44.Isaac教程--姿态估计
二维骨骼姿态估计

ISAAC教程合集地址: https://blog.csdn.net/kunhe0512/category_12163211.html
文章目录
- 二维骨骼姿态估计
-
- 应用概述
- 推理
-
- 运行推理
- 在嵌入式平台上运行推理
- 消息类型
- 小码
- 推理示例
- 训练
-
- 步骤 1. 先决条件 安装 Docker 容器
- 步骤 2. 安装
- 步骤 3. 下载 COCO 2017 和预处理
- 步骤 4. 模型训练
- 步骤 5. 转换为 ONNX 模型
- OpenPose 算法的描述和参数
-
- 步骤 1. 图像输入、缩放和归一化
- 步骤 2. 推理
- 步骤 3. 最大池化
- 步骤 4. 非极大值抑制
- 步骤 5. 生成候选极值
- 步骤 6. 生成候选零件
- 步骤 7. 生成边候选
- 步骤 8. 为边候选者分配分数
- 步骤 9. 将阈值应用于边候选者
- 步骤 10. 应用图形匹配算法
- 第 11 步。合并分割图
- 第 12 步。细化零件坐标(可选)
- 第 13 步。可视化(可选)
机器人技术需要能够检测和估计姿势、跟踪和估计未来状态以及推理这些状态以对各种铰接物体做出决策的应用程序。 此类对象的主要示例包括人、机器和无生命对象。 人的姿势估计特别复杂,因为他们行为的复杂性和服装的多样性。 数据概率分布的偏差和数据中罕见案例的存在进一步放大了这种复杂性。
Isaac SDK 中的 2D 骨架姿势估计应用程序提供了使用“具有部分亲和力场的清晰物体的 2D 骨架姿势估计”(Zhe 等人)中描述的姿势估计模型运行推理的框架。 此应用程序旨在通过利用 GPU 加速实现低延迟联合实时对象检测和 2D 关键点姿态估计,同时实现良好的准确性。
一次可以处理一个对象类的多个实例; 事实上,可以同时处理的对象实例的数量没有硬性限制。 支持重叠、遮挡和自遮挡情况。 本地帧外遮挡关键点估计也可用。
应用概述

2D 骨骼姿势估计应用程序由推理应用程序和神经网络训练应用程序组成。
推理应用程序采用 RGB 图像,将其编码为张量,运行 TensorRT 推理以联合检测和估计关键点,并确定关键点的连通性和感兴趣对象的 2D 姿态。 要运行推理,此应用程序需要针对感兴趣的对象训练有素的神经网络。
要训练神经网络,您可以使用 NVIDIA AI IOT TensorRT Pose Estimation 开源项目。 它允许使用 PyTorch 开源机器学习库从 COCO 类型数据集进行分布式 GPU 训练。 或者,可以使用任何部分亲和力场兼容的神经网络训练代码。
推理
以下计算图概述了关键点姿势估计模型从单个 RGB 图像进行的端到端推理:

运行推理
要在静态图像数据上运行推理应用程序,请在 Isaac SDK 中运行以下命令:
bob@desktop:~/isaac/sdk$ bazel run packages/skeleton_pose_estimation/apps/openpose:openpose_inference
注意
虽然该模型能够实时运行推理,但首次部署该模型需要针对目标 GPU 设备优化神经网络。 此优化可能需要 20 到 60 秒。 连续部署需要 1-2 秒来加载并且主要受目标系统的磁盘 (i/o) 性能限制。
该应用程序从静态图像中获取单眼相机输入,并输出检测到的对象的估计二维关键点。 估计的姿势可以在 http://localhost:3000 的 Sight 中自动可视化。
注意
要恢复输出中原始图像的比例和纵横比,请在 OpenPoseDecoder 配置中设置输出比例。 例如,如果原始图像(或相机)输入的分辨率为 640x480 像素,则输出比例应设置为 [480, 640]:
“isaac.skeleton_pose_estimation.OpenPoseDecoder”:{
“output_scale”:[480, 640]
在嵌入式平台上运行推理
推理需要大量资源,这可能会导致 Jetson Nano 和 Jetson TX2 等嵌入式平台出现系统压力。 可以选择在不同输入分辨率和输入/输出分辨率因子(1:2、1:4)下工作的模型,以更好地适应特定用例的约束。
适用于 Jetson Nano 的高性能模型示例可用。 该模型使用 1:4 比例因子,旨在在模型精度与 GPU-CPU 内存传输和计算能力的实时处理约束之间提供良好的折衷。 要在 Jetson Nano 上部署此模型,请按照以下步骤操作:
-
将
//packages/skeleton_pose_estimation/apps/openpose:trt_pose_inference-pkg部署到机器人,如应用程序控制台选项中所述。 -
使用以下命令切换到 Jetson 上部署包的目录:
user@jetson:~/$ cd ~/deploy/bob/trt_pose_inference-pkg
其中“bob”是您在主机系统上的用户名。
- 使用以下命令运行应用程序:
user@jetson:~/deploy/bob/trt_pose_inference-pkg-pkg/$ ./packages/skeleton_pose_estimation/apps/openpose/trt_pose_inference
消息类型
推理应用程序使用以下消息类型:
-
ImageProto
-
CameraIntrinsicsProto
-
TensorListProto
-
Skeleton2Proto
-
Skeleton2ListProto
小码
推理应用程序使用以下小码:
-
ImageLoader
-
ColorCameraEncoderCuda
-
TensorRTInference
-
OpenPoseDecoder
-
SkeletonViewer
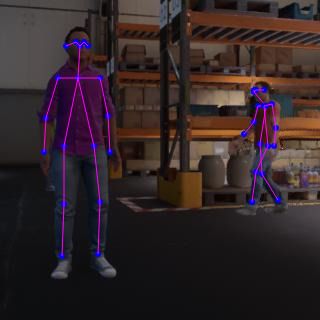
推理示例
下图演示了 OpenPose 算法的推理输出和后处理步骤(检测到的对象、图形连接和零件位置):

训练
以下步骤使用 NVIDIA AI IOT TensorRT Pose Estimation 来训练神经网络。 更多详细信息,请参阅 TensorRT Pose Estimation 文档。
注意
模型训练需要大量资源。 我们建议在 NVIDIA DGX、NVIDIA DGX Station 或多 GPU 虚拟机实例上训练神经网络。 即使使用功能强大的机器,下载数据集、预处理数据、训练模型和导出它也需要花费大量时间。
步骤 1. 先决条件 安装 Docker 容器
NVIDIA NGC 提供了一个随时可用的 NVIDIA PyTorch 1.2 Docker 镜像,其中包含用于训练 NVIDIA AI IOT TensorRT 姿态估计模型的所有先决组件。 请使用以下命令拉取并运行 Docker 容器:
注意
请参阅 NVIDIA NGC 设置页面以访问容器并设置 Docker。
docker pull nvcr.io/nvidia/pytorch:19.09-py3
nvidia-docker run -it nvcr.io/nvidia/pytorch:19.09-py3
步骤 2. 安装
克隆 NVIDIA AI IOT TensorRT Pose Estimation 存储库并安装它:
git clone https://github.com/NVIDIA-AI-IOT/trt_pose
cd trt_pose
python3 setup.py install --user
步骤 3. 下载 COCO 2017 和预处理
下载 COCO 2017 数据集并使用以下命令对其进行预处理:
注意
确保至少有 50 Gb 的空间可用于 20 Gb 下载和工作区。
cd tasks/human_pose/
bash download_coco.sh
unzip val2017.zip
unzip train2017.zip
unzip annotations_trainval2017.zip
python3 preprocess_coco_person.py annotations/person_keypoints_train2017.json annotations/person_keypoints_train2017_modified.json
python3 preprocess_coco_person.py annotations/person_keypoints_val2017.json annotations/person_keypoints_val2017_modified.json
步骤 4. 模型训练
使用以下命令训练 DNN:
cd tasks/human_pose/
python3 -m trt_pose.train experiments/resnet18_baseline_att_224x224_A.json
注意
实验文件夹中提供了替代模型分辨率和架构。
步骤 5. 转换为 ONNX 模型
TensorRT 姿势估计包包含一个实用程序,可将经过训练的模型从 PyTorch 框架转换为通用的 ONNX 格式。 在此应用程序中,PyTorch 解析器读取模型权重并将它们转换为 ONNX,以便 TensorRT codelet 可以将它们用于推理。
在训练迭代结束时,PyTorch 模型被保存为 .pth 文件。 然后,您需要使用 python 脚本和 ONNX 解析器将其转换为 ONNX 模型。
例如,在第 249 个 epoch 结束时,PyTorch 模型保存为 experiments/resnet18_baseline_att_224x224_A.json.checkpoints/epoch_249.pth,可以使用以下命令转换为 ONNX 模型:
cd tasks/human_pose/
cp experiments/resnet18_baseline_att_224x224_A.json.checkpoints/epoch_249.pth \
resnet18_baseline_att_224x224_A_epoch_249.pth
python3 ../../trt_pose/utils/export_for_isaac.py --input_checkpoint resnet18_baseline_att_224x224_A_epoch_249.pth
运行上面的命令将生成一个 resnet18_baseline_att_224x224_A_epoch_249.onnx 文件,然后您可以将其用作输入模型。 有关详细信息,请参阅 trt_pose_inference.app.json 示例和 TensorRTInference 配置。
OpenPose 算法的描述和参数
本节介绍 OpenPose 算法的步骤。 有关详细信息,请参阅 OpenPose 论文和 OpenPoseDecoder API 参考。
步骤 1. 图像输入、缩放和归一化
ImageLoader 组件将图像输入编码为包含单个 RGB 图像的 ImageProto。 原始图像被下采样并作为 3D 张量 (WxHx3) 存储在 TensorListProto 中。 此张量归一化类型由 ColorCameraEncoderCuda 组件中的参数指定。 此参数与张量大小一起在神经网络训练期间设置,并且应在推理时设置为相同的值(例如,用于单位归一化的 Unit)。 允许张量大小的小变化,但大的变化可能会导致问题(例如,将张量的纵横比从 1:1 切换到 16:9 会大大降低网络性能)。
注意
在图像归一化步骤中,图像比例和纵横比在 ColorCameraEncoderCuda 小代码中被丢弃。 要恢复比例信息,请在 OpenPoseDecoder 配置中设置输出比例。 例如,如果原始图像(或相机)输入的分辨率为 640x480 像素,则输出比例应设置为 [480, 640]:
“isaac.skeleton_pose_estimation.OpenPoseDecoder”:{
“output_scale”:[480, 640]
以下是用于推理的示例图像输入:

步骤 2. 推理
OpenPoseDecoder 对模型运行推理,生成部分亲和力场、部分高斯热图和部分高斯热图 MaxPool 张量。 有关神经网络的详细架构,请参阅 OpenPose 论文。
作为算法的第一步,TensorRTInference 组件分析高斯热图张量以确定对象部分(或关节)候选位置。 此热图的大小通常是图像大小的 1/2 或 1/4。
此张量的维数在训练时设置,并且应与 TensorRTInference codelet 中指定的维数、输入图像大小和对象部分的数量相匹配。 以下是输入 RGB 图像大小设置为640x480且部分数设置为 2 的示例:
"isaac.ml.TensorRTInference": {
"input_tensor_info": [
{
"operation_name": "input",
"dims": [3, 480, 640]
}
],
"output_tensor_info": [
...
{
"operation_name": "heatmap",
"dims": [120, 160, 2]
},
...
"isaac.skeleton_pose_estimation.OpenPoseDecoder": {
"labels": ["Wrist", "Elbow"],
下面提供了高斯热图张量的可视化,颜色对应于张量的最后一个维度:标签:手腕,颜色:红色,索引:0,标签:肘部,颜色:绿色,索引:1。

步骤 3. 最大池化
接下来,OpenPoseDecoder 将最大池化操作应用于具有在训练时确定的内核大小的高斯热图。 这种最大池化操作为非最大抑制算法提供了基础,使其能够定位部件候选位置的峰值。

步骤 4. 非极大值抑制
接下来,OpenPoseDecoder 使用对高斯热图和高斯热图 MaxPool 张量的“相等”操作执行非最大抑制。 此操作为部分候选位置提供峰值候选位置。

步骤 5. 生成候选极值
候选峰值具有与其关联的“置信度”值,这些值源自原始高斯热图。 在下面的可视化中,峰颜色的不透明度决定了置信度。
注意
之前热图中的几乎所有峰都具有低不透明度并且不可见。

步骤 6. 生成候选零件
将阈值应用于每个候选峰值的置信度值,以获得候选部件的最终列表。 可以使用 OpenPoseDecoder 的 threshold_heatmap 参数调整此阈值。 此阈值的正常值范围是 0.01 到 0.1。
下面的二元热图显示了候选零件的最终列表。 请注意,颜色对应于各个候选部分的二进制映射,就像其他可视化一样。

步骤 7. 生成边候选
接下来,OpenPoseDecoder 根据边缘连接的先前配置创建边缘候选列表。 此连接在 OpenPoseDecoder 配置中设置。 下面是一个示例,其中“Wrist”->“Elbow”的单边对应于“Arm”:
注意
图的边是有方向的。 这些方向应与 Part Affinity Fields 张量的场方向相匹配。
注意
在“edges”配置中,指定了“labels”数组的索引。
"isaac.skeleton_pose_estimation.OpenPoseDecoder": {
"labels": ["Wrist", "Elbow"],
"edges": [[1, 0] ...
下面是边缘候选列表的可视化:

步骤 8. 为边候选者分配分数
为了使用候选边确定最终的边列表,OpenPoseDecoder 根据部分亲和力场张量计算每个候选边的分数。 以下是“手臂”(“手腕”->“肘部”边缘)的单个部分亲和力场的此类张量的示例。
注意
在 TensorRTinference 配置中,最后一个维度大小是“边”数的两倍,因为部分亲和场是一个具有两个(水平和垂直)分量的矢量场。
"output_tensor_info": [
{
"operation_name": "part_affinity_fields",
"dims": [120, 160, 2]
},
OpenPoseDecoder edges_paf 参数确定场的水平和垂直分量的部分亲和力场张量的索引:
"isaac.skeleton_pose_estimation.OpenPoseDecoder": {
"edges_paf": [[1,0] ...
下面是“手臂”(“手腕”->“肘部”边缘)的部分亲和力场的可视化:

下面是“手臂”(“手腕”->“肘部”边缘)的零件亲和力场的放大图和候选零件列表。 请注意,该图中的每个箭头都是零件亲和力场的单个矢量的可视化。 还显示了“手腕”和“肘部”的两个候选部分。

为了计算每个边缘候选的分数,OpenPoseDecoder 计算部分亲和力场向量和边缘候选向量之间的点积的线积分估计。 edge_sampling_steps 参数可用于确定积分采样步数。
下图显示了一个示例线积分估计:

步骤 9. 将阈值应用于边候选者
OpenPoseDecoder 将一组最终阈值应用于边缘候选分数以确定边缘列表。 threshold_edge_score 是积分步骤的每个单独点积的阈值。 此阈值的正常值范围为 0.01 至 0.05。
threshold_edge_sampling_counter 是高于 threshold_edge_score 的单个点积数量的阈值:如果数量超过此阈值,则 Edge Candidate 被视为 Edge。
"threshold_edge_score" : 0.01,
"threshold_edge_sampling_counter" : 4,
下面是集成步骤和阈值处理后最终边列表的可视化:

步骤 10. 应用图形匹配算法
在确定部分、边缘及其分数的列表后,OpenPoseDecoder 应用图形匹配算法来确定最终的对象(骨架)列表。 应用图形匹配算法后,将应用以下阈值以按最少的部分数和分数过滤出对象:
“threshold_part_counter”:1,
“threshold_object_score”:0.1,
第 11 步。合并分割图
在某些情况下,非极大值抑制后仍然可以存在两个Part,这导致对象被分裂成不连通的图。 如果将对象拆分为两个断开连接的图形的分数小于 objects_split_score,则此类断开连接的图形将合并为单个图形。 以下参数可用于控制此算法:
“threshold_split_score”:2,
第 12 步。细化零件坐标(可选)
一旦最终对象列表可用,就可以将零件坐标从整数索引细化为高斯热图张量。 通过将 refine_parts_coordinates 参数设置为 true 可以使用此功能。 当网络具有 1:4 输入/输出分辨率因子时,通常需要此步骤。
注意
“精细部件坐标”的输出是放置在“网格中心”的浮点子像素坐标,而不是整数行和列。
"refine_parts_coordinates" : true,
第 13 步。可视化(可选)
下面是检测到的对象、图形连接和零件位置的最终可视化:

更多精彩内容:
