FastAPI第五天---实现一个机器学习后端demo
文章目录
- FastAPI第五天
-
- 1. 训练模型
- 2.编写API
- 3.优化API
FastAPI第五天
在前面,我随着官网文档已经将常用的框架功能全部过了一遍,比如路由设置、模块化设计、数据库连接操作、路由参数以及参数校验……今天就可以正式利用FastAPI来实现我们本来的目标—利用FastAPI来搭建一个我们的机器学习服务
开始之前,先来规划一下实现这个小demo的步骤:
- 首先我们需要训练一个模型
- 然后后端设置对应路由,并且调用模型预测,返回预测结果
- 优化项目
1. 训练模型
在这个demo中,我们使用20 newsgroups数据集,数据集链接
数据集包含18000篇新闻文章,一共涉及到20种话题,所以称作20 newsgroups text dataset,分文两部分:训练集和测试集,通常用来做文本分类,在``sklearn的datasets`中我们可以很方便的下载数据。
这是文本分类,所以我们需要将数据集的文本内容转为词向量;为了简化模型,我们只使用其中的四类。
import pandas as pd
import seaborn as sns
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.naive_bayes import MultinomialNB
from sklearn.svm import SVC
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from sklearn.pipeline import make_pipeline,Pipeline
import warnings
warnings.filterwarnings('ignore')
# 设置并载入数据集
categories = [
"soc.religion.christian",
"talk.religion.misc",
"comp.sys.mac.hardware",
"sci.crypt",
]
newsgroups_training = fetch_20newsgroups(
subset="train", categories=categories, random_state=0
)
newsgroups_testing = fetch_20newsgroups(
subset="test", categories=categories, random_state=0
)
# 制定pipeline管道
model = make_pipeline(
TfidfVectorizer(),
#MultinomialNB(),
#SVC(),
#AdaBoostClassifier(n_estimators=100),
#GradientBoostingClassifier(),
XGBClassifier()
)
# 训练并查看模型效果
model.fit(newsgroups_training.data, newsgroups_training.target)
predicted_targets = model.predict(newsgroups_testing.data)
accuracy = accuracy_score(newsgroups_testing.target, predicted_targets)
print(accuracy)
confusion = confusion_matrix(newsgroups_testing.target, predicted_targets)
confusion_df = pd.DataFrame(
confusion,
index=pd.Index(newsgroups_testing.target_names, name="True"),
columns=pd.Index(newsgroups_testing.target_names, name="Predicted"),
)
sns.heatmap(confusion_df,fmt='g',annot=True,cmap='Blues')
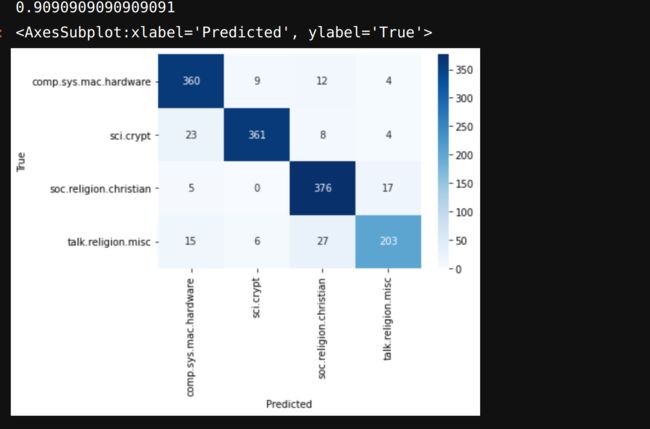
模型准确率0.9,混淆矩阵结果看起来也还算不错(今天的重点不在模型上,所以就不深究模型优化相关的内容),再有了较好性能的模型之后,我们就需要保存模型文件,并且运用模型文件进行分类预测
# 效果还可以,开始保存模型
import joblib
model_file = "model.joblib"
model_targets_tuple = (model, newsgroups_training.target_names)
joblib.dump(model_targets_tuple, model_file)
# 加载训练好的模型进行预测
import os
from typing import List, Tuple
model_file = os.path.join(os.getcwd(), "model.joblib")
loaded_model: Tuple[Pipeline, List[str]] = joblib.load(model_file)
model, targets = loaded_model
p = model.predict(["computer cpu memory ram"])
print(targets[p[0]])
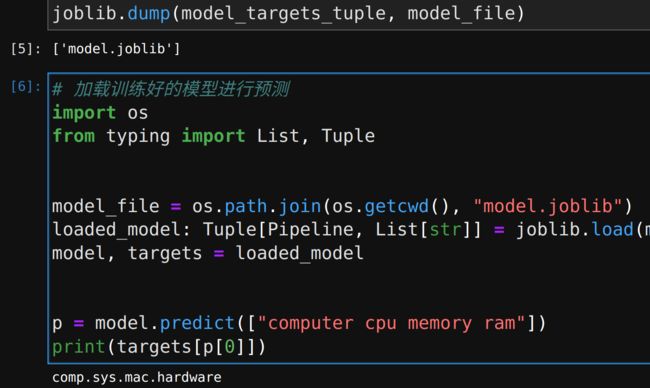
到这里,我们就完成了第一步得到了我们demo的模型,并且已经保存为joblib文件,可以随时调用。
2.编写API
有了上面的模型,我们就开始编写API。最起码的功能,提交内容可以返回对应的类别,这是必须要实现的;其次,我们要设置事件,在开始的时候要自动导入我们保存好的模型。有了上面这两个想法,就开始编写API代码
import os
from typing import List, Optional, Tuple
import joblib
from fastapi import FastAPI, Depends, status
from pydantic import BaseModel
from sklearn.pipeline import Pipeline
class PredictionInput(BaseModel):
text: str
class PredictionOutput(BaseModel):
result: str
memory = joblib.Memory(location='cache.joblib')
@memory.cache(ignore=['model'])
def predict(model: Pipeline, text: str) -> int:
prediction = model.predict([text])
return prediction[0]
class Model:
model: Optional[Pipeline]
targets: Optional[List[str]]
def load_model(self):
model_file = os.path.join(os.getcwd(), "model.joblib")
loaded_model: Tuple[Pipeline, List[str]] = joblib.load(model_file)
model, targets = loaded_model
self.model = model
self.targets = targets
def predict(self, input: PredictionInput) -> PredictionOutput:
if not self.model or not self.targets:
raise RuntimeError("模型加载失败")
prediction = predict(self.model,input.text)
result = self.targets[prediction]
return PredictionOutput(result=result)
app = FastAPI()
My_model = Model()
@app.post("/prediction")
def prediction(
output: PredictionOutput = Depends(My_model.predict),
) -> PredictionOutput:
return output
@app.on_event("startup")
async def startup():
My_model.load_model()
@app.delete("/cache", status_code=status.HTTP_204_NO_CONTENT)
def delete_cache():
memory.clear()
可以看到,我定义了一个Model类,其中包含了加载模型和预测的类方法。将预测的类方法依赖注入到我们的预测路由中,然后启动事件中绑定我们的模型载入。你们也可以看到,除了上面我说的基本功能之外还有memory之类的内容,这也就是下面要讲到的优化问题。所以干脆就把代码贴出来,然后后面讲细节。
3.优化API
设想这样一个场景,A访问这个路由提交了一组数据,之后B提交了同样的数据,这个时候我们不愿意花费计算资源再去为同一组数据做预测,所以我们需要将每一次预测的结果进行缓存,这样再次遇到相同的数据请求时我们就可以直接返回响应结果,这也就是joblib.Memory()的作用。
有的人还有可能好奇,为什么在Model类中的预测函数不写作异步函数,因为前面memory装饰的预测函数并不支持异步
在我们缓存的时候,进行I/O操作,在硬盘上读取或者写入缓存文件,这个时候会占用进程,也就是程序只能串行。而FastAPI在当我们的路径操作函数(这里就是'/prediction'路由下的prediction函数)定义为标准的非异步函数时,它会将路径操作函数放在一个单独的进程中运行,这就代表着原本的阻塞操作并不会阻塞主进程,某种程度上来说还是相当于异步操作。
当我们更换模型的时候,需要清空磁盘中存储的缓存文件,所以设置一个Delete路由清除所有缓存文件。到这里,我们今天的demo就算是实现了,下面来看一下效果。
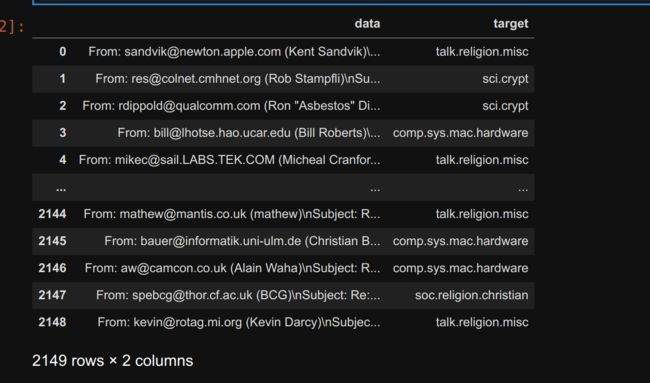
为了得到数据,我们就从训练数据中拿一点来试试
data=pd.concat(
[pd.DataFrame(newsgroups_training.data,columns=['data']),pd.DataFrame(newsgroups_training.target,columns=['target'])],
axis=1,
)
data['target']=data['target'].map(dict(zip([i for i in range(4)],newsgroups_training.target_names)))
data
得到数据后,来到Swagger页面来进行测试

然后目录中可以看到缓存的内容