(阅读)MPC-BERT: A Pre-Trained Language Model for Multi-Party Conversation Understanding
论文地址
代码
标题
MPC-BERT:一种用于多方对话理解的预训练语言模型
摘要
最近,用于多方对话(MPC)的各种神经网络模型在诸如接收人(addressee)识别、说话人识别和回复预测等任务上取得了令人印象深刻的改进。然而,现有的MPC方法通常都是将对话者和对话语句单独表征,而忽略了MPC固有的复杂结构,这种结构可以提供关键的对话者和对话语句语义信息,从而增强会话理解过程。为此,我们提出了MPC-BERT,这是一个预训练的MPC理解模型,它考虑在一个带有多个精心设计的自监督任务的统一模型中学习“谁对谁说什么(who says what to whom)”。具体地说,这些任务一般可分为:(1)对话者结构建模,包括回复语句识别、同一说话人搜索和指针一致性区分;(2)语句语义建模,包括掩码共享语句恢复和共享节点检测。我们在三个下游任务上评估MPC-BERT,包括接收人识别、说话人识别和回复选择。实验结果表明,MPC-BERT 大大优于以前的方法,并在两个基准数据集、三个下游任务上实现了当前最优的性能。
1 引入
建立一个具有智能的对话代理引起了学术界和工业界的极大关注。大多数现有的方法都是研究理解两名参与者之间的对话,旨在以基于生成(generation-based)(Shang等人,2015;Serban等人,20162017;Zhang等人,2018b,2020)或基于检索(retrieval-based)的方式(Lowe et al.,2015;Wu et al.,2017;Zhou et al.,2018;Tao et al.,2019a,b;Gu et al.,2019a,b,2020)返回一个恰当的回复。最近,研究人员更加关注一种涉及两名以上参与者的更实际和更具挑战性的情景,即众所周知的多方对话(MPC)(Ouchi and Tsuboi,2016;Zhang et al.,2018a;Le et al.,2019;Hu et al.,2019)。表1显示了Ubuntu互联网中继聊天(IRC)频道中的MPC示例,该表由一系列(说话人、对话语句、接收人)三元组组成。除了返回一个恰当的回复外,预测谁将是下一个说话人(Meng等人,2018)以及谁是对话语句的接收人(Ouchi和Tsuboi,2016;Zhang等人,2018a;Le等人,2019)是MPC中独特而重要的问题。

MPC的一个实例总是包含对话者之间、语句之间以及对话者与语句之间的复杂交互。因此,建立对话流程模型并充分理解对话内容是一项挑战。现有的MPC研究利用神经网络学习对话者和语句的表征,其表征空间要么是独立的(Ouchi和Tsuboi,2016),要么是互动的(Zhang等人,2018a)。然而,对话者和语句表征中包含的语义可能无法有效捕获,因为它们来自两个不同的表征空间。最近,为了利用自然语言理解预训练语言模型(PLMs)的突破,一些研究建议将说话人(Gu等人,2020)或主题(Wang等人,2020)信息整合到PLM中。尽管在回复选择方面的表现有所改善,但这些模型仍然忽略了语句和对话者之间的内在关系,如“称呼语”。此外,大多数现有研究分别为MPC中的每个单独任务(例如,接收人识别、说话人识别和回复预测)设计模型。直觉上,这些任务是相辅相成的。同时使用这些任务可以更好地呈现对话者和语句的语境,并有助于提高对话理解,但在以往的研究中被忽视。
基于上述问题,我们提出了MPC-BERT,通过设计PLMs的自监督任务,联合学习(Joint Learning)MPC中的“谁对谁说什么”,从而提高PLMs对MPC的理解能力。具体来说,这五个任务包括回复语句识别、同一说话人搜索、指针一致性区分、掩码共享语句恢复和共享节点检测。前三个任务旨在以从语义到结构(semantics-to-structure)的方式对MPC中的对话者结构进行建模。在MPC-BERT的输出中,对话者通过其所说语句的编码表示进行描述。因此,在这三个任务中,语句语义的表达被用来构建对话结构。另一方面,后两个任务旨在以结构到语义(structure-to-semantics )的方式对语句语义进行建模。直观地说,对话结构影响MPC中的信息流。因此,结构信息也可以用来加强话语语义的表达。通常,这五个自监督任务被用于在多任务学习框架中联合训练MPC-BERT,这有助于模型学习对话者和语句之间以及结构和语义之间的互补信息。通过这种方法,MPC-BERT可以产生更好的对话者和语句表征,可以有效地推广到MPC的多个下游任务。
联合学习和多任务学习
为了衡量这些自监督任务的有效性并测试MPC-BERT的泛化能力,我们在三个下游任务上对其进行了评估,包括接收人识别、说话人识别和回复选择,这是MPC的三个核心研究问题。采用两个基于Ubuntu IRC通道的基准进行评估。其中一份由Hu等人(2019年)发布。另一个由Ouchi和Tsuboi(2016)发布,根据对话长度有三个实验设置。实验结果表明,在这两个基准的测试集上,就接收人识别的对话准确率( accuracy)而言MPC-BERT的性能比目前最先进的模型分别高出3.51%, 2.86%, 3.28%和5.36%,就说话人识别的语句精确率( precision)而言分别高出7.66%, 2.60%, 3.38%和4.24%,就回复选择的回复召回率(recall)而言分别高出3.82%, 2.71%, 2.55%和3.22%。
准确率、精确率、召回率
综上所述,我们在本文中的贡献有三个方面:(1)提出了一种用于MPC理解的PLM:MPC-BERT,设计了五个基于对话和对话者之间交互的自监督任务。(2) 采用三个下游任务来综合评价我们设计的自监督任务的有效性和MPC-BERT的泛化能力。(3) 我们提出的MPC-BERT在两个基准上实现了三个下游任务的当前最优性能。
2 相关工作
现有的建立对话系统的方法大致可分为研究双方对话和多方对话(MPC)。本文研究MPC。除了预测对话语句,识别说话人和识别接收人也是MPC的重要任务。Ouchi和Tsuboi(2016)首先提出了接收人和回复选择任务,并创建了一个MPC语料库用于这项任务的研究。Zhang等人(2018a)提出了SI-RNN,它对说话人嵌入(speaker embeddings)进行角色敏感的更新,用于接收人和回复选择。Meng等人(2018)提出了一项说话人分类任务,作为说话人建模的替代任务。Le等人(2019年)提出了一个who-to-whom(W2W)模型来识别所有对话语句的接收人。Hu et al.(2019)提出了一种图形结构网络(GSN),用于为回复生成的图形信息流建模。Wang等人(2020年)提出跟踪动态主题以进行回复选择。
speaking embeddings
总的来说,以往的MPC研究不能有效地统一对话者和对话语句的表征。此外,它们仅限于每个单独的任务,忽略了不同任务之间的互补信息。据我们所知,本文首次尝试设计各种自监督任务,以构建用于MPC理解的PLM,并尽可能全面地评估PLM在三个下游任务上的性能。
3 MPC-BERT与自监督任务
MPC实例由一系列(说话人、对话语句、接收人)三元组组成,表示为
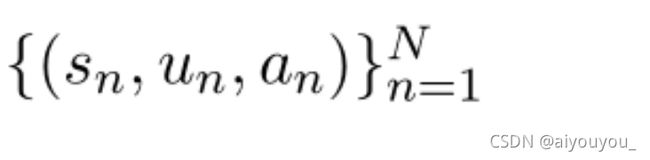 ,其中N是对话的轮数。我们的目标是为通用的MPC理解建立一个预训练语言模型。给定一个对话,该模型期望为所有语句生成嵌入向量(embedding vector),这些嵌入向量不仅包含每个语句的语义信息,还包含整个对话的说话人和接收人结构。因此,通过微调模型参数,它可以有效地适应各种下游任务。
,其中N是对话的轮数。我们的目标是为通用的MPC理解建立一个预训练语言模型。给定一个对话,该模型期望为所有语句生成嵌入向量(embedding vector),这些嵌入向量不仅包含每个语句的语义信息,还包含整个对话的说话人和接收人结构。因此,通过微调模型参数,它可以有效地适应各种下游任务。
3.1 模型概述
本文选择BERT(Devlin et al.,2019)作为我们用于MPC的PLM的主干。因此,我们将其命名为MPC-BERT。值得注意的是,我们提出的用于训练MPC-BERT的自监督任务也可以应用于其他类型的PLM。
我们首先概述了MPC-BERT的输入表示(input representation)和总体架构。在构造输入表示时,为了考虑每个语句的说话人信息,如图1所示,引入了说话人嵌入(Gu等人,2020)。考虑到不同对话中的对话者集合不一致,首先随机初始化一个基于位置的对话者嵌入表,并在预训练过程中进行更新,这意味着根据对话中每个对话者出现的顺序为每个对话者分配一个嵌入向量。然后,通过查找该嵌入表,可以导出每个语句的说话人嵌入。说话人嵌入与标准的标记(token)、位置和分段嵌入相结合,然后由BERT编码。不同的自监督任务利用对应于不同输入标记的BERT的输出嵌入进行进一步计算。
Token
注:词法分析是计算机科学中将字符序列转换为标记(token)序列的过程。从输入字符流中生成标记的过程叫作标记化(tokenization),在这个过程中,词法分析器还会对标记进行分类。

3.2 对话者结构建模任务
前三项任务遵循语义到结构的方式。在MPC-BERT中,每个对话者都是通过其所说语句的编码表示来描述的。因此,语句语义的表达被用来构建对话结构。图1显示了这三个任务的输入表示和模型体系结构。[CLS]标记插入到每个语句的开头,表示其语句级别表征。然后,将对话中的所有语句连接起来,并在整个序列的末尾插入[SEP]标记。值得注意的是,这三个任务共享相同形式的输入数据。因此,输入只需要通过BERT编码一次,而输出可以输入到三个任务中,这样计算效率很高。如图1所示,为了使BERT的输出适应不同的任务,在BERT的顶部放置了一个任务相关的非线性转换层。我们下面将对这些任务的细节进行描述。
3.2.1 回复语句识别(Reply-to Utterance Recognition)
为了使该模型能够识别每一个语句的接收人,提出了一个名为回复语句识别(RUR)的自监督任务来学习当前回复语句的前一个语句。在BERT编码后,我们提取每个[CLS]标记的语境化表示(contextualized representations),这些标记表示单个语句。接下来,执行非线性变换和正规化,以导出这项特定任务的语句表示 ,其中
,其中![]() ,d=768。然后,对于一个特定的语句
,d=768。然后,对于一个特定的语句![]() ,该语句与之前所有语句的匹配分数计算如下:
,该语句与之前所有语句的匹配分数计算如下:

其中![]() 是一个线性变换,mij表示Uj作为Ui的reply-to语句(即Ui回复Uj)的匹配度,1≤j
是一个线性变换,mij表示Uj作为Ui的reply-to语句(即Ui回复Uj)的匹配度,1≤j![]() 中的每个对话进行识别操作。同时,采用动态采样策略,使模型能够查看更多的样本。最后,该自监督任务的预训练目标是尽可能减少交叉熵损失 (cross-entropy loss)
中的每个对话进行识别操作。同时,采用动态采样策略,使模型能够查看更多的样本。最后,该自监督任务的预训练目标是尽可能减少交叉熵损失 (cross-entropy loss)

其中,如果Ui是对Uj的回复则yij=1,否则yij=0。
注:Softmax层作用是将输出正规化。Softmax层将N个(−∞,+∞)的实数映射为N个(0,1)的实数,同时保证这N个数的和为1。这N个(0,1)的实数就代表该样本属于各个类别的概率值。
3.2.2 同一说话人搜索(Identical Speaker Searching)
对于MPC来说,了解谁是一个对话语句的说话人也很重要。同一说话人搜索任务(ISS)被设计为对输入表示中的特定语句的说话人嵌入进行掩码运算,目的是预测给定对话的说话人。由于对话者的集合在不同的对话中有所不同,因此预测某一对话的说话人的任务被重新表述为搜索共享同一说话人的语句。
首先,对于一个特定的语句,它的说话人嵌入被一个特殊的[Mask]对话者嵌入进行掩码表示,以避免信息泄漏。给出此特定任务的语句表示![]() ,其中
,其中![]() ,Ui与其前面所有语句的匹配分数的计算方法与式(1)类似。这里,mij表示Uj与Ui共享同一说话人的匹配度。对于动态采样集
,Ui与其前面所有语句的匹配分数的计算方法与式(1)类似。这里,mij表示Uj与Ui共享同一说话人的匹配度。对于动态采样集![]() 中的每个实例,在前几轮对话中必须有一个语句与它共享同一个说话人。否则,它将从集合中移除。最后,该任务的预训练目标是最小化交叉熵损失,类似于等式(2)。这里,如果Uj与Ui共享同一个说话人则yij=1,否则yij=0。
中的每个实例,在前几轮对话中必须有一个语句与它共享同一个说话人。否则,它将从集合中移除。最后,该任务的预训练目标是最小化交叉熵损失,类似于等式(2)。这里,如果Uj与Ui共享同一个说话人则yij=1,否则yij=0。
3.2.3 指针一致性区分(Pointer Consistency Distinction)
我们设计了一个名为指针一致性区分(PCD)的任务,在MPC中对说话人和接收人进行联合建模。在这个任务中,一对表示“回复”关系的语句被定义为一个说话人到接收人(speaker-to-addressee)指针。这里,我们假设从同一说话人指向同一接收人的两个指针的表示应该是一致的。如图2(a)所示,说话人Sm说了Ui和Uj,分别回复了说话人Sn说的Ui'和Uj'。因此,语句元组(Ui,Ui')和(Uj,Uj')都表示Sm指向Sn的指针,它们的指针表示应该是一致的。

给定此特定任务的语句表示 ,其中
,其中![]() ,首先,我们捕获每个语句元组中包含的指针信息。一个语句元组(Ui,Ui')之间的元素(emlement-wise)差和乘,被计算和串联为
,首先,我们捕获每个语句元组中包含的指针信息。一个语句元组(Ui,Ui')之间的元素(emlement-wise)差和乘,被计算和串联为

其中![]() 。然后,我们压缩(compress)
。然后,我们压缩(compress)![]() 并获得指针表示
并获得指针表示![]()

其中 ![]() ,
, ,这俩是参数。同样,从该对话中抽样的一个一致指针表示
,这俩是参数。同样,从该对话中抽样的一个一致指针表示![]() 和一个不一致指针表示
和一个不一致指针表示![]() 也可以获得。每两个指针之间的相似性计算如下
也可以获得。每两个指针之间的相似性计算如下

其中,mij表示指针![]() 与指针
与指针![]() 一致的匹配程度。mik可以相应地导出。最后,本任务的预训练目标是将铰链损失(hinge loss)降至最低,该铰链损失强制mij比mik至少大∆ (若mij比mik大于等于∆则损失为0)
一致的匹配程度。mik可以相应地导出。最后,本任务的预训练目标是将铰链损失(hinge loss)降至最低,该铰链损失强制mij比mik至少大∆ (若mij比mik大于等于∆则损失为0)

hinge loss
3.3 语句语义建模任务
直观地说,对话结构可能会影响信息流,因此它可以用来加强语句语义的表达。因此,设计了两个遵循从结构到语义的自监督任务。
3.3.1 掩码共享语句恢复(Masked Shared Utterance Restoration)
在MPC中,通常有多个语句是一组shared utterance(共享接收人的语句)的回复目标。直觉上,与非shared utterance相比,shared utterance与更多的上下文中的语句语义相关。基于这一特点,我们设计了一个掩码共享语句恢复(MSUR)任务。我们首先从一个对话中的所有组共享语句中随机抽取一组语句,抽样语句中的所有标记用一个[MASK]标记掩码表示。然后,在给定其余对话的情况下,该模型被强制恢复被掩码表示的语句。
形式上,假设Ui是被掩码表示的一组共享语句,li是Ui中的标记数。给定此任务的标记表示![]() ,其中
,其中![]() ,每个被掩码表示的标记的概率分布可以计算为
,每个被掩码表示的标记的概率分布可以计算为
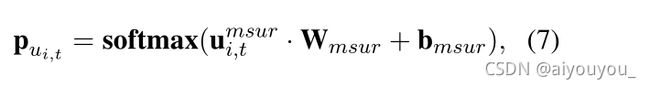 其中
其中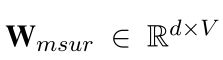 是标记嵌入表,V表示词汇表大小,bmsur∈
是标记嵌入表,V表示词汇表大小,bmsur∈ ![]() 是一个偏移向量。最后,该自监督任务的预训练目标是最小化负对数似然损失( negative log-likelihood loss)
是一个偏移向量。最后,该自监督任务的预训练目标是最小化负对数似然损失( negative log-likelihood loss)

其中,![]() 是
是![]() 对应原始标记中的元素。
对应原始标记中的元素。
3.3.2 共享节点检测(Shared Node Detection)
一个完整的MPC实例可以划分为几个子对话,我们假设同一父节点下的子对话的表示趋于相似。如图2(b)所示,两个子对话{U3,U5,U7,U8}和{U4,U6,U9}共享同一父节点U2。因此,它们应该是语义相关的。在此假设下,我们设计了一个名为共享节点检测(SND)的自监督任务,该任务利用对话结构来增强模型测量两个子对话语义相关性的能力。
我们首先为这项任务构建预训练样本。根据经验,为了过滤出语句较少的子对话,仅收集一个对话中顶部共享节点下的子对话。给定一个完整的MPC,两个语句最多的子对话形成一个正对(positive pair)。对于每一个正对,我们用从训练语料库中随机抽取的另一个子对话替换其中的一个元素,形成一个负对(negative pair)。
形式上,给定两个子对话ci和cj,每个子对话中的语句首先分别连接,形成两个分段(segment)。然后,用[SEP]标记连接两个分段,并在整个序列的开头插入[CLS]标记。该序列由BERT编码,以导出[CLS]标记的语境化表示(contextualized representations)。该表示进一步使用带有sigmoid激活的非线性变换,计算出匹配分数mij,即ci和di共享同一父节点的概率。最后,本任务的预训练目标是尽可能减少交叉熵损失
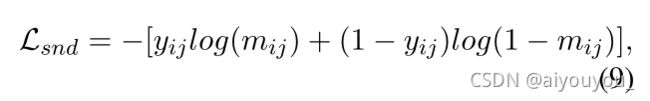
其中,如果ci和cj共享同一父节点,则yij=1,否则yij=0。
3.4 多任务学习
此外,我们还采用了在原始BERT预训练(Devlin等人,2019年)中的掩码语言模型(MLM)和下一句预测(NSP)的任务,这已被证明对整合领域知识是有效的(Gu等人,2020年;Gururangan等人,2020年)。最后,MPC-BERT通过执行多任务学习进行训练,该多任务学习最小化了所有损失函数之和

4 下游任务
4.1 接收人识别(Addressee Recognition)
鉴于多方对话中部分接收人未知,Ouchi和Tsuboi(2016)以及Zhang等人(2018a)识别了最后一句话的接收人。Le等人(2019年)识别了对话中所有语句的接收人。在本文中,我们遵循了Le等人(2019)提出的更具挑战性的设置。
在形式上,给定
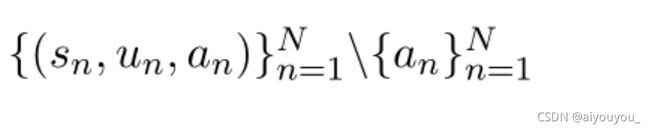
,模型被要求进行预测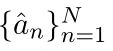 ,其中,
,其中,![]() 是从对话中的对话者集中选择的,\ 表示排除。当应用MPC-BERT时,这项任务被重新表述为从相同接收人处找到一个前面的语句。其与前面所有语句的RUR匹配分数按照公式(1)计算。然后,选择得分最高的语句,并将所选语句的说话人视为识别出的接收人。最后,该任务的微调目标是尽可能减少交叉熵损失
是从对话中的对话者集中选择的,\ 表示排除。当应用MPC-BERT时,这项任务被重新表述为从相同接收人处找到一个前面的语句。其与前面所有语句的RUR匹配分数按照公式(1)计算。然后,选择得分最高的语句,并将所选语句的说话人视为识别出的接收人。最后,该任务的微调目标是尽可能减少交叉熵损失

其中,mij在式(1)中定义,如果Uj的说话人是Ui的接收人,则yij=1,否则yij=0。
4.2 说话人识别(Speaker Identification)
这项任务旨在识别一个对话中最后一句话的说话人。在形式上,给定 ,模型被要求进行预测
,模型被要求进行预测![]() ,其中,
,其中,![]() 是从本次对话的对话者集中挑选出来的。当应用MPC-BERT时,该任务被重新表述为识别共享同一说话人的语句。对于最后一个话语UN,其说话人嵌入被mask,其与所有前面的语句的ISS匹配分数mNj按照第3.2.2节计算。该任务的微调目标是尽可能减少交叉熵损失
是从本次对话的对话者集中挑选出来的。当应用MPC-BERT时,该任务被重新表述为识别共享同一说话人的语句。对于最后一个话语UN,其说话人嵌入被mask,其与所有前面的语句的ISS匹配分数mNj按照第3.2.2节计算。该任务的微调目标是尽可能减少交叉熵损失
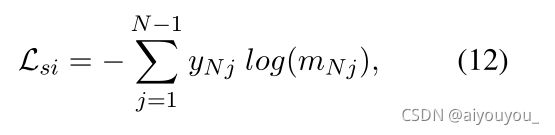
其中,如果Uj与UN共享同一个说话人,则yNj=1,否则yNj=0。
4.3 回复选择(Response Selection)
该任务要求模型在给定对话上下文![]() 的情况下,从一组候选回复中选择
的情况下,从一组候选回复中选择![]() 。关键是衡量上下文两段和回复的相似性。我们将每个回复候选与上下文连接起来,并使用MPC-BERT提取第一个[CLS]标记的上下文化表示
。关键是衡量上下文两段和回复的相似性。我们将每个回复候选与上下文连接起来,并使用MPC-BERT提取第一个[CLS]标记的上下文化表示![]() 。然后,将e[CLS]馈入具有sigmoid激活的非线性变换,以获得上下文和回复之间的匹配分数。最后,该任务的微调目标是根据训练集中回复的真/假标签最小化交叉熵损失
。然后,将e[CLS]馈入具有sigmoid激活的非线性变换,以获得上下文和回复之间的匹配分数。最后,该任务的微调目标是根据训练集中回复的真/假标签最小化交叉熵损失

其中,如果回复r是上下文C的适当响应则y=1;否则y=0。
5 实验
5.1 数据集
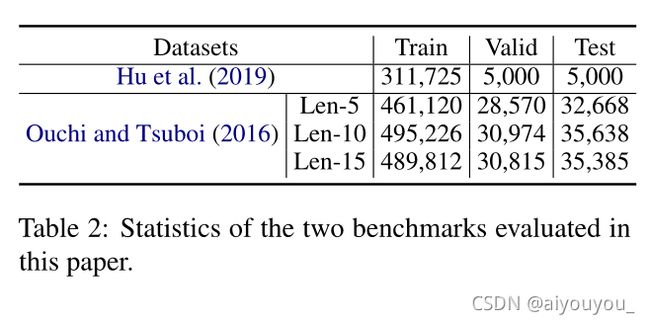
我们在两个Ubuntu IRC基准上评估了我们提出的方法。其中一个由Hu等人(2019年)发布,其中为每个话语提供了说话人和收件人标签。另一个基准是由Ouchi和Tsuboi(2016年)发布的。在这里,我们采用了inLe等人(2019)共享的版本进行公平比较。根据先前研究的拆分策略(Ouchi和Tsuboi,2016;Zhang等人,2018a;Le等人,2019),根据会话长度将会话分为三类(Len5、Len-10和Len-15)。表2给出了在我们的实验中评估的两个基准的统计数据。
5.2 基线模型
基于非预训练的模型
Ouchi和Tsuboi(2016)提出了一个动态模型DRNN,该模型使用会话流更新说话人嵌入。Zhang等人(2018a)将DRNN改进为SI-RNN,从而敏感地更新了说话人嵌入角色。Le等人(2019年)提出了W2W,它在一个统一的框架内联合模拟对话者和话语,并预测所有的收件人。
基于预训练的模型
BERT(Devlin等人,2019年)接受过预先培训,学习MLM和NSP任务的一般语言表达。SABERT(Gu et al.,2020)在特定领域语料库中添加了说话人嵌入和进一步的预训练,以整合领域知识。我们使用本文使用的预训练语料库重新实现了SA-BERT,以确保公平比较。
5.3 实施细节
我们所有的实验都采用了BERT-base-uncased版本。对于预培训,GELU(Hendrycks和Gimpel,2016)被用作所有非线性转换的激活。采用Adam方法(Kingma和Ba,2015)进行优化。学习速率已初始化为0。00005,预热比例设置为0。1我们预先训练了10个时代的伯特。Hu等人(2019年)使用的数据集的训练集用于预训练。最大话语数设置为7。最大序列长度设置为230。对于RUR,每个示例的最大采样数设置为4,ISS为2,PCD为2。∆在等式(6)中,被设置为0。4,在验证集的{0.2,0.4,0.6,0.8}中获得最佳性能。使用GeForce RTX 2080 Ti GPU进行预培训,批量大小设置为4。
对于微调,根据这些数据集的特点,某些配置是不同的。ForHu等人(2019年),最大话语数设置为7,最大序列长度设置为230。对于inOuchi和Tsuboi(2016)的三个实验设置,最大话语数设置为5、10和15,最大序列长度设置为120、220和320。PLMs中的所有参数均已更新。学习速率已初始化为0。00002,预热比例设置为0。1.ForHu等人(2019年)对10个时期的收件人识别、10个时期的说话人识别和5个时期的响应选择进行了微调。ForOuchi和Tsuboi(2016)将微调时间分别设置为5、5和3。还使用GeForce RTX 2080 Ti GPU执行微调。Hu等人(2019年)将批量设置为16,inOuchi和Tsuboi(2016年)的三个实验设置分别设置为40、20和12。验证集用于选择最佳模型进行测试。
所有代码均在TensorFlow框架中实施(Abadi等人,2016年),并发布以帮助复制我们的结果。
5.4 指标和结果
接收人识别
我们遵循先前工作的指标(Le等人,2019年),采用precision@1 (P@1)用基本事实来评价每一句话。此外,如果一个会话的所有话语的收件人都被正确识别,则该会话被标记为肯定会话,这被计算为准确度(Acc.)。
表3显示了收件人识别的结果。结果表明,MPC-BERT的性能优于性能最好的模型,即。E萨伯特,以3的优势。51%, 2. 86%, 3. 28%和5%。就Acc而言,在这些测试集上分别为36%,验证了建议的五项自我监督任务作为一个整体的有效性。为了进一步说明每个任务的有效性,进行了消融试验,如表3最后五行所示。我们可以观察到,所有自我监督的任务都是有用的,因为删除任何一个任务都会导致性能下降。在这五项任务中,RUR起着最重要的作用,而关注对话者结构建模的任务比关注话语语义的任务贡献更大。

说话人识别
同样地,P@1被用作会话最后一次话语的说话人识别评估指标,结果如表4所示。结果表明,MPC-BERT比SA-BERT的性能好7倍。66%, 2. 60%, 3. 38%和4%。按价格计算,分别为24%P@1. 此外,从烧蚀结果中我们发现,所有任务都有助于提高说话人识别的性能,ISS和RUR贡献最大。特别是,删除PCD、MSUR和SND只会导致性能轻微下降。原因可能是这些任务传递的信息是多余的。

回复选择
这个Rn@kmetrics此处采用了之前的研究(Ouchi和Tsuboi,2016;Zhang等人,2018a)。每个模型的任务是从可用的候选者中选择最匹配的回答,我们计算召回率为Rn@k. 遵循两种设置,其中Kwas设置为1,nwas设置为2或10。
表5显示了响应选择的结果。结果表明,MPC-BERT的表现优于SABERT,相差3%。82%, 2. 71%, 2. 55%和3%。按成本计算,分别为22%R10@1. 烧蚀测试表明,SND是最有用的反应选择任务,两个任务侧重于话语语义的贡献大于侧重于对话者结构的任务。

5.5 论述
图3说明了在Ouchi和Tsuboi(2016)的测试集上,BERT、SA-BERT和MPC-BERT的性能如何随着不同的会话长度而变化。可以看出,随着会话长度的增加,收件人识别和说话人识别的性能下降。原因可能是较长的会议总是包含更多的对话者,这增加了预测对话者的难度。同时,响应选择的性能随着会话长度的增加而显著提高。这可以归因于较长的会话通过更多的细节丰富了上下文的表示,这有利于响应选择。此外,随着会话长度的增加,MPC-BERT在收件人识别和说话人识别方面的性能比SA-BERT稍有下降,并且R10@1gapMPC-BERT和SA-BERT之间的响应选择从2扩大。71%对3。22%. 这些结果表明,在建模复杂结构的长MPC时,MPC-BERT优于SA-BERT。

6 结论
在本文中,我们提出了MPC-BERT,一个预训练的语言模型,具有五个自我监督的任务,用于理解MPC。这些任务共同学习人类MPC的说法。在三个下游任务上的实验结果表明,MPC-BERT在两个基准上的性能大大优于以前的方法,并达到了最新的水平。