计算机汇编语言
文章目录
- 前言
- 第一章 基础知识
-
- 1.机器语言&汇编语言
- 2.内存地址空间
-
- 2.1 主板
- 2.2 存储器芯片
- 2.3 内存地址空间
- 第二章 寄存器
-
- 1.通用寄存器
- 2.物理地址
- 3.CS:IP寄存器
- 4.DS和[address]
- 5.mov、add、sub指令
- 6.栈&栈段
- 第三章 汇编源程序
-
- 1.源程序
- 2.[BX]和loop指令
-
- 2.1 [BX]
- 2.2 loop指令
- 3.段前缀
- 4.多个段的源程序
- 第四章 定位内存地址
-
- 1.and和or指令
- 2.[BX+idata]
- 3.寻址方式
- 4.数据处理
-
- 4.1 div指令
- 4.2 伪指令dd
- 4.3 dup操作符
- 第五章 转移指令
-
- 1.offset操作符
- 2.jmp指令
-
- 2.1 位移转移
- 2.2 目的转移
- 3.jcxz指令
- 4.loop指令
- 5.ret和retf指令
- 6.call指令
- 第六章 标志寄存器
-
- 1.ZF标志
- 2.PF标志
- 3.SF标志
- 4.CF标志
- 5.OF标志
- 6.DF标志
- 第七章 内中断
-
- 1.中断向量表
- 2.中断过程
- 3.中断处理程序
- 4.单步中断
- 5.int指令
- 5.int指令
前言
本博客参考《汇编语言 第四版》王爽,因为汇编语言和具体微处理器联系,每种微处理器的汇编语言都不同,本博客针对以8086CPU为中央处理器的PC机进行学习;
汇编语言是各种CPU提供的机器指令的助记符的集合,可以通过汇编语言直接控制硬件系统进行工作;
Q:为什么说汇编语言可以直接操作硬件?那么汇编过程还有什么意义呢?
A:汇编语言利用助记符代替机器指令的操作码,用地址符号或标号代替指令或操作数的地址;
汇编语言是面向机器的语言而不是机器语言,但汇编语言的本质就是机器语言;
可以这样理解,从机器语言到汇编语言仅仅只是将英语翻译成汉语,本质上都是可以书写并识别的语言(同物种),但是从高级语言到汇编语言就是将动物写的“字”翻译成人类的字(跨物种);
汇编语言和机器语言是一一对应的:每一条汇编语言指令对应一条机器语言指令;而高级语言和低级语言是一对多的关系:C++的一条语句可以拓展成多条汇编指令或机器指令(机器语言是机器能够直接识别的指令代码,所以我们常简称机器语言为机器指令);
第一章 基础知识
1.机器语言&汇编语言
机器语言是机器指令的集合,机器指令就是一台机器可以正确执行的命令;
现在PC机中的可以执行机器指令、进行运算的芯片我们称为CPU,CPU是一种微处理器,而每一种微处理器由于其硬件设计和内部结构不同,需要使用不同的电平脉冲来控制使其工作,故每种微处理器都有属于自己的机器语言;
机器语言难以辨别和记忆,于是出现了汇编语言,汇编语言主要由以下三类指令构成:
- 汇编指令:机器码的助记符,与机器码一一对应;
- 伪指令:没有对应的机器码,由编译器而不是CPU执行;
- 其他符号:如加减运算符号等,没有对应的机器码;
汇编语言的主体和核心是汇编指令,特决定了汇编语言的特性,汇编指令和机器指令的差别在于汇编指令是机器指令便于记忆的书写格式;
2.内存地址空间
2.1 主板
每台PC机都有一个主板,主板上的核心器件和主要器件通过总线(地址总线、数据总线和控制总线)连接:
- CPU
- 存储器(这里指的是内存,也就是装在主板上的RAM)
- 外围芯片组
- 拓展插槽
- RAM内存条
- 接口卡:CPU无法直接控制外部设备,拓展插槽上的接口卡直接控制这些外部设备 —— CPU通过总线向接口卡发出命令,接口卡根据CPU的命令控制外设工作,常见的接口卡有显卡、网卡等;
2.2 存储器芯片
一台PC机上安装了多个存储器芯片:
- RAM:主要的RAM是装在主板上的RAM和插在拓展插槽上的RAM;
- 接口卡上的RAM:某些接口卡需要暂存大量的输入输出数据,典型的例子是显存(显卡上的) —— 将需要显示的内容写入显存就能出现在显示器上;
- 装有BIOS的ROM:BIOS是一类软件系统,通过它可以利用硬件设备进行最基本的输入和输出,主板和某些接口卡上都插有存储相应BIOS的ROM(主板的BIOS称为系统BIOS);
2.3 内存地址空间
上述存储器芯片在物理上是独立的器件,但CPU在操纵它们的时候都将它们统一作为内存来对待(看作一个由若干存储单元组成的逻辑存储器,这个逻辑存储器就是我们所说的内存地址空间)
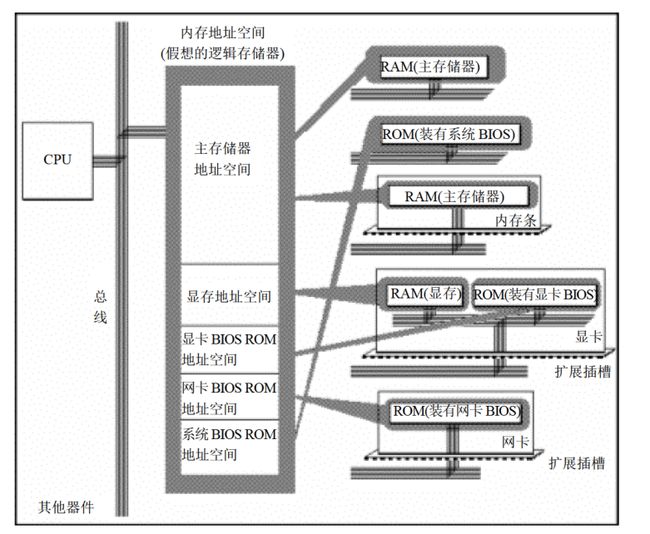
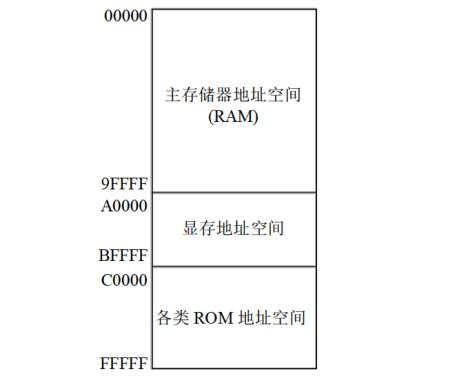
当我们基于一个计算机硬件系统编程的时候必须知道这个系统中的内存地址空间分配情况,不同计算机系统的内存地址空间的分配情况不同,如下是8086PC机内存地址空间分配情况
第二章 寄存器
一个典型的CPU以下几部分组成:
- 运算器进行信息处理;
- 寄存器进行信息存储;
- 控制器控制各个器件进行工作;
- 内部总线连接各种器件,在它们之间进行数据传送;
对于一个汇编程序员来说,CPU中的主要部件是寄存器 —— 寄存器是CPU中程序员可以用指令读写的部件,程序员通过改变各种寄存器中的内容来实现对CPU的控制;
不同的CPU其寄存器的个数、结构互不相同,8086CPU有14个寄存器,我们在之后的课程中会依次介绍;
1.通用寄存器
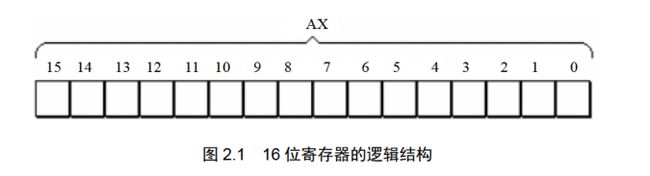
8086(以后默认情况下的8086都是指8086CPU)的所有寄存器都是16bit,可以存放两个字节;
AX、BX、CX、DX这四个寄存器通常存放一般性的数据,称为通用寄存器;
AX通用寄存器的逻辑结构如下所示:
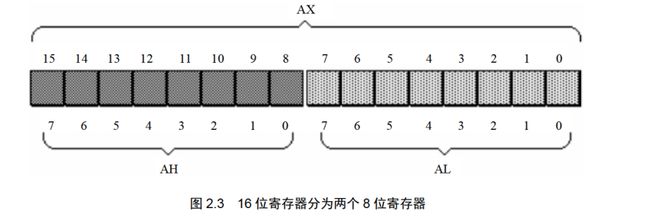
因为8086之前的寄存器都是8bit的,为了能够兼容,所以8086这四个通用寄存器都可以分为两个独立的8bit寄存器使用;
-
AX可分为AH和AL;
-
BX可分为BH和BL;
-
CX可分为CH和CL;
-
DX可分为DH和DL;
将AX分为两个8位寄存器情况如下,AX的低8位构成AL寄存器,高8位构成AH寄存器
8086可以一次性处理以下两种尺寸的数据:
- 字节:byte,1byte=8bit;
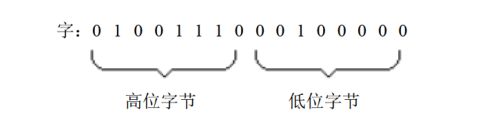
- 字:word,1word=2byte,这两个字节分别称为这个字的高位字节和低位字节(千万注意不是所有的CPU中的1word=2byte,字的大小取决于具体系统的总线宽度,16位微机8086中是1word=2byte)
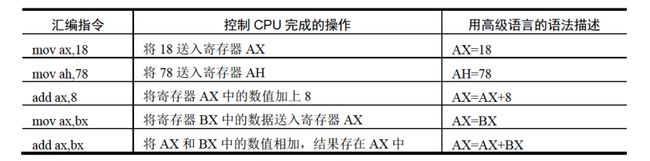
我们先简单介绍几条汇编指令以及其如何控制CPU进行工作(这里并不是指汇编指令只能控制CPU,汇编语言几乎可以直接控制、访问各种硬件设备)
2.物理地址
8086是16位机,也可以说8086是16位结构的CPU,16位结构描述了一个CPU具有下面几方面特性:
-
运算器一次最多可以处理16位的数据;
-
寄存器的最大宽度为16位;
-
寄存器和运算器之间的通路为16位;
8086有20位地址线,但8086是16位结构,如果简单的发送地址只能送16位,8086采用内部合成的方法将两个16位地址形成一个20位地址
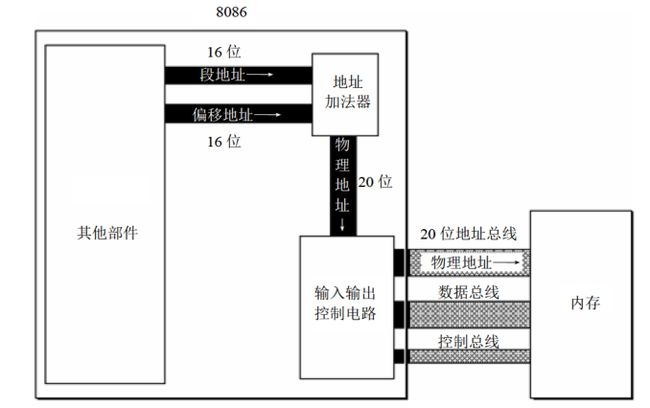
当8086CPU要读写内存时:
(1)CPU中的相关部件提供两个16位的地址,一个称为段地址,另一个称为偏移地址;
(2)段地址和偏移地址通过内部总线送入一个称为地址加法器(物理地址=段地址*16+偏移地址)的部件;
(3)地址加法器将两个16位地址合成为一个20位的物理地址;
(4)地址加法器通过内部总线将20位物理地址送入输入输出控制电路;
(5)输入输出控制电路将20位物理地址送上地址总线;
(6)20位物理地址被地址总线传送到存储器;
段地址*16的意义是左移4位二进制位
段地址中的段不是指内存被划分成一个个的段,段的划分来自于CPU,CPU使用分段的方式来管理内存
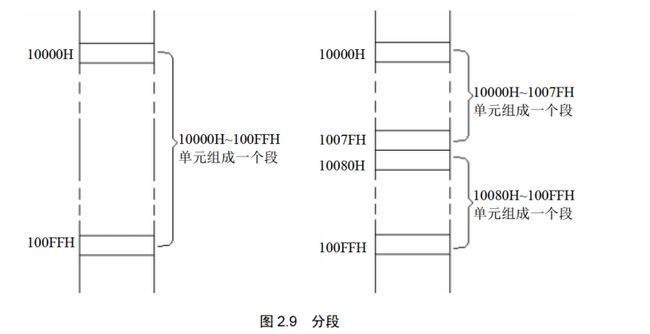
在编程中根据需要,可以将若干连续内存单元看作一个段:
- 段地址*16定位段的起始地址 —— 段的起始地址必须是16整数倍;
- 偏移地址定位段中的内存单元 —— 一个段最大长度只能是64KB(针对16位偏移地址而言);
3.CS:IP寄存器
8086在访问内存时需要由相关部件提供内存单元的段地址和偏移地址,其中段地址存放在段寄存器中,8086由CS、DS、SS和ES四个段寄存器提供段地址;
CS是代码段寄存器,IP为指令指针寄存器,CS和IP指示了CPU当前要读取指令的地址,8086CPU将从内存CS*16+IP单元开始,读取一条指令并执行 —— 即任意时刻,8086CPU将CS:IP指向的内容当作指令执行
8086工作过程简述如下:
(1)从CS:IP指向的内存单元读取指令,读取的指令进入指令缓冲器;
(2)IP=IP+所读取指令的长度,从而指向下一条指令;
(3)执行指令。转到步骤(1),重复这个过程;
8086CPU加电启动或复位后,CS和IP被初始化为CS=FFFFH,IP=0000H,即CPU从内存FFFF0H单元中读取指令并执行;
8086大部分寄存器的值可以使用mov指令来修改,mov指令称为传送指令;但是要改变CS、IP内容的指令被统称为转移指令,显然mov不可行,我们这里介绍一个简单的转移指令:jmp;
“jmp 段地址:偏移地址”指令的功能为:用指令中的段地址和偏移地址修改CS和IP中的值;
“jmp 某合法寄存器”指令的功能为:用寄存器中的值修改IP中的值;
代码段的定义:当我们将一组内存单元定义为一个段且将一段代码存放在该段中,我们称其为代码段,如何使得代码段中的指令被执行呢?只需要将这段代码的首地址传输给CS:IP指向即可;
数据段的定义:同理,我们可以将一组连续的内存单元当作专门存储数据的内存空间,从而定义了一个数据段,访问数据段时,只需要用DS存放数据段的段地址,再根据相关指令访问数据段中的具体单元即可;
注意:汇编源程序中,数据不能以字母开头,需要在前面加0,如9138H可以直接写为“9138H”,但是A000H在汇编源程序中只能写成“0A000H”
4.DS和[address]
字单元简单来说就是存放一个字型数据(16bit)的内存单元,由两个地址连续的内存单元组成,字的低位字节存放在低地址单元中,高位字节存放在高地址单元中,之后我们会将起始地址为N的字单元简称为N地址字单元;
DS寄存器用于存放要访问的数据的段地址,指令中的“[]”说明操作对象是一个内存单元,该内存单元=DS中的段地址+[]中的偏移地址;
mov指令访问内存单元时,可以只在mov指令中给出单元的偏移地址,此时段地址默认在DS寄存器中;
push、pop指令中可以只给出偏移地址,段地址会在指令执行时CPU自动从DS取得;
[address]表示一个偏移地址为address的内存单元;
5.mov、add、sub指令
mov、add、sub指令都有两个操作对象,mov指令可以有如下形式:

注意,在8086中随意向一段内存空间写入内容是很危险的(不只是针对8086,应该养成良好的编程习惯),在不确定一段内存空间中是否存放重要的数据或代码的时候不能随意向其中写入内容;
—注意了,很多人肯定会疑惑,我们编程的时候也没注意这么多啊?那是因为我们之前的编程一直都是在操作系统中安全、规矩的编程,使用的是操作系统分配给我们的空间;但是当我们需要直接对硬件进行编程可就是自由、直接地用汇编语言去操作真实的硬件,稍微有差错都会导致死机等(但事实上在现在的Windows上不理会操作系统直接使用汇编语言操作硬件是不可能的,硬件已经被操作系统完全保护起来了)
在操作系统的环境中,合法地通过操作系统取得的空间都是安全的,在操作系统允许的情况下,程序可以取得任意容量的空间;
add和sub可以有如下几种形式:

6.栈&栈段
栈是一种具有特殊访问方式的存储空间 —— 最后进入这个空间的数据最先出去;
如今的CPU都有栈机制,8086提供相应的指令以栈的方式访问内存空间,也就是说基于8086编程时可以将一段内存当作栈来使用;
push ax;将寄存器ax中的数据送入栈中
pop ax;从栈顶取出数据送入ax
8086的入栈和出栈操作都是以字为单位进行;
关于CPU如何知道栈顶的位置,有相应的寄存器来存放栈顶的地址 —— 段寄存器SS和寄存器SP,栈顶的段地址存放在SS中,偏移地址存放在SP中;
任意时刻,SS:SP指向栈顶元素;
从下图我们可以看出,入栈时,8086的栈顶从高地址向低地址方向增长;
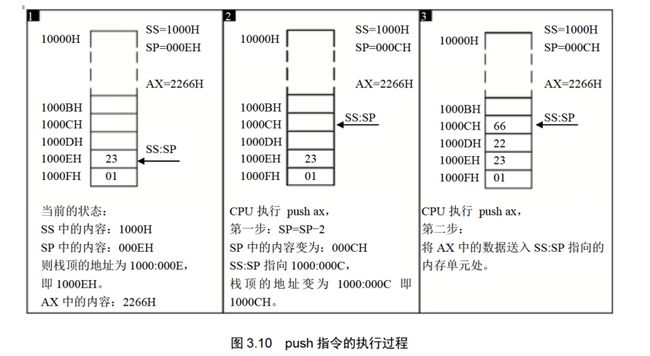
同样的pop操作与push操作刚好相反
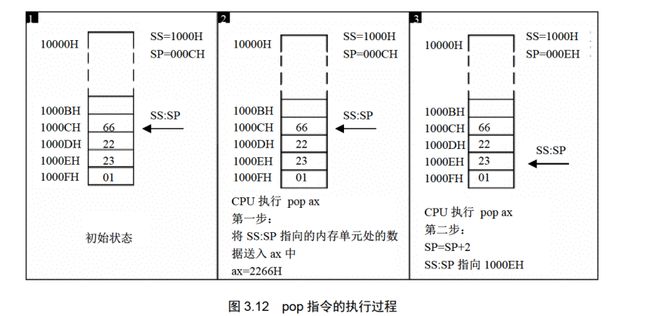
注意,出栈后,SS:SP指向新的栈顶,但是2266H实际还是存在,但是此时它不属于栈,再次执行push操作的时候这个数据将会被覆盖;
pop和push实质上都是内存传送指令,可以在寄存器和内存之间传送数据;
pop和push指令与mov指令不同之处在于push/pop访问的内存单元地址不是在指令中给出,而是由SS:SP指出,且push和pop还会改变SP中的内容;
当栈满的时候使用push指令入栈或者栈空的时候使用pop指令出栈都会发生栈顶超界的问题,这是很危险的事(一般来说栈内和栈外的数据不属于同一个程序,这就会导致其他程序的数据被修改)
当然8086并没有做出对此的解决方法,这就需要我们自己在编程的时候避免出现栈顶超界的问题;
仿照前面的定义,可以将长度为N(N<=64KB)的一组连续地址且起始地址为16倍数的内存单元定义为一个段,我们将这个段作为栈空间来使用从而定义了一个栈段(类比代码段、数据段),以栈的方式进行访问;
当然人为定义的栈段CPU是并不知道的,需要使用SS:SP指向我们定义的栈段,这样就可以使得push、pop等栈操作指定访问我们定义的栈段;
段总结

一段内存,可以既是代码的存储空间又是数据的存储空间还可以是栈空间,也可以什么都不是,关键在于CPU中寄存器的设置(即CS IP SS SP DS的指向)
第三章 汇编源程序
汇编源程序是后缀名为.asm的文件,需要经过编译器编译成.exe或者.com文件才能执行,本章我们主要介绍一个完整的汇编源程序的框架;
1.源程序
assume cs:codesg
codesg segment
mov ax,0123H
mov bx,0456H
add ax,bx
add ax,ax
mov ax,4c00H
int 21H
codesg ends
end
汇编语言程序中主要包含两种指令,一种是汇编指令,另一种是伪指令:
- 汇编指令编译为机器代码最终被CPU执行;
- 伪指令没有对应的机器指令,编译器根据伪指令进行相关的编译工作
我们很容易看出来上述代码中出现的伪指令:
(1)segment和ends是一对成对使用的伪指令,功能是定义一个段,该段的名称需要标识,具体使用格式如下
段名 segment
...
段名 ends
一个汇编程序是由多个段组成的,这些段被用来存放代码、数据或者当作栈空间使用:一个源程序中所有会被计算机处理的信息:指令、数据、栈都被划分到了不同的段中;
一个有意义的汇编程序至少要有一个代码段用于存放代码;
(2)end是一个汇编程序结束的标记,编译器碰到了伪指令end则结束对源程序的编译;
(3)assume的功能是假设某段寄存器和程序中的某一个segment…ends定义的段相关联,如上面的代码中我们使用assume cs:codesg将用作代码段的codesg段和CPU中的段寄存器cs关联
在汇编语言中,将源程序文件中所有的内容称为源程序,将源程序中最终由计算机执行、处理的指令或数据称为程序;
源程序经过编译、连接后成为机器码,存储在可执行文件(可执行文件由描述信息和程序组成,程序源自源程序中的汇编指令和定义的数据,描述信息主要是编译、连接程序对源程序中相关伪指令进行处理得到的信息)中,故我们现在讨论可执行文件的执行机制;
一个程序P2在可执行文件中,则必须有一个正在运行的程序P1,将P2从可执行文件中加载入内存后,将CPU的控制权交给P2,P2才能得以运行。P2开始运行后,Pl暂停运行。
而当P2运行完毕后,应该将CPU的控制权交还给使它得以运行的程序P1,此后,P1继续运行。
现在,我们知道,一个程序结束后,将CPU的控制权交还给使它得以运行的程序,我们称这个过程为:程序返回。那么,如何返回呢?应该在程序的末尾添加返回的程序段(我们会在后面详细介绍)。
2.[BX]和loop指令
之后的课程中我们为了方便描述,使用"()"表示一个寄存器或一个内存单元(当然是物理地址)中的内容,(ax)表示ax中的内容,(al)表示al中的内容,(20000H)表示内存20000H单元中内容;
"()"中的元素可以有3种类型:
- 寄存器名
- 段寄存器名
- 内存单元的物理地址(20bit数据)
"(X)"表示的数据有两种类型:
- 字节
- 字
具体类型由寄存器名或具体的运算决定
还需要补充的是,之后我们使用idata表示常量,带有idata的指令都是非法指令只能用于我们学习,比如mov ds,idata表示mov ds,1,mov ds,2等
2.1 [BX]
我们知道,要完整描述一个内存单元需要两个信息:
- 内存单元的地址;
- 内存单元的长度;
[BX]类似于[0],我们知道用[0]表示内存单元时,其偏移地址是0,段地址默认在DS中,单元的长度可由具体的指令中的其他操作对象(寄存器)指出;
[BX]表示一个内存单元,其偏移地址在BX中;
2.2 loop指令
loop指令顾名思义与循环相关,其格式如下
loop 标号
通常情况下,我们使用loop指令实现循环功能,在cx寄存器中存放循环次数
CPU执行loop指令的时候进行如下两步操作:
- (cx)=(cx)-1
- 判断cx中的值,若不为0则转至标号处执行程序,若为0则向下执行
下面我们给出一段源程序以计算212
assume cs:code
code segment
mov ax,2
mov cx,11
s:add ax,ax
loop s
mov ax,4c00H
int 21H
code ends
end
首先是标号s,汇编程序的标号代表一个地址,该地址存在一条指令:add ax,ax(当然这里的指令代码是我们自己编写的)
当在循环过程中,偏移地址需要递增的时候,表示内存单元偏移地址的X应该是一个变量 —— 我们可以将偏移地址放在BX中,用[BX]的方式访问内存单元,在循环开始之前设(BX)=0,每次循环将BX中的值加1即可
3.段前缀
指令“mov ax,[bx]”中,内存单元的偏移地址由bx给出,而段地址默认在ds中。我们可以在访问内存单元的指令中显式地给出内存单元的段地址所在的段寄存器
mov ax,ds:[bx] ;将内存单元中内容送入ax,这个内存单元长度为2字节,偏移地址在bx中,段地址在ds中
mov ax,cs:[bx] ;偏移地址在bx中,段地址在cs中
诸如上述出现在访问内存单元的指令中且显式指明内存单元的段地址的"ds:""cs:"称为段前缀
4.多个段的源程序
assume cs:code
code segment
dw 0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H ;定义字型数据,define word,此处定义了8个字型数据,每个数据占用两字节
mov bx,0
mov ax,0
mov cx,8
s:add ax,cs:[bx]
add bx,2
loop s
mov ax,4c00H
int 21H
code ends
end
;汇编程序不需要使用分号表示一条语句的结束,汇编程序中的注释以分号开头
这个代码段存在一个问题就是将数据和代码等全部塞在一个代码段中,这就导致这个程序只有一个代码段,在该代码段中前面16个字节是使用dw定义的字型数据,从第16个字节开始才是汇编指令对应的机器码;
这样的问题就是我们只能使用debug来执行程序,因为程序的入口处不是我们希望执行的指令,我们可以直接在源程序中指明程序的入口所在
assume cs:code
code segment
dw 0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H
start:
mov bx,0
mov ax,0
mov cx,8
s:add ax,cs:[bx]
add bx,2
loop s
mov ax,4c00H
int 21H
code ends
end start
;start这个标号在程序的第一条指令前面出现,接着在end后出现
;end除了通知编译器程序结束,还可以通知编译器程序的入口在什么地方
接下来我们开始使用栈,下面的代码用于解决利用栈将程序中定义的数据逆序存放
assume cs:code
code segment
dw 0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ;定义16个字型数据,程序加载后将取得这16个字的内存空间用于存放这16个数据,在后面的程序中可以将这段空间作为栈使用(16应该是为了避免溢出)-可以说是开辟空间
start:
mov ax,cs
mov ss,ax
mov sp,30H ;设置cs:10~cs:2F的内存空间作为栈来使用,初始状态下栈为空故ss:sp指向栈底cs:30
mov bx,0
mov cx,8
s: push cs:[bx]
add bx,2
loop s ;将以上代码段0~15单元中的8个字型数据依次入栈
mov bx,0
mov cx,8
s0: pop cs:[bx]
add bx,2
loop s0 ;将以上8个字型数据依次出栈
mov ax,4c00H
int 21H
code ends
end start
把数据、代码、栈放在一个段中会出现以下问题:
- 一个段中显得程序很混乱;
- 一个段不能超过64KB,如果光是数据大小都超过64KB则不允许(当然这只是8086的限制)
下面这个程序实现了和上述程序相同的功能,但是它将数据、栈和代码放在了不同的段中
assume cs:code,ds:data,ss:stack ;对于不同的段,要有不同的段名,当然assume只是伪指令,CPU并不能根据assume的绑定知道code data stack分别是什么段,也就不知道该如何处理
data segment
dw 0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H
data ends
stack segment
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0 ;定义16个字型数据,程序加载后将取得这16个字的内存空间用于存放这16个数据,在后面的程序中可以将这段空间作为栈使用(16应该是为了避免溢出)-可以说是开辟空间
stack ends
code segment
start:
mov ax,stack
mov ss,ax ;设置ss指向stack
mov sp,20H ;设置栈顶ss:sp指向stack:20
;CPU执行上述指令后将把stack段作为栈空间使用
mov ax,data ;将名称为data段的段地址送入ax
mov ds,ax ;ds指向data段
mov bx,0 ;ds:bx指向data段中第一个单元
mov cx,8
s: push [bx]
add bx,2
loop s ;将以上代码段0~15单元中的8个字型数据依次入栈
mov bx,0
mov cx,8
s0: pop [bx]
add bx,2
loop s0 ;将以上8个字型数据依次出栈
mov ax,4c00H
int 21H
code ends
end start
多个段的情况下如何访问段中的数据呢?还是和以前一样通过地址,地址分为两部分:段地址和偏移地址 —— 程序中段名相当于一个标号,代表了段地址,偏移地址则需要看段中数据在段中的位置
;将程序中的data段中的数据0abcH(地址为data:6)送入bx中
mov ax,data
mov ds,ax
mov bx,ds:[6]
;注意不可以使用这样的指令
mov ds,data ;不能直接把一个数值送入段寄存器中,此处的data在编译的时候是会被处理成为一个表示段地址的数值(这个概念在书上前面应该已经讲过了,但是那个时候没有引起重视,但是毕竟是初学所以没必要严格要求每个概念点一字不差的记录下来,对于一些忽略的自行Google也可以)
mov bx,ds:[6]
我们只能通过以下方式将数据加载到段寄存器中:首先将数据加载到通用寄存器中,然后将其从通用寄存器移到段寄存器中;
大胆猜测一下不能这么做的原因在于工程师根本没有创建一条可以将信号从存储器I/O数据线馈送到段寄存器的电路路径
第四章 定位内存地址
之所以需要专门介绍寻址方式,是因为合理的使用寻址方式可以设计更合理的结构来看待我们需要处理的数据,而为需要处理的数据设计一种清晰的数据结构是程序设计的一个关键问题;
1.and和or指令
and指令:逻辑与指令,按位进行与运算
mov al,01100011B
and al,00111011B
;执行过后al=00100011B
or指令:逻辑或指令,按位进行或运算
mov al,01100011B
or al,00111011B
;执行过后al=01111011B
2.[BX+idata]
前面已经介绍过,使用[BX]指明一个内存单元,这里我们给出一种更加灵活的方式指明内存单元:[BX+idata],表示该内存单元的偏移地址为(BX)+idata;
之所以介绍这种表示内存单元的方式,是为了引出数组这一数据结构;
假设此时datasg段中有两个字符串,一个起始地址为0,另一个起始地址为5,我们可以将这两个字符串看作两个数组,一个从0地址开始存放另一个从5开始存放,我们可以使用[0+BX]和[5+BX]的方式在同一个循环中定位这两个字符串中的字符;
3.寻址方式
SI和DI是8086中与BX功能相近的寄存器,但是SI和DI不能分成两个8位寄存器来使用;
引入这两个寄存器之后我们可以使用更加灵活的方式来指明一个内存单元:[BX+SI]或[BX+DI],以前者为例,[BX+SI]表示一个内存单元,其偏移地址为(BX)+(SI);
我们甚至还可以这样表示一个内存单元:[BX+SI+idata],其偏移地址为(BX)+(SI)+idata;
我们这里总结前面介绍过的几种定位内存地址的方法(即寻址方式)

下面我们讨论一个问题,程序中需要经常进行数据的暂存,这些数据可能是在寄存器中的,也可能是在内存中的,但是使用寄存器一定不是一个好的方法(因为寄存器的数量是有限的),所以此时就只能选择内存(将需要暂存的数据放在内存单元中,需要使用的时候从内存单元中恢复),however,在保存多个数据的时候我们需要记住数据保存在了哪个单元中,非常麻烦;
综上,我们需要使用内存来暂存数据,且需要使用栈结构使程序结构清晰
当数据存放在内存中的时候,我们称定位内存单元的方法为寻址,前面已经介绍过不少寻址方式,我们这里做一个总结
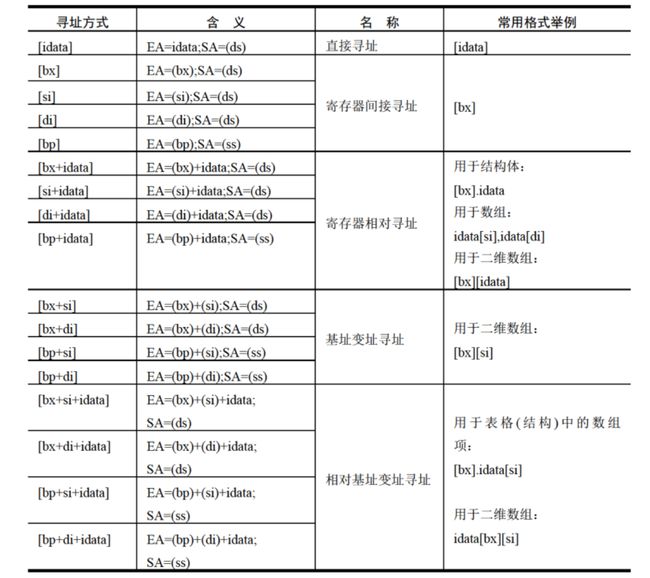
4.数据处理
首先我们定义描述性的符号:reg和sreg,其中reg表示一个寄存器,sreg表示一个段寄存器

-
8086中只有BX、SI、DI和BP可以用在[…]中进行内存单元的寻址,这四个寄存器可以单独出现,也可以以四种组合出现:
- BX+SI
- BX+DI
- BP+SI
- BP+DI:只要在[…]中包含寄存器BP但没有显式给出段地址,则段地址默认在SS中
-
8086中绝大部分的机器指令都是进行
数据处理的指令,数据处理大致可以分为三类:读取、写入和运算;机器指令并不会关心数据的值是多少,只关心指令执行的前一刻它将要处理的数据所在的位置,可能在如下三个地方:CPU内部、内存和端口; -
上面已经说到数据可能所在的位置,那8086如何表示数据所在的这些位置?主要有三种表示方法:
- 立即数:对于直接包含在机器指令中的数据称为立即数,在汇编指令中直接给出这些立即数即可
mov ax,1 add bx,2000H- 寄存器:指令要处理的数据在寄存器中,因此在汇编指令中我们需要给出相应的寄存器的名称
mov ax,bx mov ds,ax- 段地址(SA)和偏移地址(EA):指令要处理的数据在内存中,在汇编指令中使用我们前面介绍过的方式给出EA和SA在某个段寄存器中
;存放段地址的寄存器可以是默认的 mov ax,[0] ;段地址默认在DS中 mov ax,[bp];段地址默认在SS中 ;当然存放段地址的寄存器可以是显式给出的 mov ax,ds:[bp] ;SA=ds,EA=bp mov ax,cs:[BX+SI+8] ;SA=CS,EA=BX+SI+8
前面说过8086的指令可以处理两种尺寸的数据 —— byte和word,因此我们需要在机器指令中指明指令进行的是字操作还是字节操作
主要有两种方法可以进行判别:
- 根据寄存器名进行处理,ax表示十六位字操作,al表示八位字节操作;
mov ax,1
mov al,1
- 当然寄存器名并不是万能的,很多机器指令并不存在寄存器名,这种情况下使用操作符X ptr指明内存单元的长度,此处X在汇编语言中可以是word或byte
mov word ptr ds:[0],1 ;word ptr指明指令访问的内存单元是一个字单元
mov byte ptr ds:[0],1 ;byte ptr指明指令访问的内存单元是一个字节单元
不要觉得显式指定需要访问的内存单元的长度很鸡肋(至少我们在前面一直都没有提过这个问题),这很可能导致某些指令进行内存单元的修改的时候处理一个或两个单元的内容
- 当然还有些指令只能进行字操作或字节操作,push只能进行字操作
4.1 div指令
div是除法指令,使用的时候需要注意:
- 除数:分8bit和16bit两种,在一个reg寄存器或内存单元中
- 被除数:默认放在AX或DX和AX中:
- 除数8bit,被除数16bit,默认在AX中存放;
- 除数为16bit,被除数为32bit,在DX和AX中存放,DX存放高16bit,AX存放低16bit;
- 商:
- 除数为8bit,AL存储除法操作的商,AH存储除法操作的余数;
- 除数为16bit,AX存储除法操作的商,DX存储出发操作的余数;
div byte ptr ds:[0]
;意味着(al)=(ax)/((ds)*16+0)的商
;(ah)=(ax)/((ds)*16+0)的余数
4.2 伪指令dd
前面我们分别使用db和dw来定义字节型数据和字型数据,而dd用来定义dword双字型数据,也就是占用两个字的数据
4.3 dup操作符
dup与dd dw db同样是被编译器处理的符号,主要用于配合数据定义伪指令实现数据重复
db 3 dup(0)
;定义3个字节,值都是0,相当于db 0,0,0
db 3 dup(0,1,2)
;定义9个字节,相当于db 0,1,2,0,1,2,0,1,2
可见dup的指令格式如下
db 重复次数 dup(需要重复的字节型数据)
dw 重复次数 dup(需要重复的字数据)
dd 重复次数 dup(需要重复的双字数据)
第五章 转移指令
前面介绍的mov等大部分指令都是传送指令,我们定义可以修改IP或可以同时修改CS和IP的指令统称为转移指令,即转移指令是可以控制CPU执行内存中某处代码的指令;
8086的转移行为有以下几类:
- 只修改IP,称为段内转移,如jmp ax;根据转移指令对IP
- 短转移IP的修改范围-128~127
- 近转移IP的修改范围-32768~32767
- 同时修改CS和IP,称为段间转移,如jmp 1000:0;
8086转移指令主要分为以下几类:
-
无条件转移指令
-
条件转移指令
-
循环指令
-
过程
-
中断
这些转移指令转移前提可能不同,但转移的基本原理相同,这里主要通过学习无条件转移指令jmp来理解CPU执行转移指令的基本原理
1.offset操作符
offset的功能是取得标号的偏移地址
assume cs:codesg
codesg segment
start:mov ax,offset start ;等同于mov ax,0,start是代码段中的标号,标记的指令是代码段中的第一条指令,偏移地址为0
s:mov ax,offset s;等同于mov ax,3,s标记的指令是代码段中第二条指令,因为第一条指令长度为3字节,则s偏移地址为3
2.jmp指令
无条件转移指令,可以只修改IP,也可以同时修改CS和IP
jmp指令需要的给出两种信息:
-
转移的目的地址
-
转移的距离
不同的信息对应了不同的jmp指令格式
2.1 位移转移
jmp short 标号
实现段内短转移,指令中的short符号说明指令进行的是短转移,标号是指代码段中的标号,指明了指令要转移的目的地 —— 转移指令结束后,CS:IP应当指向标号处的指令
assume cs:codesg
codesg segment
start:mov ax,0
jmp short s ;执行该指令过后,跳过了add ax,1,执行s处的指令,因此最终ax的值为1而不是2
add ax,1
s:inc ax
codesg ends
ens start
CPU在执行jmp指令的时候并不需要转移的目的地址,这就意味着CPU不需要目的地址就可以实现对IP的修改
转移指令并没有告诉CPU要转移的目的地址,却告诉了CPU要转移的位移(比如“将当前的IP向后移动3个字节”)

2.2 目的转移
前面的jmp指令其对应的机器指令中并没有转移的目的地址,仅是相对于当前IP的转移位移
jmp far ptr 标号
;(CS)=标号所在段的段地址
;(IP)=标号在段中的偏移地址
;far ptr指明了该指令使用标号的段地址和偏移地址来修改CS和IP
;功能:这条指令实现的是段间转移,又称为远转移,转移的目的地址在指令中
jmp 16位reg
;功能:(IP)=(16位reg),表明转移地址在寄存器中
下面我们再介绍两种格式的转移地址在内存中的jmp指令
第一种是段内转移
jmp word ptr 内存单元地址
;功能:从内存单元地址处存放一个字,存放的是转移的目的偏移地址
内存单元地址可以使用任一寻址方式给出
mov ax,0123H
mov ds:[0],ax
jmp word ptr ds:[0]
;执行后的(IP)=0123H
第二种是段间转移
jmp dword ptr 内存单元地址
;功能:从内存单元地址处存放两个字,高地址的字是转移目的段地址,低地址的字是转移目的偏移地址
;(CS)=(内存单元地址+2)
;(IP)=(内存单元地址)
内存单元地址可以用寻址方式的任一格式给出
mov ax,0123H
mov ds:[0],ax
mov word ptr ds:[2],0
jmp dword ptr ds:[0]
;执行过后(CS)=0,(IP)=0123H,CS:IP指向0000:0123
3.jcxz指令
jcxz指令是有条件转移指令,所有的有条件转移指令都是短转移,在对应的机器码中包含转移的位移而不是目的地址,且对IP的修改范围都是-128~127
jcxz 标号
;功能:若(CX)=0则转移到标号处执行操作,若(CX)!=0则怎么也不做,程序向下执行
;操作:当(CX)=0时,(IP)=(IP)+8bit位移
上述8bit位移计算方法为

4.loop指令
loop指令为循环指令,所有的循环指令都是短转移,在对应的机器码中包含转移的位移而不是目的地址,对IP的修改范围为-128~127
loop 标号
;功能:首先计算(CX)=(CX)-1,如果(CX)!=0则(IP)=(IP)+8位位移,如果(CX)=0则什么也不做,程序向下执行
上述8bit位移计算方法为

5.ret和retf指令
ret指令使用栈中的数据修改IP中的内容,实现近转移;
retf指令使用栈中的数据修改CS和IP中的内容,实现远转移;
简单来说CPU执行ret指令的时候相当于进行pop IP,CPU执行retf指令时相当于进行pop IP pop CS
6.call指令
call指令不能实现短转移,除此之外,call指令实现转移的方法和jmp指令原理几乎完全相同;
CPU执行call指令的时候进行两步操作:
- 将当前的IP或CS和IP压栈;
- 转移;
因为我们这里是速刷汇编语言,所以针对这种指令的具体用法我们就暂且不再细讲,需要的时候自行Google或看书;还有就是一些不是很重要的指令比如mul之类的我们也省略不讲(因为已经汇编语言已经差不多接触两天了,不能再耗费更多的时间在上面了)
第六章 标志寄存器
CPU内部的寄存器中存在一种特殊的寄存器,一般来说有以下作用:
- 存储相关指令的某些执行结果;
- 为CPU执行相关指令提供行为依据;
- 控制CPU的相关工作方式;
这样的特殊寄存器在8086中被称为标志寄存器,8086中的标志寄存器有16位,其中存储的信息通常被称为程序状态字PSW;
我们简称8086中的标志寄存器为flag,flag和其他寄存器不一样,其他寄存器是使用整个寄存器来存放数据的,而flag寄存器按位起作用,也就是说flag寄存器的每一位都有特殊的含义、记录特定的信息;
8086中的flag寄存器结构如图

其中的1、3、5、12、13、14、15在8086中并没有使用,不具备任何含义;
1.ZF标志
flag的第六位ZF零标志位,记录相关指令执行后其结果是否为0:
- 结果为0则ZF=1;
- 结果不为0则ZF=0;
2.PF标志
flag的第二位是PF奇偶标志位,记录相关指令执行后其结果中的所有bit位中的1的个数是否为偶数:
- 如果1的个数为偶数则PF=1;
- 如果为奇数则PF=0;
3.SF标志
flag的第七位是SF符号标志位,记录相关指令执行后其结果是否为负:
- 结果为负则SF=1;
- 结果非负则SF=0;
SF标志就是CPU对有符号数运算结果的一种记录,它记录数据的正负:
- 将数据作为有符号数来运算的时候通过SF标志得知结果的正负;
- 将数据作为无符号数来运算的时候SF的值没有意义;
4.CF标志
flag的第零位是CF进位标志位,在进行无符号数运算的时候,它记录了运算结果的最高有效位向更高位的进位值,或者从更高位的错位值;
对于位数为N的无符号数来说,其对应的二进制信息的最高位(N-1)就是它的最高有效位
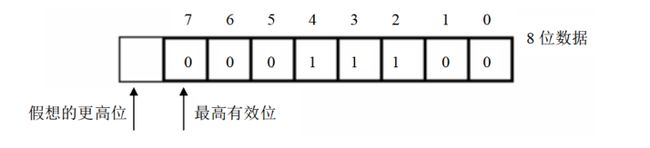
5.OF标志
在进行有符号数运算的时候,如果结果超过了机器所能表示的范围则称为溢出,那么运算的结果将会不正确,CPU需要对指令执行后是否产生溢出进行记录;
flag的第十一位是OF溢出标志位,OF记录了有符号数的运算结果是否发生了溢出:
- 发生溢出则OF=1;
- 未发生溢出则OF=0;
CF是对无符号数运算有意义的标志位,OF是对有符号数运算有意义的标志位(虽然我也不知道为什么把无符号数和进位绑定,把有符号数和溢出绑定)
6.DF标志
flag的第十位是DF方向标志位,在串处理指令中控制每次操作后SI和DI的增减:
- DF=0则每次操作后SI和DI递增;
- DF=1则每次操作后SI和DI递减;
第七章 内中断
中断信息可以来自CPU的内部和外部,这一章我们主要讨论来自CPU内部的中断信息;
关于内中断和外中断我们在操作系统计算机操作系统 - Tintoki_blog (gintoki-jpg.github.io)或计算机组成原理计组期末复习笔记 - Tintoki_blog (gintoki-jpg.github.io)中有详细介绍,此处不再赘述;
对于8086,当CPU内部出现如下情况将产生相应的中断信息:
- 除法错误(除法溢出等)
- 单步执行;
- 执行into指令;
- 执行int指令;
要对这四种不同类型的信息进行处理,8086需要先知道接收到的中断信息的来源,因此中断信息中需要包含识别来源的编码——称为中断类型码,是一个字节型数据,可以表示256种中断信息的来源,上面介绍的四种中断源在8086中的中断类型码如下:
- 除法错误:0
- 单步执行:1
- into指令:4
- int指令:该指令的格式为
int n,指令中的n为字节型立即数,是提供给CPU的中断类型码;
由我们编程写的用于处理中断信息的程序被称为中断处理程序,CPU收到中断信息后需要转去执行中断处理程序,这就引出我们应该如何根据中断信息确定其处理程序的入口;
前面介绍的中断信息中的包含有标识中断源的中断类型码,其作用就是定位中断处理程序 —— 要定位中断处理程序就需要知道它的段地址和偏移地址,如何根据8位中断类型码得到中断处理程序的段地址和偏移地址呢?
1.中断向量表
CPU使用8位中断类型码,通过中断向量表找到相应的中断处理程序的入口地址;
中断向量表就是中断向量的列表,中断向量就是中断处理程序的入口地址 —— 简单来说中断向量表就是中断处理程序入口地址的列表;
中断向量表保存在内存中,存放了256个中断源对应的中断程序的入口(事实上系统要处理的中断事件远没有达到256个,中断向量表中很多单元是空的),CPU只需要将中断类型码作为中断向量表的表项号定位相应的表项,就可以得到中断处理程序的入口地址;
中断向量表中的一个表项存放一个中断向量,这个中断向量包括入口地址的段地址和偏移地址,故一个表项占两个字:高地址字存放段地址,低地址字存放偏移地址;
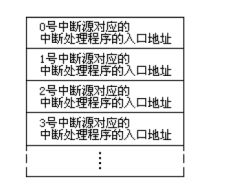
那么下面的问题就是CPU如何找到中断向量表 —— 对于8086来说中断向量表被指定放在内存地址0处,内存0000:0000到0000:03FF这1024个单元中存放中断向量(一般情况下0000:0200到0000:02FF的256个字节的空间对应的中断向量表表项都是空的);
2.中断过程
CPU通过中断类型码找到中断处理程序的入口,将CS:IP设置为该入口地址 —— 这个过程由CPU硬件自动完成,被称为中断过程;
CPU收到中断信息后,首先引发中断过程,CS:IP指向中断处理程序的入口之后,CPU开始执行中断处理程序;
8086收到中断信息后引发的中断过程如下:
(1)(从中断信息中)取得中断类型码;
(2)标志寄存器的值入栈(因为在中断过程中要改变标志寄存器的值,所以先将其保存在栈中);(这一步书上说的就是标志寄存器 ,但是CS和IP的值理论上也是需要保存的-4、5步骤就是保存CS和IP的值便于CPU回头继续执行被中断的程序)
(3)设置标志寄存器的第8位TF和第9位IF的值为0(这一步的目的后面将介绍);
(4)CS的内容入栈;
(5)IP的内容入栈;
(6)从内存地址为中断类型码(* 4)和中断类型码(* 4+2)的两个字单元中读取中断处理程序的入口地址设置IP和CS;
3.中断处理程序
中断处理程序的常规编写步骤如下:
- 保存用到的寄存器;
- 处理中断;
- 恢复用到的寄存器;
- 使用iret指令返回:iret指令通常和硬件实现的中断过程配合使用,中断过程中寄存器入栈的顺序为标志寄存器、CS、IP,iret指令的出栈顺序是IP、CS、标志寄存器,实现了用执行中断程序前的CPU现场恢复标志寄存器以及CS和IP的工作;
4.单步中断
一般地,CPU执行完一条指令后,检测标志寄存器的TF位若为1则产生单步中断(类型码为1)进而引发如下中断过程:
- 取得中断类型码1;
- 标志寄存器入栈,TF、IF设置为0;
- CS、IP入栈
- (IP)=(1*4),CS=(1 *4+2)
CPU提供这样的功能,一个直观的例子就是Debug让CPU执行一条指令后就显示各个寄存器的状态 —— 即Debug提供了单步中断的中断处理程序,其功能为显式所有寄存器中的内容后等待输入命令;
当然在进入中断处理程序之前需要设置TF=0,避免CPU在执行中断处理程序的时候发生单步中断;
CPU提供单步中断的原因就是为单步跟踪程序的执行过程提供了实现机制;
5.int指令
;int指令的格式为 int n,其中n为中断类型码,其功能是引发中断过程
CPU执行int n指令相当于引发一个n号中断的中断过程(即可以在程序中使用int指令调用任何一个中断的中断处理过程),执行过程如下:
- 取出中断类型码n
- 标志寄存器入栈,IF=0,TF=0
- CS、IP入栈
- (IP)=(n *4),(CS)=(n *4+2)
一般情况下,系统将一些具有一定功能的子程序,以中断处理程序的方式提供给应用程序调用,当我们编程的时候可以使用int指令调用这些子程序(当然也可以自己编写一些中断处理程序,我们称之为中断例程)
BIOS和DOS提供了一些常用中断例程,系统板的ROM中存放着一条程序BIOS(基本输入输出系统),主要包含以下内容:
- 硬件系统的检测和初始化程序;
- 外中断和内中断的中断例程;
- 用于硬件I/O操作的中断例程;
- 其他与硬件相关的中断例程;
操作系统DOS提供的中断例程实际就是操作系统向程序员提供的编程资源;
程序员在编程的时候可以用int指令直接调用BIOS和DOS提供的中断例程完成某些工作,和硬件相关的DOS中断例程中一般都会调用BIOS的中断例程;
我们给出BIOS和DOS提供的中断例程装载到内存中的实例(实际上很接近操作系统中的系统启动前的一系列操作):

2022/9/22 11:08 到此为止我们的汇编语言的学习告一段落,之后我们将继续学习操作系统和汇编原理,如果对汇编语言感兴趣想要深入可自行学习;
1)进而引发如下中断过程:
- 取得中断类型码1;
- 标志寄存器入栈,TF、IF设置为0;
- CS、IP入栈
- (IP)=(1*4),CS=(1 *4+2)
CPU提供这样的功能,一个直观的例子就是Debug让CPU执行一条指令后就显示各个寄存器的状态 —— 即Debug提供了单步中断的中断处理程序,其功能为显式所有寄存器中的内容后等待输入命令;
当然在进入中断处理程序之前需要设置TF=0,避免CPU在执行中断处理程序的时候发生单步中断;
CPU提供单步中断的原因就是为单步跟踪程序的执行过程提供了实现机制;
5.int指令
;int指令的格式为 int n,其中n为中断类型码,其功能是引发中断过程
CPU执行int n指令相当于引发一个n号中断的中断过程(即可以在程序中使用int指令调用任何一个中断的中断处理过程),执行过程如下:
- 取出中断类型码n
- 标志寄存器入栈,IF=0,TF=0
- CS、IP入栈
- (IP)=(n *4),(CS)=(n *4+2)
一般情况下,系统将一些具有一定功能的子程序,以中断处理程序的方式提供给应用程序调用,当我们编程的时候可以使用int指令调用这些子程序(当然也可以自己编写一些中断处理程序,我们称之为中断例程)
BIOS和DOS提供了一些常用中断例程,系统板的ROM中存放着一条程序BIOS(基本输入输出系统),主要包含以下内容:
- 硬件系统的检测和初始化程序;
- 外中断和内中断的中断例程;
- 用于硬件I/O操作的中断例程;
- 其他与硬件相关的中断例程;
操作系统DOS提供的中断例程实际就是操作系统向程序员提供的编程资源;
程序员在编程的时候可以用int指令直接调用BIOS和DOS提供的中断例程完成某些工作,和硬件相关的DOS中断例程中一般都会调用BIOS的中断例程;
我们给出BIOS和DOS提供的中断例程装载到内存中的实例(实际上很接近操作系统中的系统启动前的一系列操作):
