Hadoop离线_网站流量日志数据分析系统_数据入库
数据入库ETL
-
-
-
-
- 1.数据仓库设计
- 2.本项目中数据仓库的设计
- 3.创建 ODS 层数据表
- 4.导入 ODS 层数据
- 5.生成 ODS 层明细宽表
-
-
-
1.数据仓库设计
1.1维度建模概述
维度建模 (dimensional modeling) 是专门用于分析型数据库、数据仓库、数据集市建模(数据集市可以理解为是一种"小型数据仓库")的方法。
维度表 (dimension) 就是对数据按类别、区域等各个角度进行分析,比如有一个实例:今天下午白某在星巴克花40元喝了一杯星冰乐。以消费为主题对这段信息可以提取四个维度:时间维度 (今天下午)、地点维度 (星巴克)、价格维度 (40元)、商品维度 (星冰乐)。所以一般情况下维度表信息比较固定,且数据量小。
事实表 (fact table) 包含了与各维度表相关联的外键,并通过JOIN方式与维度表关联。事实表的度量通常是数值类型,且记录数会不断增加,表规模迅速增长。
数据仓库的主导功能是面向分析,以查询为主,不涉及数据更新操作,所以不需要严格遵守规范化设计原则。事实表的设计是以能够正确记录历史信息为准则,维度表的设计是以能够以合适的角度来聚合主题内容为准则。
1.2维度建模的三种模式
1.星型模式
星型模式 (Star Schema) 是以事实表为中心,所有的维度表直接连接在事实表上,像星星一样,是最常用的维度建模方式。
特点:
1.维度表只和事实表关联,维度表之间没有关联
2.每个维度表主键为单列,且该主键放置在事实表中,作为两边连接的外键
3.以事实表为核心,维表围绕核心呈星形分布

2.雪花模式
雪花模式 (Snowflake Schema) 是对星形模式的扩展。雪花模式的维度表可以拥有其他维度表的,虽然这种模型相比星型更规范一些,但是由于这种模型不太容易理解,维护成本比较高,而且性能方面需要关联多层维表,性能也比星型模型要低。所以一般不是很常用。

3.星座模型
星座模式是星型模式延伸而来,星型模式是基于一张事实表的,而星座模式是基于多张事实表的,而且共享维度信息。前面介绍的两种维度建模方法都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表也可能被多个事实表用到。在业务发展后期,绝大部分维度建模都采用的是星座模式。
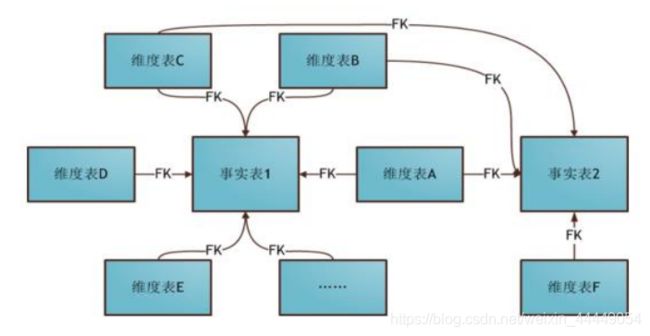
2.本项目中数据仓库的设计
2.1事实表设计


注意:使用星型模型
2.2维度表设计
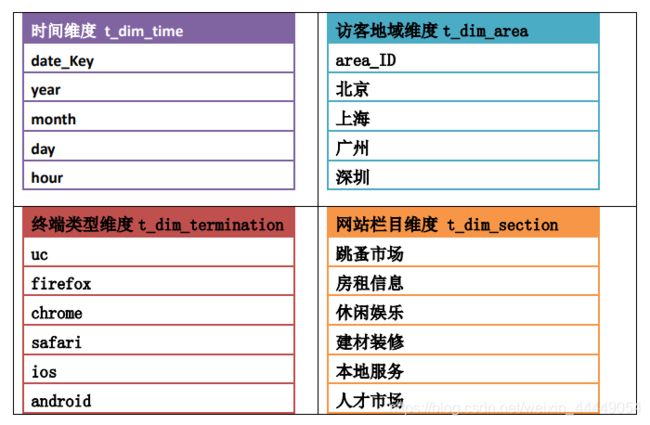
3.创建 ODS 层数据表
创建数据库:create database weblog;
3.1原始日志数据表
create table ods_weblog_origin(
valid string,
remote_addr string,
remote_user string,
time_local string,
request string,
status string,
body_bytes_sent string,
http_referer string,
http_user_agent string)
partitioned by (datestr string)
row format delimited
fields terminated by '\001';
3.2点击流模型 pageviews 表
create table ods_click_pageviews(
session string,
remote_addr string,
remote_user string,
time_local string,
request string,
visit_step string,
page_staylong string,
http_referer string,
http_user_agent string,
body_bytes_sent string,
status string)
partitioned by (datestr string)
row format delimited
fields terminated by '\001';
3.3点击流 visit 模型表
create table ods_click_stream_visit(
session string,
remote_addr string,
inTime string,
outTime string,
inPage string,
outPage string,
referal string,
pageVisits int)
partitioned by (datestr string)
row format delimited
fields terminated by '\001';
4.导入 ODS 层数据
1.导入清洗结果数据到贴源数据表ods_weblog_originLOAD DATA LOCAL inpath '/export/servers/weblog/weblogout' overwrite INTO TABLE ods_weblog_origin PARTITION ( datestr = '20130918' );
LOAD DATA LOCAL inpath '/export/servers/weblog/pageView' overwrite INTO TABLE ods_click_pageviews PARTITION ( datestr = '20130918' );
LOAD DATA LOCAL inpath '/export/servers/weblog/visit' overwrite INTO TABLE ods_click_stream_visit PARTITION ( datestr = '20130918' );
5.生成 ODS 层明细宽表
5.1需求实现
整个数据分析的过程是按照数据仓库的层次分层进行的,总体来说,是从
ODS 原始数据中整理出一些中间表(比如,为后续分析方便,将原始数据中的时
间、url 等非结构化数据作结构化抽取,将各种字段信息进行细化,形成明细表),
然后再在中间表的基础之上统计出各种指标数据。
5.2 ETL 实现
建明细表 ods_weblog_detail:
drop table ods_weblog_detail;
create table ods_weblog_detail(
valid string, --有效标识
remote_addr string, --来源 IP
remote_user string, --用户标识
time_local string, --访问完整时间
daystr string, --访问日期
timestr string, --访问时间
month string, --访问月
day string, --访问日
hour string, --访问时
request string, --请求的 url
status string, --响应码
body_bytes_sent string, --传输字节数
http_referer string, --来源 url
ref_host string, --来源的 host
ref_path string, --来源的路径
ref_query string, --来源参数 query
ref_query_id string, --来源参数 query 的值
http_user_agent string --客户终端标识
)
partitioned by(datestr string);
插入数据:
INSERT INTO TABLE ods_weblog_detail PARTITION ( datestr = '20130918' )
SELECT c.valid,c.remote_addr,c.remote_user,c.time_local,
substring( c.time_local, 0, 10 ) AS daystr,
substring( c.time_local, 12 ) AS timestr,
substring( c.time_local, 6, 2 ) AS month,
substring( c.time_local, 9, 2 ) AS day,
substring( c.time_local, 11, 3 ) AS hour,
c.request,c.status,c.body_bytes_sent,c.http_referer,c.ref_host,c.ref_path,c.ref_query,c.ref_query_id,c.http_user_agent
FROM (
SELECT a.valid,a.remote_addr,a.remote_user,a.time_local,a.request,a.status,a.body_bytes_sent,a.http_referer,a.http_user_agent,
b.ref_host,b.ref_path,b.ref_query,b.ref_query_id
FROM ods_weblog_origin a
LATERAL VIEW parse_url_tuple ( regexp_replace ( http_referer, "\"", "" ),
'HOST','PATH','QUERY','QUERY:id' ) b
AS ref_host,ref_path,ref_query,ref_query_id ) c;
或者分两步写:
1.抽取refer_url到中间表 t_ods_tmp_referurl
CREATE TABLE t_ods_tmp_referurl AS
SELECT a.*,b.*
FROM ods_weblog_origin a
LATERAL VIEW parse_url_tuple (
regexp_replace ( http_referer, "\"", "" ),
'HOST','PATH','QUERY','QUERY:id' ) b
AS host,path,query,query_id;
2.抽取转换time_local字段到中间表明细表 t_ods_tmp_detail
CREATE TABLE t_ods_tmp_detail AS
SELECT b.*,
substring( time_local, 0, 10 ) AS daystr,
substring( time_local, 12 ) AS timestr,
substring( time_local, 6, 2 ) AS month,
substring( time_local, 9, 2 ) AS day,
substring( time_local, 11, 3 ) AS hour
FROM t_ods_tmp_referurl b;