在三维的位置。最后是深度信息,可以具体的展示当前拍摄到的物体的深度值。全部加总在一起,就可以帮助我们重建出一个标准的物体出来。
2. 三维重建面临的挑战
三维重建算法的主要挑战在形体重建和染色上。一些相关的传统重建算法例如sfm (structure-from-motion), Kinectfusion, bundlefusion等,基于正确的相机姿态以及深度图,已经可以很好的重建出具有丰富纹理的白模场景,因而使用这些算法,对于可闭合区域或刚体的形体,一般可以取得较好的结果。
在色彩重建方面,基于类似深度图融合的rgb-fusion算法可以更进一步的建模场景的色彩信息。但是由于RGB-fusion是通过平滑点阵中的点来建模色彩的,使用了类似指数平滑的思想,因此重建出的色彩比较平均,色彩对比度不强,看起来很模糊,不太满足现实场景的要求。
目前来看,针对三维场景进行染色操作,还是具有相当程度的挑战性。最近的隐式神经表示网络(比如Nerf模型)在色彩建模上则拥有独特的优势,但是需要基于具体测试样例,单独进行训练。如果不做精调而直接使用,效果差强人意。
3. 三维重建经典算法
mobile3Drecon算法
这个算法是由商汤开发的,主要提出了一种可以进行端到端的三维重建的架构。传统的三维重建算法对高复杂度的室内模型效果不是很好,而且训练和测试阶段都需要深度信息支持,才能进行高质量的三维重建。但是用户一般是没有办法收集深度信息的,因而传统方案很难直接用于现实产品中。此外,使用的算子在移动端上并不被很好支持。这些问题对于AR商业化具有很大的影响。
因此,mobile3Drecon(以下简称mobilerecon)进行了一系列优化,希望仅凭输入视频流来实现准确的三维重建。为了获取拍摄场景的姿态,使用了手机自带的imu信息,基于自研的slam算法进行高质量的姿态估测(也可以考虑使用基于关键帧的visual-inertial SLAM系统,在安卓手机ARcore以及苹果手机ARkit有相关实现);为了获取深度信息,使用了深度图估测算法(多维SGM)进行深度估测;并进一步使用基于置信度的方法优化深度图,并使用深度学习网络(编解码结构)进行精调。
重建过程中,会实时收集较多的视频帧。每一帧都用来进行重建,未必会提升整体精度,反而会导致较高的延迟。因此,作者使用了key-frame selection的方法,基于针对性的挑选了若干帧用来做训练、评估,在保证准确度相近或更优的情况下,极大地减少了需要的视频帧,进一步优化了模型运行时间。
模型整体架构图如下(节选自mobilerecon)。
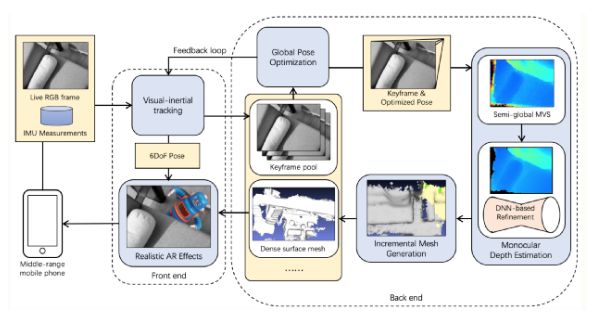 mobilerecon结构图, 版权属于原作者
mobilerecon结构图, 版权属于原作者
作者首先使用了IMU进行姿态测量,然后进行了key-frame selection。具体操作是,使用了不同时间戳下,基于baseline的分数来做判断。一般来说,我们不希望给定的输入是有断层(相邻两帧之间毫无关联)的,而希望相邻两帧的输入可以尽可能连续。为了鼓励选择的相邻关键帧对应的视野尽可能靠近,引入了相邻视域的轴夹角,以及相应的baseline共同来判断当前帧是否为合适的关键帧。
之后依次进行深度图估计以及实时三维重建,以获得可用的三维网格重建结果。优化阶段主要优化光学深度损失,来学得合理的深度图估计结果。由于依赖深度图,重建结果的好坏和深度图的估测质量息息相关。
Atlas算法
atlas这个算法是由magicleap这家公司提出的。基本而言,这个算法使用一组视频流+对应相机姿态作为输入,尝试使用输入的视频来直接对场景进行三维重建,并从中尽可能多的利用场景先验作为信息,帮助模型在减少已有参数的同时,进一步的提升模型的表现。相比于以往的深度图估测方法,Atlas对于数据的需求量少了一大截。
这篇论文主要受到MVS和深度图融合的启发,从MVS的角度,合理的深度计算对于整体模型精准建模的帮助很大。这里尝试把原图像投影到目标图像对应的深度平面上并进行匹配,并从中找到正确的深度平面。进一步的,作者使用卷积对原图进行了特征提取,使用了更为鲁棒的特征来进行相应匹配。
作者同时使用了tsdf融合来进行mesh建模。给定计算好的tsdf结果,尝试找到tsdf表面零点交织的位置,使用marching cube来进行提取顶点,之后便可以生成相关的三维mesh网格,经过三维卷积网络精调之后,便可以生成高质量的重建结果。但是进行tsdf融合的前提是,需要有相关的深度测量结果,这对于硬件要求比较高。比较幸运的是,作者使用的scannet数据集,里面提供了相应的图像、姿态、深度信息真值,仅用于训练阶段是可以满足相关要求的。
atlas基于这两点构建模型。首先使用了二维卷积网络对输入图像进行特征提取,之后把这些特征基于相机已知内参、外参反投影到三维空间。这里具体做法是,把每个像素按照光束照射方向映射到三维空间。这样做可以避免目标帧的选择,而且允许我们把整个帧序列融合到三维空间内;融合帧的方式是进行简单的加权。以此作为输入,我们使用三维卷积网络来学习这些特征,以直接预测TSDF在每个顶点位置的值。此外这个网络可以通过简单的追加一个分割头部,来实现三维场景的分割。
这里是atlas整体的框架图:
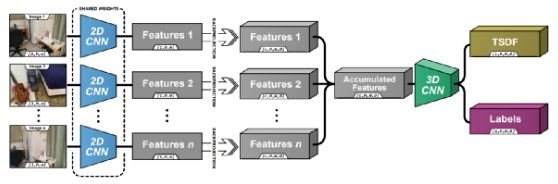 Atlas结构图,版权属于原作者
Atlas结构图,版权属于原作者
整体来看,每张图片作为输入,会通过一个二维卷积网络,生成对应的三维向量。之后会对每个二维坐标点上的像素值,使用相机投影矩阵,由二维转换到三维空间。这里需要注意的是,所有沿着光照方向照射到的体素,都会被赋值相同的特征(也就是二维图像上点对应的特征)。这些特征会在整个视频序列上积聚,使用平滑的方式进行加权。下面公式介绍了如何进行voxel上特定位置体素的融合。与当前投影点出现的频率(也就是权重W),以及体素值(权重V)有关。
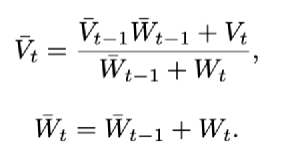
整个网络使用了类似encoder-decoder的结构来实现,最终输出分别使用了111的三维卷积来获取tsdf预测值以及相应的分割结果。
对于tsdf的预测,使用了l1 损失,并且对真值进行了log-transform,同时只计算真值对应位置。为了防止网络去学习墙体上的一些缺陷,额外的对整列全部为1的voxel进行了标注,并对这些位置也进行惩罚。这么做的原因是,如果voxel的整列都是1(没有被观测到)那么大概率这个voxel不在这个场景里面。为了加速训练,作者提前计算了tsdf真值并且进行相应的存储,以实现加速目的。
Neuralrecon
Neuralrecon是商汤提出的算法,延续了Atlas算法的核心思想。更进一步的,Neuralrecon尝试使用基于多尺度的方式进行tsdf值预测,来实现更高质量的重建精度。此外考虑到传统三维卷积占用显存大的问题,引入了三维稀疏卷积的方式来进一步提升算子效率,使用了更低的内存占用换取了更高质量的场景重建。此外,作者引入了三维GRU模块,来取代传统的tsdf融合方法,尝试使用可以自学习的GRU模块,让模型的学习更具有选择性。
下图是Neuralrecon的结构:

Neuralrecon使用了实时渲染的思路,整体会以一个大的Tsdf体素来存储。整体框架的输入是通过视频采集的,帧数比较多,全部使用的话,效率比较低,这里有和mobilerecon一样的问题。因此,每次对于给定的输入图像,并不会每一帧都会使用,而是通过选择其中的关键帧,只使用这些比较有代表性的帧来做渲染。
具体来说,会按照相对平移距离t_max以及相对旋转角度R_max挑选合适的帧。之后会基于N_view(默认值9)个关键帧,计算相应的bounding volume。这里bounding volume作用是去使用一个体素,围住所有的关键帧,并计算出对应的视域。计算时只考虑固定深度下的bounding volume,如果某点的深度过深则不予考虑。
由于是实时渲染,会需要使用当前帧进行三维重建,重建结果会和全局重建融合,因此会有局部(local)坐标与全局坐标的区别。全局坐标基于整个大的tsdf体素来观察每一个点,而一个大的体素可以进一步划分为多个小的voxel, 而局部坐标则是基于当前的voxel去计算当前坐标的。因此,在计算局部重建结果后,与全局结果融合的时候,需要进行坐标转化。总的voxel数量乘以每个voxel的尺度,就是大的体素的尺度。
在重建过程中,会由粗到细,进行三个阶段的精细化训练。训练过程中,每个voxel会预测两个参数,分别为occ score和sdf值。occ score代表了当前voxel处于TSDF截断距离内的置信度,如果未能达到一定阈值,则会判定这个voxel里是空的。此外,Neuralrecon没有使用单视图下预测对应深度图的方式(mobilerecon)来建模,而是采用了直接预测局部坐标下的物体表面值的方式来建模。这样子学得的物体表面会更加平滑,而且在尺度上更加一致。
为了能够使得前后学习到fragments更加一致,作者尝试引入了三维GRU模块。输入特征会先通过三维卷积,进行特征提取,之后把学到的特征和全局隐层特征进行融合,生成更新的隐层特征,用它来预测tsdf值。同时,生成的新的隐层特征会基于voxel,更新掉原来隐层特征的对应位置,以更好的存储全局隐层特征。
这里GRU模块代表了,有多少之前重建的信息被融合到了当前卷积提取的特征上,以及当前卷积提取的特征中,有多少会被融合到隐层特征内,因此,也可以把GRU模块视为一个选择性的注意力机制。下图是进行GRU模块计算的详细公式。图中的SparseConv指的是稀疏卷积,具体实现方式是通过torchsparse实现的。

训练过程中,需要同时训练occ score以及tsdf预测值。这里使用BCE损失(binary cross-entropy)来训练occ score(置信度处于0-1之间)以及SDF损失来训练sdf预测值。这里的SDF损失和atlas一样,都是使用了l1损失,直接优化预测得到的sdf值以及提前计算好的sdf真值之间的差值,来实现合理的SDF值训练。
4. 结语
本文总结了三种三维重建相关的论文,简单介绍了训练阶段基于深度信息,测试阶段仅需视频就可支持可泛化三维重建的优秀算法。需要注意的是,最近两年隐式神经表达网络在三维重建中起了越来越重要的作用,其中以Nerf为代表的模型,越来越多的出现在顶会论文中。然而,目前已有的Nerf方法无法很好实现场景预测的泛化,仍旧需要精调之后才能得到满意的效果,因此本文没有涉及到相关的论文。如何能够使用nerf模型进行高质量的场三维重建,以及可泛化的场景纹理、色彩学习,是一个非常值得期待的方向,之后也会对相关方向多花时间学习。
参考
Sun, J., Xie, Y., Chen, L., Zhou, X., and Bao, H., “NeuralRecon: Real-Time Coherent 3D Reconstruction from Monocular Video”, arXiv e-prints, 2021.
Murez, Z., van As, T., Bartolozzi, J., Sinha, A., Badrinarayanan, V., and Rabinovich, A., “Atlas: End-to-End 3D Scene Reconstruction from Posed Images”, arXiv e-prints, 2020.
X. Yang, et al.,"Mobile3DRecon: Real-time Monocular 3D Reconstruction on a Mobile Phone" in IEEE Transactions on Visualization & Computer Graphics, vol. 26, no. 12, pp. 3446-3456, 2020.
Angela Dai, Matthias Nießner, Michael Zollhöfer, Shahram Izadi, and Christian Theobalt. 2017. BundleFusion: Real-Time Globally Consistent 3D Reconstruction Using On-the-Fly Surface Reintegration. ACM Trans. Graph. 36, 3, Article 24 (June 2017), 18 pages. https://doi.org/10.1145/3054739
Park, J. J., Florence, P., Straub, J., Newcombe, R., and Lovegrove, S., “DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation”, arXiv e-prints, 2019.
R. A. Newcombe et al., "KinectFusion: Real-time dense surface mapping and tracking," 2011 10th IEEE International Symposium on Mixed and Augmented Reality, 2011, pp. 127-136, doi: 10.1109/ISMAR.2011.6092378.
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
