大数据集群搭建
目录
一、安装 jdk
二、安装 tomcat
三、安装 mysql
四、搭建集群 (三台)
4.1 新增 linux 系统
4.2 关闭防火墙
4.3 关闭 selinux
4.4 配置 hosts 文件
4.5 scp 远程文件拷贝
4.5.1 本地机器内容拷贝到远程机器
4.5.2 远程机器内容拷贝到本地机器
4.6 ssh 远程登录
4.6.1 使用 ssh 基于密码的远程登录 (了解)
4.6.2 使用 ssh 基于秘钥的免密码登录 (掌握)
4.7 三台机器时钟同步
4.7.1 同步互联网时间
4.7.2 跟内网某台机器同步时间
一、安装 jdk
第一步: 查看当前系统中是否已安装了 JDK
[root@hadoop01 ~]# java -version
java version "1.7.0_261"
OpenJDK Runtime Environment (rhel-2.6.22.2.el7_8-x86_64 u261-b02)
OpenJDK 64-Bit Server VM (build 24.261-b02, mixed mode)第二步: 查询已安装的 JDK
[root@hadoop01 ~]# rpm -qa | grep java
java-1.8.0-openjdk-1.8.0.262.b10-1.el7.x86_64
javapackages-tools-3.4.1-11.el7.noarch
tzdata-java-2020a-1.el7.noarch
java-1.7.0-openjdk-headless-1.7.0.261-2.6.22.2.el7_8.x86_64
java-1.7.0-openjdk-1.7.0.261-2.6.22.2.el7_8.x86_64
python-javapackages-3.4.1-11.el7.noarch第三步: 卸载 Linux 系统提供的 JDK
[root@hadoop01 ~]# yum remove *openjdk*第四步: 下载 JDK 安装包
下载链接: Java Downloads | Oracle

官网下载需要登录, 使用这个网站的账户和密码进行登录下载:
oracle.com passwords - BugMeNot
第五步: 上传安装包到 /export/software, 解压到 /export/servers
[root@hadoop01 ~]# mkdir -p /export/software # 创建保存软件包目录
[root@hadoop01 ~]# mkdir -p /export/servers # 创建安装软件目录
# 将压缩包解压到指定目录
[root@hadoop01 ~]# tar -zxvf /export/software/jdk-8u341-linux-x64.tar.gz -C /export/servers/第六步: 将 JDK 路径放到环境变量中
目的: 为了能在任何目录下都可以使用 javac 和 java
(1). 新建 /etc/profile.d/my_env.sh 文件, 添加内容后保存退出
[root@hadoop01 ~]# vim /etc/profile.d/my_env.sh
# 添加以下内容
#JAVA_HOME
export JAVA_HOME=/export/servers/jdk1.8.0_341
export PATH=$PATH:$JAVA_HOME/bin(2). source 一下 /etc/profile 文件, 让新的环境变量 PATH 生效
[root@hadoop01 ~]# source /etc/profile第七步: 测试是否安装成功
[root@hadoop01 ~]# java -version
java version "1.8.0_341"
Java(TM) SE Runtime Environment (build 1.8.0_341-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.341-b10, mixed mode)二、安装 tomcat
第一步: 下载 tomcat 安装包
下载链接: Apache Tomcat® - Apache Tomcat 9 Software Downloads

第二步: 创建上传的目录和安装目录
[root@hadoop01 ~]# mkdir -p /export/software # 文件上传目录
[root@hadoop01 ~]# mkdir -p /export/servers # 文件安装目录第三步: 上传安装包到 /export/software 目录下

第四步: 将安装包解压到 /export/servers 目录下
[root@hadoop01 ~]# tar -zxvf /export/software/apache-tomcat-9.0.67.tar.gz -C /export/servers/第五步: 启动 tomcat
[root@hadoop01 ~]# cd /export/servers/apache-tomcat-9.0.67/bin/ # 进入到bin目录下
[root@hadoop01 bin]# ./startup.sh # 启动
Using CATALINA_BASE: /export/servers/apache-tomcat-9.0.67
Using CATALINA_HOME: /export/servers/apache-tomcat-9.0.67
Using CATALINA_TMPDIR: /export/servers/apache-tomcat-9.0.67/temp
Using JRE_HOME: /usr
Using CLASSPATH: /export/servers/apache-tomcat-9.0.67/bin/bootstrap.jar:/export/servers/apache-tomcat-9.0.67/bin/tomcat-juli.jar
Using CATALINA_OPTS:
Tomcat started.提示: 防火墙要么关闭, 要么开放 tomcat 指定的端口, 否则无法访问
第六步: 测试
访问 http://192.168.224.129:8080/
这里的 ip 地址是自己虚拟机的 ip 地址, 出现以下界面说明成功

三、安装 mysql
第一步: 查询系统自带的 mysql
rp[root@hadoop01 ~]# rpm -qa | grep mariadb
mariadb-libs-5.5.68-1.el7.x86_64第二步: 卸载系统自带的 mysql
[root@hadoop01 ~]# rpm -e --nodeps mariadb-libs第三步: 下载 mysql 安装包
下载链接: MySQL :: Download MySQL Community Server (Archived Versions)

第四步: 创建 mysql 安装包存放点
[root@hadoop01 ~]# mkdir -p /export/software/mysql第五步: 将 mysql 安装包上传到 /export/software/mysql 下解压
上传:

解压:
[root@hadoop01 ~]# tar -xvf /export/software/mysql/mysql-8.0.28-1.el7.x86_64.rpm-bundle.tar
mysql-community-client-8.0.28-1.el7.x86_64.rpm
mysql-community-client-plugins-8.0.28-1.el7.x86_64.rpm
mysql-community-common-8.0.28-1.el7.x86_64.rpm
mysql-community-devel-8.0.28-1.el7.x86_64.rpm
mysql-community-embedded-compat-8.0.28-1.el7.x86_64.rpm
mysql-community-icu-data-files-8.0.28-1.el7.x86_64.rpm
mysql-community-libs-8.0.28-1.el7.x86_64.rpm
mysql-community-libs-compat-8.0.28-1.el7.x86_64.rpm
mysql-community-server-8.0.28-1.el7.x86_64.rpm
mysql-community-test-8.0.28-1.el7.x86_64.rpm第六步: 执行安装
注意: 包与包存在依赖关系, 需要按照顺序安装

第七步: 初始化 mysql
[root@hadoop01 ~]# mysqld --initalize --console第八步: 更改所属组
[root@hadoop01 ~]# chown -R mysql:mysql /var/lib/mysql第九步: 启动 mysql
[root@hadoop01 ~]# systemctl start mysqld第十步: 查看生产的临时 root 密码
![]()
第十一步: 登录, 修改临时密码
登录
[root@hadoop01 ~]# mysql -u root -p
Enter password: # 这里输入刚刚获取到的临时密码修改临时密码
mysql> alter user 'root'@'localhost' identified by 'Titanfall2.';
Query OK, 0 rows affected (0.00 sec)第十二步: 授权远程登录
# 授权
mysql> create user 'root'@'%' identified by 'Titanfall2.';
Query OK, 0 rows affected (0.01 sec)
mysql> grant all on *.* to 'root'@'%';
Query OK, 0 rows affected (0.00 sec)
mysql> alter user 'root'@'%' identified with mysql_native_password by 'Titanfall2.';
Query OK, 0 rows affected (0.00 sec)
# 立即生效
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)第十三步: 建议设置为开机自启动服务
[root@hadoop01 ~]# systemctl enable mysqld四、搭建集群 (三台)
4.1 新增 linux 系统
第一步: 克隆虚拟机 (克隆前将虚拟机关机)




克隆完成

第二步: 修改主机名
vim /etc/hostname修改后保存退出, 重启生效
第三步: 修改网卡信息
vim /etc/sysconfig/network-scripts/ifcfg-ens33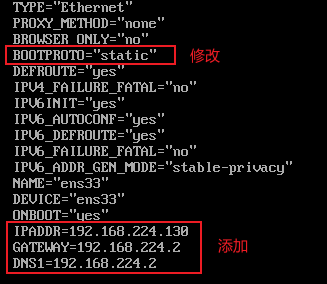
修改完成后保存退出
systemctl restart network # 重启网卡4.2 关闭防火墙
三台机器关闭防火墙
内网环境安全性比较高, 防火墙开启会影响效率, 所以关闭防火墙
三台机器执行以下命令 (root 用户来执行)
systemctl stop firewalld # 临时关闭防火墙
systemctl disable firewalld # 关闭防火墙自启4.3 关闭 selinux
三台机器关闭 selinux
vim /etc/selinux/config
4.4 配置 hosts 文件
三台机器配置 hosts 文件
vim /etc/hosts
修改完成后, 重启系统生效
4.5 scp 远程文件拷贝
scp 是 remote file copy program 的缩写, scp 是远程文件拷贝命令
4.5.1 本地机器内容拷贝到远程机器

4.5.1.1 拷贝文件
1. 语法格式: scp local_file remote_username@remote_ip:remote_folder
2. 案例实操: 将 hadoop01 的三个文件复制到 hadoop02 机器的 /root 目录下
准备工作: 在 hadoop01 的 root 目录下创建三个 .txt 文件
[root@hadoop01 ~]# touch 1.txt
[root@hadoop01 ~]# touch 2.txt
[root@hadoop01 ~]# touch 3.txt拷贝文件:
[root@hadoop01 ~]# scp /root/1.txt [email protected]:/root/ # 方式一
[root@hadoop01 ~]# scp /root/2.txt root@hadoop02:/root/ # 方式二
[root@hadoop01 ~]# scp /root/3.txt hadoop02:/root/ # 方式三4.5.1.2 拷贝目录
1. 语法格式: scp -r local_folder remote_username@remote_ip:remote_folder
2. 案例实操: 将 hadoop01 的三个目录复制到 hadoop03 机器的 /root 目录下
准备工作: 在 hadoop01 的 root 目录下创建三个目录
[root@hadoop01 ~]# mkdir -p aa/bb/cc
[root@hadoop01 ~]# mkdir -p dd/ee/ff
[root@hadoop01 ~]# mkdir -p gg/hh/ii拷贝目录:
[root@hadoop01 ~]# scp -r /root/aa/bb/cc/ [email protected]:/root/
[root@hadoop01 ~]# scp -r /root/dd/ee/ff/ root@hadoop02:/root/
[root@hadoop01 ~]# scp -r /root/gg/hh/ii/ hadoop02:/root/4.5.2 远程机器内容拷贝到本地机器
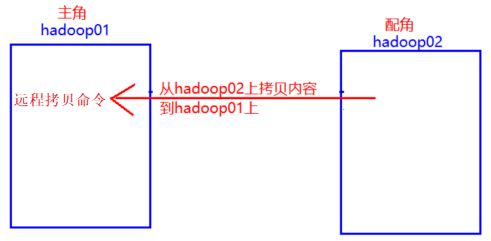
4.5.2.1 拷贝文件
1. 语法格式: remote_username@remote_ip:remote_file local_folder
2. 案例实操: 将 hadoop02 中 /root 目录下的 .txt 文件复制到 hadoop01 的 /root目录下
准备工作: 在 hadoop02 的 /root 目录下创建三个 .txt 文件
[root@hadoop02 ~]# touch a.txt
[root@hadoop02 ~]# touch b.txt
[root@hadoop02 ~]# touch c.txt拷贝文件:
[root@hadoop01 ~]# scp [email protected]:/root/a.txt /root/ # 方式一
[root@hadoop01 ~]# scp root@hadoop02:/root/b.txt /root/ # 方式二
[root@hadoop01 ~]# scp hadoop02:/root/c.txt /root/ # 方式三4.5.2.2 拷贝目录
1. 语法格式: scp -r remote_username@remote_ip:remote_folder local_folder
2. 案例实操: 将 hadoop02 中 /root 目录下的三个文件夹复制到 hadoop01 的 /root 目录下
准备工作: 在 hadoop02 的 /root 目录下创建三个文件夹
[root@hadoop02 ~]# mkdir a
[root@hadoop02 ~]# mkdir b拷贝目录:
[root@hadoop01 ~]# scp -r [email protected]:/root/a /root # 方式一
[root@hadoop01 ~]# scp -r hadoop02:/root/b /root # 方式二4.6 ssh 远程登录
4.6.1 使用 ssh 基于密码的远程登录 (了解)
1.命令
命令: ssh ip地址 含义: 远程登录到指定服务器上(必须知道正确的密码)
2.案例实操
在 hadoop01 机器上登录到 hadoop02 机器
[root@hadoop01 ~]# ssh hadoop02
root@hadoop02's password: 细节: 首次远程登录会询问 yes/no, 以后可能就不会了
4.6.2 使用 ssh 基于秘钥的免密码登录 (掌握)
1. 生成公钥和私钥
[root@hadoop01 ~]# ssh-keygen -t rsa # 执行这行命令后直接敲三个回车
[root@hadoop01 ~]# cd .ssh
[root@hadoop01 .ssh]# ls
id_rsa id_rsa.pub known_hosts # id_rsa (私钥)、id_rsa.pub (公钥)2. 将公钥拷贝到要免密登录的目标机器上
[root@hadoop01 .ssh]# ssh-copy-id hadoop01
[root@hadoop01 .ssh]# ssh-copy-id hadoop02
[root@hadoop01 .ssh]# ssh-copy-id hadoop033. 分别在 hadoop02 和 hadoop03 上设置 1、2 两步
4. .ssh 文件夹下 (~/.ssh) 的文件功能解释
| known_hosts | 记录 ssh 访问过计算机的公钥 (public key) |
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
5. 测试
hadoop01 免密登录 hadoop02、hadoop03
[root@hadoop01 ~]# ssh hadoop02
Last login: Sat Oct 1 15:00:05 2022 from hadoop01
[root@hadoop02 ~]# exit
登出
Connection to hadoop02 closed.
[root@hadoop01 ~]# ssh hadoop03
Last login: Sat Oct 1 15:00:15 2022 from hadoop024.7 三台机器时钟同步
4.7.1 同步互联网时间

| 命令 | 英文 | 含义 |
| ntpdate 互联网时间服务器地址 | Network Time Protocol | 同步时间 |
- 阿里云时钟同步服务器
-
ntpdate ntp4.aliyun.com
-
-
三台机器定时任务: 直接与阿里云服务器进行时钟同步
-
crontab -e */1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
-
4.7.2 跟内网某台机器同步时间
为了安全, 大数据集群的节点不允许连接外网

以 hadoop01 这台服务器的时间为准进行时钟同步
在此之前, 我们需要删除三台服务器的定时时钟同步任务
crontab -r第一步: htpd 服务
1. 确认是否安装了 ntpd 服务
[root@hadoop01 ~]# rpm -qa | grep ntpd
ntpdate-4.2.6p5-29.el7.centos.2.x86_64如果没有安装, 可以进行在线安装:
[root@hadoop01 ~]# yum -y install ntpd2. 启动 ntpd 服务
[root@hadoop01 ~]# systemctl start ntpd3. 设置 ntpd 服务开机启动
[root@hadoop01 ~]# systemctl enable ntpd第二步: 编辑 /etc/ntp.conf
1. 编辑 hadoop01 的 /etc/ntp.conf
[root@hadoop01 ~]# vim /etc/ntp.conf在文件中添加如下内容, 配置我们的时钟广播地址
# 假如时钟服务器ip地址为: 192.168.224.129
restrict 192.168.224.0 mask 255.255.255.0 nomodify notrap注释以下四行内容
# server 0.centos.pool.ntp.org iburst
# server 1.centos.pool.ntp.org iburst
# server 2.centos.pool.ntp.org iburst
# server 3.centos.pool.ntp.org iburst去掉以下内容的注释, 如果没有这两行内容, 那就自己加上
server 127.127.1.0 # localclock
fudge 127.127.1.0 stratum 10配置以下内容, 保证 BIOS 与系统时间同步
[root@hadoop01 ~]# vim /etc/sysconfig/ntpd添加一行内容: SYNC_HWLOCK=yes

重启 ntpd 服务
[root@hadoop01 ~]# systemctl restart ntpd注意: 如果更改 ntp 时钟服务器的时间, 也需要重启 ntpd 服务
第三步: 另外两台机器与第一台机器时间同步
- 手动同步时间
-
# ntpdate 后面写 ip地址也可以 [root@hadoop02 ~]# ntpdate hadoop01 [root@hadoop03 ~]# ntpdate hadoop01
-
- 定时任务同步时间
-
crontab -e # 添加以下任务 */1 * * * * /usr/sbin/ntpdate 192.168.224.129 - 注意: 如果报错
- 解决办法: 断开再连
-
systemctl stop ntpd
-