VM虚拟机下的Hadoop的集群环境搭建
本文出自https://shuwoom.com博客,欢迎访问!
一、实验环境:
1、Win10pc
2、VMware
3、xftp6
4、所需安装包
![]()
![]()
![]()
二、安装Centos系统并配置网络:(以下内容均以root用户进行操作)
1、新建虚拟机,使用ISO安装系统:

2、进行时间地区还有服务网络设置:

3、进行永和和root的密码设置:

4、NAT网络配置:
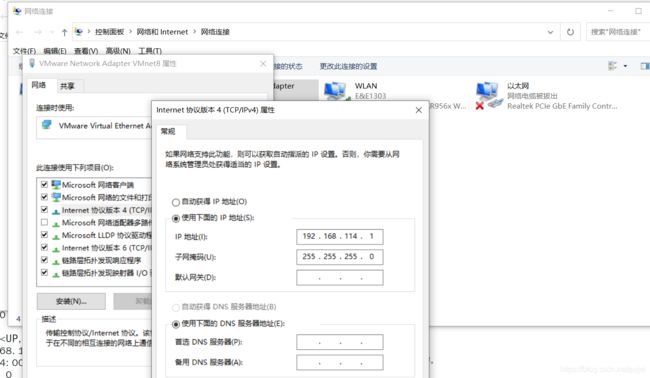




vim /etc/sysconfig/network-scripts/ifcfg-ens33(打开网卡配置文件,配置静态网络)

service network restart(重启网卡)
测试网络:

同上面的一致,创建其他的虚拟机,也可以进行克隆
三、四台主机的网络配置和主机名绑定:
1、Centos7.6 64 VM
hadoop 192.168.114.150
hadoop1 192.168.114.151
hadoop2 192.168.114.152
hadoop3 192.168.114.153
2、IP地址与主机名的绑定
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop
NTPSERVERARGS=iburst
同理,修改hadoop1、hadoop2、hadoop3的HOSTNAME为各自的主机名
vim /etc/hosts(打开/etc/host文件,进行IP和主机名的绑定)
192.168.114.150 hadoop
192.168.114.151 hadoop1
192.168.114.152 hadoop2
192.168.114.153 hadoop3
每一个主机上都要进行上述配置,然后reboot即可
3、测试四台主机(hadoop、hadoop1、hadoop2、hadoop3)之间是否能互通

四、SSH免密登录:
1、查看是否有隐藏文件.ssh(没有就创建一个mkdir .ssh)
2、ssh-keygen -t rsa(输完命令敲击三下回车)
命令的作用是在.ssh文件夹下生成id_dsa和id_ds.pub两个文件,这私钥和公钥
3、cp id_rsa.pub authorized_keys(将公钥加入到用于认证的公钥文件中)
4、验证是否可以免密登录本主机

5、将authorized_keys文件分别复制到其他三个主机上(先去查看其他主机上有没有.ssh文件,没有先创建,否则无法copy)
scp authorized_keys root@hadoop1:.ssh/

6、在hadoop上验证是否可以免密登录

五、JDK的安装以及JAVA环境变量的配置:
1、先去检查一下系统中有没有默认安装的JDK
java -version

2、安装并配置使用新的JDK
(1)使用Xftp将hadoop-1.1.2.tar.gz和jdk-7u80-linux-x64.rpm传输到hadoop主机下的/usr/local/目录下
(2)解压jdk-7u80-linux-x64.rpm文件(解压完默认是放在/usr/java/文件夹下的)
chmod +x jdk-7u80-linux-x64.rpm
rpm -ivh jdk-7u80-linux-x64.rpm
mv jdk1.7.0_80/ /usr/local/jdk
(3)配置JAVA环境
vim /etc/profile
#set java environment
export JAVA_HOME=/usr/local/jdk
export PATH=.:$JAVA_HOME/bin:$PATH
source /etc/profile
(4)检查一下JDK是否安装成功
java -version

(5)将/etc/profile文件复制到其他的三个主机上
scp /etc/profile root@hadoop1:/etc/
scp /etc/profile root@hadoop2:/etc/
scp /etc/profile root@hadoop3:/etc/

(6)将/usr/local/jdk/文件夹复制到其他三台主机的/usr/local/下
scp -r /usr/local/jdk/ root@hadoop1:/usr/local/
scp -r /usr/local/jdk/ root@hadoop2:/usr/local/
scp -r /usr/local/jdk/ root@hadoop3:/usr/local/
(7)检查其他三台主机的JDK是否安装成功
六、安装配置Hadoop:
1、安装解压hadoop
tar -zxvf hadoop-1.1.2.tar.gz
mv hadoop-1.1.2 hadoop(重命名)
2、配置Hadoop
进入hadoop下的conf文件夹下
(1)指定jdk安装位置,(Hadoop-env.sh)
export JAVA_HOME=/usr/local/jdk
(2)配置HDFS地址和端口(core-site.xml)
fs.default.name
hdfs://hadoop:9000
hadoop.tmp.dir
/usr/local/hadoop/tmp
(3)hdfs-site.xml(子节点有几个就写几)
dfs.replication
2
(4)配置MapReduce文件(配置JobTracker的地址和端口)
mapred.job.tracker
hadoop:9001
(5)配置master和slaves文件
hadoop(master)
hadoop1(slaves)
hadoop2(slaves)
hadoop3(slaves)
(6)将hadoop文件复制到其他三台机器的/usr/local/目录下
scp -r /usr/local/hadoop/ root@hadoop1:/usr/local/
scp -r /usr/local/hadoop/ root@hadoop2:/usr/local/
scp -r /usr/local/hadoop/ root@hadoop3:/usr/local/
(7)配置环境
vim /etc/profile
source /etc/profile(. /etc/profile)
(8)将配置文件复制到其他三台机器上同样的目录下
scp /etc/profile root@hadoop1:/etc/
scp /etc/profile root@hadoop2:/etc/
scp /etc/profile root@hadoop3:/etc/

3、启动Hadoop
hadoop:
hadoop namenode -format

start-all.sh

jps

hadoop1:

hadoop2:

hadoop3:

截至到现在,Hadoop集群搭建完成,可以通过桌面上的浏览器访问localhost:50030(mapreduce的web页面)和localhost:50070(HDFS的web页面)进行查看。
备注:刚开始接触Hadoop,很多东西不是特别清楚,欢迎大家指正,也希望可以和大家一起学习交流!