python-pandas学习笔记
文章目录
- 读写文件
-
- 一般读写xlsx/csv文件
- 读写有多个子表的excel表格
- 查询、遍历
-
- 获取表头信息
- 获取某一行并转为list数据
- 判断表格是否为空
- 按照列名筛选出整行信息
- 按单元格值筛选另一列信息
- 获取单个单元格以及单元格内容
- 二维表的美观显示
- 修改
-
- 修改单个表格的内容
- 增删表格
-
- 从其他类型对象生成DataFrame对象
- 增加一列
- 删除一列
- 增加一行
- 删除行
- 拼接表格
-
- 后缀拼接单行
- 持续更新中。。。
读写文件
一般读写xlsx/csv文件
import pandas as pd
'''
filename: 为文件名或者路径,filename也可以是一个url
sheet_name: 指定要读取的xlsx文件的子表,默认为0
返回值df为DataFrame类型的二维数据表格,下同
'''
df = pandas.read_excel(filename,sheet_name = 0) #
# 写入xlsx格式文件
df.to_excel(filename,index = False) # 不写入行索引,默认是写入的
# 读取csv文件
df = pandas.read_csv(filename)
#写入csv文件
df.to_csv(filename,index = False,sep = ',') # sep为指定的分隔符
读写有多个子表的excel表格
import pandas
# 读取所有子表
df = pandas.read_excel(file_name,sheet_name = None)
查询、遍历
获取表头信息
header_info = df.columns.values # 返回的是numpy.ndarray类型数据
header_info = df.columns.values.tolist() # 转为list
获取某一行并转为list数据
import pandas as pd
order_list = pd.DataFrame(np.array([[12,3,1],[13,4,0],[17,4,5],[16,5,2],[14,3,1]]),
columns = ['capacity required','unit returns','time remaining'])
order1 = np.array(order_list.iloc[1])
order1 = order1.tolist()
判断表格是否为空
df.empty # 若为空返回True,否则返回False
按照列名筛选出整行信息
# 筛选出二维表中所有某列值为“XX”的全部行信息
df_find = df_books[df_books['出版年份'] == 2015] # 打印出出版年份所有出版年份为2015的书籍信息
按单元格值筛选另一列信息
# 筛选出所有某列值为“XX”的“YY”列信息,返回的是 Series 对象
df_find = df_books.loc[df_books['出版年份'] == 2015,'书名'] # 打印出出版年份所有出版年份为2015的书名
获取单个单元格以及单元格内容
# 筛选出所有某列值为“XX”的“YY”列信息,返回的是 Series 对象
# 筛选出图书编号为15的书名,这里的图书编号为二维表的主键,所以返回的Series对象里面只有一个元素
df_find = df_books.loc[df_books['图书编号'] == 15,'书名']
# 获取单个单元格内容
df_find_cont = df_books.loc[df_books['图书编号'] == 15,'书名'].item() # 返回的是str类型的对象
二维表的美观显示
强烈推荐用prettytable库里面的接口显示二维表格,下面是显示效果。
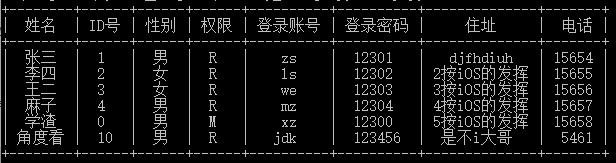
对应的代码:
import pandas
from prettytable import PrettyTable
df_readers = pandas.read_excel("./readers.xlsx",sheet_name = 0)
tb_header = df_readers.columns.values.tolist() # 获取表头信息,并转为list
table = PrettyTable(tb_header) # 创建显示表格
rows = df_readers.values.tolist() # 获取表格内容,不含表头,转为2维list
for r in rows:
table.add_row(r)
print(table)
修改
修改单个表格的内容
# 先筛选出指定单元格,然后赋值即可
df_find = df_books.loc[df_books['图书编号'] == 15,'书名'] = "Python编程——从入门到放弃"
增删表格
从其他类型对象生成DataFrame对象
df = pandas.DataFrame(new_dict) # 字典
df = pandas.DataFrame(np_2arr) # numpy中的二维数组或者用2维list也行
# 注意:字典生成的DataFrame会按照键值生成表头,numpy数组或2_list用默认的表头
增加一列
# 直接操作新列名,赋予所有列一个初始值即可
df['新列名'] = new_col_value
删除一列
# 方法一
del df['列名']
# 方法二
'''
colName:要删除的列名
axis:为0时表示删除的是行索引,为1时表示删除的是列名
inplace:默认值为False,表示不修改原df,返回一个新的df;True时表示在原df上修改。
'''
df_new = df.drop('colName',axis = 1,inplace = False)
增加一行
用loc方法
df.loc[end+1] = list_array # 与新增列类似
删除行
其实每一次筛选就是一次删除。
# 删除’col_name‘列中值为“col_value”的行,注意返回值
df = df[~df['col_name'].isin([col_value])]
拼接表格
后缀拼接单行
appen方法,该方法默认不会修改当前表格,而是返回一个新的DataFrame类型的数据。
'''
df1与df2的表头需要一致,ignore_index表示忽略行索引。
df2可以是表格,也可以是字典或类似字典格式的对象如json,不管是哪种,键数要与df1保持一致
'''
df_new = df1.append(df2,ignore_index = True)