吴恩达机器学习课程笔记(11-18章)
第十一章
11.1 确定执行的优先级
垃圾邮件分类器算法: 为了解决这样一个问题,我们首先要做的决定是如何选择并表达特征向量 x x x 。我们可以选择一个由 100 100 100 个最常出现在垃圾邮件中的词所构成的列表,根据这些词是否有在邮件中出现,来获得我们的特征向量(出现为 1 1 1,不出现为 0 0 0),尺寸为 100 × 1 100×1 100×1 。
为了构建这个分类器算法,我们可以做很多事,例如:
- 收集更多的数据,让我们有更多的垃圾邮件和非垃圾邮件的样本
- 基于邮件的路由信息开发一系列复杂的特征
- 基于邮件的正文信息开发一系列复杂的特征,包括考虑截词的处理
- 为探测刻意的拼写错误(把watch写成w4tch)开发复杂的算法
在上面这些选项中,非常难决定应该在哪一项上花费时间和精力,作出明智的选择,比随着感觉走要更好。
11.2 误差分析
帮助解决在各种提升性能的方法中进行选择。
- 推荐方法
- 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法
- 绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
- 进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的样本,看看这些样本是否有某种系统化的趋势
- 用一个数字去直观的体现算法性能是重要的
- 误差分析应该在验证集上进行
11.3 不对称性分类的误差评估
不对称性分类: 数据集中一种类别的数量比另一种多得多,如:癌症影像识别。
如果有一个偏斜类分类任务(癌症诊断),用分类精确度并不能很好地衡量算法性能,如癌症诊断任务中可能现有数据集中仅有 5 % 5\% 5% 的样本为阳性样本,因此即使我们用一个只会输出负类的分类器,也可以获得 95 % 95\% 95% 的准确率,但显然这是没有意义的。为解决上述问题,引入下述评价指标。
我们将算法预测的结果分为四种情况:
- 正确肯定(True Positive,TP): 预测为真,实际为真
- 正确否定(True Negative,TN): 预测为假,实际为假
- 错误肯定(False Positive,FP): 预测为真,实际为假
- 错误否定(False Negative,FN): 预测为假,实际为真
查准率: Precision = TP / (TP + FP)
例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率: Recall = TP / (TP + FN)
例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。

11.4 查准率和查全率的权衡
如果我们希望只在非常确信的情况下预测为真(肿瘤为恶性),即我们希望更高的查准率,我们可以使用比0.5更大的阀值,如0.7,0.9。这样做我们会减少错误预测病人为恶性肿瘤的情况,同时却会增加未能成功预测肿瘤为恶性的情况。
如果我们希望提高查全率,尽可能地让所有有可能是恶性肿瘤的病人都得到进一步地检查、诊断,我们可以使用比0.5更小的阀值,如0.3。
我们可以将不同阀值情况下,查全率与查准率的关系绘制成图表,曲线的形状根据数据的不同而不同:

我们希望有一个帮助我们选择这个阀值的方法。一种方法是计算F1值(F1 Score),其计算公式为: F 1 S c o r e = 2 P R P + R F1\ Score=\frac{2PR}{P+R} F1 Score=P+R2PR
我们选择使得F1值最高的阀值。
11.5 机器学习数据
“不是谁有最好的算法就能获胜。而是谁拥有最多的数据”。
海量数据是合理的。
- 假设特征 x ∈ R n + 1 x\in R^{n+1} x∈Rn+1 已经提供了足够的信息,可以去准确的预测出标签 y y y。判断这一点:给出这样的特征输入 x x x,人类专家是否可以给出正确的输出。
- 学习算法可以使用更多的参数
- 使用更多的训练数据,不易过拟合。
第十二章
12.1 优化目标
逻辑回归:
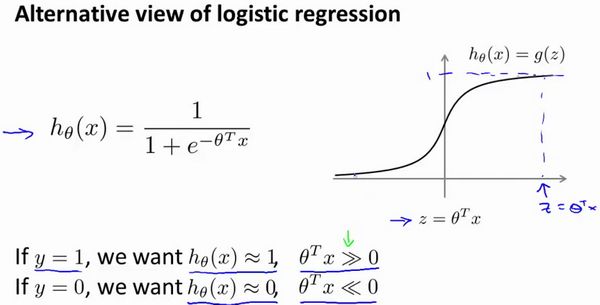
C o s t ( h θ ( x ) , y ) = − y log h θ ( x ) − ( 1 − y ) log ( 1 − h θ ( x ) ) Cost(h_\theta(x),y)=-y\log h_\theta(x)-(1-y)\log(1-h_\theta(x)) Cost(hθ(x),y)=−yloghθ(x)−(1−y)log(1−hθ(x))
令 c o s t 1 ( θ T x ) = − log h θ ( x ) cost_1(\theta^T x)=-\log h_\theta(x) cost1(θTx)=−loghθ(x), c o s t 0 ( θ T x ) = − log ( 1 − h θ ( x ) ) cost_0(\theta^T x)=-\log(1-h_\theta(x)) cost0(θTx)=−log(1−hθ(x))
SVM hypothesis:
min θ C ∑ i = 1 m [ y ( i ) c o s t 1 ( θ T x ( i ) ) + ( 1 − y ( i ) ) c o s t 0 ( θ T x ( i ) ) ] + 1 2 ∑ i = 1 n θ j 2 \mathop{\min}\limits_{\theta}C\sum\limits_{i=1}^{m}[y^{(i)}cost_1(\theta^Tx^{(i)})+(1-y^{(i)})cost_0(\theta^Tx^{(i)})]+\frac{1}{2}\sum\limits_{i=1}^n\theta_j^2 θminCi=1∑m[y(i)cost1(θTx(i))+(1−y(i))cost0(θTx(i))]+21i=1∑nθj2
Hypothesis:
h θ ( x ) = { 1 i f θ T x ≥ 0 0 o t h e r w i s e h_\theta(x)=\begin{cases}1&if\ \theta^Tx\ge0\\0&otherwise\end{cases} hθ(x)={10if θTx≥0otherwise
12.2 直观上对大间隔的理解
SVM:

决策边界:

如果你将C设置的不要太大,则你最终会得到这条黑线;当不是非常非常大的时候,它可以忽略掉一些异常点的影响,得到更好的决策边界。
- C C C 较大时,相当于 λ \lambda λ 较小,可能会导致过拟合,高方差
- C C C 较小时,相当于 λ \lambda λ 较大,可能会导致欠拟合,高偏差
12.3 核函数1
使用高级数的多项式模型来解决无法用直线进行分隔的分类问题:

为了获得上图所示的判定边界,我们的模型可能是 θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 1 x 2 + θ 4 x 1 2 + θ 5 x 2 2 + . . . \theta_0+\theta_1x_1+\theta_2x_2+\theta_3x_1x_2+\theta_4x_1^2+\theta_5x_2^2+... θ0+θ1x1+θ2x2+θ3x1x2+θ4x12+θ5x22+... 的形式。
我们可以用一系列的新的特征 f f f 来替换模型中的每一项: f 1 = x 1 , f 2 = x 2 , f 3 = x 1 x 2 , f 4 = x 1 2 , f 5 = x 2 2 f_1=x_1,f_2=x_2,f_3=x_1x_2,f_4=x_1^2,f_5=x_2^2 f1=x1,f2=x2,f3=x1x2,f4=x12,f5=x22
得到: h θ ( x ) = θ 0 + θ 1 f 1 + θ 2 f 2 + θ 3 f 3 + θ 4 f 4 + θ 5 f 5 h_\theta(x)=\theta_0+\theta_1f_1+\theta_2f_2+\theta_3f_3+\theta_4f_4+\theta_5f_5 hθ(x)=θ0+θ1f1+θ2f2+θ3f3+θ4f4+θ5f5
利用核函数来计算出新的特征: 给定一个训练样本 x x x,我们利用 x x x 的各个特征与我们预先选定的地标 l ( 1 ) , l ( 2 ) , l ( 3 ) l^{(1)},l^{(2)},l^{(3)} l(1),l(2),l(3) 的近似程度来选取新的特征 f 1 , f 2 , f 3 f_1,f_2,f_3 f1,f2,f3

例如: f 1 = s i m i l a r i t y ( x , l ( 1 ) ) = e ( − ∥ x − l ( 1 ) ∥ 2 2 σ 2 ) f_1=similarity(x,l^{(1)})=e(-\frac{\lVert x-l^{(1)}\rVert^2}{2\sigma^2}) f1=similarity(x,l(1))=e(−2σ2∥x−l(1)∥2),其中 ∥ x − l ( 1 ) ∥ 2 = ∑ j = 1 n ( x j − l j ( 1 ) ) 2 \lVert x-l^{(1)}\rVert^2=\sum\limits_{j=1}^n(x_j-l_j^{(1)})^2 ∥x−l(1)∥2=j=1∑n(xj−lj(1))2
地标的作用: 如果一个训练样本 x x x 与地标 l l l 之间的距离近似于0,则新特征 f f f 近似于 e 0 = 1 e^0=1 e0=1,如果训练样本 x x x 与地标 l l l 之间距离较远,则 f f f 近似于 e − ( 一个较大的数 ) = 0 e^{-(一个较大的数)}=0 e−(一个较大的数)=0
在下图中,当样本处于洋红色的点位置处,因为其离 l ( 1 ) l^{(1)} l(1) 更近,但是离 l ( 2 ) l^{(2)} l(2) 和 l ( 3 ) l^{(3)} l(3) 较远,因此 f 1 f_1 f1 接近 1 1 1,而 f 2 , f 3 f_2,f_3 f2,f3 接近 0 0 0。因此 h θ ( x ) = θ 0 + θ 1 f 1 + θ 2 f 2 + θ 3 f 3 > 0 h_\theta(x)=\theta_0+\theta_1f_1+\theta_2f_2+\theta_3f_3>0 hθ(x)=θ0+θ1f1+θ2f2+θ3f3>0,因此预测 y = 1 y=1 y=1。同理可以求出,对于离 l ( 2 ) l^{(2)} l(2) 较近的绿色点,也预测 y = 1 y=1 y=1,但是对于蓝绿色的点,因为其离三个地标都较远,故预测 y = 0 y=0 y=0。
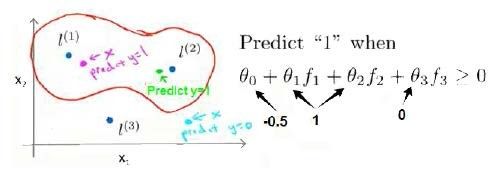
这样,图中红色的封闭曲线所表示的范围,便是我们依据一个单一的训练样本和我们选取的地标所得出的判定边界,在预测时,我们采用的特征不是训练样本本身的特征,而是通过核函数计算出的新特征 f 1 , f 2 , f 3 f_1,f_2,f_3 f1,f2,f3 。
12.4 核函数2
对于带有核函数的SVM该如何选择地标:
- 训练集: { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) } \{(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(m)},y^{(m)})\} {(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}
- 选择 l ( 1 ) = x ( 1 ) , l ( 2 ) = x ( 2 ) , . . . , l ( m ) = x ( m ) l^{(1)}=x^{(1)},l^{(2)}=x^{(2)},...,l^{(m)}=x^{(m)} l(1)=x(1),l(2)=x(2),...,l(m)=x(m)
- 计算 f f f: f 1 = s i m i l a r i t y ( x , l ( 1 ) ) , f 2 = s i m i l a r i t y ( x , l ( 2 ) ) , . . . , f m = s i m i l a r i t y ( x , l ( m ) ) f_1=similarity(x,l^{(1)}),f_2=similarity(x,l^{(2)}),...,f_m=similarity(x,l^{(m)}) f1=similarity(x,l(1)),f2=similarity(x,l(2)),...,fm=similarity(x,l(m))
- min θ C ∑ i = 1 m [ y ( i ) c o s t 1 ( θ T f ( i ) ) + ( 1 − y ( i ) ) c o s t 0 ( θ T f ( i ) ) ] + 1 2 ∑ i = 1 n θ j 2 \mathop{\min}\limits_{\theta}C\sum\limits_{i=1}^{m}[y^{(i)}cost_1(\theta^Tf^{(i)})+(1-y^{(i)})cost_0(\theta^Tf^{(i)})]+\frac{1}{2}\sum\limits_{i=1}^n\theta_j^2 θminCi=1∑m[y(i)cost1(θTf(i))+(1−y(i))cost0(θTf(i))]+21i=1∑nθj2
给定 x x x,计算新特征 f f f,当 θ T f ≥ 0 \theta^Tf\ge0 θTf≥0 时,预测 y = 1 y=1 y=1,否则反之。
下面是支持向量机的两个参数 C = 1 λ C=\frac{1}{\lambda} C=λ1 和 σ \sigma σ 的影响:
- C C C 较大时,相当于 λ \lambda λ 较小,可能会导致过拟合,高方差
- C C C 较小时,相当于 λ \lambda λ 较大,可能会导致欠拟合,高偏差
- σ \sigma σ 较大时,可能会导致低方差,高偏差
- σ \sigma σ 较小时,可能会导致低偏差,高方差
12.5 使用SVM
在高斯核函数之外我们还有其他一些选择,如:
- 多项式核函数(Polynomial Kernel)
- 字符串核函数(String kernel)
- 卡方核函数( chi-square kernel)
- 直方图交集核函数(histogram intersection kernel)
- 等等…
这些核函数的目标也都是根据训练集和地标之间的距离来构建新特征,这些核函数需要满足Mercer’s定理,才能被支持向量机的优化软件正确处理。
多类分类问题: 假设我们利用之前介绍的一对多方法来解决一个多类分类问题。如果一共有 k k k 个类,则我们需要 k k k 个模型,以及 k k k 个参数向量 θ \theta θ 。我们同样也可以训练 k k k 个支持向量机来解决多类分类问题。但是大多数支持向量机软件包都有内置的多类分类功能,我们只要直接使用即可。
尽管你不去写你自己的SVM的优化软件,但是你也需要做几件事:
- 参数 C C C 的选择
- 核函数的选择
逻辑回归 VS SVM:
n n n 表示特征数量, m m m 表示训练样本数量
- 如果 n n n 相对 m m m 很大(如: n = 10000 , m = 10 ~ 1000 n=10000,m=10~1000 n=10000,m=10~1000),使用逻辑回归或者线性核函数的SVM
- 如果 n n n 较小 m m m 中等(如: n = 1 ~ 1000 , m = 10 ~ 10000 n=1~1000,m=10~10000 n=1~1000,m=10~10000),使用高斯核函数SVM
- 如果 n n n 较小 m m m 很大(如: n = 1 ~ 1000 , m = 50000 + n=1~1000,m=50000+ n=1~1000,m=50000+),使用逻辑回归或者线性核函数的SVM
值得一提的是,神经网络在以上三种情况下都可能会有较好的表现,但是训练神经网络可能非常慢,选择支持向量机的原因主要在于它的代价函数是凸函数,不存在局部最小值。
第十三章
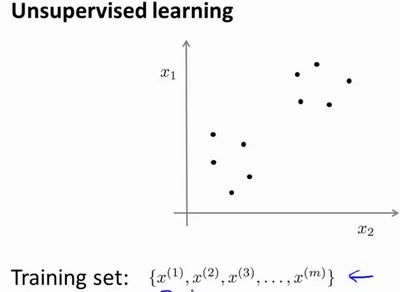
13.1 无监督学习
训练集: { x ( 1 ) , x ( 2 ) , x ( 3 ) , . . . , x ( m ) } \{x^{(1)},x^{(2)},x^{(3)},...,x^{(m)}\} {x(1),x(2),x(3),...,x(m)}
聚类算法应用: 市场分割;社交网络分析;服务器组织;天文数据分析
13.2 K-Means算法
定义: K-均值算法是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。
K均值算法:
- 输入聚类数量 K K K
- 随机初始化 K K K 个聚类中心 μ 1 , μ 2 , . . . , μ K \mu_1,\mu_2,...,\mu_K μ1,μ2,...,μK
- 簇分配:将每个点赋予离其最近的聚类中心点
- 更新簇中心:计算每类数据点的均值作为新的聚类中心
- 重复上述步骤直到收敛,即聚类结果不变
K-均值算法也可以很便利地用于将数据分为许多不同组,即使在没有非常明显区分的组群的情况下也可以。下图所示的数据集包含身高和体重两项特征构成的,利用K-均值算法将数据分为三类,用于帮助确定将要生产的T-恤衫的三种尺寸。

13.3 优化目标
K-均值的代价函数(畸变函数): J ( c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ K ) = 1 m ∑ i = 1 m ∥ X ( i ) − μ c ( i ) ∥ 2 J(c^{(1)},...,c^{(m)},\mu_1,...,\mu_K)=\frac{1}{m}\sum\limits_{i=1}^m\lVert X^{(i)}-\mu_{c^{(i)}}\rVert^2 J(c(1),...,c(m),μ1,...,μK)=m1i=1∑m∥X(i)−μc(i)∥2
- μ 1 , μ 2 , . . . , μ K \mu_1,\mu_2,...,\mu_K μ1,μ2,...,μK 表示聚类中心
- c ( i ) c^{(i)} c(i) 表示当前 x ( i ) x^{(i)} x(i) 分配给哪个类别
- μ c ( i ) \mu_{c^{(i)}} μc(i) 表示当前 x ( i ) x^{(i)} x(i) 分配给哪个聚类中心
优化目标: min c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ K J ( c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ K ) \mathop{\min}\limits_{c^{(1)},...,c^{(m)},\mu_1,...,\mu_K}J(c^{(1)},...,c^{(m)},\mu_1,...,\mu_K) c(1),...,c(m),μ1,...,μKminJ(c(1),...,c(m),μ1,...,μK)
步骤:
- 簇分配是在优化 c ( 1 ) , . . . , c ( m ) c^{(1)},...,c^{(m)} c(1),...,c(m),而保持 μ 1 , . . . , μ K \mu_1,...,\mu_K μ1,...,μK 不变
- 更新簇中心是在优化 μ 1 , . . . , μ K \mu_1,...,\mu_K μ1,...,μK,而保持 c ( 1 ) , . . . , c ( m ) c^{(1)},...,c^{(m)} c(1),...,c(m) 不变
- K-Means算法其实就是分两步 min c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ K J ( c ( 1 ) , . . . , c ( m ) , μ 1 , . . . , μ K ) = 1 m ∑ i = 1 m ∥ X ( i ) − μ c ( i ) ∥ 2 \mathop{\min}\limits_{c^{(1)},...,c^{(m)},\mu_1,...,\mu_K}J(c^{(1)},...,c^{(m)},\mu_1,...,\mu_K)=\frac{1}{m}\sum\limits_{i=1}^m\lVert X^{(i)}-\mu_{c^{(i)}}\rVert^2 c(1),...,c(m),μ1,...,μKminJ(c(1),...,c(m),μ1,...,μK)=m1i=1∑m∥X(i)−μc(i)∥2
13.4 随机初始化
随机初始化所有的聚类中心点:
- 我们应该选择 K < m K
K<m ,即聚类中心点的个数要小于所有训练集实例的数量 - 随机选择 K K K 个训练实例,然后令 K K K 个聚类中心分别与这 K K K 个训练实例相等

为了解决这个问题,我们通常需要多次运行K-均值算法,每一次都重新进行随机初始化,最后再比较多次运行K-均值的结果,选择代价函数最小的结果。这种方法在 K K K较小的时候( 2 − 10 2-10 2−10)还是可行的,但是如果 K K K较大,这么做也可能不会有明显地改善。
13.5 选取聚类数量
“肘部法则”:
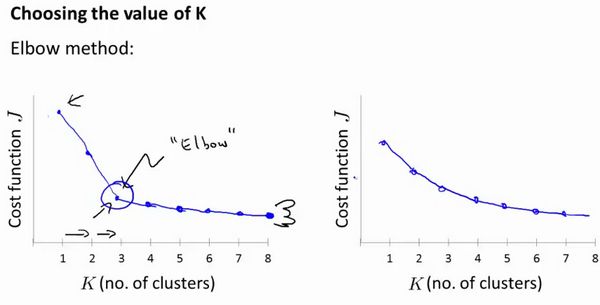
你会发现这种模式,它的畸变值会迅速下降,从1到2,从2到3之后,你会在3的时候达到一个肘点。在此之后,畸变值就下降的非常慢,看起来就像使用3个聚类来进行聚类是正确的,这是因为那个点是曲线的肘点,畸变值下降得很快, K = 3 K=3 K=3 之后就下降得很慢,那么我们就选 K = 3 K=3 K=3。当你应用“肘部法则”的时候,如果你得到了一个像上面这样的图,那么这将是一种用来选择聚类个数的合理方法。
例如,我们的 T-恤制造例子中,我们要将用户按照身材聚类,我们可以分成3个尺寸: S , M , L S,M,L S,M,L,也可以分成5个尺寸: X S , S , M , L , X L XS,S,M,L,XL XS,S,M,L,XL,这样的选择是建立在回答“聚类后我们制造的T-恤是否能较好地适合我们的客户”这个问题的基础上作出的。
第十四章
14.1 目标1:数据压缩
目的: 减少空间、算法加速
减少数据量: 如:二维到一维,三维到二维
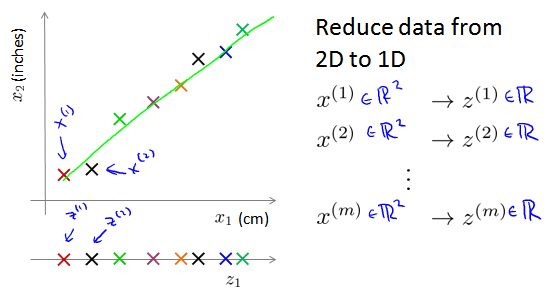
14.2 目标2:可视化
在许多及其学习问题中,如果我们能将数据可视化,我们便能寻找到一个更好的解决方案,降维可以帮助我们。
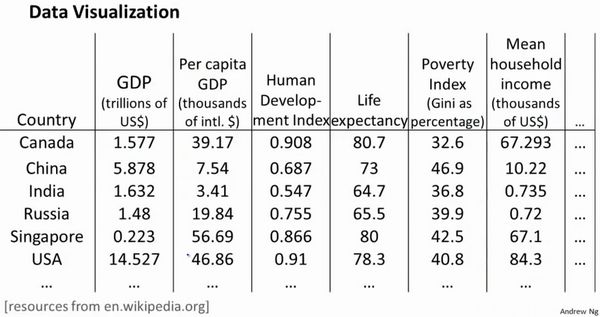
假使我们有有关于许多不同国家的数据,每一个特征向量都有50个特征(如GDP,人均GDP,平均寿命等)。如果要将这个50维的数据可视化是不可能的。使用降维的方法将其降至2维,我们便可以将其可视化了。
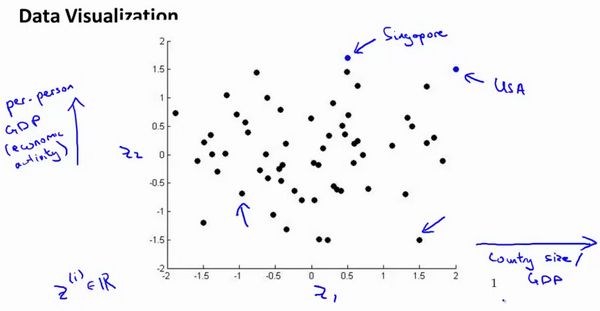
这样做的问题在于,降维的算法只负责减少维数,新产生的特征的意义就必须由我们自己去发现了。
14.3 主成分分析问题规划1
主成分分析(PCA) 是最常见的降维算法。
在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望投射平均均方误差能尽可能地小。方向向量是一个经过原点的向量,而投射误差是从特征向量向该方向向量作垂线的长度。

问题: 将 n n n 维数据降至 k k k 维
目标: 找到向量 u ( 1 ) , u ( 2 ) , . . . , u ( k ) u^{(1)},u^{(2)},...,u^{(k)} u(1),u(2),...,u(k) 使得总的投射误差最小
主成分分析与线性回归的比较:
- 主成分分析最小化的是投射误差(Projected Error),而线性回归尝试的是最小化预测误差
- 主成分分析不作任何预测,而线性回归的目的是预测结果

上图中,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影)。
14.4 主成分分析问题规划2
训练集: { x ( 1 ) , x ( 2 ) , x ( 3 ) , . . . , x ( m ) } \{x^{(1)},x^{(2)},x^{(3)},...,x^{(m)}\} {x(1),x(2),x(3),...,x(m)}
- 均值归一化: 计算 μ j = 1 m ∑ i = 1 m x j ( i ) \mu_j=\frac{1}{m}\sum\limits_{i=1}^mx_j^{(i)} μj=m1i=1∑mxj(i),然后用 x j ( i ) − μ j s j \frac{x_j^{(i)}-\mu_j}{s_j} sjxj(i)−μj 代替 x j ( i ) x_j^{(i)} xj(i),如果特征是在不同的数量级上,我们还需要将其除以标准差 σ 2 \sigma^2 σ2 。
- 计算协方差矩阵(Covariance Matrix): ∑ = 1 m ∑ i = 1 m ( x ( i ) ) ( x ( i ) ) T \sum=\frac{1}{m}\sum\limits_{i=1}^m(x^{(i)})(x^{(i)})^T ∑=m1i=1∑m(x(i))(x(i))T
- 计算协方差矩阵的特征向量(Eigenvectors):
[U, S, V] = svd(Sigma),若将数据从 n n n 维降至 k k k 维,我们只需要从 U U U 中选取前 k k k 个向量,获得一个 n × k n\times k n×k 维度的矩阵,我们用 U r e d u c e U_{reduce} Ureduce 表示,然后通过如下计算获得要求的新特征向量 z ( i ) z^{(i)} z(i): z ( i ) = U r e d u c e T ⋅ x ( i ) z^{(i)}=U_{reduce}^T\cdot x^{(i)} z(i)=UreduceT⋅x(i)
14.5 主成分数量选择
投射的平均均方误差: 1 m ∑ i = 1 m ∣ ∣ x ( i ) − x a p p r o x ( i ) ∣ ∣ 2 \frac{1}{m}\sum\limits_{i=1}^m||x^{(i)}-x_{approx}^{(i)}||^2 m1i=1∑m∣∣x(i)−xapprox(i)∣∣2
训练集的方差: 1 m ∑ i = 1 m ∣ ∣ x ( i ) ∣ ∣ 2 \frac{1}{m}\sum\limits_{i=1}^m||x^{(i)}||^2 m1i=1∑m∣∣x(i)∣∣2
我们希望在平均均方误差与训练集方差的比例尽可能小的情况下选择尽可能小的 k k k 值。
我们可以先令 k = 1 k=1 k=1,然后进行主要成分分析,获得 U r e d u c e U_{reduce} Ureduce 和 z z z,然后计算比例是否小于 1 % 1\% 1%。如果不是的话再令 k = 2 k=2 k=2,如此类推,直到找到可以使得比例小于 1 % 1\% 1% 的最小 k k k 值(原因是各个特征之间通常情况存在某种相关性)。
更好的方式来选择 k k k: [U, S, V] = svd(Sigma)

其中的 S S S 是一个 n × n n\times n n×n 的矩阵,只有对角线上有值,而其它单元都是 0 0 0,我们可以使用这个矩阵来计算平均均方误差与训练集方差的比例: 1 m ∑ i = 1 m ∣ ∣ x ( i ) − x a p p r o x ( i ) ∣ ∣ 2 1 m ∑ i = 1 m ∣ ∣ x ( i ) ∣ ∣ 2 = 1 − ∑ i = 1 k S i i ∑ i = 1 m S i i ≤ 1 % \frac{\frac{1}{m}\sum\limits_{i=1}^m||x^{(i)}-x_{approx}^{(i)}||^2}{\frac{1}{m}\sum\limits_{i=1}^m||x^{(i)}||^2}=1-\frac{\sum\limits_{i=1}^kS_{ii}}{\sum\limits_{i=1}^mS_{ii}}\le1\% m1i=1∑m∣∣x(i)∣∣2m1i=1∑m∣∣x(i)−xapprox(i)∣∣2=1−i=1∑mSiii=1∑kSii≤1%,即: ∑ i = 1 k S i i ∑ i = 1 m S i i ≥ 0.99 \frac{\sum\limits_{i=1}^kS_{ii}}{\sum\limits_{i=1}^mS_{ii}}\ge0.99 i=1∑mSiii=1∑kSii≥0.99
在压缩过数据后,我们可以采用如下方法来近似地获得原有的特征: x a p p r o x ( i ) = U r e d u c e z ( i ) x_{approx}^{(i)}=U_{reduce}z^{(i)} xapprox(i)=Ureducez(i)
14.6 压缩重现
z z z 为 1 1 1 维, x x x 为 2 2 2 维
z = U r e d u c e T x , x a p p r o x = U r e d u c e ⋅ z , x a p p r o x ≈ x z=U_{reduce}^Tx,x_{approx}=U_{reduce}\cdot z,x_{approx}\approx x z=UreduceTx,xapprox=Ureduce⋅z,xapprox≈x

14.7 应用PCA的建议
训练集: { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) } \{(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(m)},y^{(m)})\} {(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}
对输入进行PCA: { ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) } ⇒ { ( z ( 1 ) , y ( 1 ) ) , ( z ( 2 ) , y ( 2 ) ) , . . . , ( z ( m ) , y ( m ) ) } \{(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(m)},y^{(m)})\}\Rightarrow \{(z^{(1)},y^{(1)}),(z^{(2)},y^{(2)}),...,(z^{(m)},y^{(m)})\} {(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}⇒{(z(1),y(1)),(z(2),y(2)),...,(z(m),y(m))}
注意: 在训练集上进行PCA映射计算,但是该映射可以应用到验证集和测试集上。
应用PCA:
- 压缩:
- 减少占用内存
- 学习算法加速
- 可视化
- 不要用PCA去解决过拟合问题。
- 什么时候不适合使用PCA?首先使用原始的输入进行实验,如果没有得到预期效果,再考虑采用PCA。PCA毕竟是降维,还是会有信息损失!而且增加了额外的工作量。