Intel Distiller工具包-量化实现2
本系列文章
Intel Distiller工具包-量化实现1
Intel Distiller工具包-量化实现2
回顾
- 上一篇文章中介绍了Distiller及Quantizer基类,基类定义了重要的变量,如replacement_factory(dict,用于记录待量化module对应的wrapper);此外定义了量化流程,包括 预处理(BN折叠,激活优化等)、量化模块替换、后处理 等主要步骤;
- 本文介绍继承自Quantizer的子类量化器,包括
- PostTrainLinearQuantizer(本文)
- QuantAwareTrainRangeLinearQuantizer(后续)
- PACTQuantizer(后续)
- NCFQuantAwareTrainQuantizer(后续)
- 本文代码也挺多的,由于没法全部贴出来,有些地方说的不清楚的,还请读者去参考源码;
PostTrainLinearQuantizer
- 后训练量化器;对已训练好的模型进行量化,需要先使用少量输入收集模型内部输入、输出、权重的统计数据;
- PostTrainLinearQuantizer的类定义如下:主要内容在构造函数里,下面介绍;其他就是加了预处理(BN折叠、激活层优化)等;
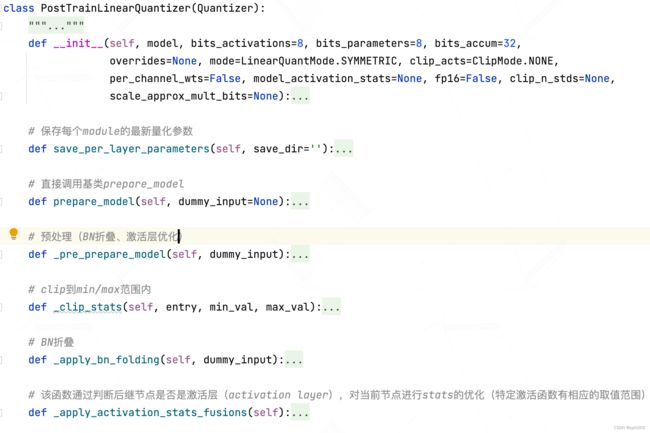
- 构造函数:重点在这



- 构造函数中,前面都是检查和默认设置(如量化模式检查、clip模式检查、是否有统计数据、默认量化设置等);直到下面这段代码,才是PostTrainLinearQuantizer核心
#### PART1-参数层的量化:使用固定的 RangeLinearQuantParamLayerWrapper #### self.replacement_factory[nn.Conv2d] = replace_param_layer self.replacement_factory[nn.Conv3d] = replace_param_layer self.replacement_factory[nn.Linear] = replace_param_layer #### PART2-非参数层的量化:使用相应的Wrapper,使用functools partial #### # concat:固定wrapper_type为RangeLinearQuantConcatWrapper factory_concat = partial( replace_non_param_layer, RangeLinearQuantConcatWrapper) # add:固定wrapper_type为RangeLinearQuantEltwiseAddWrapper factory_eltwiseadd = partial( replace_non_param_layer, RangeLinearQuantEltwiseAddWrapper) # dot-product:固定wrapper_type为RangeLinearQuantEltwiseMultWrapper factory_eltwisemult = partial( replace_non_param_layer, RangeLinearQuantEltwiseMultWrapper) # matrix-mul:固定wrapper_type为RangeLinearQuantMatmulWrapper factory_matmul = partial( replace_non_param_layer, RangeLinearQuantMatmulWrapper) update_wrapper(factory_concat, replace_non_param_layer) # 从参数2的对象 取内置参数 覆盖 参数1的对象对应参数 update_wrapper(factory_eltwiseadd, replace_non_param_layer) update_wrapper(factory_eltwisemult, replace_non_param_layer) update_wrapper(factory_matmul, replace_non_param_layer) self.replacement_factory[distiller.modules.Concat] = factory_concat # factory_concat(Concat, ...) self.replacement_factory[distiller.modules.EltwiseAdd] = factory_eltwiseadd self.replacement_factory[distiller.modules.EltwiseMult] = factory_eltwisemult self.replacement_factory[distiller.modules.Matmul] = factory_matmul self.replacement_factory[distiller.modules.BatchMatmul] = factory_matmul # =============================================== #### PART3-embedding层的量化:#### self.replacement_factory[nn.Embedding] = replace_embedding - 正如代码注释所述,代码分别对 可量化参数层、非参数层、embedding层进行量化设置
- 参数层:
- 以nn.Conv2d为例:self.replacement_factory[nn.Conv2d] = replace_param_layer
- 表示nn.Conv2d这个module会被replace_param_layer生成的量化版本module替换掉
- 我们来看看replace_param_layer是什么样的?
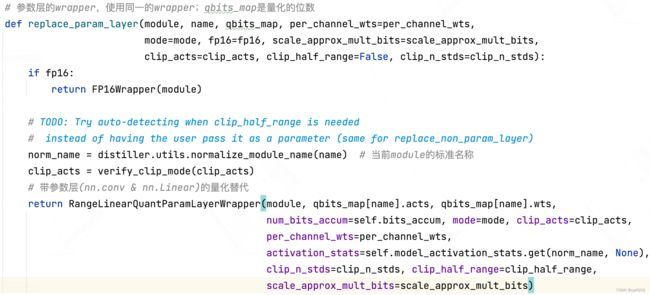
- 可以看到replace_param_layer在对module(此处指nn.Conv2d)封装时,其实返回的是RangeLinearQuantParamLayerWrapper对象(它是一个nn.Module,即新module替换旧module);所以我们再来看看这个wrapper对象是如何实现的;
- RangeLinearQuantParamLayerWrapper继承自RangeLinearQuantWrapper,需要先看看基类RangeLinearQuantWrapper的定义:

- 重点看一下forward函数:

- RangeLinearQuantParamLayerWrapper需要根据基类RangeLinearQuantWrapper的定义和自身需求实现相关函数,主要是quantized_forward和get_accum_to_output_re_quantization_params;具体定义如下
# 定义了参数层量化的方式 class RangeLinearQuantParamLayerWrapper(RangeLinearQuantWrapper): """ Linear range-based quantization wrappers for layers with weights and bias (namely torch.nn.ConvNd and torch.nn.Linear) Assume: x_q = round(scale_x * x_f) - zero_point_x Hence: x_f = 1/scale_x * x_q + zero_point_x # 根据下面写法,应该是 1/scale_x * (x_q + zero_point_x) (And the same for y_q, w_q and b_q) So, we get: (use "zp" as abbreviation for zero_point) y_f = x_f * w_f + b_f # 以下除第一步外均省略round,注意中括号中,bias是作为re-quant-bias存在,也就是实现时是round()-0 y_q = round(scale_y * y_f) - zp_y = scale_y * (x_f * w_f + b_f) - zp_y = scale_y scale_x * scale_w = ------------------- * [(x_q + zp_x) * (w_q + zp_w) + ------------------- * (b_q + zp_b)] - zp_y scale_x * scale_w scale_b Args: wrapped_module (torch.nn.Module): Module to be wrapped num_bits_acts (int): Number of bits used for inputs and output quantization num_bits_params (int): Number of bits used for parameters (weights and bias) quantization num_bits_accum (int): Number of bits allocated for the accumulator of intermediate integer results mode (LinearQuantMode): Quantization mode to use (symmetric / asymmetric-signed/unsigned) clip_acts (ClipNode): See RangeLinearQuantWrapper per_channel_wts (bool): Enable quantization of weights using separate quantization parameters per output channel activation_stats (dict): See RangeLinearQuantWrapper clip_n_stds (int): See RangeLinearQuantWrapper clip_half_range (bool) : See RangeLinearQuantWrapper scale_approx_mult_bits (int): See RangeLinearQuantWrapper(是否使用整型处理scale) """ def __init__(self, wrapped_module, num_bits_acts, num_bits_params, num_bits_accum=32, mode=LinearQuantMode.SYMMETRIC, clip_acts=ClipMode.NONE, per_channel_wts=False, activation_stats=None, clip_n_stds=None, clip_half_range=False, scale_approx_mult_bits=None): super(RangeLinearQuantParamLayerWrapper, self).__init__(wrapped_module, num_bits_acts, num_bits_accum, mode, clip_acts, activation_stats, clip_n_stds, clip_half_range, scale_approx_mult_bits) if not isinstance(wrapped_module, (nn.Conv2d, nn.Conv3d, nn.Linear)): raise ValueError(self.__class__.__name__ + ' can wrap only Conv2D, Conv3D and Linear modules') self.num_bits_params = num_bits_params # 参数量化bits self.per_channel_wts = per_channel_wts # 权重是否逐通道量化 # 获取量化范围(根据量化模式)sign: [-128,127] unsign: [0, 255] self.params_min_q_val, self.params_max_q_val = get_quantized_range( num_bits_params, signed=mode != LinearQuantMode.ASYMMETRIC_UNSIGNED) # Quantize weights - overwrite FP32 weights(获取当前op权重weights的量化参数) w_scale, w_zero_point = _get_quant_params_from_tensor(wrapped_module.weight, num_bits_params, self.mode, per_channel=per_channel_wts) # 添加一个伪属性fake-attr,可保存但不参与参数更新 self.register_buffer('w_scale', w_scale) self.register_buffer('w_zero_point', w_zero_point) # 量化权重(weight.data)并且替换(inplace=True),注意要clamp(另一种方式是提前将x、w都clamp到规定的范围内) linear_quantize_clamp(wrapped_module.weight.data, self.w_scale, self.w_zero_point, self.params_min_q_val, self.params_max_q_val, inplace=True) self.has_bias = hasattr(wrapped_module, 'bias') and wrapped_module.bias is not None device = self.w_scale.device # 当前module是否有统计数据并且有input if self.preset_act_stats: self.in_0_scale = self.in_0_scale.to(device) # 只使用第一个input的scale self.register_buffer('accum_scale', self.in_0_scale * self.w_scale) if self.per_channel_wts: # TODO how? self.accum_scale = self.accum_scale.squeeze(dim=-1) else: self.accum_scale = 1 # Quantize bias self.has_bias = hasattr(wrapped_module, 'bias') and wrapped_module.bias is not None if self.has_bias: if self.preset_act_stats: # 如果accu_scale可以根据统计数据得到,则令bias_scale==accu_scale,bias_zp==0,量化范围也来自accu # 注意这里的量化方式,是根据doc里的公式设计的;此外,bias根据accum的量化范围进行clamp linear_quantize_clamp(wrapped_module.bias.data, self.accum_scale.squeeze(), 0, self.accum_min_q_val, self.accum_max_q_val, inplace=True) else: # 否则使用bias自己的scale和zp和通用量化范围 b_scale, b_zero_point = _get_quant_params_from_tensor(wrapped_module.bias, num_bits_params, self.mode) self.register_buffer('b_scale', b_scale) self.register_buffer('b_zero_point', b_zero_point) # TODO 注意inplace=False,dynamic requantize,why? base_b_q = linear_quantize_clamp(wrapped_module.bias.data, self.b_scale, self.b_zero_point, self.params_min_q_val, self.params_max_q_val) # Dynamic ranges - save in auxiliary buffer, requantize each time based on dynamic input scale factor self.register_buffer('base_b_q', base_b_q) # A flag indicating that the simulated quantized weights are pre-shifted. for faster performance. # In the first forward pass - `w_zero_point` is added into the weights, to allow faster inference, # and all subsequent calls are done with these shifted weights. # Upon calling `self.state_dict()` - we restore the actual quantized weights. # i.e. is_simulated_quant_weight_shifted = False self.register_buffer('is_simulated_quant_weight_shifted', torch.tensor(0, dtype=torch.uint8, device=device)) def state_dict(self, destination=None, prefix='', keep_vars=False): if self.is_simulated_quant_weight_shifted: # We want to return the weights to their integer representation: # 根据doc,weight要加上w_zp,利用is_simulated_quant_weight_shifted标记;保存的时候恢复到真实的weight self.wrapped_module.weight.data -= self.w_zero_point self.is_simulated_quant_weight_shifted.sub_(1) # i.e. is_simulated_quant_weight_shifted = False return super(RangeLinearQuantParamLayerWrapper, self).state_dict(destination, prefix, keep_vars) def get_inputs_quantization_params(self, input): if not self.preset_act_stats: # 如果没有统计数据提供支持,则需要dynamic计算 self.in_0_scale, self.in_0_zero_point = _get_quant_params_from_tensor( input, self.num_bits_acts, self.mode, clip=self.clip_acts, num_stds=self.clip_n_stds, scale_approx_mult_bits=self.scale_approx_mult_bits) return [self.in_0_scale], [self.in_0_zero_point] def quantized_forward(self, input_q): # See class documentation for quantized calculation details. if not self.preset_act_stats: # 没有统计数据 # 基类中 self.accum_scale = 1,这里重置 self.accum_scale = self.in_0_scale * self.w_scale # in_0_scale在get_inputs_quantization_params中补全定义了 if self.per_channel_wts: self.accum_scale = self.accum_scale.squeeze(dim=-1) if self.has_bias: # Re-quantize bias to match x * w scale: # b_q' = (in_scale * w_scale / b_scale) * (b_q + b_zero_point) bias_requant_scale = self.accum_scale.squeeze() / self.b_scale if self.scale_approx_mult_bits is not None: bias_requant_scale = approx_scale_as_mult_and_shift(bias_requant_scale, self.scale_approx_mult_bits) # 没有统计数据情况下,对bias根据accum scale进行*重新*量化(根据doc里的公式,但公式里原来是没有round的) # b_q' = round[(in_scale * w_scale / b_scale) * (base_b_q + b_zero_point)] - 0 self.wrapped_module.bias.data = linear_quantize_clamp(self.base_b_q + self.b_zero_point, bias_requant_scale, 0, self.accum_min_q_val, self.accum_max_q_val) # Note the main terms within the summation is: # (x_q + zp_x) * (w_q + zp_w) # In a performance-optimized solution, we would expand the parentheses and perform the computation similar # to what is described here: # https://github.com/google/gemmlowp/blob/master/doc/low-precision.md#efficient-handling-of-offsets # However, for now we're more concerned with simplicity rather than speed. So we'll just add the zero points # to the input and weights and pass those to the wrapped model. Functionally, since at this point we're # dealing solely with integer values, the results are the same either way. if self.mode != LinearQuantMode.SYMMETRIC and not self.is_simulated_quant_weight_shifted: # We "store" the w_zero_point inside our wrapped module's weights to # improve performance on inference. self.wrapped_module.weight.data += self.w_zero_point # 对称模式w_zp=0 self.is_simulated_quant_weight_shifted.add_(1) # i.e. is_simulated_quant_weight_shifted = True input_q += self.in_0_zero_point # 执行doc中的 (x_q + zp_x) * (w_q + zp_w) + # round[ (in_scale * w_scale / b_scale) * (b_q + b_zero_point) - 0 ] # 获得accum,注意只是个中间量化值,没有实际意义 accum = self.wrapped_module.forward(input_q) # accum的量化范围是32bits clamp(accum.data, self.accum_min_q_val, self.accum_max_q_val, inplace=True) return accum def get_output_quantization_params(self, accumulator): if self.preset_act_stats: return self.output_scale, self.output_zero_point # TODO why? 没有历史统计数据的话,scale_y和zp_y都无从获得? y_f = accumulator / self.accum_scale return _get_quant_params_from_tensor(y_f, self.num_bits_acts, self.mode, clip=self.clip_acts, num_stds=self.clip_n_stds, scale_approx_mult_bits=self.scale_approx_mult_bits) def get_accum_to_output_re_quantization_params(self, output_scale, output_zero_point): requant_scale = output_scale / self.accum_scale if self.scale_approx_mult_bits is not None: requant_scale = approx_scale_as_mult_and_shift(requant_scale, self.scale_approx_mult_bits) return requant_scale, output_zero_point - 整体思路是:
- 在doc里,解释了distiller是如何将原计算转换成 float -> int -> float形式的 ,并让原module执行int部分的计算,达到核心计算由int执行的目的(即实现量化计算)
- __init__中,事先计算weight、bias(如果有)的量化值;此处根据是否有统计数据会有些处理上的差异;
- quantized_forward函数:接收量化的输入,然后让原module执行量化计算,返回的是中间量化值(不是y_f对应的y_q)

-
get_accum_to_output_re_quantization_params函数:根据doc解释,要得到最终的量化输出结果y_q,还需要对quantized_forward的输出值(accum)进行变换;观察doc解释,该变换又可以视为一种量化,因此该函数根据doc输出 二次量化的scale和zp;
-
小结:
-
通过上述module替换(封装),当做inference时,虽然nn.Conv2d不变,但是计算时就变成int类型计算了;
-
值得一提的是,distiller工具包没有实现整型的gemm(矩阵乘/igemm),因此量化后还需要引入igemm包;
-
- 非参数层
- 非参数层和参数层做法大体类似,只不过因为没有参数,所以有些不同
- 举例说明:这是对加法操作(distiller现将其封装为module)进行的量化
# add:固定wrapper_type为RangeLinearQuantEltwiseAddWrapper factory_eltwiseadd = partial(replace_non_param_layer, RangeLinearQuantEltwiseAddWrapper) - replace_non_param_layer类似replace_param_layer,但是多了一个参数wrapper_type,表示wrapper类型;该参数的设置是为了复用函数考虑的,因为非参module较多(如加法、逐元素乘法/点积、批乘法等),各个module需要使用不同的wrapper;定义如下:

- 看一下eltwiseadd的wrapper,实现思路和上面的带参wrapper是一样的,不一样的是quantized_forward代表的量化实现过程
class RangeLinearQuantEltwiseAddWrapper(RangeLinearQuantWrapper): """ add-0107-zyc y_f = in0_f + in1_f in0_q = round(in0_f * scale_in0) - zp_in0 in1_q = round(in1_f * scale_in1) - zp_in1 y_q = round(y_f * scale_y) - zp_y => 以下省略round = scale_y * ( in0_f + in1_f ) - zp_y scale_y = ------------------- * [ scale_in1*(in0_q + zp_in0) + (in1_q + zp_in1)*scale_in0 ] - zp_y scale_in0*scale_in1 => 可以发现上式不能进行int计算,所以需要进一步处理:对in0_q和in1_q重新量化,scale统一为该节点output/accum的scale in0_re_q = scale_accum * [( in0_q + zp_in0 ) / scale_in0] - 0 # 此时新的scale为scale_accum,zp为0 in1_re_q = scale_accum * [( in0_q + zp_in1 ) / scale_in1] - 0 => 则 y_q = round(y_f * scale_y) - zp_y => 以下省略round = scale_y * ( in0_f + in1_f ) - zp_y scale_y = ------------------------- * [scale_re_in1*(in0_re_q+zp_re_in0)+(in1_re_q+zp_re_in1)*scale_re_in0] - zp_y scale_re_in0*scale_re_in1 = 1 * [ (in0_re_q + zp_re_in0) + (in1_re_q + zp_re_in1) ] - zp_y = 1 * (in0_re_q + in1_re_q) - zp_y note:从推导的角度来看,上述重量化做法并没有问题 """ def __init__(self, wrapped_module, num_bits_acts, mode=LinearQuantMode.SYMMETRIC, clip_acts=ClipMode.NONE, activation_stats=None, clip_n_stds=None, clip_half_range=False, scale_approx_mult_bits=None): if not isinstance(wrapped_module, distiller.modules.EltwiseAdd): raise ValueError(self.__class__.__name__ + ' can only wrap distiller.modules.EltwiseAdd modules') if not activation_stats: raise NoStatsError(self.__class__.__name__ + ' must get activation stats, dynamic quantization not supported') super(RangeLinearQuantEltwiseAddWrapper, self).__init__(wrapped_module, num_bits_acts, mode=mode, clip_acts=clip_acts, activation_stats=activation_stats, clip_n_stds=clip_n_stds, clip_half_range=clip_half_range, scale_approx_mult_bits=scale_approx_mult_bits) if self.preset_act_stats: # For addition to make sense, all input scales must match. So we set a re-scale factor according # to the preset output scale requant_scales = [self.output_scale / in_scale for in_scale in self.inputs_scales()] if scale_approx_mult_bits is not None: requant_scales = [approx_scale_as_mult_and_shift(requant_scale, scale_approx_mult_bits) for requant_scale in requant_scales] for idx, requant_scale in enumerate(requant_scales): self.register_buffer('in_{0}_requant_scale'.format(idx), requant_scale) def inputs_requant_scales(self): if not self.preset_act_stats: raise RuntimeError('Input quantization parameter iterators only available when activation stats were given') for idx in range(self.num_inputs): name = 'in_{0}_requant_scale'.format(idx) yield getattr(self, name) def get_inputs_quantization_params(self, *inputs): return self.inputs_scales(), self.inputs_zero_points() def quantized_forward(self, *inputs_q): # Re-scale inputs to the accumulator range # 对已量化的输入重新量化,scale变为accum的(self.output_scale),如此统一了scale_in inputs_re_q = [linear_quantize_clamp(input_q + zp, requant_scale, 0, self.accum_min_q_val, self.accum_max_q_val, inplace=False) for input_q, requant_scale, zp in zip(inputs_q, self.inputs_requant_scales(), self.inputs_zero_points())] accum = self.wrapped_module(*inputs_re_q) clamp(accum.data, self.accum_min_q_val, self.accum_max_q_val, inplace=True) return accum def get_output_quantization_params(self, accumulator): return self.output_scale, self.output_zero_point def get_accum_to_output_re_quantization_params(self, output_scale, output_zero_point): return 1., self.output_zero_point
- Embedding层
- 该层的量化计算就比较简单了(其实不做量化也行吧,除非为了减少模型大小),以下为定义:

- 可以看到,没有复杂的quantized_forward和二次量化;
- 该层的量化计算就比较简单了(其实不做量化也行吧,除非为了减少模型大小),以下为定义:
- 小结:以上介绍了后训练量化器是如何实现的,核心部分是 各类wrapper 对原module的封装替代;
- 补充:scale(一般是float)的整型计算方法
- 直接上代码了;基本思想就是 floor(scale*2^N) / (2^N),N其实能大就大

- 直接上代码了;基本思想就是 floor(scale*2^N) / (2^N),N其实能大就大
- 参数层:
- BN折叠实现
- 见BN折叠
- 激活层优化
- 待补充
总结
- 本文介绍了distiller量化器基类Quantizer的一个子类:PostTrainLinearQuantizer;
- 核心部分是 各类wrapper 对原module的封装替代;以及一些优化处理,如BN折叠、激活层优化、scale整型化计算等;