想机器学习实战却不会特征降维?这可不行
最近期末需要交的论文有些多,所以更新进度有些慢,为了弥补空白期,以后也会给大家转载一些好文,感谢各位哥哥姐姐一直以来的支持。
如果只对降维的代码部分感兴趣可以直接划至文末。
一直都在研究关于机器学习相关算法的理论,最近准备打算在Kaggle参加些竞赛,但只会一些理论知识是不足以针对给定的数据建立一个比较不错的模型,这其中还包括很多必要的操作,比如缺失值处理、特征工程等等。
今天来说一下特征降维,我们在练习时通常会用sklearn自带的数据集,比如鸢尾花数据集,通常这类数据集是经过处理的,特点就是规模小且完整性强,但对于Kaggle竞赛或者其他领域中给定的数据集一般都是规模偏大且具有很多缺失值。
规模大可分为两方面,一方面是数据多而特征少,另一方面是数据少但特征多。我们都知道数据多对于建模是有好处的,因为数据越多覆盖面就越广,会提高模型的准确率,当然这可能会牺牲一些内存和计算时间。
但是特征多可未必就是一件好的事情,如果将数据集映射至一个空间中,每一个特征就对应一个维度,随着维度的增加,学习器所需的样本的数量通常以指数增加,但通常高维度数据集的样本个数并不满足要求,这样的数据稀疏性也特别高,可能导致模型的准确率偏低,且对内存和计算时间很不友好。


特征降维

对于多特征数据集,我们可以有这么一个设想就是会不会有一些特征之间的相关性很高?比如学习时长和学习成绩之间可能就是正相关,学习时间越长学习成绩也会越高,那么删去其中一个对数据集的影响可能特别微小,其他特征做类似操作,最后剩下的特征两两之间不相关,此操作就叫做降维。
降维是一种针对高维度数据集数据预处理方法,它的基本思想就是保留一些相对重要的特征,除去剩下的特征和数据中的噪声,降维操作可以很大程度节省运行内存和计算时间,让数据处理更加高效。
对数据降维还有以下一系列原因:
使数据集更易使用;
降低很多算法的计算开销;
除去数据中的噪声;
使得结果易懂。
常见的降维方法有主成分分析(PCA)、因子分析(FA)、独立成分分析(ICA)和奇异值分解(SVD)。其中PCA和SVD是最常用的两种,本文介绍第一种PCA降维法。
主成分分析
原理及对应操作
主成分分析顾名思义是对主成分进行分析,那么找出主成分应该是key点。PCA的基本思想就是将初始数据集中的n维特征映射至k维上,得到的k维特征就可以被称作主成分,k维不是在n维中挑选出来的,而是以n维特征为基础重构出来的。
PCA会在已知数据的基础上重构坐标轴,它的原理是要最大化保留样本间的方差,两个特征之间方差越大不就代表相关性越差嘛。比如:
第一个新坐标轴就是原始数据中方差最大的方向。
第二个新坐标轴要是与第一个新坐标轴正交的平面中方差最大的方向。
第三个新坐标轴要是与第一、第二新坐标轴正交的平面中方差最大的方向。
第四、第五...依次类推直到第n个新坐标轴(对应n维)。
为了加深这部分理解,以二维平面先举一个例子,二维平面中依据原始数据新建坐标轴如下图:

为了更直观的理解,若将方差换一个说法,那么第一个新坐标轴就是覆盖样本最多的一条(斜向右上),第二个新坐标轴需要与第一新坐标轴正交且覆盖样本最多(斜向左上),依次类推。
覆盖的样本多少并不是以坐标轴穿过多少样本点评判的,而是通过样本点垂直映射至该轴的个数有多少,具体如下图:

回到之前的n维重构坐标轴,由于顺序是依据方差的大小依次排序的,所以越到后面方差越小,而方差越小代表特征之间相关性越强,那么这类特征就可以删去,只保留前k个坐标轴(对应k维),这就相当于保留了含有数据集绝大部分方差的特征,而除去方差几乎为0的特征。
那么问题来了,二维、三维可以根据样本点的分布画出重构坐标轴,但是更高维人的大脑是不接受的,我们不得不通过计算的方式求得特征之间的方差,进而得到这些新坐标轴的的方向。
具体方法就是通过计算原始数据矩阵对应的协方差矩阵,然后可以得到协方差矩阵对应的特征值和特征向量,选取特征值最大的前k个特征向量组成的矩阵,通过特征矩阵就可以将原始数据矩阵从n维空间映射至k维空间,从而实现特征降维。
方差、协方差及协方差矩阵
如果你曾经接触过线性代数可能对这三个概念很熟悉,可能间隔时间太久有些模糊,下面再帮大家温习一下:
方差(Variance)一般用来描述样本集合中的各个样本点到样本均值的差的平方和的均值:
协方差(Covariance)目的是度量两个变量(只能为两个)线性相关的程度:
为可以说明两个变量线性无关,但不能证明两个变量相互独立,当 时,二者呈正相关, 时,二者呈负相关。
协方差矩阵就是由两两变量之间的协方差组成,有以下特点:
协方差矩阵可以处理多维度问题。
协方差矩阵是一个对称的矩阵,而且对角线是各个维度上的方差。
协方差矩阵计算的是不同维度之间的协方差,而不是不同样本之间的。
样本矩阵中若每行是一个样本,则每列为一个维度。
假设数据是3维的,那么对应协方差矩阵为:
这里简要概括一下协方差矩阵是怎么求得的,假设一个数据集有3维特征、每个特征有m个变量,这个数据集对应的数据矩阵如下:
若假设他们的均值都为0,可以得到下面等式:

可以看到对角线上为每个特征方差,其余位置为两个特征之间的协方差, 求得的就为协方差矩阵。
这里叙述的有些简略,感兴趣的小伙伴可以自行查询相关知识。
特征值和特征向量
得到了数据矩阵的协方差矩阵,下面就应该求协方差矩阵的特征值和特征向量,先了解一下这两个概念,如果一个向量v是矩阵A的特征向量,那么一定存在下列等式:
其中A可视为数据矩阵对应的协方差矩阵, 是特征向量v的特征值。数据矩阵的主成分就是由其对应的协方差矩阵的特征向量,按照对应的特征值由大到小排序得到的。最大的特征值对应的特征向量就为第一主成分,第二大的特征值对应的特征向量就为第二主成分,依次类推,如果由n维映射至k维就截取至第k主成分。
实例操作
通过上述部分总结一下PCA降维操作的步骤:
去均值化
依据数据矩阵计算协方差矩阵
计算协方差矩阵的特征值和特征向量
将特征值从大到小排序
保留前k个特征值对应的特征向量
将原始数据的n维映射至k维中
公式手推降维
原始数据集矩阵,每行代表一个特征:
对每个特征去均值化:
计算对应的协方差矩阵:
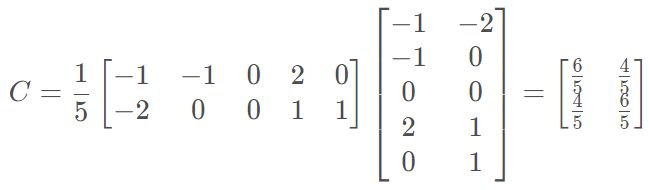
依据协方差矩阵计算特征值和特征向量,套入公式:
拆开计算如下:

可以求得两特征值:
,
当 时,对应向量应该满足如下等式:
对应的特征向量可取为:
同理当 时,对应特征向量可取为:
这里我就不对两个特征向量进行标准化处理了,直接合并两个特征向量可以得到矩阵P:
选取大的特征值对应的特征向量乘以原数据矩阵后可得到降维后的矩阵A:

综上步骤就是通过PCA手推公式实现二维降为一维的操作。
numpy实现降维
import numpy as np
def PCA(X,k):
'''
X:输入矩阵
k:需要降低到的维数
'''
X = np.array(X) #转为矩阵
sample_num ,feature_num = X.shape #样本数和特征数
meanVals = np.mean(X,axis = 0) #求每个特征的均值
X_mean = X-meanVals #去均值化
Cov = np.dot(X_mean.T,X_mean)/sample_num #求协方差矩阵
feature_val,feature_vec = np.linalg.eig(Cov)
#将特征值和特征向量打包
val_sort = [(np.abs(feature_val[i]),feature_vec[:,i]) for i in range(feature_num)]
val_sort.sort(reverse=True) #按特征值由大到小排列
#截取至前k个特征向量组成特征矩阵
feature_mat = [feature[1] for feature in val_sort[:k]]
# 降n维映射至k维
PCA_mat = np.dot(X_mean,np.array(feature_mat).T)
return PCA_mat
if __name__ == "__main__":
X = [[1, 1], [1, 3], [2, 3], [4, 4], [2, 4]]
print(PCA(X,1))
运行截图如下:
 代码部分就是公式的套用,每一步后都有注释,不再过多解释。可以看到得到的结果和上面手推公式得到的有些出入,上文曾提过特征向量是可以随意缩放的,这也是导致两个结果不同的原因,可以在运行代码时打印一下特征向量feature_vec,观察一下这个特点。
代码部分就是公式的套用,每一步后都有注释,不再过多解释。可以看到得到的结果和上面手推公式得到的有些出入,上文曾提过特征向量是可以随意缩放的,这也是导致两个结果不同的原因,可以在运行代码时打印一下特征向量feature_vec,观察一下这个特点。
sklearn库实现降维
from sklearn.decomposition import PCA
import numpy as np
X = [[1, 1], [1, 3], [2, 3], [4, 4], [2, 4]]
X = np.array(X)
pca = PCA(n_components=1)
PCA_mat = pca.fit_transform(X)
print(PCA_mat)
这里只说一下参数n_components,如果输入的是整数,代表数据集需要映射的维数,比如输入3代表最后要映射至3维;如果输入的是小数,则代表映射的维数为原数据维数的占比,比如输入0.3,如果原数据20维,就将其映射至6维。
总结
上面用到的数据集特别简单,建议在练习的时候用一些特征较多的数据集,可以利用图像绘制一下各个主成分占总方差的比例,很直观的一个结果就是排序较前的一些主成分占比特别大,最后一些占比可能只有零点几,这也是我们上文叙述的内容最基本的原理。
本文参考博客:
1.https://blog.csdn.net/hustqb/article/details/78394058 2.https://blog.csdn.net/program_developer/article/details/80632779 3.https://blog.csdn.net/HLBoy_happy/article/details/77146012
End
![]()
推荐阅读:
别再暴力匹配字符串了,高效的KMP才是真的香!
回溯法、分支限界法两种思想帮你轻松搞定旅行售货员问题(TSP)
请查收这份"位运算"的装逼指南
