微服务项目 -- day04 分布式搜索引擎ElasticSearch
一、ElasticSearch简介
1、什么是ElasticSearch
Elasticsearch是一个实时的分布式搜索和分析引擎。它可以帮助你用前所未有的速度去处理大规模数据。ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
2、EclaticSearch的特点
可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上
将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES;
开箱即用的,部署简单
全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理
3、ElasticSearch的体系结构
下表是Elasticsearch与MySQL数据库逻辑结构概念的对比

二、Windows下的ElasticSearch安装与使用
1、ElasticSearch的部署和启动
(1)、下载ElasticSearch
资源路径:https://download.csdn.net/download/wingzhezhe/10539750
(2)、启动ElasticSearch,解压可用,进入bin目录下执行命令即可启动:
说明:ElasticSearch启动日志中的9200端口号是Http协议访问的端口号,9300端口号是java代码连接访问的端口号
三、Head插件的安装与使用
1、Head插件的作用
如果都是通过rest请求的方式使用Elasticsearch,未免太过麻烦,而且也不够人性化。我们一般都会使用图形化界面来实现Elasticsearch的日常管理,最常用的就是Head插件。
2、Head插件的下载安装
(1)、安装Head插件
下载路径:https://download.csdn.net/download/wingzhezhe/10539870,下载后解压到非中文目录即可。
(2)、安装Node.js
下载地址:https://download.csdn.net/download/wingzhezhe/10539885,按照提示默认安装即可。
(3)、安装cnpm命令,需要联网安装
npm install -g cnpm --registry=https://registry.npm.taobao.org
(4)、将grunt安装为全局命令
grunt是基于Node.js的项目构建工具,可以自动运行设定的任务
cnpm install -g grunt-cli
(5)、安装依赖
cnpm isntall
(6)、进入head插件目录,启动head
grunt server
(7)、修改ElasticSearch配置文件,支持跨域

(8)、重启ElasticSearch服务和head插件,浏览器访问

四、IK分词器
1、IK分词器的下载安装
下载地址:https://download.csdn.net/download/wingzhezhe/10540090
解压后改名为ik,将文件夹拷贝到ElasticSearch的Plugins目录下,重启ElasticSearch即可使用

2、自定义词库
在大多数情况下,ElasticSearch对中文进行的分词有不能够完全满足自己的需要,需要自定义停止词和扩展词,配置方式如下:
(1)、进入elasticsearch-5.6.8/plugins/ik/config目录
创建extword.dic文件,在文件中编写自定义的词汇,保存格式为UTF-8无BOM格式
(2)、修改配置IKAnalyzer.cfg.xml文件,加入扩展词文件映射

五、搜索微服务开发
1、搜索微服务模块环境搭建
(1)、创建Maven module,在pom.xml中加入依赖jar包坐标
org.springframework.boot
spring-boot-starter-data-elasticsearch
com.scf
scf_common
1.0-SNAPSHOT
(2)、编辑配置文件和启动引导类
application.yml
server:
port: 9007
spring:
application:
name: scf-search
data:
elasticsearch:
cluster-nodes: 127.0.0.1:9300SearchApplication.java
package com.scf.search;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import util.IdWorker;
@SpringBootApplication
public class SearchApplication {
public static void main(String[] args) {
SpringApplication.run(SearchApplication.class, args);
}
@Bean
public IdWorker idWorkker() {
return new IdWorker(1, 1);
}
}(3)、编写实体类和数据访问层接口
Article.java
package com.scf.search.pojo;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import java.io.Serializable;
/**
* 文章实体类
*/
@Document(indexName = "tensquare", type = "article")
public class Article implements Serializable {
@Id
private String id;
//@Field注解用于指定使用的分词器
@Field(index = true, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")
private String title;
@Field(index = true, analyzer = "ik_max_word", searchAnalyzer = "ik_max_word")
private String content;
private String state;
setter/setter
}ArticleDao.java
package com.scf.search.dao;
import com.scf.search.pojo.Article;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
/**
* 文章数据访问层接口
*/
public interface ArticleDao extends ElasticsearchRepository {
} 2、实现新增文章、根据文章或内容模糊查询的功能
ArticleDao.java
/**
* 根据文章或者标题模糊查询
* @param title
* @param content
* @param pageable
* @return
*/
public Page findByTitleOrContentLike(String title, String content, Pageable pageable); ArticleService.java
package com.scf.search.service;
import com.scf.search.dao.ArticleDao;
import com.scf.search.pojo.Article;
import entity.PageResult;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.stereotype.Service;
@Service
public class ArticleService {
@Autowired
private ArticleDao articleDao;
/**
* 增加文章
* @param article
*/
public void add(Article article){
articleDao.save(article);
}
/**
* 根据关键字查询文章列表
* @param keywords
* @param page
* @param size
* @return
*/
public PageResult findByKeywords(String keywords, int page, int size){
PageRequest pageRequest = PageRequest.of(page - 1, size);
Page pageList = articleDao.findByTitleOrContentLike(keywords, keywords, pageRequest);
return new PageResult(pageList.getTotalElements(), pageList.getContent());
}
} ArticleController.java
package com.scf.search.controller;
import com.scf.search.pojo.Article;
import com.scf.search.service.ArticleService;
import entity.PageResult;
import entity.Result;
import entity.StatusCode;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@CrossOrigin
@RequestMapping("/article")
public class ArticleController {
@Autowired
private ArticleService articleService;
/**
* 添加文章
* @param article
* @return
*/
@RequestMapping(method = RequestMethod.POST)
public Result add(@RequestBody Article article){
articleService.add(article);
return new Result(true, StatusCode.OK, "添加成功");
}
/**
* 根据关键字查询
* @param keyswords
* @param page
* @param size
* @return
*/
@RequestMapping(value = "/search/{keywords}/{page}/{size}", method = RequestMethod.GET)
public Result findByKeywords(@PathVariable String keyswords, @PathVariable int page, @PathVariable int size){
PageResult pageResult = articleService.findByKeywords(keyswords, page, size);
return new Result(true, StatusCode.OK, "查询成功", pageResult);
}
}六、ElasticSearch与MySQL数据同步
1、Logstash介绍与下载安装与测试
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。
下载地址:https://download.csdn.net/download/wingzhezhe/10540320 解压即可,进入bin目录,命令行输入如下命令:

stdin,表示输入流,指从键盘输入
stdout,表示输出流,指从显示器输出
命令行参数:
-e 执行
--config 或 -f 配置文件,后跟参数类型可以是一个字符串的配置或全路径文件名或全路径路径(如:/etc/logstash.d/,logstash会自动读取/etc/logstash.d/目录下所有*.conf 的文本文件,然后在自己内存里拼接成一个完整的大配置文件再去执行)
2、通过Logstash实现MySQL数据库中数据导入ElasticSearch
(1)、logstash-5.6.8目录下创建任意文件夹并创建编写配置文件

mysql.conf
input {
jdbc {
# 配置数据库连接信息
jdbc_connection_string => "jdbc:mysql://192.168.37.133:3306/tensquare_article?characterEncoding=UTF8"
# the user we wish to excute our statement as
jdbc_user => "root"
jdbc_password => "123456"
# jdbc驱动包所在目录,绝对路径
jdbc_driver_library => "D:\\JavaEE\\ElasticSearch\\logstash-5.6.8\\mysqletc\\mysql-connector-java-5.1.46.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 是否分页
jdbc_paging_enabled => "true"
# 每次查询条数
jdbc_page_size => "50000"
# 以下对应着要执行的sql的绝对路径, 适用于比较复杂的sql语句。
#statement_filepath => ""
statement => "select id, title, content, state from tb_article"
# 定时字段 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新(测试结果,不同的话请留言指出)
schedule => "* * * * *"
}
}
output {
elasticsearch {
# ElasticSearch的IP地址与端口
hosts => "127.0.0.1:9200"
# ElasticSearch索引名称(自己定义的)
index => "tensquare"
# 自增ID编号 %{id} :表示取sql查询结果中的id字段的值
document_id => "%{id}"
document_type => "article"
}
stdout {
#以JSON格式输出
codec => json_lines
}
}(2)、启动logstash,使用命令导入数据
logstash -f ../mysqletc/mysql.con七、ElasticSearch在Docker环境下的安装
1、拉取镜像
pull elasticsearch:5.6.82、守护式启动容器
docker run -di --name=tensquare_elasticsearch -p 9200:9200 -p 9300:9300 elasticsearch:5.6.83、进入elasticsearch容器,修改配置文件,允许远程访问

进入容器中,使用vim/vi命令修改,但docker中没有vi插件,不能直接修改,因此需要将配置文件复制到宿主机,修改完成之后再重新拷贝到docker容器中,命令如下:
-- 将容日中的配置文件拷入宿主机
docker cp tensquare_elasticsearch:/usr/share/elasticsearch/config/elasticsearch.yml /root/elasticsearch.yml
-- 停止容器,删除容器
docker stop tensquare_elasticsearch
docker rm tensquare_elasticsearch
-- 重新创建守护式容器,并将/root下的elasaticsearch.yml配置文件挂载到创建的容器中的配置文件上,修改宿主机的配置文件,容器中配置文件也会被修改,参数v表示挂载
docker run -di --name=tensquare_elasticsearch -p 9200:9200 -p 9300:9300 -v /root/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml elasticsearch:5.6.8
编辑宿主机上挂载的配置文件
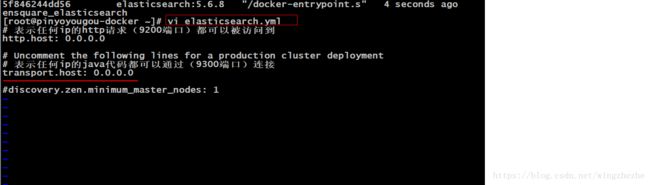
4、重启docker中的elasticsearch容器

启动docker容器失败,此时,需要进行Linux系统调优,方式如下:
(1)、修改/etc/security/limit.conf配置文件,末位加入如下配置
# Linux系统能够打开的最大文件文件
* soft nofile 65536
* hard nofile 65536(2)、修改/etc/sysctl.conf,追加如下内容
# 限制一个进程可以使用的虚拟内容数量
vm.max_map_count=655360(3)、使用命令,让修改的内核参数立即生效
sysctl -p
reboot