Pandas+Seaborn+Plotly:联手探索苹果AppStore
公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
今天给大家分享一篇kaggle实战的新文章:基于Seaborn+Plotly的AppleStore可视化探索,这是一篇完全基于统计+可视化的数据分析案例。
原notebook只用了seaborn库,很多图形小编用plotly进行了实现,原文章地址:https://www.kaggle.com/adityapatil673/visual-analysis-of-apps-on-applestore/notebook

导入库
import pandas as pd
import numpy as np
# 可视化
from matplotlib import pyplot as plt
import seaborn as sns
import plotly_express as px
import plotly.graph_objects as go
数据基本信息
读取并且查看基本信息:

# 1、整体大小
data.shape
(7197, 16)
# 2、缺失值
data.isnull().sum()
id 0
track_name 0
size_bytes 0
currency 0
price 0
rating_count_tot 0
rating_count_ver 0
user_rating 0
user_rating_ver 0
ver 0
cont_rating 0
prime_genre 0
sup_devices.num 0
ipadSc_urls.num 0
lang.num 0
vpp_lic 0
dtype: int64
# 3、字段类型
data.dtypes
id int64
track_name object
size_bytes int64
currency object
price float64
rating_count_tot int64
rating_count_ver int64
user_rating float64
user_rating_ver float64
ver object
cont_rating object
prime_genre object
sup_devices.num int64
ipadSc_urls.num int64
lang.num int64
vpp_lic int64
dtype: object
一般情况下,也会查看数据的描述统计信息(针对数值型的字段):

APP信息统计
免费的APP数量
sum(data.price == 0)
4056
价格超过50的APP数量
价格大于50即表示为:超贵(原文:super expensive apps)
sum(data.price >= 50)
7
价格超过50的比例
sum((data.price > 50) / len(data.price) * 100)
0.09726274836737528
# 个人写法
sum(data.price >= 50) / len(data) * 100
0.09726274836737529
离群数据
价格超过50的APP信息
outlier = data[data.price > 50][['track_name','price','prime_genre','user_rating']]
outlier

免费APP
选择免费APP的数据信息

正常区间的APP
取数
paidapps = data[(data["price"] > 0) & (data.price < 50)]
# 正常价格区间的最大值和最小值
print("max_price:", max(paidapps.price))
print("min_price:", min(paidapps.price))
max_price: 49.99
min_price: 0.99
价格分布
plt.style.use("fivethirtyeight")
plt.figure(figsize=(12,10))
# 1、绘制直方图
# 2*1*1 两行一列的第1个图
plt.subplot(2,1,1) # 位置
plt.hist(paidapps.price, log=True) # 绘制直方图
# 标题和label值
plt.title("Price distribution of apps (Log scale)")
plt.ylabel("Frequency Log scale")
plt.xlabel("Price Distributions in ($) ")
# 2、绘制stripplot(分布散点图)
# 两行一列的第2个图
plt.subplot(2,1,2)
plt.title("Visual Price distribution")
sns.stripplot(data=paidapps, # 整体数据
y="price", # 待绘图的字段
jitter=True, # 当数据点重合较多时,用该参数做调整
orient="h", # 水平方向显示 h-水平 v-垂直
size=6
)
plt.show()

结论1
- 随着价格的上涨,付费应用的数量呈现指数级的下降
- 很少应用的价格超过30刀;因此,尽量保持价格在30以下
category对价格分布的影响
data.columns # 数据字段
Index(['id', 'track_name', 'size_bytes', 'currency', 'price',
'rating_count_tot', 'rating_count_ver', 'user_rating',
'user_rating_ver', 'ver', 'cont_rating', 'prime_genre',
'sup_devices.num', 'ipadSc_urls.num', 'lang.num', 'vpp_lic'],
dtype='object')
种类及数目
data["prime_genre"].value_counts()
Games 3862
Entertainment 535
Education 453
Photo & Video 349
Utilities 248
Health & Fitness 180
Productivity 178
Social Networking 167
Lifestyle 144
Music 138
Shopping 122
Sports 114
Book 112
Finance 104
Travel 81
News 75
Weather 72
Reference 64
Food & Drink 63
Business 57
Navigation 46
Medical 23
Catalogs 10
Name: prime_genre, dtype: int64
显示前5个种类
# y轴范围
yrange = [0,25]
fsize =15
plt.figure(figsize=(12,10))
# 分别绘制5个子图
# 图1
plt.subplot(5,1,1)
plt.xlim(yrange)
# 挑出第一类的数据
games = paidapps[paidapps["prime_genre"] == "Games"]
sns.stripplot(data=games,
y="price",
jitter=True,
orient="h",
size=6,
color="#eb5e66"
)
plt.title("Games", fontsize=fsize)
plt.xlabel("")
# 图2
plt.subplot(5,1,2)
plt.xlim(yrange)
# 挑出第一类的数据
ent = paidapps[paidapps["prime_genre"] == "Entertainment"]
sns.stripplot(data=ent,
y="price",
jitter=True,
orient="h",
size=6,
color="#ff8300"
)
plt.title("Entertainment", fontsize=fsize)
plt.xlabel("")
# 图3
plt.subplot(5,1,3)
plt.xlim(yrange)
edu = paidapps[paidapps.prime_genre=='Education']
sns.stripplot(data=edu,y='price',jitter= True ,orient ='h' ,size=6,color='#20B2AA')
plt.title('Education',fontsize=fsize)
plt.xlabel('')
# 图4
plt.subplot(5,1,4)
plt.xlim(yrange)
pv = paidapps[paidapps.prime_genre=='Photo & Video']
sns.stripplot(data=pv,
y='price',
jitter= True,
orient ='h',
size=6,
color='#b84efd')
plt.title('Photo & Video',fontsize=fsize)
plt.xlabel('')
# 图5(个人添加)
plt.subplot(5,1,5)
plt.xlim(yrange)
ut = paidapps[paidapps.prime_genre=='Utilities']
sns.stripplot(data=ut,
y='price',
jitter= True,
orient ='h',
size=6,
color='#084cfd')
plt.title('Utilities',fontsize=fsize)
plt.xlabel('')

结论2
- Games游戏类的apps价格相对高且分布更广,直到25美元
- Entertainment娱乐类的apps价格相对较低
Paid apps Vs Free apps
付费APP和免费APP之间的比较
app种类
# app的种类
categories = data["prime_genre"].value_counts()
categories
Games 3862
Entertainment 535
Education 453
Photo & Video 349
Utilities 248
Health & Fitness 180
Productivity 178
Social Networking 167
Lifestyle 144
Music 138
Shopping 122
Sports 114
Book 112
Finance 104
Travel 81
News 75
Weather 72
Reference 64
Food & Drink 63
Business 57
Navigation 46
Medical 23
Catalogs 10
Name: prime_genre, dtype: int64
len(categories)
23
选择前4个
选择前4个,其他的APP全部标记为Other
s = categories.index[:4]
s
Index(['Games', 'Entertainment', 'Education', 'Photo & Video'], dtype='object')
def categ(x):
if x in s:
return x
else:
return "Others"
data["broad_genre"] = data["prime_genre"].apply(categ)
data.head()
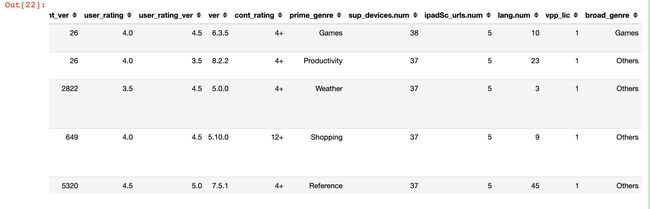
统计免费和付费APP下的种类数
# 免费
data[data.price==0].broad_genre.value_counts()
Games 2257
Others 1166
Entertainment 334
Photo & Video 167
Education 132
Name: broad_genre, dtype: int64

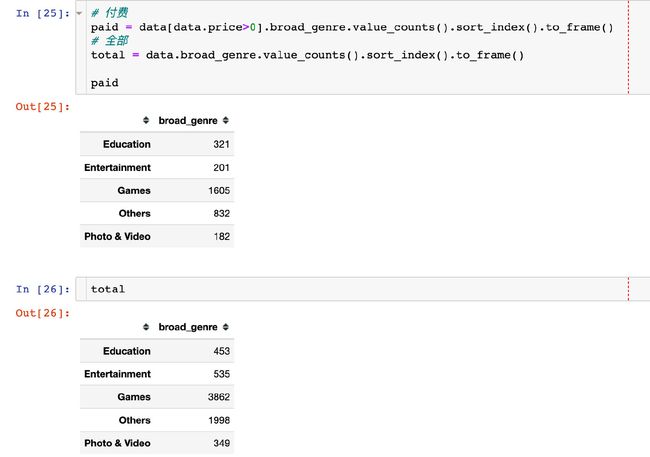
将两个数据合并起来:

统计量对比
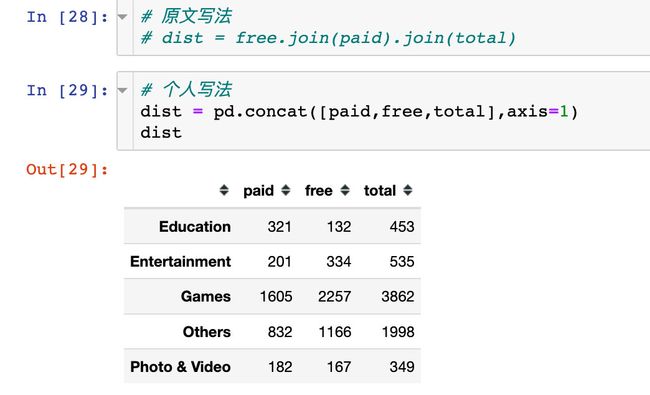

高亮显示最大值(个人增加)
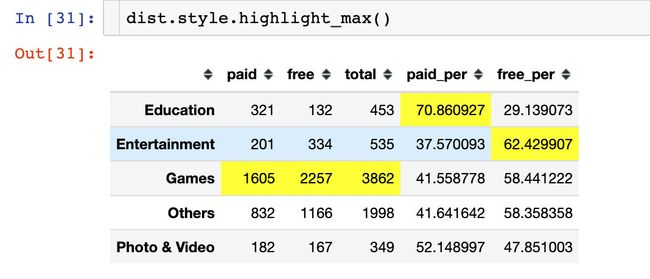
结论3
从上面的高亮结果中,我们发现:
- Games相关的APP是最多的,不管是paid还是free
- 从付费占比来看,Education教育类型占比最大
- 从免费占比来看,Entertainment娱乐类型的占比最大
付费和免费的占比
生成数据
分组对比付费和免费的占比
list_free = dist.free_per.tolist()
list_free
[29.13907284768212,
62.42990654205608,
58.44122216468152,
58.35835835835835,
47.85100286532951]
# 列表转成元组
tuple_free = tuple(list_free)
# 付费类型相同操作
tuple_paidapps = tuple(dist.paid_per.tolist())
柱状图
plt.figure(figsize=(12,8))
N = 5
ind = np.arange(N)
width = 0.56 # 两个柱子间的宽度
p1 = plt.bar(ind, tuple_free, width, color="#45cea2")
p2 = plt.bar(ind,tuple_paidapps,width,bottom=tuple_free,color="#fdd400")
plt.xticks(ind,tuple(dist.index.tolist()))
plt.legend((p1[0],p2[0]),("free","paid"))
plt.show()

饼图
# 绘制饼图
pies = dist[['free_per','paid_per']]
pies.columns=['free %','paid %']
pies

plt.figure(figsize=(15,8))
pies.T.plot.pie(subplots=True, # 显示子图
figsize=(20,4), # 大小
colors=['#45cea2','#fad470'] # 颜色
)
plt.show()

结论4
- 在教育类的APP中,付费paid的占比是很高的
- 相反的,在娱乐类的APP中,免费free的占比是很高的
付费APP真的足够好吗?
价格分类
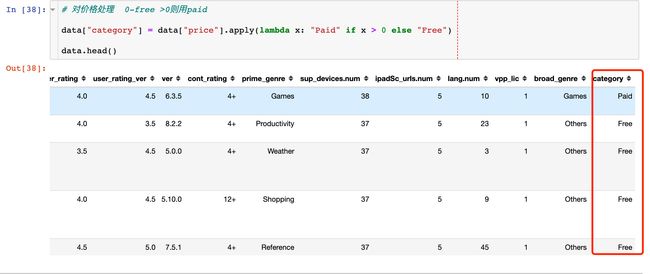
# 对价格处理 0-free >0则用paid
data["category"] = data["price"].apply(lambda x: "Paid" if x > 0 else "Free")
data.head()
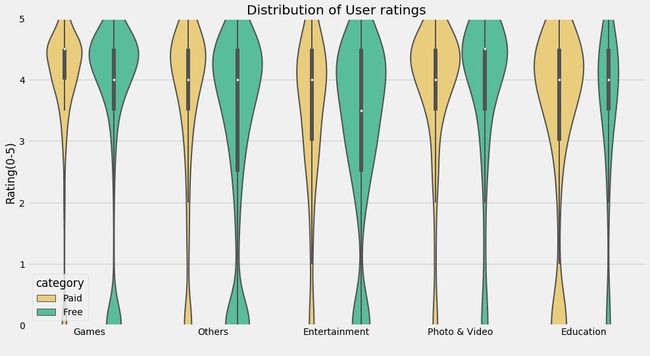
小提琴图
plt.figure(figsize=(15,8))
plt.style.use("fast")
plt.ylim([0,5])
plt.title("Distribution of User ratings")
sns.violinplot(data=data, # 数据+2个轴
y="user_rating",
x="broad_genre",
hue="category", # 分组
vertical=True, # 垂直显示
kde=False,
split=True, # 同个类别的小提琴图一起显示
linewidth=2,
scale="count",
palette=['#fdd470','#45cea2']
)
plt.xlabel(" ")
plt.ylabel("Rating(0-5)")
plt.show()

结论5(个人增加)
- 在Education类的APP中,paid的占比是明显高于free;其次是Photo & Video
- Entertainment娱乐的APP,free占比高于paid;且整体的占比分布更为宽
注意下面的代码中改变了split参数:
plt.figure(figsize=(15,8))
plt.style.use("fast")
plt.ylim([0,5])
plt.title("Distribution of User ratings")
sns.violinplot(data=data,
y="user_rating",
x="broad_genre",
hue="category",
vertical=True,
kde=False,
split=False, # 关注这个参数
linewidth=2,
scale="count",
palette=['#fdd470','#45cea2']
)
plt.xlabel(" ")
plt.ylabel("Rating(0-5)")
plt.show()
size和price 关系
探索:是不是价格越高,size越大了?
sns.color_palette("husl",8)
sns.set_style("whitegrid")
flatui = ["#9b59b6", "#3498db", "#95a5a6", "#e74c3c", "#34495e", "#2ecc71"]
# 改变字节数
data["MB"] = data.size_bytes.apply(lambda x: x/1048576)
# 挑选区间的数据
paidapps_regression =data[((data.price<30) & (data.price>0))]
sns.lmplot(data=paidapps_regression,
x="MB",
y="price",
size=4,
aspect=2,
col_wrap=2,
hue="broad_genre",
col="broad_genre",
fit_reg=False,
palette=sns.color_palette("husl",5)
)
plt.show()

使用Plotly实现(个人增加)
增加使用plotly实现方法
px.scatter(paidapps_regression,
x="MB",
y="price",
color="broad_genre",
facet_col="broad_genre",
facet_col_wrap=2
)

APP分类:是否可根据paid和free来划分
5种类型占比
# 1、设置颜色和大小
BlueOrangeWapang = ['#fc910d','#fcb13e','#239cd3','#1674b1','#ed6d50']
plt.figure(figsize=(10,10))
# 2、数据
label_names=data.broad_genre.value_counts().sort_index().index
size = data.broad_genre.value_counts().sort_index().tolist()
# 3、内嵌空白圆
my_circle=plt.Circle((0,0), 0.5, color='white')
# 4、圆
plt.pie(size, labels=label_names, colors=BlueOrangeWapang)
p=plt.gcf()
p.gca().add_artist(my_circle)
plt.show()

使用plotly如何实现:
# Plotly如何实现
fig = px.pie(values=size,
names=label_names,
labels=label_names,
hole=0.5)
fig.update_traces(textposition='inside', textinfo='percent+label')
fig.show()

5种类型+是否付费
f=pd.DataFrame(index=np.arange(0,10,2),
data=dist.free.values, # free
columns=['num'])
p=pd.DataFrame(index=np.arange(1,11,2),
data=dist.paid.values, # paid
columns=['num'])
final = pd.concat([f,p],names=['labels']).sort_index()
final

plt.figure(figsize=(20,20))
group_names=data.broad_genre.value_counts().sort_index().index
group_size=data.broad_genre.value_counts().sort_index().tolist()
h = ['Free', 'Paid']
subgroup_names= 5*h
sub= ['#45cea2','#fdd470']
subcolors= 5*sub
subgroup_size=final.num.tolist()
# 外层
fig, ax = plt.subplots()
ax.axis('equal')
mypie, _ = ax.pie(group_size, radius=2.5, labels=group_names, colors=BlueOrangeWapang)
plt.setp( mypie, width=1.2, edgecolor='white')
# 内层
mypie2, _ = ax.pie(subgroup_size, radius=1.6, labels=subgroup_names, labeldistance=0.7, colors=subcolors)
plt.setp( mypie2, width=0.8, edgecolor='white')
plt.margins(0,0)
plt.show()

基于plotly的实现:
# plotly如何实现
fig = px.sunburst(
data,
path=["broad_genre","category"],
values="MB"
)
fig.show()
